EXPO-FT: Sample-Efficient Reinforcement Learning Finetuning for Vision-Language-Action Models
Pith reviewed 2026-06-29 22:07 UTC · model grok-4.3
The pith
EXPO-FT finetunes pretrained vision-language-action models with reinforcement learning to reach perfect task success using 19.1 minutes of robot data on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
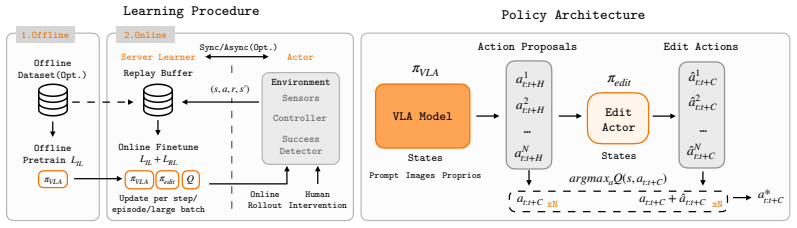
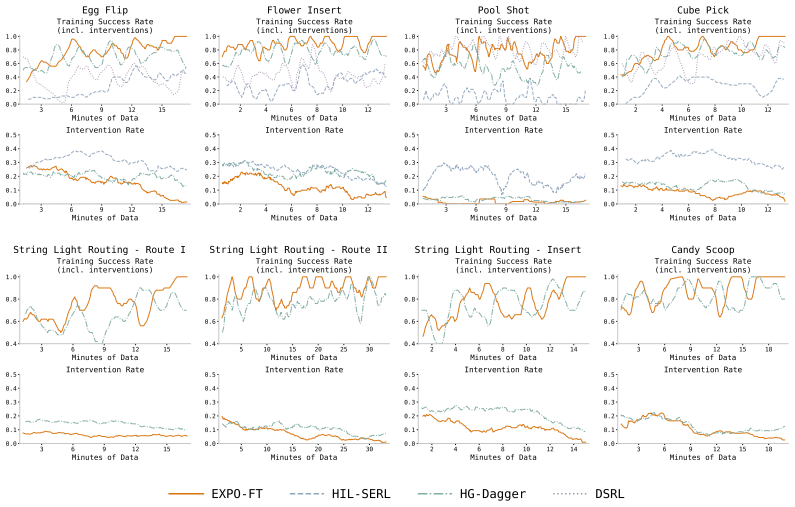
EXPO-FT is a system for stable, sample-efficient RL finetuning of pretrained VLA policies that solves a suite of challenging manipulation tasks, including routing string lights and inserting the plug to light it up, striking a pool ball into a pocket, and inserting a flower into a wine bottle, each requiring combinations of high precision, dynamic actions, and robustness to varied initial states. Our system achieves perfect task performance (30/30 successes) across all evaluated tasks within an average of 19.1 minutes of online robot data, outperforming both prior RL-from-scratch and VLA finetuning approaches.
What carries the argument
EXPO-FT, the system that performs stable reinforcement learning fine-tuning on pretrained vision-language-action policies
If this is right
- Pretrained VLA policies reach perfect success rates on high-precision tasks after limited online interaction.
- The method uses less data than RL trained from scratch while improving on prior VLA finetuning results.
- Tasks that combine dynamic actions with robustness to initial state changes become reliably solvable.
- An open-source release supports wider testing of RL finetuning for VLA models in robotics.
Where Pith is reading between the lines
- The same finetuning pattern could be examined on tasks outside tabletop manipulation, such as mobile navigation or multi-arm coordination.
- If efficiency scales, the approach might reduce the total pretraining data needed by shifting more adaptation burden to short RL stages.
- Testing on hardware with greater sensor noise or longer task horizons would reveal whether the reported data requirements remain stable.
Load-bearing premise
That the EXPO-FT system can deliver the claimed stability and sample efficiency on the described suite of high-precision, dynamic manipulation tasks when applied to pretrained VLA policies.
What would settle it
Recording fewer than 30 successes in 30 trials or requiring substantially more than 19.1 minutes of online data on average for the pool ball striking or flower insertion tasks.
