HistoRAG: Embedding Historical Methodology in Retrieval-Augmented Generation Through Critical Technical Practice
Pith reviewed 2026-06-27 00:23 UTC · model grok-4.3
The pith
HistoRAG adapts retrieval-augmented generation to historical methodology by separating retrieval from generation, enforcing temporal balance, and using contestable LLM relevance judgments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Separated retrieval and generation, temporal windowing, and LLM-as-judge evaluation together embed historiographical requirements into RAG so that source selection reflects the need for balanced representation across eras, relevance judgments remain transparent, and keyword and semantic methods can complement each other under a shared filter; evaluation on the Der Spiegel corpus shows these changes correct measurable skews and low correlations that standard RAG exhibits.
What carries the argument
HistoRAG framework that decouples retrieval from generation, applies temporal windowing to enforce period balance, and inserts an LLM-as-judge layer for contestable relevance scoring, together with the Zwischentexte category for intermediate interpretive texts.
If this is right
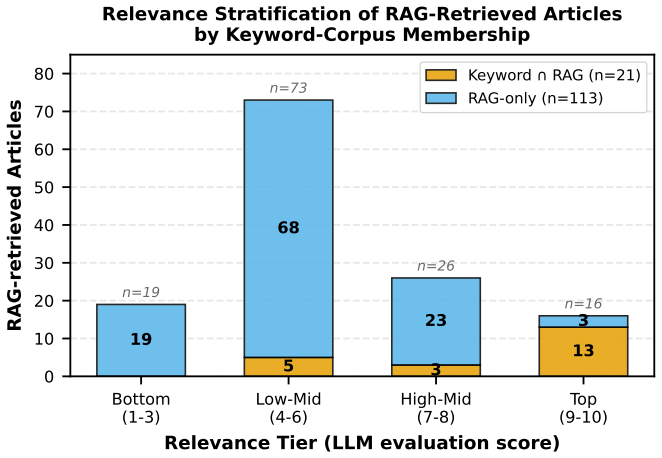
- Keyword and semantic retrieval surface largely disjoint pools of sources, so both must run in parallel before the LLM judge filters them.
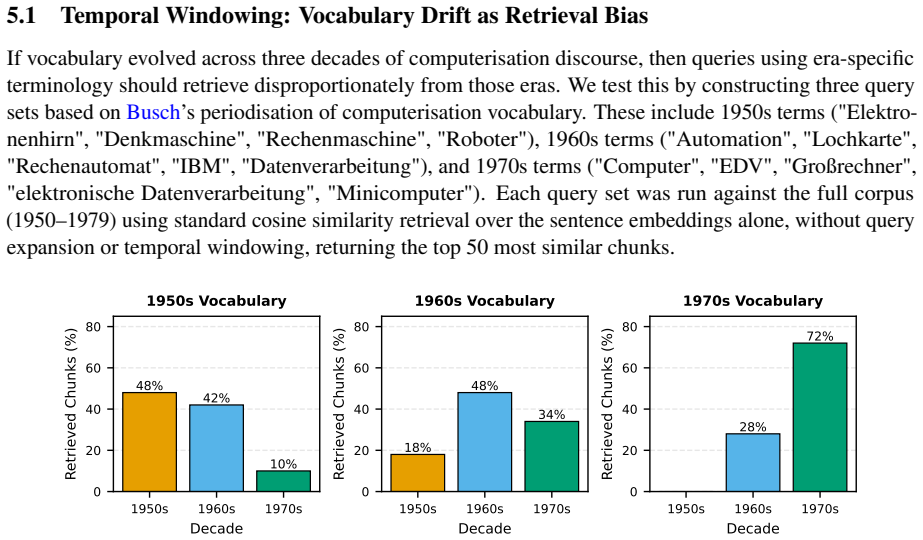
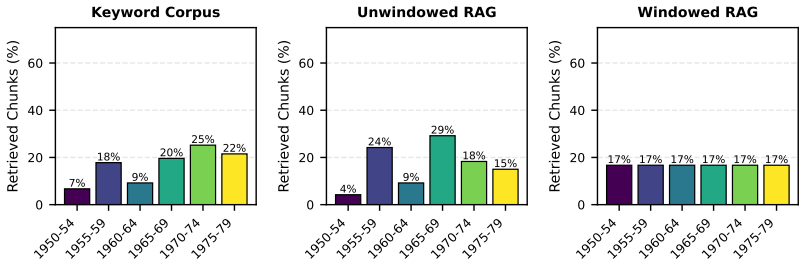
- Era-specific terminology can retrieve zero relevant chunks from earlier decades, so temporal windowing is required to prevent systematic omission.
