Verified Misguidance: Measuring Structural Citation Failures in Search-Augmented LLMs
Pith reviewed 2026-06-29 09:21 UTC · model grok-4.3
The pith
Search-augmented LLMs cite real sources that distort content in 30.6 percent of cases or come from unsuitable domains in 27.1 percent of cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
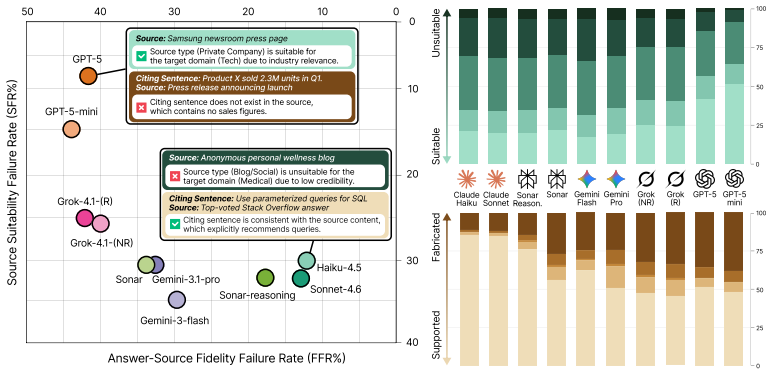
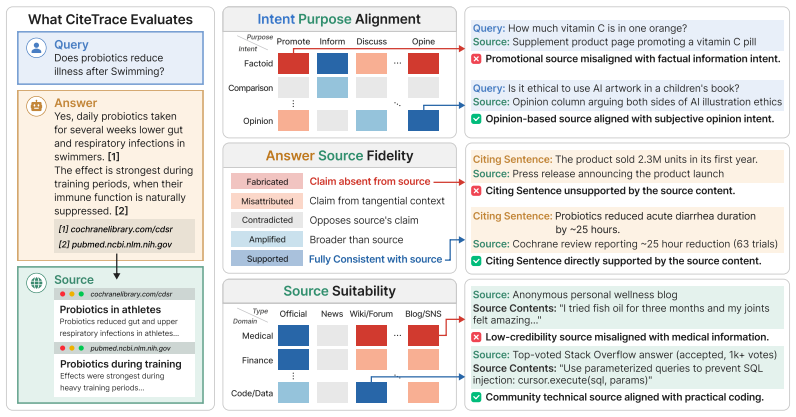
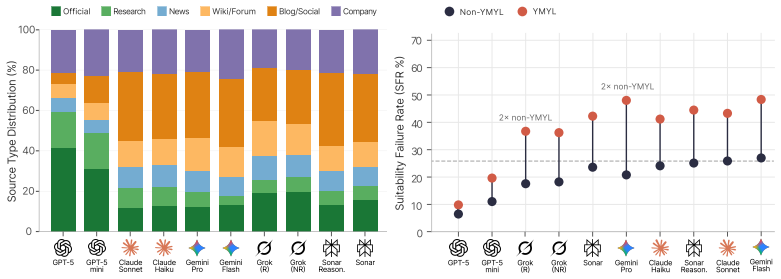
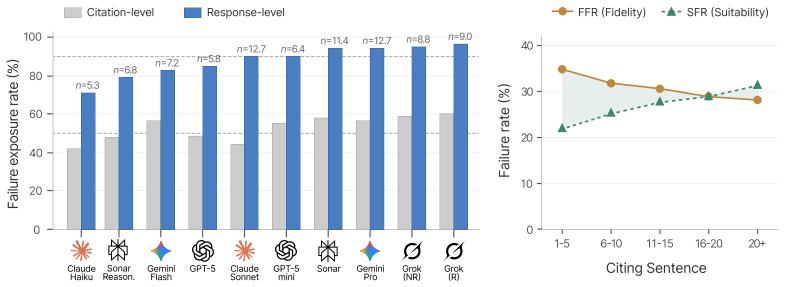
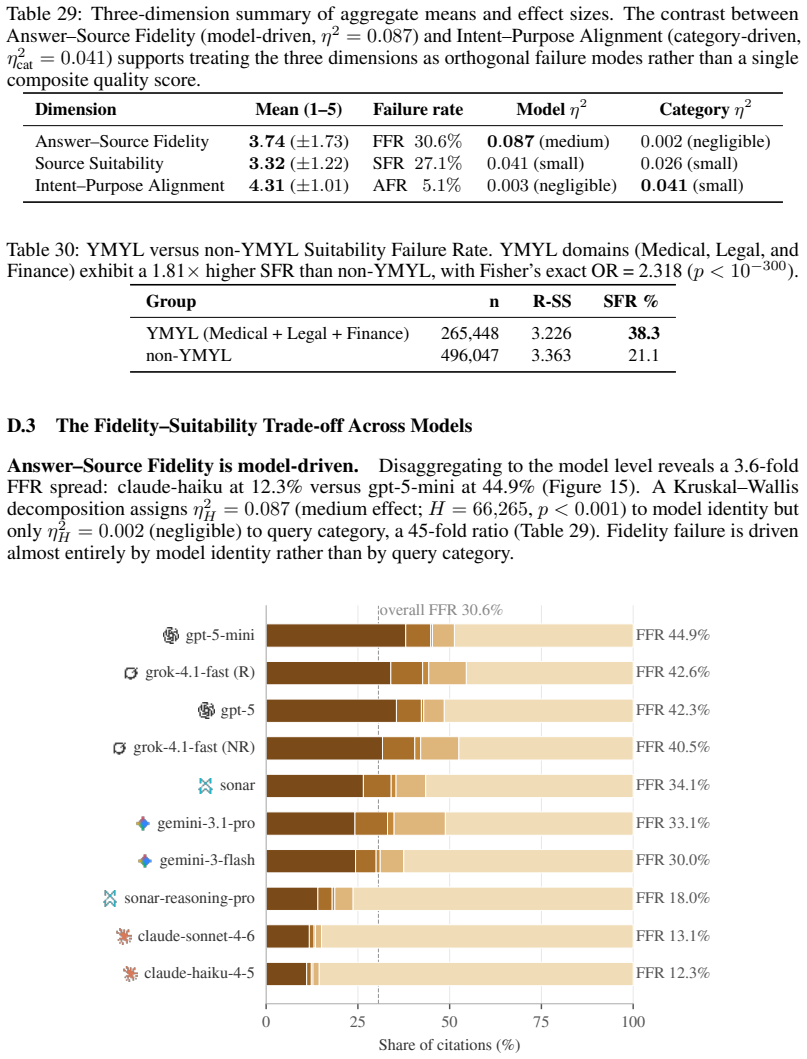
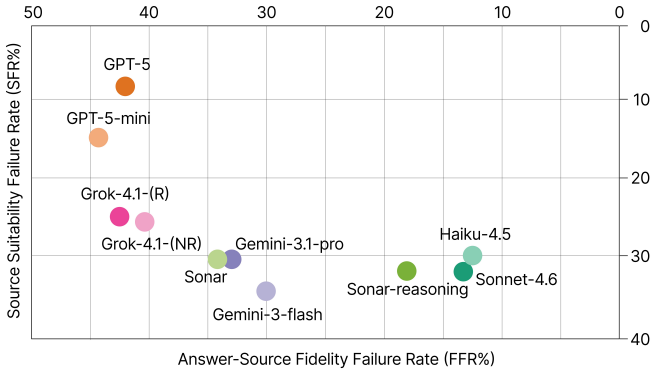
The central claim is that search-augmented LLMs exhibit verified misguidance, a pattern in which they cite real, accessible sources that nevertheless fail on intent-purpose alignment, source suitability, or answer-source fidelity. This produces a fidelity-suitability trade-off in which more faithful citations often come from less appropriate sources and vice versa. Measurements across the dataset show 30.6 percent of citations distort their sources and 27.1 percent originate from domain-inappropriate sources, with up to 96 percent of responses containing at least one structurally misleading citation. Provider-level factors explain 88-96 percent of citation-quality variance.
What carries the argument
The CITETRACE dataset, which traces citation chains from 11,200 real-world queries through 112,000 responses to produce 761,495 evaluable citation pairs, combined with a three-dimension evaluation framework that scores each citation on intent-purpose alignment, source suitability, and answer-source fidelity using expert-validated predefined matrices and a five-level fidelity rubric.
