Bridging the Gap: Enabling Soft Actor Critic for High Performance Legged Locomotion
Pith reviewed 2026-06-30 00:51 UTC · model grok-4.3
The pith
Targeted fixes to policy initialization, critic targets, and return estimation let SAC match PPO in parallel legged robot training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
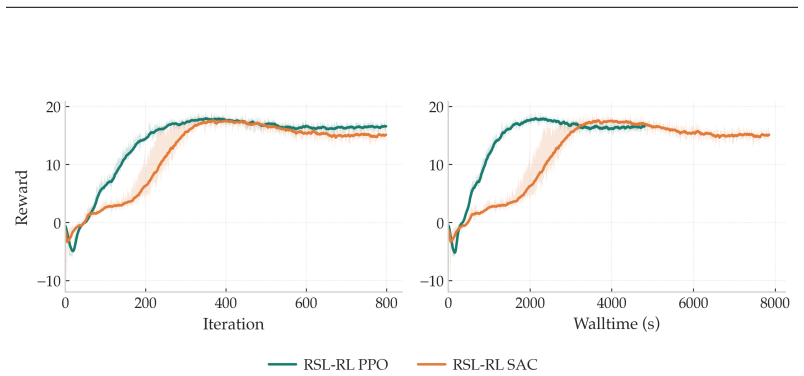
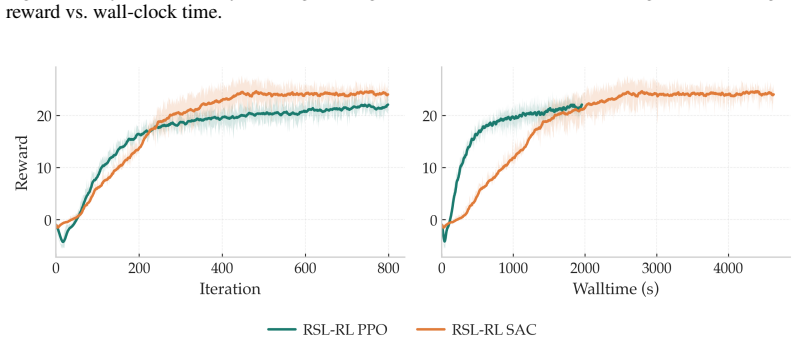
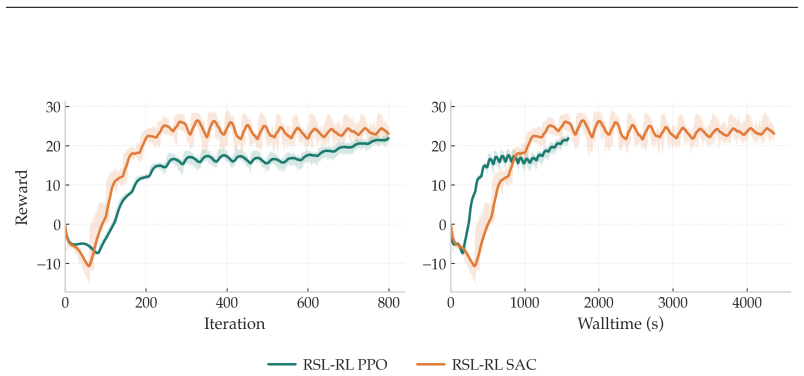
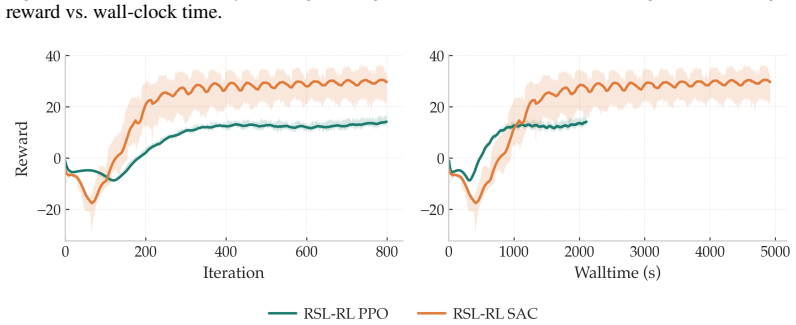
Modifications covering policy initialization, timeout-aware critic targets, and multi-step return estimation enable SAC to train stably at scale in massively parallel environments. When tested across multiple legged robot platforms and diverse locomotion tasks, the adjusted SAC closes the performance gap with PPO entirely.
What carries the argument
The three targeted modifications—policy initialization, timeout-aware critic targets, and multi-step return estimation—that together stabilize off-policy SAC training in massively parallel simulation for legged locomotion.
If this is right
- The same algorithm can now handle both large-scale simulation pre-training and continuous online adaptation on real robots.
- Sample reuse becomes available for legged locomotion without sacrificing final task performance.
- Training stability at scale is achieved for off-policy methods in environments previously dominated by on-policy algorithms.
- The approach applies across different robot morphologies and locomotion objectives without platform-specific retuning.
Where Pith is reading between the lines
- Sim-to-real pipelines could run the identical learner from simulation through hardware deployment, removing the need to switch algorithms mid-process.
- The performance difference between on-policy and off-policy methods in parallel settings appears driven by implementation details rather than a fundamental limitation.
- Similar adjustments to initialization and return estimation may improve other off-policy algorithms when scaled to thousands of parallel environments.