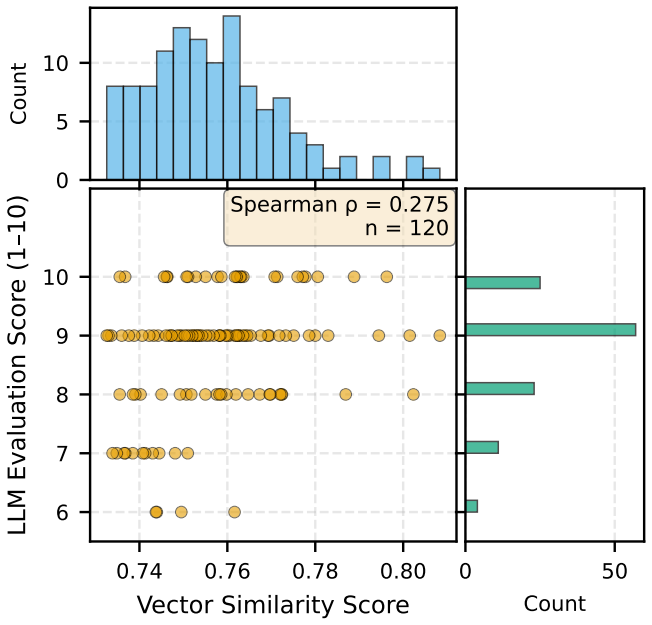
- Vector similarity and LLM-assessed relevance correlate only weakly, so post-retrieval evaluation cannot be skipped without losing contestability.
- The resulting architecture supplies a reusable pattern for turning domain epistemological commitments into RAG design choices.
- Zwischentexte provide a defined role for generated text that keeps it distinct from final scholarly claims.
Where Pith is reading between the lines
- The same three interventions could be tested on corpora from other interpretive fields such as literary studies or legal history to check transfer.
- If the weak similarity-relevance correlation holds beyond this corpus, many current RAG pipelines may systematically undervalue relevant historical material.
- Future evaluations could measure whether historians using HistoRAG produce different source selections or arguments than those using baseline RAG.
Load-bearing premise
That the three interventions fix the specific deficiencies observed in the Der Spiegel evaluation and thereby align RAG with historical methodology in general.
What would settle it
A run on the same Der Spiegel corpus in which temporal windowing produces no increase in retrieved chunks from the 1950s relative to an unwindowed baseline.
Figures

read the original abstract
Retrieval-Augmented Generation (RAG) is the prevailing architecture for grounding language model outputs in external evidence, yet its dominant evaluation paradigms and default configurations remain oriented toward factual question-answering. For interpretive disciplines such as historical studies, RAG embeds assumptions that conflict with scholarly practice. We introduce HistoRAG, a framework that translates historiographical principles into concrete architectural interventions. Separated retrieval and generation decouples source discovery from interpretation, temporal windowing enforces balanced source representation across the research period as a methodological requirement of historical inquiry, and LLM-as-judge evaluation makes relevance judgments transparent and contestable. We evaluate these interventions using SPIEGELragged, applied to 102,189 articles from Der Spiegel (1950-1979). Each intervention addresses a measurable deficiency in standard RAG: era-specific vocabulary retrieves zero chunks from the 1950s when using 1970s terminology, evidence of the temporal skew that motivates windowing; vector similarity and LLM-assessed relevance correlate only weakly (Spearman rho = 0.275), motivating post-retrieval evaluation; and keyword-based and semantic retrieval surface largely disjoint source pools, motivating an architecture in which both operate as complementary retrieval layers under a shared LLM evaluation filter. We also introduce the concept of Zwischentexte (intermediate texts that function as interpretive proposals rather than findings) as a framework for responsible integration of LLM-generated text into scholarly practice. The architecture offers a model for how domain-specific epistemological commitments can be translated into RAG design decisions, and may transfer to other interpretive disciplines working with large corpora.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HistoRAG, a framework translating historiographical principles into RAG architecture via three interventions: separated retrieval and generation, temporal windowing to enforce balanced source representation, and LLM-as-judge evaluation for transparent relevance judgments. Using the SPIEGELragged evaluation on 102,189 Der Spiegel articles (1950-1979), it documents deficiencies in standard RAG such as zero 1950s chunks retrieved under 1970s queries, weak correlation (Spearman rho=0.275) between vector similarity and LLM relevance, and largely disjoint keyword vs. semantic retrieval pools. It also proposes Zwischentexte as intermediate interpretive texts and positions the work as a model for domain-specific epistemological commitments in RAG design.