If this is right
- A fidelity-suitability trade-off appears consistently across models, so improving one dimension often harms the other.
- Provider-level differences explain 88-96 percent of citation-quality variance, indicating that retrieval and ranking policies at the system level dominate over model-specific capabilities.
- Up to 96 percent of responses contain at least one structurally misleading citation, so users relying on citations without verification face a high probability of encountering distorted or mismatched evidence.
- The evaluation framework can be applied to any system that returns citation-bearing responses, enabling systematic diagnosis of structural citation failures.
Where Pith is reading between the lines
- Targeting provider-level source selection and ranking logic may yield larger reductions in verified misguidance than further tuning of the language models themselves.
- Explicit mechanisms to detect and balance the fidelity-suitability trade-off during retrieval could be added to existing search-augmented pipelines.
- The dataset could serve as a benchmark for testing whether new retrieval methods reduce the rate of domain-inappropriate or distorting citations.
Load-bearing premise
The three-dimension evaluation framework using expert-validated predefined matrices and a five-level fidelity rubric accurately captures the structural trustworthiness of citations without systematic bias.
What would settle it
Re-scoring a random sample of several hundred citation pairs with a new panel of experts and obtaining substantially different distributions on any of the three dimensions would show the framework does not reliably measure citation quality.
Figures







read the original abstract
Users of search-augmented LLMs rely on citations as evidence that responses are grounded in real sources, and rarely verify the cited pages themselves. Millions of queries per day now pass through these systems, making citation quality a silent determinant of whether users are informed or misled-yet existing benchmarks each address one facet in isolation, leaving the joint structure that determines citation trustworthiness unmeasured. We construct CITETRACE, a large-scale dataset that traces the full citation chain from user query through retrieved source to generated answer: 11,200 real-world queries from 28 communities paired with 112,000 responses from ten models across five providers, yielding 761,495 evaluable citation pairs. We design a three-dimension evaluation framework that scores each citation on intent-purpose alignment, source suitability, and answer-source fidelity, using expert-validated predefined matrices and a five-level fidelity rubric; the framework applies to any system that produces citation-bearing responses. Applying this framework at scale, we identify a systematic pattern we call VERIFIED MISGUIDANCE (VM): models cite real, accessible sources yet fail along one or more dimensions, producing a fidelity-suitability trade-off in which faithful models select inappropriate sources and vice versa. Across our pool, 30.6% of citations distort their sources and 27.1% originate from domain-inappropriate sources; at the response level, up to 96% of users encounter at least one structurally misleading citation. Provider-level differences explain 88-96% of citation-quality variance, suggesting that source selection is governed more by factors beyond individual model capability than by the LLMs themselves. Together, CITETRACE and its evaluation framework provide the first resource for diagnosing structural citation failures in deployed search-augmented systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs the CITETRACE dataset from 11,200 real-world queries across 28 communities, generating 112,000 responses from ten models and 761,495 citation pairs. It proposes a three-dimension evaluation framework assessing intent-purpose alignment, source suitability, and answer-source fidelity via expert-validated matrices and a five-level rubric. The analysis reveals a 'Verified Misguidance' pattern, with 30.6% of citations distorting sources, 27.1% from inappropriate domains, up to 96% of responses having at least one misleading citation, and provider-level factors explaining 88-96% of quality variance.
Significance. If the framework's annotations prove reliable, the work is significant for quantifying citation trustworthiness issues in search-augmented LLMs at scale. It provides a new dataset and framework applicable to any citation-bearing system, highlighting a fidelity-suitability trade-off and the dominance of provider effects. The large empirical scale and construction of a traceable citation dataset are clear strengths that could advance benchmarking in this area.
major comments (1)
- [Framework design and validation] The section describing the three-dimension evaluation framework states that it uses 'expert-validated predefined matrices and a five-level fidelity rubric' but provides no information on the number of experts, their selection or training, or inter-rater reliability statistics. This is load-bearing for the central claims, as the reported 30.6% distortion rate, 27.1% inappropriate source rate, and the VM pattern are direct outputs of applying this rubric to the 761k pairs; without agreement metrics, the possibility of annotator bias cannot be assessed.
minor comments (2)
- [Results section] The explanation of how provider-level differences account for 88-96% of variance would benefit from an explicit reference to the statistical method or model used (e.g., ANOVA or regression details).
