The Token Is a Group Element: On Lie-Algebra Attention over Matrix Lie Groups
Pith reviewed 2026-06-26 17:28 UTC · model grok-4.3
The pith
Tokens defined as bare matrix Lie group elements yield a closed-form attention score from the relative pose logarithm that applies to affine groups and uses 50-80 times fewer parameters than learned kernels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By defining tokens as bare elements g_i of a matrix Lie group G, the attention score becomes the negative squared algebra norm s_ij = −‖log(g_i^{-1} g_j)‖_λ² / τ under a block-weighted Frobenius inner product. This score is intrinsic to the group, automatically satisfies equivariance and the cocycle condition, and applies to any matrix Lie group admitting a suitable logarithm chart, including the affine groups that exclude irrep-based or surjective-exp methods.
What carries the argument
The Lie algebra element w_ij = log(g_i^{-1} g_j) obtained from the relative group element, whose block-weighted Frobenius norm supplies the closed-form attention score without learned parameters or representation theory.
If this is right
- The attention construction reaches the non-compact affine group Aff(2) that irrep-based and surjective-exp methods must exclude.
- On SE(2) the closed-form score matches or outperforms a learned MLP kernel on the same invariant while using 50 to 80 times fewer score parameters.
- A vector-token baseline breaks invariance by five to twelve orders of magnitude on the tested sequence-completion tasks.
- Equivariance under the diagonal G-action and the cocycle condition hold automatically from the group structure without additional design.
Where Pith is reading between the lines
- The same relative-pose construction could be tested on SE(3) or Aff(3) to check whether the parameter advantage scales to higher-dimensional groups.
- Hybrid models could attach feature payloads to the group-element tokens to combine geometric invariance with learned content.
Load-bearing premise
A logarithm chart exists that contains all relevant relative poses g_i^{-1} g_j for the chosen matrix Lie groups and that the block-weighted Frobenius inner product supplies a suitable metric on the algebra.
What would settle it
Applying a fixed group element to all tokens via left multiplication and checking whether the resulting attention scores remain exactly unchanged; any measurable deviation would show the claimed automatic equivariance does not hold.
Figures

read the original abstract
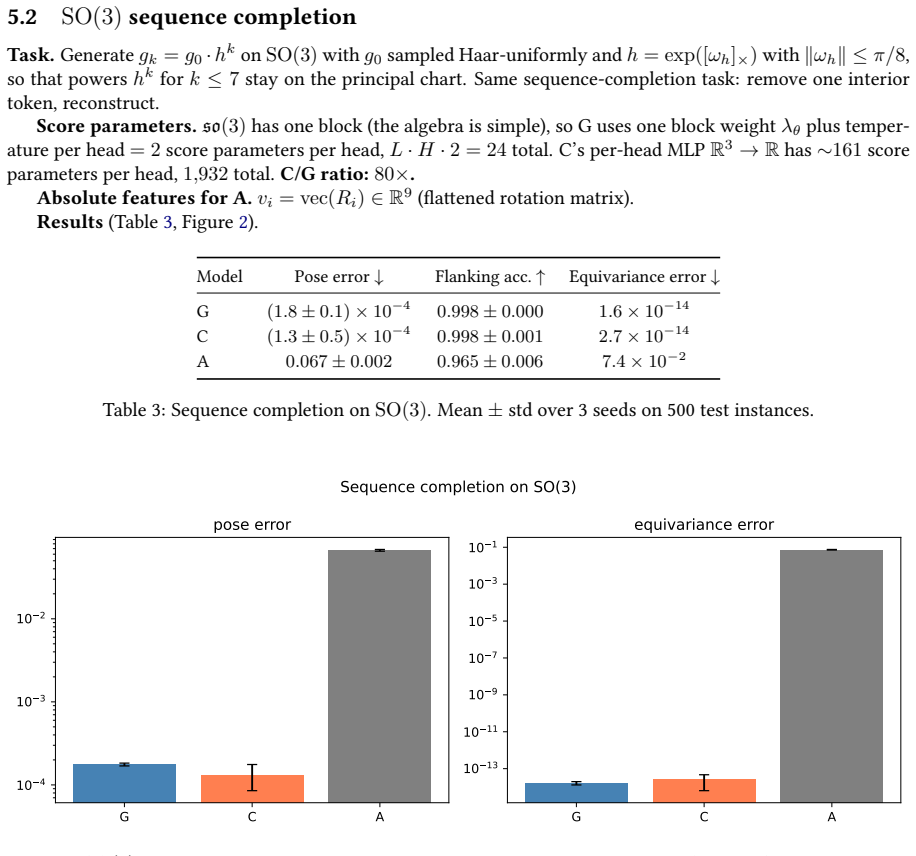
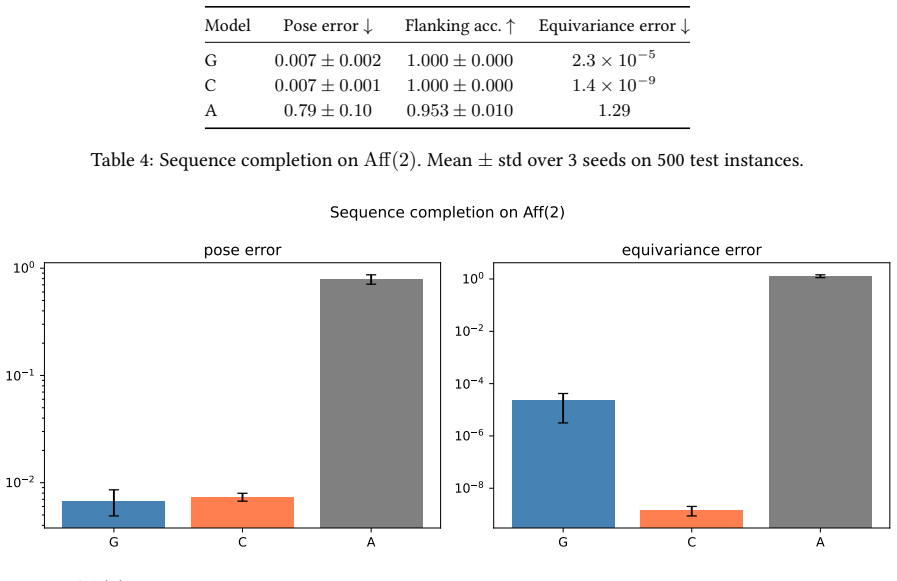