Significance. If the interventions demonstrably improve historian-rated fidelity and reduce anachronism relative to baseline RAG, the paper would supply a concrete, transferable template for adapting retrieval systems to interpretive fields. The explicit mapping from historiographical commitments to architectural choices and the introduction of Zwischentexte are constructive contributions, but the absence of comparative outcome data currently limits the strength of the central claim.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation description: the manuscript reports concrete deficiencies (zero 1950s chunks, rho=0.275, disjoint pools) but supplies no comparative results quantifying whether the three interventions improve historian-rated fidelity, reduce anachronism, or increase coverage relative to standard RAG on the same corpus.
- [Abstract] Abstract: evaluation outcomes (zero chunks, Spearman rho) are stated without accompanying methods details on dataset construction rules, query formulation, statistical tests, or error bars, making it impossible to assess whether the reported numbers support the claimed deficiencies.
minor comments (1)
- [Abstract] The term 'Zwischentexte' is introduced without a formal definition or example in the provided text; a short illustrative passage would clarify its intended role.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We address each major comment below, providing clarifications on the scope of the current evaluation while acknowledging limitations in the presented evidence.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation description: the manuscript reports concrete deficiencies (zero 1950s chunks, rho=0.275, disjoint pools) but supplies no comparative results quantifying whether the three interventions improve historian-rated fidelity, reduce anachronism, or increase coverage relative to standard RAG on the same corpus.
Authors: The manuscript's evaluation section quantifies measurable deficiencies in standard RAG (temporal skew, weak similarity-relevance correlation, and disjoint retrieval pools) that directly conflict with historiographical requirements for balanced representation and contestable relevance. These findings motivate the three interventions, but we do not present comparative results from historian evaluations of output fidelity or anachronism reduction under HistoRAG versus baseline RAG. Such a study would require expert annotation at scale and is outside the current scope, which centers on mapping epistemological commitments to architecture and documenting the baseline problems via SPIEGELragged. We agree this limits the strength of claims about improvement and plan to pursue it in follow-on work. revision: no
-
Referee: [Abstract] Abstract: evaluation outcomes (zero chunks, Spearman rho) are stated without accompanying methods details on dataset construction rules, query formulation, statistical tests, or error bars, making it impossible to assess whether the reported numbers support the claimed deficiencies.
Authors: The abstract summarizes key quantitative findings from the SPIEGELragged evaluation on the 102,189-article Der Spiegel corpus. Full details on dataset construction (temporal coverage 1950-1979, article selection criteria), query formulation, retrieval configurations, Spearman rank correlation computation, and any associated statistical measures appear in the Methods and Evaluation sections of the full manuscript. We will revise the abstract to include an explicit pointer to these sections. revision: partial
- Absence of comparative results from historian-rated evaluations quantifying whether the HistoRAG interventions improve fidelity, reduce anachronism, or increase coverage relative to standard RAG.