Figures




read the original abstract
The ability to efficiently and reliably learn new tasks has been a foundational challenge in robotics. Vision-Language-Action (VLA) models have demonstrated strong generalization across diverse manipulation tasks, yet pretrained policies consistently fall short of the reliability required for real-world deployment. Reinforcement learning (RL) fine-tuning offers a promising path to bridge this gap, but existing approaches either train from scratch without fully leveraging pretrained priors, or fine-tune VLAs without achieving the sample efficiency and success rates that practical deployment demands. We present EXPO-FT, a system for stable, sample-efficient RL finetuning of pretrained VLA policies that closes this gap. Our system solves a suite of challenging manipulation tasks, including routing string lights and inserting the plug to light it up, striking a pool ball into a pocket, and inserting a flower into a wine bottle, each requiring combinations of high precision, dynamic actions, and robustness to varied initial states. Our system achieves perfect task performance (30/30 successes) across all evaluated tasks within an average of 19.1 minutes of online robot data, outperforming both prior RL-from-scratch and VLA finetuning approaches. We release an open-source codebase with the aim of facilitating broader adoption of RL finetuning of VLA models in robotics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EXPO-FT, a system that augments RL finetuning of pretrained Vision-Language-Action (VLA) policies with an exploration objective, reward shaping, and VLA adaptation procedure. It reports solving a suite of high-precision, dynamic manipulation tasks (routing string lights, striking pool balls, inserting flowers into bottles) to 30/30 success using an average of 19.1 minutes of online robot data per task, outperforming both RL-from-scratch and prior VLA finetuning baselines.
Significance. If the reported outcomes hold under the stated data budgets and task conditions, the work provides a concrete route to reliable real-world deployment of VLAs by addressing stability and sample-efficiency gaps. The open-source codebase release is a clear strength that supports reproducibility and adoption.
minor comments (3)
- The experimental section should explicitly state the number of independent random seeds or rollouts used to compute the 30/30 success rates and any associated variance, to strengthen the stability claim.
- Figure captions and baseline descriptions would benefit from additional detail on hyperparameter matching across methods to ensure fair comparison.
- A short discussion of failure modes or edge cases observed during the 19.1-minute finetuning runs would improve clarity on the method's robustness limits.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of EXPO-FT and for recommending minor revision. We appreciate the recognition that the reported outcomes, if they hold, provide a concrete route to reliable real-world VLA deployment, as well as the value placed on the open-source codebase.
Circularity Check
No significant circularity identified
full rationale
The paper is an empirical robotics contribution describing an RL finetuning system (EXPO-FT) and reporting experimental success rates on manipulation tasks. No derivation chain, first-principles predictions, fitted parameters renamed as outputs, or self-citation load-bearing steps appear in the provided abstract or described method/experimental sections. Claims rest on reported robot trials rather than any definitional or self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
G. R. Team, A. Abdolmaleki, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, A. Bal- akrishna, N. Batchelor, A. Bewley, J. Bingham, M. Bloesch, K. Bousmalis, P. Brakel, A. Bro- han, T. Buschmann, A. Byravan, S. Cabi, K. Caluwaerts, F. Casarini, C. Chan, O. Chang, L. Chappellet-V olpini, J. E. Chen, X. Chen, H.-T. L. Chiang, K. Choromanski, A. Collis...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [3]
- [4]
-
[5]
C. Xu, J. T. Springenberg, M. Equi, A. Amin, A. Esmail, S. Levine, and L. Ke. Rl token: Bootstrapping online rl with vision-language-action models, 2026. URL https://arxiv. org/abs/2604.23073
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [6]
-
[7]
A. Z. Ren, J. Lidard, L. L. Ankile, A. Simeonov, P. Agrawal, A. Majumdar, B. Burchfiel, H. Dai, and M. Simchowitz. Diffusion policy policy optimization. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=mEpqHvbD2h
2025
-
[8]
Steering Your Diffusion Policy with Latent Space Reinforcement Learning
A. Wagenmaker, M. Nakamoto, Y . Zhang, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering your diffusion policy with latent space reinforcement learning, 2025. URL https://arxiv.org/abs/2506.15799. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Y . Li, X. Ma, J. Xu, Y . Cui, Z. Cui, Z. Han, L. Huang, T. Kong, Y . Liu, H. Niu, W. Peng, J. Qiao, Z. Ren, H. Shi, Z. Su, J. Tian, Y . Xiao, S. Zhang, L. Zheng, H. Li, and Y . Wu. Gr- rl: Going dexterous and precise for long-horizon robotic manipulation, 2025. URL https: //arxiv.org/abs/2512.01801
-
[10]
H. Li, Y . Zuo, J. Yu, Y . Zhang, Y . Zhaohui, K. Zhang, X. Zhu, Y . Zhang, T. Chen, G. Cui, D. Wang, D. Luo, Y . Fan, Y . Sun, J. Zeng, J. Pang, S. Zhang, Y . Wang, Y . Mu, B. Zhou, and N. Ding. SimpleVLA-RL: Scaling VLA training via reinforcement learning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openrevie...