- [Dataset construction] Clarification on how the 28 communities were selected and any controls for selection bias would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below and agree that additional details on the annotation process are required to support the central claims. The revised manuscript will incorporate these details.
read point-by-point responses
-
Referee: [Framework design and validation] The section describing the three-dimension evaluation framework states that it uses 'expert-validated predefined matrices and a five-level fidelity rubric' but provides no information on the number of experts, their selection or training, or inter-rater reliability statistics. This is load-bearing for the central claims, as the reported 30.6% distortion rate, 27.1% inappropriate source rate, and the VM pattern are direct outputs of applying this rubric to the 761k pairs; without agreement metrics, the possibility of annotator bias cannot be assessed.
Authors: We agree that the submitted manuscript omits these critical details on the expert validation process, which prevents readers from fully assessing reliability and potential bias. The annotation protocol used predefined matrices and the five-level rubric, but the manuscript does not report the number of experts, selection criteria, training, or inter-rater statistics. In the revision we will add a new subsection (likely 3.3.1) that reports: the number of experts and their backgrounds, recruitment and selection process, training and calibration procedure, and inter-rater reliability metrics computed on a held-out sample of citation pairs. We will also release the full annotation guidelines and a sample of annotated pairs as supplementary material. These additions directly address the concern without changing the reported aggregate statistics or conclusions. revision: yes
Circularity Check
No circularity: empirical measurement study with independent data and scoring
full rationale
The paper constructs CITETRACE (11,200 queries, 112,000 responses, 761k citation pairs) from external sources and applies a three-dimension rubric (intent-purpose alignment, source suitability, answer-source fidelity) with expert-validated matrices and a five-level scale. All headline statistics (30.6% distortion, 27.1% domain-inappropriate, 88-96% provider variance) are direct tallies from this application. No equations, fitted parameters, predictions, self-citations, or uniqueness theorems appear; the measurement chain does not reduce any output to a quantity defined by the inputs themselves. This is a standard empirical study whose central claims rest on the collected data and rubric application rather than any self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert-validated predefined matrices and five-level fidelity rubric provide an unbiased measure of citation quality across intent, suitability, and fidelity dimensions
Reference graph
Works this paper leans on
-
[1]
Geo: Generative engine optimization
Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, and Ameet Deshpande. Geo: Generative engine optimization. InProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining, pages 5–16, 2024
2024
-
[2]
George A. Akerlof. The market for “lemons”: Quality uncertainty and the market mechanism. The Quarterly Journal of Economics, 84(3):488–500, 1970
1970
-
[3]
Croissant: A metadata format for ML-ready datasets
Mubashara Akhtar, Omar Benjelloun, Costanza Conforti, Luca Foschini, Pieter Gijsbers, Joan Giner-Miguelez, Sujata Goswami, Nitisha Jain, Michalis Karamousadakis, Satyapriya Krishna, Michael Kuchnik, Sylvain Lesage, Quentin Lhoest, Pierre Marcenac, Manil Maskey, Peter Mattson, Luis Oala, Hamidah Oderinwale, Pierre Ruyssen, Tim Santos, Rajat Shinde, Elena S...