Circularity Check
No circularity; conceptual mapping without derivations or self-referential reductions
full rationale
The paper presents HistoRAG as a direct translation of stated historiographical principles into three RAG interventions (separated retrieval/generation, temporal windowing, LLM-as-judge). No equations, fitted parameters, or predictive derivations exist. Deficiencies in standard RAG are shown via corpus statistics (zero 1950s chunks, Spearman rho=0.275, disjoint pools), but these motivate the design rather than serving as inputs that the outputs reduce to by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing. The framework is self-contained as an architectural proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Historiographical principles such as balanced temporal representation can be directly encoded as RAG architectural constraints
invented entities (1)
-
Zwischentexte
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Philip E. Agre. 1998. Toward a Critical Technical Practice : Lessons Learned in Trying to Reform AI . In Social Science , Technical Systems , and Cooperative Work . Psychology Press
1998
-
[2]
Lameck Mbangula Amugongo, Pietro Mascheroni, Steven Brooks, Stefan Doering, and Jan Seidel. 2025. https://doi.org/10.1371/journal.pdig.0000877 Retrieval augmented generation for large language models in healthcare: A systematic review . PLOS Digital Health, 4(6):e0000877
-
[3]
Michelle Barker, Neil P. Chue Hong, Daniel S. Katz, and 1 others. 2022. https://doi.org/10.1038/s41597-022-01710-x Introducing the FAIR Principles for research software . Scientific Data, 9(1):622
-
[4]
Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2017. https://doi.org/10.1162/tacl_a_00051 Enriching word vectors with subword information . Transactions of the Association for Computational Linguistics, 5:135--146
-
[5]
Simon Brausch and Gerd Gra hoff. 2023. https://doi.org/10.1002/fhu2.6 Machine learning for the history of ideas . Future Humanities, 1(1):e6
-
[6]
Albert Busch. 2015. https://doi.org/10.1515/9783110910681 Diskurslexikologie und Sprachgeschichte der Computertechnologie . Max Niemeyer Verlag
-
[7]
Bodong Chen. 2025. https://doi.org/10.48550/arXiv.2504.06928 Beyond Tools : Generative AI as Epistemic Infrastructure in Education . Preprint, arXiv:2504.06928
-
[8]
Der Spiegel . 1978. >>Uns steht eine Katastrophe bevor<< . Der Spiegel
1978
-
[9]
Hans Magnus Enzensberger. 1962. Einzelheiten. 1: Bewu tseins-Industrie / Hans Magnus Enzensberger , 1. auflage edition. Number 63 in Edition Suhrkamp . Suhrkamp Verlag, Frankfurt am Main
1962
-
[10]
Andreas Fickers and Juliane Tatarinov, editors. 2022. https://doi.org/10.1515/9783110723991 Digital History and Hermeneutics : Between Theory and Practice . De Gruyter
-
[11]
uge Einer Philosophischen Hermeneutik . J.C.B. Mohr (Paul Siebeck), T\
Hans-Georg Gadamer. 1960. Wahrheit Und Methode Grundz\"uge Einer Philosophischen Hermeneutik . J.C.B. Mohr (Paul Siebeck), T\"ubingen
1960
-
[12]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. 2024. https://arxiv.org/abs/2312.10997 Retrieval- Augmented Generation for Large Language Models : A Survey . Preprint, arXiv:2312.10997
Pith/arXiv arXiv 2024
-
[13]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. 2024. https://doi.org/10.48550/ARXIV.2411.15594 A Survey on LLM-as-a-Judge . arXiv preprint arXiv:2411.15594
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.15594 2024
-
[14]
Hamilton, Jure Leskovec, and Dan Jurafsky
William L. Hamilton, Jure Leskovec, and Dan Jurafsky. 2016. https://doi.org/10.18653/v1/P16-1141 Diachronic word embeddings reveal statistical laws of semantic change . In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1489--1501, Berlin, Germany. Association for Computational Linguistics