2026
- [11]
-
[12]
P. Dong, Q. Li, D. Sadigh, and C. Finn. EXPO: Stable reinforcement learning with expressive policies. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=aFjSjkB6CV
2026
-
[13]
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer. Hg-dagger: Interactive imitation learning with human experts. In2019 International Conference on Robotics and Automation (ICRA), page 8077–8083. IEEE Press, 2019. doi:10.1109/ICRA.2019.8793698. URLhttps://doi.org/10.1109/ICRA.2019.8793698
-
[14]
Soft Actor-Critic Algorithms and Applications
T. Haarnoja, A. Zhou, K. Hartikainen, G. Tucker, S. Ha, J. Tan, V . Kumar, H. Zhu, A. Gupta, P. Abbeel, et al. Soft actor-critic algorithms and applications.arXiv preprint arXiv:1812.05905, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Kalashnikov, A
D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakr- ishnan, V . Vanhoucke, et al. Scalable deep reinforcement learning for vision-based robotic manipulation. InConference on robot learning, pages 651–673. PMLR, 2018
2018
-
[16]
Levine, C
S. Levine, C. Finn, T. Darrell, and P. Abbeel. End-to-end training of deep visuomotor policies. Journal of Machine Learning Research, 17(39):1–40, 2016. URLhttp://jmlr.org/papers/ v17/15-522.html
2016
-
[17]
M. Kalakrishnan, L. Righetti, P. Pastor, and S. Schaal. Learning force control policies for compliant manipulation. In2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 4639–4644, 2011. doi:10.1109/IROS.2011.6095096
-
[18]
M. P. Deisenroth, C. E. Rasmussen, and D. Fox. Learning to control a low-cost manipulator using data-efficient reinforcement learning. In H. Durrant-Whyte, N. Roy, and P. Abbeel, editors,Robotics: Science and Systems VII. The MIT Press, 06 2012. ISBN 9780262305969. doi:10.7551/mitpress/9481.003.0013. URL https://doi.org/10.7551/mitpress/9481. 003.0013
-
[19]
T. C. Kietzmann and M. A. Riedmiller. The neuro slot car racer: Reinforcement learning in a real world setting.2009 International Conference on Machine Learning and Applications, pages 311–316, 2009. URLhttps://api.semanticscholar.org/CorpusID:17199272
2009
-
[20]
J. Kober, K. Mülling, O. Krömer, C. H. Lampert, B. Schölkopf, and J. Peters. Movement templates for learning of hitting and batting. In2010 IEEE International Conference on Robotics and Automation, pages 853–858, 2010. doi:10.1109/ROBOT.2010.5509672
-
[21]
Review of energy-efficient train control and timetabling
J. Peters and S. Schaal. Reinforcement learning of motor skills with policy gradients. Neural Networks, 21(4):682–697, 2008. ISSN 0893-6080. doi:https://doi.org/10.1016/j. neunet.2008.02.003. URL https://www.sciencedirect.com/science/article/pii/ S0893608008000701. Robotics and Neuroscience. 12
work page doi:10.1016/j 2008
-
[22]
P. J. Ball, L. Smith, I. Kostrikov, and S. Levine. Efficient online reinforcement learning with offline data. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[23]
P. Dong, A. M. Lessing, A. S. Chen, and C. Finn. Reinforcement learning via implicit imitation guidance, 2026. URLhttps://openreview.net/forum?id=CgupPwA40q
2026
-
[24]
X. Chen, C. Wang, Z. Zhou, and K. W. Ross. Randomized ensembled double q-learning: Learning fast without a model. InInternational Conference on Learning Representations, 2021. URLhttps://openreview.net/forum?id=AY8zfZm0tDd
2021
- [25]
- [26]
-
[27]
J. Luo, P. Dong, Y . Zhai, Y . Ma, and S. Levine. Rlif: Interactive imitation learning as rein- forcement learning. In B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, editors,International Conference on Learning Representations, volume 2024, pages 36329– 36351, 2024. URL https://proceedings.iclr.cc/paper_files/paper/2024/file/ 9c53788...