We place the attention token on the group: a token is an element $g_i$ of a matrix Lie group $G$ -- a bare transformation, with no feature payload and no external action $\rho(g)$ carrying it. To our knowledge this is the first attention construction whose tokens are bare matrix Lie group elements: their score is the closed-form algebra norm of the relative pose rather than a learned kernel, and it reaches the affine full-frame groups that every irrep- or surjective-exp-based method must exclude. We call it Lie-Algebra Attention. Once tokens are group elements, the rest follows with none of the usual representation-theoretic machinery. The relative geometry of a pair is canonical, $g_i^{-1} g_j$, so the pairwise invariant $w_{ij} = \log(g_i^{-1} g_j)$ is intrinsic rather than designed; equivariance under the diagonal $G$-action is tautological, and the cocycle condition holds automatically. The attention score is the negative squared algebra norm, $s_{ij} = -\|\log(g_i^{-1} g_j)\|_\lambda^2/\tau$: the canonical proximity kernel under a block-weighted Frobenius inner product, with no irreducible representations, spherical harmonics, Clebsch-Gordan products, or learned kernel. The construction applies to any matrix Lie group on a chosen logarithm chart containing the relative poses, including the non-compact non-abelian affine groups with scale and shear that no vector-token attention method reaches: neither the irrep tradition nor surjective-exp methods. Three sequence-completion experiments, on SE(2), SO(3), and Aff(2), bear this out: the closed-form score matches a learned MLP kernel on the same invariant and outperforms it on SE(2), using 50 to 80x fewer score parameters, while a vector-token baseline breaks invariance by five to twelve orders of magnitude.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Lie-Algebra Attention in which tokens are bare elements g_i of a matrix Lie group G (no feature vectors or external representations). The pairwise score is the closed-form s_ij = -||log(g_i^{-1} g_j)||_λ²/τ under a block-weighted Frobenius inner product on the Lie algebra; equivariance is automatic. The construction is claimed to apply to any matrix Lie group on a chosen logarithm chart containing the relative poses, including non-compact affine groups excluded by irrep- or surjective-exp-based methods. Three sequence-completion experiments (SE(2), SO(3), Aff(2)) are reported to show that the closed-form score matches or outperforms a learned MLP kernel on the same invariant while using 50-80× fewer score parameters, and that a vector-token baseline violates invariance by 5-12 orders of magnitude.