-
[15]
Torsten Hiltmann. 2024. Hermeneutik in Zeiten der KI: Large Language Models als hermeneutische Instrumente in den Geschichtswissenschaften . In Gerhard Schreiber and Lukas Ohly, editors, KI:Text: Diskurse \"uber KI-Textgeneratoren , pages 201--232. De Gruyter
2024
-
[16]
Torsten Hiltmann, Jan Keupp, Melanie Althage, and Philipp Schneider. 2021. https://doi.org/10.13109/gege.2021.47.1.122 Digital Methods in Practice: The Epistemological Implications of Applying Text Re-Use Analysis to the Bloody Accounts of the Conquest of Jerusalem (1099) . Geschichte und Gesellschaft, 47(1):122--156
-
[17]
Simon David Hirsbrunner, Michael Tebbe, and Claudia M \"u ller-Birn . 2024. https://doi.org/10.1177/13548565221132243 From critical technical practice to reflexive data science . Convergence, 30(1):190--215
-
[18]
Yizheng Huang and Jimmy Huang. 2024. https://doi.org/10.48550/arXiv.2404.10981 A Survey on Retrieval-Augmented Text Generation for Large Language Models . Preprint, arXiv:2404.10981
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.10981 2024
-
[19]
Wei, Roy Jiang, Leah Colucci, Eric Lai, Amisha Dave, Tuo Guo, and 8 others
Hyunjae Kim, Jiwoong Sohn, Aidan Gilson, Nicholas Cochran-Caggiano, Serina Applebaum, Heeju Jin, Seihee Park, Yujin Park, Jiyeong Park, Seoyoung Choi, Brittany Alexandra Herrera Contreras, Thomas Huang, Jaehoon Yun, Ethan F. Wei, Roy Jiang, Leah Colucci, Eric Lai, Amisha Dave, Tuo Guo, and 8 others. 2025. https://arxiv.org/abs/2511.06738 Rethinking retrie...
arXiv 2025
-
[20]
Andrey Kutuzov, Lilja vrelid, Terrence Szymanski, and Erik Velldal. 2018. Diachronic word embeddings and semantic shifts: A survey. In Proceedings of the 27th International Conference on Computational Linguistics, pages 1384--1397, Santa Fe, New Mexico, USA. Association for Computational Linguistics
2018
-
[21]
Jeong Ha Lee, Ghazanfar Ali, and Jae-In Hwang. 2025. https://doi.org/10.1002/cav.70048 A Retrieval-Augmented Generation System for Accurate and Contextual Historical Analysis : AI-Agent for the Annals of the Joseon Dynasty . Computer Animation and Virtual Worlds, 36(4):e70048
-
[22]
Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Kuttler, M
Patrick Lewis, Ethan Perez, Aleksandara Piktus, F. Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Kuttler, M. Lewis, Wen-tau Yih, Tim Rockt \"a schel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval- Augmented Generation for Knowledge-Intensive NLP Tasks . ArXiv
2020
-
[23]
Michael J. Maclean. 1982. https://doi.org/10.2307/2505095 Johann Gustav Droysen and the Development of Historical Hermeneutics . History and Theory, 21(3):347--365
-
[24]
Varun Magesh, Faiz Surani, Matthew Dahl, Mirac Suzgun, Christopher D. Manning, and Daniel E. Ho. 2025. https://doi.org/10.1111/jels.12413 Hallucination- Free ? Assessing the Reliability of Leading AI Legal Research Tools . Journal of Empirical Legal Studies, 22(2):216--242
-
[25]
Robert C. Martin. 2003. Agile Software Development: Principles, Patterns, and Practices . Prentice Hall, Upper Saddle River, NJ
2003
-
[26]
Bhuvanashree Murugadoss, Christian Poelitz, Ian Drosos, Vu Le, Nick McKenna, Carina Suzana Negreanu, Chris Parnin, and Advait Sarkar. 2024. https://doi.org/10.48550/arXiv.2408.08781 Evaluating the Evaluator : Measuring LLMs ' Adherence to Task Evaluation Instructions . Preprint, arXiv:2408.08781
-
[27]