2024
-
[4]
Kenneth J. Arrow. Uncertainty and the welfare economics of medical care.The American Economic Review, 53(5):941–973, 1963
1963
-
[5]
Measuring political bias in large language models: What is said and how it is said
Yejin Bang, Delong Chen, Nayeon Lee, and Pascale Fung. Measuring political bias in large language models: What is said and how it is said. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11142–11159, 2024
2024
-
[6]
Trafilatura: A web scraping library and command-line tool for text discovery and extraction
Adrien Barbaresi. Trafilatura: A web scraping library and command-line tool for text discovery and extraction. InProceedings of the Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations, pages 122–131, 2021
2021
-
[7]
Exploring the composition of the searchable web: A corpus-based taxonomy of web registers.Corpora, 10(1):11–45, 2015
Douglas Biber, Jesse Egbert, and Mark Davies. Exploring the composition of the searchable web: A corpus-based taxonomy of web registers.Corpora, 10(1):11–45, 2015
2015
-
[8]
The CRAAP test.LOEX Quarterly, 31(3):4, 2004
Sarah Blakeslee. The CRAAP test.LOEX Quarterly, 31(3):4, 2004
2004
-
[9]
Bernd Bohnet, Vinh Q Tran, Pat Verga, Roee Aharoni, Daniel Andor, Livio Baldini Soares, Massimiliano Ciaramita, Jacob Eisenstein, Kuzman Ganchev, Jonathan Herzig, et al. Attributed question answering: Evaluation and modeling for attributed large language models.arXiv preprint arXiv:2212.08037, 2022
-
[10]
A non-factoid question-answering taxonomy
Valeriia Bolotova, Vladislav Blinov, Falk Scholer, W Bruce Croft, and Mark Sanderson. A non-factoid question-answering taxonomy. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1196–1207, 2022
2022
-
[11]
A taxonomy of web search
Andrei Broder. A taxonomy of web search. InACM SIGIR Forum, volume 36, pages 3–10, 2002
2002
-
[12]
A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20(1):37–46, 1960
Jacob Cohen. A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20(1):37–46, 1960. 10
1960
-
[13]
Citations and trust in llm generated responses, 2025
Yifan Ding, Matthew Facciani, Amrit Poudel, Ellen Joyce, Salvador Aguinaga, Balaji Veeramani, Sanmitra Bhattacharya, and Tim Weninger. Citations and trust in llm generated responses, 2025. URLhttps://arxiv.org/abs/2501.01303
-
[14]
RAGAS: Automated evaluation of retrieval augmented generation
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. RAGAS: Automated evaluation of retrieval augmented generation. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, pages 150–158, 2024
2024
-
[15]
B. J. Fogg, Cathy Soohoo, David R. Danielson, Leslie Marable, Julianne Stanford, and Ellen R. Tauber. How do users evaluate the credibility of web sites? a study with over 2,500 participants. InProceedings of the 2003 Conference on Designing for User Experiences (DUX), pages 1–15, 2003
2003
-
[16]
Enabling large language models to generate text with citations
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. Enabling large language models to generate text with citations. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6465–6488, 2023
2023
-
[17]
Search quality evaluator guidelines
Google. Search quality evaluator guidelines. https://guidelines.raterhub.com/sear chqualityevaluatorguidelines.pdf, 2022
2022
-
[18]
Sebastian Haan. Semanticcite: Citation verification with ai-powered full-text analysis and evidence-based reasoning.arXiv preprint arXiv:2511.16198, 2025
-
[19]
Verspoor, and Timothy Baldwin
Doris Hoogeveen, Karin M. Verspoor, and Timothy Baldwin. CQADupStack: A benchmark data set for community question-answering research. InProceedings of the 20th Australasian Document Computing Symposium, pages 3:1–3:8, 2015
2015
-
[20]
Retrieval-augmented generation with estimation of source reliability
Jeongyeon Hwang, Junyoung Park, Hyejin Park, Dongwoo Kim, Sangdon Park, and Jungseul Ok. Retrieval-augmented generation with estimation of source reliability. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 34279–34303. Association for Computational Linguistics, 2025. URL https://aclanthology.org/2025. emnlp...