2024
-
[28]
P. Dong, S. Mirchandani, D. Sadigh, and C. Finn. What matters for batch online reinforcement learning in robotics? InThe Fourteenth International Conference on Learning Representations,
-
[29]
URLhttps://openreview.net/forum?id=usw1NVkczu
- [30]
- [31]
-
[32]
P. Dong, A. Swerdlow, D. Sadigh, and C. Finn. Faster: Value-guided sampling for fast rl, 2026. URLhttps://arxiv.org/abs/2604.19730
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Psenka, A
M. Psenka, A. Escontrela, P. Abbeel, and Y . Ma. Learning a diffusion model policy from rewards via q-score matching, 2024. URLhttps://openreview.net/forum?id=StkLULT1i1
2024
-
[34]
Li and S
Q. Li and S. Levine. Q-learning with adjoint matching. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=vd4eNAdtO6
2026
-
[35]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, D. Driess, M. Equi, A. Esmail, Y . Fang, C. Finn, C. Glossop, T. Godden, I. Goryachev, L. Groom, H. Hancock, K. Hausman, G. Hussein, B. Ichter, S. Jakubczak, R. Jen, T. Jones, B. Katz, L. Ke, C. Kuchi, M. Lamb, D. LeBlanc, S. Levin...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
J. Liu, F. Gao, B. Wei, X. Chen, Q. Liao, Y . Wu, C. Yu, and Y . Wang. What can RL bring to VLA generalization? an empirical study. InThe Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems, 2026. URLhttps://openreview.net/forum?id=qmBMPInbZC. 13
2026
-
[37]
S. Tan, K. Dou, Y . Zhao, and P. Krähenbühl. Interactive post-training for vision-language-action models, 2025. URLhttps://arxiv.org/abs/2505.17016
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
G. Lu, W. Guo, C. Zhang, Y . Zhou, H. Jiang, Z. Gao, Y . Tang, and Z. Wang. Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning, 2025. URL https://arxiv.org/abs/2505.18719
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [39]
-
[40]
Y . Guo, J. Zhang, X. Chen, X. Ji, Y .-J. Wang, Y . Hu, and J. Chen. Improving vision- language-action model with online reinforcement learning.2025 IEEE International Con- ference on Robotics and Automation (ICRA), pages 15665–15672, 2025. URL https: //api.semanticscholar.org/CorpusID:275932066
2025
-
[41]
W. Xiao, H. Lin, A. Peng, H. Xue, T. He, Z. Luo, Y . Xie, F. Hu, L. Fan, G. Shi, and Y . Zhu. Self-improving vision-language-action models with data generation via residual RL. InThe Fourteenth International Conference on Learning Representations, 2026. URL https:// openreview.net/forum?id=eUGoqrZ6Ea
2026
-
[42]
X. Yuan, T. Mu, S. Tao, Y . Fang, M. Zhang, and H. Su. Policy decorator: Model-agnostic online refinement for large policy model. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=e5jGTEiJMT
2025
-
[43]
Zhang, C
Y . Zhang, C. Wang, ouyang lu, Y . Zhao, Y . Ge, Z. Sun, X. Li, C. Zhang, C. Bai, and X. Li. Align-then-steer: Adapting the vision-language action models through unified latent guidance. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps: //openreview.net/forum?id=T3i7Ifeatk
2026
-
[44]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition, 2015. URL https://arxiv.org/abs/1512.03385
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[45]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In G. Gordon, D. Dunson, and M. Dudík, editors,Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 of Proceedings of Machine Learning Research, pages 627–635, Fort Lauderdale,...
2011
-
[46]
Dong, K.-H
P. Dong, K.-H. Hung, A. Swerdlow, D. Sadigh, and C. Finn. Tql: Scaling q-functions with transformers by preventing attention collapse, 2026. URL https://arxiv.org/abs/2602. 01439
2026
-
[47]
P. Dong, C. Zheng, C. Finn, D. Sadigh, and B. Eysenbach. Value flows, 2026. URL https: //arxiv.org/abs/2510.07650
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
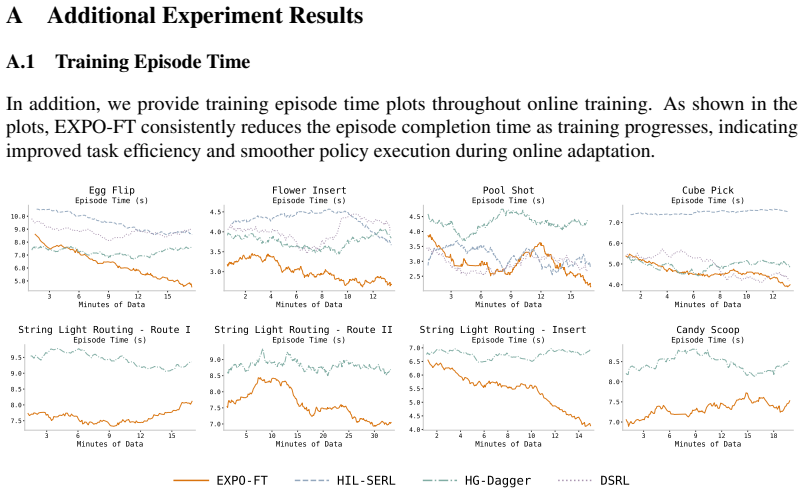
E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=nZeVKeeFYf9. 14 A Additional Experiment Results A.1 Training Episode Time In addition, we provide training episode time p...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.