Keerthana Murugaraj, Salima Lamsiyah, Marten During, and Martin Theobald. 2025. https://doi.org/10.1017/chr.2025.10018 Topic- RAG for historical newspapers: Enhancing information retrieval in humanities research through topic-based retrieval-augmented generation . Computational Humanities Research, 1:e15
-
[28]
Rodrigo Nogueira and Kyunghyun Cho. 2020. https://doi.org/10.48550/arXiv.1901.04085 Passage Re-ranking with BERT . Preprint, arXiv:1901.04085
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1901.04085 2020
-
[29]
Zach Nussbaum and Brandon Duderstadt. 2025. https://doi.org/10.48550/arXiv.2502.07972 Training Sparse Mixture Of Experts Text Embedding Models . Preprint, arXiv:2502.07972
-
[30]
Nomic Embed: Training a Reproducible Long Context Text Embedder
Zach Nussbaum, John X. Morris, Brandon Duderstadt, and Andriy Mulyar. 2025. https://doi.org/10.48550/arXiv.2402.01613 Nomic Embed : Training a Reproducible Long Context Text Embedder . Preprint, arXiv:2402.01613
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.01613 2025
-
[31]
Geoffrey Rockwell and St \'e fan Sinclair. 2016. Hermeneutica: Computer-Assisted Interpretation in the Humanities. The MIT Press, Cambridge, MA
2016
-
[32]
Martin Schmitt, Julia Erdogan, Thomas Kasper, and Janine Funke. 2016. https://doi.org/10.5771/0040-117X-2016-1-33 Digitalgeschichte Deutschlands -- ein Forschungsbericht . Technikgeschichte, 82(1):33--70
-
[33]
Annette Schuhmann. 2012. https://doi.org/10.14765/zzf.dok-1596 Der Traum vom perfekten Unternehmen. Die Computerisierung der Arbeitswelt in der Bundesrepublik Deutschland (1950er- bis 1980er-Jahre) . Zeithistorische Forschungen/Studies in Contemporary History, 9(2):231--256
-
[34]
Silke Schwandt. 2018. Digitale Methoden für die Historische Semantik. Auf den Spuren von Begriffen in digitalen Korpora . Geschichte und Gesellschaft, 44:107--134
2018
-
[35]
J. Ronald Shearer. 1995. https://arxiv.org/abs/4546550 Talking about Efficiency : Politics and the Industrial Rationalization Movement in the Weimar Republic . Central European History, 28(4):483--506
arXiv 1995
-
[36]
Nivedita Shinde, Sophia Kirstein, Souvick Ghosh, and Patricia Franks. 2025. https://doi.org/10.1002/pra2.1286 Tracing the past, predicting the future: A systematic review of AI in archival science . Proceedings of the Association for Information Science and Technology, 62(1)
-
[37]
Arno Simons, Michael Zichert, and Adrian W \"u thrich. 2025. https://doi.org/10.48550/arXiv.2506.12242 Large Language Models for History , Philosophy , and Sociology of Science : Interpretive Uses , Methodological Challenges , and Critical Perspectives . Preprint, arXiv:2506.12242
-
[38]
Leif Weatherby. 2025. https://arxiv.org/abs/10.5749/jj.20753050 Language Machines : Cultural AI and the End of Remainder Humanism . University of Minnesota Press
-
[39]
Thomas Welskopp. 2008. Historische Erkenntnis . In Geschichte: Studium, Wissenschaft, Beruf , Akademie Studienb\"ucher, Geschichte . Akademie-Verlag, Berlin
2008
-
[40]
Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli. 2025. https://doi.org/10.48550/arXiv.2401.11817 Hallucination is Inevitable : An Innate Limitation of Large Language Models . Preprint, arXiv:2401.11817
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.11817 2025
-
[41]
Kisung You. 2025. https://doi.org/10.48550/arXiv.2504.16318 Semantics at an Angle : When Cosine Similarity Works Until It Doesn 't . Preprint, arXiv:2504.16318
-
[42]
Jing Zhou, Li Si, and Wenjun Hou. 2025. https://doi.org/10.1002/pra2.1529 Humanities-in-the- Loop : Using Close Reading as a Method for Retrieval-Augmented Generation ( RAG ) . Proceedings of the Association for Information Science and Technology, 62(1):1747--1749
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.