2025
-
[21]
Content taxonomy 3.0
IAB Tech Lab. Content taxonomy 3.0. IAB Tech Lab Standard, 2022. URL https://iabtec hlab.com/standards/content-taxonomy/
2022
-
[22]
Peter Ingwersen and Kalervo Järvelin.The Turn: Integration of Information Seeking and Retrieval in Context, volume 18 ofThe Information Retrieval Series. Springer, Dordrecht, 2005. ISBN 978-1-4020-3851-8. doi: 10.1007/1-4020-3851-8
-
[23]
Determining the informational, navigational, and transactional intent of web queries.Information Processing & Management, 44(3):1251–1266, 2008
Bernard J Jansen, Danielle L Booth, and Amanda Spink. Determining the informational, navigational, and transactional intent of web queries.Information Processing & Management, 44(3):1251–1266, 2008
2008
-
[24]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38, 2023
2023
-
[25]
SourceBench: Can AI answers reference quality web sources?arXiv preprint arXiv:2602.16942, 2026
Hexi Jin, Stephen Liu, Yuheng Li, Simran Malik, and Yiying Zhang. SourceBench: Can AI answers reference quality web sources?arXiv preprint arXiv:2602.16942, 2026
-
[26]
Understanding and predicting web content credibility using the content credibility corpus.Information Processing & Management, 53(5):1043–1061, 2017
Michal Kakol, Radoslaw Nielek, and Adam Wierzbicki. Understanding and predicting web content credibility using the content credibility corpus.Information Processing & Management, 53(5):1043–1061, 2017
2017
-
[27]
Hannah Rose Kirk, Bertie Vidgen, Paul Röttger, and Scott A. Hale. PRISM: A participatory, representative and individualised evaluation of language model alignment. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2024. Best Paper Award
2024
-
[28]
A guideline of selecting and reporting intraclass correlation coefficients for reliability research.Journal of chiropractic medicine, 15(2):155–163, 2016
Terry K Koo and Mae Y Li. A guideline of selecting and reporting intraclass correlation coefficients for reliability research.Journal of chiropractic medicine, 15(2):155–163, 2016. 11
2016
-
[29]
Rfc 9309 robots exclusion protocol.Internet Engineering Task Force, 2022
Martijn Koster, Gary Illyes, Henner Zeller, and Lizzi Sassman. Rfc 9309 robots exclusion protocol.Internet Engineering Task Force, 2022
2022
-
[30]
Computing Krippendorff’s alpha-reliability
Klaus Krippendorff. Computing Krippendorff’s alpha-reliability. Technical Report 43, Annenberg School for Communication, University of Pennsylvania, 2011. URL https: //repository.upenn.edu/asc_papers/43
2011
-
[31]
Evaluating the factual consistency of abstractive text summarization
Wojciech Kryscinski, Bryan McCann, Caiming Xiong, and Richard Socher. Evaluating the factual consistency of abstractive text summarization. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 9332–9346, 2020. doi: 10.18653 /v1/2020.emnlp-main.750. URLhttps://aclanthology.org/2020.emnlp-main.750/
2020
-
[32]
Philippe Laban, Tobias Schnabel, Paul N. Bennett, and Marti A. Hearst. SummaC: Re-visiting NLI-based models for inconsistency detection in summarization.Transactions of the Association for Computational Linguistics, 10:163–177, 2022. doi: 10.1162/tacl_a_00453
-
[33]
The measurement of observer agreement for categorical data.biometrics, pages 159–174, 1977
J Richard Landis and Gary G Koch. The measurement of observer agreement for categorical data.biometrics, pages 159–174, 1977
1977
-
[34]
Alice Li and Luanne Sinnamon. Generative ai search engines as arbiters of public knowledge: An audit of bias and authority.Proceedings of the Association for Information Science and Technology, 61(1):205–217, 2024
2024
-
[35]
Liu, Tianyi Zhang, and Percy Liang
Nelson F. Liu, Tianyi Zhang, and Percy Liang. Evaluating verifiability in generative search engines.Findings of the Association for Computational Linguistics (EMNLP), pages 7001–7025, 2023
2023
-
[36]
On faithfulness and factuality in abstractive summarization
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. On faithfulness and factuality in abstractive summarization. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1906–1919, 2020. doi: 10.18653/v1/2020.acl -main.173. URLhttps://aclanthology.org/2020.acl-main.173/
-
[37]
FActScore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076–12100, 2023. doi: 10.18653 /v1/2...