Significance. If the central claims hold, the work supplies a parameter-efficient, representation-free attention mechanism whose equivariance and cocycle properties follow directly from the group structure. The closed-form score and explicit applicability to Aff(2) and similar groups constitute a genuine extension beyond existing geometric attention constructions. The reported parameter reduction and invariance preservation, if reproducible, would be a concrete practical advantage.
major comments (2)
- [Abstract and Aff(2) experiment description] Abstract and Aff(2) experiment: the score s_ij = -||log(g_i^{-1} g_j)||_λ²/τ is defined only when every relative pose lies in the image of the chosen logarithm chart. For Aff(2) the exponential map is not surjective (a matrix [[A b]; [0 1]] admits a real logarithm only under specific eigenvalue and Jordan conditions on A). The manuscript states that the construction applies “on a chosen logarithm chart containing the relative poses” but supplies no verification that the Aff(2) sequence-completion dataset satisfies this condition for all pairs. This verification is load-bearing for the Aff(2) results and for the claim that the method reaches affine groups.
- [Experiments section] Experiments: the quantitative claims (matching/outperforming the MLP, 50-80× parameter reduction, invariance violation by 5-12 orders of magnitude) are presented without data splits, error bars, training details, or code. Because the soundness of these outcomes cannot be assessed from the given text, the experimental support for the central efficiency and invariance claims remains unverifiable.
minor comments (2)
- The choice and tuning procedure for the block weights λ and temperature τ should be stated explicitly, including whether they are fixed across groups or selected per experiment.
- The exact architecture, hidden dimension, and training protocol of the MLP baseline (and of the vector-token baseline) should be given so that the parameter-count comparison can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and Aff(2) experiment description] Abstract and Aff(2) experiment: the score s_ij = -||log(g_i^{-1} g_j)||_λ²/τ is defined only when every relative pose lies in the image of the chosen logarithm chart. For Aff(2) the exponential map is not surjective (a matrix [[A b]; [0 1]] admits a real logarithm only under specific eigenvalue and Jordan conditions on A). The manuscript states that the construction applies “on a chosen logarithm chart containing the relative poses” but supplies no verification that the Aff(2) sequence-completion dataset satisfies this condition for all pairs. This verification is load-bearing for the Aff(2) results and for the claim that the method reaches affine groups.
Authors: We agree that explicit verification is required for the Aff(2) claim. The Aff(2) sequences were generated so that all relative poses satisfy the eigenvalue and Jordan conditions for a real matrix logarithm to exist under the standard chart. In the revision we will add a dedicated paragraph in the Aff(2) experiment subsection that (i) states the precise conditions used, (ii) reports that every generated relative pose meets them, and (iii) confirms the chosen logarithm chart therefore contains the entire dataset. This makes the load-bearing assumption verifiable. revision: yes
-
Referee: [Experiments section] Experiments: the quantitative claims (matching/outperforming the MLP, 50-80× parameter reduction, invariance violation by 5-12 orders of magnitude) are presented without data splits, error bars, training details, or code. Because the soundness of these outcomes cannot be assessed from the given text, the experimental support for the central efficiency and invariance claims remains unverifiable.