2023
-
[38]
Angelopoulos, Trevor Darrell, Narges Norouzi, and Joseph E
Mihran Miroyan, Tsung-Han Wu, Logan King, Tianle Li, Jiayi Pan, Xinyan Hu, Wei-Lin Chiang, Anastasios N. Angelopoulos, Trevor Darrell, Narges Norouzi, and Joseph E. Gonzalez. Search arena: Analyzing search-augmented LLMs. InProceedings of the International Conference on Learning Representations (ICLR), 2026. arXiv:2506.05334
-
[39]
Pranav Narayanan Venkit, Philippe Laban, Yilun Zhou, Yixin Mao, and Chien-Sheng Wu. Search engines in the AI era: A qualitative understanding to the false promise of factual and verifiable source-cited responses in LLM-based search. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT), pages 1325–1340, 2025. doi: ...
-
[40]
Nicholson, Milo Mordaunt, Patrice Lopez, Ashish Uppala, Domenic Rosber, Sean P
Josh M. Nicholson, Milo Mordaunt, Patrice Lopez, Ashish Uppala, Domenic Rosber, Sean P. Bber, Christoph Thaler, Yuhao Deng, Casey S. Greene, and Satoshi Nishi. Scite: A smart citation index that displays the context of citations and classifies their intent using deep learning. Quantitative Science Studies, 2(3):882–898, 2021
2021
-
[41]
Understanding factuality in abstractive summarization with FRANK: A benchmark for factuality metrics
Artidoro Pagnoni, Vidhisha Balachandran, and Yulia Tsvetkov. Understanding factuality in abstractive summarization with FRANK: A benchmark for factuality metrics. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4812–4829, 2021. doi: 10.18653/v1/2021.n a...
-
[42]
Citeme: Can language models accurately cite scientific claims?Advances in Neural Information Processing Systems, 37:7847–7877, 2024
Ori Press, Andreas Hochlehnert, Ameya Prabhu, Vishaal Udandarao, Ofir Press, and Matthias Bethge. Citeme: Can language models accurately cite scientific claims?Advances in Neural Information Processing Systems, 37:7847–7877, 2024. 12
2024
-
[43]
Detecting and Correcting Reference Hallucinations in Commercial LLMs and Deep Research Agents
Delip Rao, Eric Wong, and Chris Callison-Burch. Detecting and correcting reference hal- lucinations in commercial llms and deep research agents.arXiv preprint arXiv:2604.03173, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Measuring attribution in natural language generation models.Computational Linguistics, 49(4):777–840, December
Hannah Rashkin, Vitaly Nikolaev, Matthew Lamm, Lora Aroyo, Michael Collins, Dipanjan Das, Slav Petrov, Gaurav Singh Tomar, Iulia Turc, and David Reitter. Measuring attribution in natural language generation models.Computational Linguistics, 49(4):777–840, December
-
[45]
doi: 10.1162/coli_a_00486. URLhttps://aclanthology.org/2023.cl-4.2/
-
[46]
Soo Young Rieh and David R. Danielson. Credibility: A multidisciplinary framework.Annual Review of Information Science and Technology, 41(1):307–364, 2007. doi: 10.1002/aris.2007. 1440410114
-
[47]
Understanding user goals in web search
Daniel E Rose and Danny Levinson. Understanding user goals in web search. InProceedings of the 13th international conference on World Wide Web, pages 13–19, 2004
2004
-
[48]
ARES: An automated evaluation framework for retrieval-augmented generation systems
Jon Saad-Falcon, Omar Khattab, Christopher Potts, and Matei Zaharia. ARES: An automated evaluation framework for retrieval-augmented generation systems. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 338–354, 2024
2024
-
[49]
Yash Saxena, Raviteja Bommireddy, Ankur Padia, and Manas Gaur. Generation-time vs. post-hoc citation: A holistic evaluation of LLM attribution.arXiv preprint arXiv:2509.21557, 2025
-
[50]
Schema.org: A shared vocabulary for structured data
Schema.org Community Group. Schema.org: A shared vocabulary for structured data. https: //schema.org, 2011. Founded by Google, Microsoft, Yahoo, and Yandex
2011
-
[51]
Functional text dimensions for the annotation of web corpora.Corpora, 13(1): 65–95, 2018
Serge Sharoff. Functional text dimensions for the annotation of web corpora.Corpora, 13(1): 65–95, 2018
2018
-
[52]