Authors: We accept that the current experimental description is insufficient for reproducibility. In the revised manuscript we will expand the Experiments section with: (a) explicit train/validation/test splits and generation procedure, (b) results averaged over multiple random seeds together with standard deviations, (c) full hyper-parameter tables and optimizer settings, and (d) a public code repository link (to be activated upon acceptance). These additions will allow direct assessment of the reported efficiency and invariance numbers. revision: yes
Circularity Check
No significant circularity; derivation is explicitly definitional and externally validated
full rationale
The paper's core construction defines the token as a bare group element g_i and the score directly as s_ij = -||log(g_i^{-1} g_j)||_λ²/τ from the relative pose and block-weighted Frobenius norm, with equivariance called tautological by construction. No step claims a derived prediction that reduces to a fitted parameter or self-citation chain; the MLP kernel comparison uses the same invariant as an external baseline, and experiments on SE(2), SO(3), Aff(2) provide independent performance checks. The logarithm-chart assumption is stated explicitly but does not create a definitional loop. The result is self-contained against the supplied group-theoretic definitions.
Axiom & Free-Parameter Ledger
free parameters (2)
- λ (block weights)
- τ (temperature)
axioms (2)
- domain assumption A logarithm chart exists containing the relative poses g_i^{-1} g_j for the groups under study.
- standard math Matrix Lie groups are closed under inversion and the group operation.
Reference graph
Works this paper leans on
-
[1]
N. Thomas et al.Tensor Field Networks: Rotation- and Translation-Equivariant Neural Networks for 3D Point Clouds. arXiv:1802.08219, 2018
Pith/arXiv arXiv 2018
-
[2]
F. B. Fuchs, D. E. Worrall, V. Fischer, M. Welling.SE(3)-Transformers: 3D Roto-Translation Equivariant At- tention Networks. NeurIPS 2020. 18
2020
-
[3]
Y.-L. Liao, T. Smidt.Equiformer: Equivariant Graph Attention Transformer for 3D Atomistic Graphs. arXiv:2206.11990, 2022
arXiv 2022
-
[4]
Y.-L. Liao, A. J. Hoffman, S. C. Shen, A. Duval, S. W. Norwood, T. Smidt.EquiformerV3: Scaling Efficient, Expressive, and General SE(3)-Equivariant Graph Attention Transformers. arXiv:2604.09130, 2026
Pith/arXiv arXiv 2026
-
[5]
Batatia et al.MACE: Higher Order Equivariant Message Passing Neural Networks for Fast and Accurate Force Fields
I. Batatia et al.MACE: Higher Order Equivariant Message Passing Neural Networks for Fast and Accurate Force Fields. NeurIPS 2022
2022
-
[6]
Cohen, M
T. Cohen, M. Welling.Group Equivariant Convolutional Networks. ICML 2016
2016
-
[7]
Weiler, G
M. Weiler, G. Cesa.General E(2)-Equivariant Steerable CNNs. NeurIPS 2019
2019
-
[8]
V. G. Satorras, E. Hoogeboom, M. Welling.E(n) Equivariant Graph Neural Networks. ICML 2021
2021
-
[9]
Brehmer, P
J. Brehmer, P. de Haan, S. Behrends, T. Cohen.Geometric Algebra Transformer. NeurIPS 2023