Yalin Sun, Yan Zhang, Jacek Gwizdka, and Ciaran B. Trace. Consumer evaluation of the quality of online health information: Systematic literature review of relevant criteria and indicators. Journal of Medical Internet Research, 21(5):e12522, 2019. doi: 10.2196/12522
-
[53]
Swales.Genre Analysis: English in Academic and Research Settings
John M. Swales.Genre Analysis: English in Academic and Research Settings. Cambridge University Press, Cambridge, 1990
1990
-
[54]
MiniCheck: Efficient fact-checking of LLMs on grounding documents
Liyan Tang, Philippe Laban, and Greg Durrett. MiniCheck: Efficient fact-checking of LLMs on grounding documents. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024
2024
-
[55]
Minaoar Hossain Tanzil, Shaiful Chowdhury, Somayeh Modaberi, Gias Uddin, and Hadi Hemmati. A systematic mapping study of crowd knowledge enhanced software engineering research using Stack Overflow.Journal of Systems and Software, 226:112405, 2025. doi: 10.1016/j.jss.2025.112405
-
[56]
Robert S. Taylor. Question-negotiation and information seeking in libraries.College & Research Libraries, 29(3):178–194, 1968. doi: 10.5860/crl_29_03_178
-
[57]
Assessing web search credibility and response groundedness in chat assistants
Ivan Vykopal, Matúš Pikuliak, Simon Ostermann, and Marian Simko. Assessing web search credibility and response groundedness in chat assistants. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2539–2560, 2026
2026
-
[58]
Correctness is not faithful- ness in retrieval augmented generation attributions
Jonas Wallat, Maria Heuss, Maarten de Rijke, and Avishek Anand. Correctness is not faithful- ness in retrieval augmented generation attributions. InProceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in Information Retrieval (ICTIR), pages 22–32, 2025
2025
-
[59]
Asking and answering questions to evaluate the factual consistency of summaries
Alex Wang, Kyunghyun Cho, and Mike Lewis. Asking and answering questions to evaluate the factual consistency of summaries. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5008–5020, 2020. doi: 10.18653/v1/2020.acl-main.450. URLhttps://aclanthology.org/2020.acl-main.450/. 13
-
[60]
Kevin Wu, Eric Wu, Kevin Wei, Angela Zhang, Allison Casasola, Teresa Nguyen, Sith Ri- antawan, Patricia Shi, Daniel Ho, and James Zou. An automated framework for assessing how well LLMs cite relevant medical references.Nature Communications, 16(1):3615, 2025. doi: 10.1038/s41467-025-58551-6
-
[61]
ALiiCE: Evaluating positional fine-grained citation generation
Yilong Xu, Jinhua Niu, and Guoxin Xie. ALiiCE: Evaluating positional fine-grained citation generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024
2024
-
[62]
GhostCite: A Large-Scale Analysis of Citation Validity in the Age of Large Language Models
Zuyao Xu, Yuqi Qiu, Lu Sun, FaSheng Miao, Fubin Wu, Xinyi Wang, Xiang Li, Haozhe Lu, ZhengZe Zhang, Yuxin Hu, et al. Ghostcite: A large-scale analysis of citation validity in the age of large language models.arXiv preprint arXiv:2602.06718, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[63]
Peixian Zhang, Qiming Ye, Zifan Peng, Kiran Garimella, and Gareth Tyson. Source coverage and citation bias in llm-based vs. traditional search engines.arXiv preprint arXiv:2512.09483, 2025. 14 Appendices A Discussions: Scope, Limitations, and Broader Impact. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .16 A.1 Scope and Operational Assumpti...
-
[64]
You’re more likely to experience dizziness, fatigue or feeling faint (a recipe for injury), as well as increasing the risk of bleeding, bruising or soreness
but content is fabricated (ASF = 1). This pattern matches the OpenAI provider profile (FFR 43.8%, SFR 11.7%). 58 Case 5: Accurate citation of an inappropriate source—fitness-app blog as medical evidence Query IDQ04569 QueryWhy I should avoid exercising after blood donation? SiteMedical Sciences·Science Modelclaude-haiku-4-5 (Anthropic) QIQI2 Explanation C...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.