2023
-
[10]
de Haan, T
P. de Haan, T. Cohen, J. Brehmer.Euclidean, Projective, Conformal: Choosing a Geometric Algebra for Equiv- ariant Transformers. AISTATS 2024
2024
-
[11]
S. Xu, D. Chen, K. Wong, C. Zhang, K. Fallah, R. Urtasun.Efficient Equivariant Transformer for Self-Driving Agent Modeling(DriveGATr). arXiv:2604.01466, 2026
arXiv 2026
-
[12]
G. E. Hinton, S. Sabour, N. Frosst.Matrix Capsules with EM Routing. ICLR 2018
2018
-
[13]
Jaderberg, K
M. Jaderberg, K. Simonyan, A. Zisserman, K. Kavukcuoglu.Spatial Transformer Networks. NeurIPS 2015
2015
-
[14]
Jumper et al.Highly Accurate Protein Structure Prediction with AlphaFold
J. Jumper et al.Highly Accurate Protein Structure Prediction with AlphaFold. Nature 596, 583–589, 2021
2021
-
[15]
N. Funk, J. Urain, J. Carvalho, V. Prasad, G. Chalvatzaki, J. Peters.ActionFlow: Equivariant, Accurate, and Efficient Policies with Spatially Symmetric Flow Matching. arXiv:2409.04576, 2024
arXiv 2024
-
[16]
Hutchinson, C
M. Hutchinson, C. Le Lan, S. Zaidi, E. Dupont, Y. W. Teh, H. Kim.LieTransformer: Equivariant Self-Attention for Lie Groups. ICML 2021
2021
- [17]
-
[18]
E. J. Bekkers, S. Vadgama, R. D. Hesselink et al.Fast, Expressive SE(n) Equivariant Networks Through Weight- Sharing in Position-Orientation Space. ICLR 2024
2024
-
[19]
Mironenco, P
M. Mironenco, P. Forr ´e.Lie Group Decompositions for Equivariant Neural Networks. ICLR 2024
2024
-
[20]
J. Su, Y. Lu, S. Pan, A. Murtadha, B. Wen, Y. Liu.RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv:2104.09864, 2021
Pith/arXiv arXiv 2021
-
[21]
Ji.RiemannFormer: A Framework for Attention in Curved Spaces
Z. Ji.RiemannFormer: A Framework for Attention in Curved Spaces. arXiv:2506.07405, 2025
arXiv 2025
-
[22]
Ostmeier et al.LieRE: Lie Rotational Positional Encodings
S. Ostmeier et al.LieRE: Lie Rotational Positional Encodings. arXiv:2406.10322, 2024
arXiv 2024
- [23]
-
[24]
Howell et al.Clebsch–Gordan Transformer: Fast and Global Equivariant Attention
O. Howell et al.Clebsch–Gordan Transformer: Fast and Global Equivariant Attention. arXiv:2509.24093, 2025
arXiv 2025
-
[25]
J. Fu, Q. Xie, D. Meng, Z. Xu.Vanilla Group Equivariant Vision Transformer: Simple and Effective. arXiv:2602.08047, 2026
arXiv 2026
-
[26]
Y. Zhang, Z. Chen, Y. Liu, Z. Qin, H. Yuan, K. Xu, Y. Yuan, Q. Gu, A. C.-C. Yao.Group Representational Position Encoding. arXiv:2512.07805, 2025
Pith/arXiv arXiv 2025
-
[27]
J. Franc ¸ois, L. Ravera.Toward Manifest Relationality in Transformers via Symmetry Reduction. arXiv:2602.18948, 2026
arXiv 2026
-
[28]
C. Kim, S. Zhao, M. Zhu, T.-Y. Lin, M. Ghaffari.Equivariant Neural Networks for General Linear Symmetries on Lie Algebras(Reductive Lie Neurons). arXiv:2510.22984, 2025
arXiv 2025
-
[29]
P. Hoyos, S. Ubaru, D. Huh, V. Kalantzis, K. L. Clarkson, M. Kilmer, H. Avron, L. Horesh.Group-Algebraic Tensors: Provably-optimal Equivariant Learning and Physical Symmetry Discovery. arXiv:2605.20440, 2026. 19
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.