Load-bearing premise
The three identified issues are the primary reasons SAC previously underperformed PPO, and the fixes resolve them without introducing new errors that would prevent equivalent results.
What would settle it
Training the modified SAC in the same IsaacLab parallel setup on the reported robot platforms and tasks and checking whether reward curves and final locomotion performance match those of PPO without extra per-task tuning.
Figures


read the original abstract
Proximal Policy Optimization (PPO) has become the de facto standard for training legged robots, thanks to its robustness and scalability in massively parallel simulation environments like IsaacLab. However, its on-policy nature makes it inherently sample-inefficient, preventing its use for continuous adaptation and fine-tuning on real hardware. Soft Actor-Critic (SAC), by contrast, is an off-policy algorithm that can reuse past experience, making it a natural candidate for sim-to-real transfer workflows where the same algorithm can be used both in simulation and for online learning on the real robot. Despite these advantages, SAC has consistently failed to match PPO's empirical performance in massively parallel training settings. This work identifies the root causes of this gap and introduces targeted modifications, covering policy initialization, timeout-aware critic targets, and multi-step return estimation, that enable SAC to train stably at scale. Evaluated across multiple legged robot platforms and diverse locomotion tasks, our approach closes the performance gap with PPO entirely.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies three root causes for SAC underperforming PPO in massively parallel IsaacLab settings for legged locomotion—policy initialization, timeout-aware critic targets, and multi-step return estimation—and introduces targeted modifications to SAC. It claims these changes enable stable training at scale and close the performance gap with PPO entirely, as demonstrated across multiple legged robot platforms and diverse locomotion tasks.
Significance. If the empirical results and ablations hold, the work would be significant for robotics by making off-policy methods like SAC viable for high-performance parallel simulation training of legged robots. This could enable sample-efficient workflows, continuous adaptation, and unified sim-to-real pipelines that are incompatible with on-policy PPO.
major comments (2)
- [Abstract] Abstract: The central claim that the modifications 'close the performance gap with PPO entirely' is unsupported by any quantitative results, ablation studies, error bars, or statistical comparisons. This is load-bearing for the headline assertion that the three identified factors are the primary causes and that the fixes resolve them without compensating errors or platform-specific tuning.
- [Methods/Results] Methods/Results (implied by abstract framing): No details are supplied on how the root causes were isolated (e.g., controlled experiments isolating initialization vs. timeout handling vs. multi-step returns), nor on whether ablations confirm each component is necessary versus other implementation factors such as reward scaling or parallel environment handling.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical support. We agree that the claims require additional quantitative backing, ablation studies, and details on root-cause isolation. We will revise the manuscript to incorporate these elements while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the modifications 'close the performance gap with PPO entirely' is unsupported by any quantitative results, ablation studies, error bars, or statistical comparisons. This is load-bearing for the headline assertion that the three identified factors are the primary causes and that the fixes resolve them without compensating errors or platform-specific tuning.
Authors: We acknowledge that the abstract's strong claim must be supported by explicit quantitative evidence. The manuscript reports performance matching across multiple platforms and tasks, but we agree that error bars, statistical tests, and direct quantitative comparisons are needed to substantiate 'entirely' closing the gap without platform-specific effects. In revision we will add multi-seed results with standard deviations, statistical significance metrics, and expanded tables/figures quantifying the performance equivalence. revision: yes
-
Referee: [Methods/Results] Methods/Results (implied by abstract framing): No details are supplied on how the root causes were isolated (e.g., controlled experiments isolating initialization vs. timeout handling vs. multi-step returns), nor on whether ablations confirm each component is necessary versus other implementation factors such as reward scaling or parallel environment handling.
Authors: The root causes were identified through systematic debugging in the massively parallel setting, but the manuscript does not present the controlled isolation experiments or full ablation suite. We will add a new subsection with targeted ablations that disable each modification individually while holding other factors fixed, plus controls for reward scaling and environment parallelism. This will confirm necessity and rule out compensating errors. revision: yes
Circularity Check
No circularity: empirical identification and fixes with external benchmarks
full rationale
The paper is framed as an empirical study that identifies root causes for SAC underperformance in massively parallel settings and introduces targeted modifications (policy initialization, timeout-aware critic targets, multi-step returns). No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Claims rest on experimental evaluation across multiple legged robot platforms and tasks, which are external benchmarks. This is self-contained against those benchmarks with no reduction of any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Massively parallel simulation environments like IsaacLab are representative of the conditions under which legged locomotion policies must be trained and transferred.
Reference graph
Works this paper leans on
-
[1]
Marc G Bellemare, Will Dabney, and R ´emi Munos
URLhttps://arxiv.org/abs/2602.20220. Marc G Bellemare, Will Dabney, and R ´emi Munos. A distributional perspective on reinforcement learning. InInternational Conference on Machine Learning,
-
[2]
Exploration by Random Network Distillation
URLhttps://arxiv.org/abs/1810.12894. Xuxin Cheng, Kexin Shi, Ananye Agarwal, and Deepak Pathak. Extreme parkour with legged robots. In2024 IEEE International Conference on Robotics and Automation (ICRA),
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Simplifying deep temporal difference learning.arXiv preprint arXiv:2407.04811,
Matteo Gallici, Mattie Fellows, Benjamin Ellis, Bartomeu Pou, Ivan Masmitja, Jakob Nicolaus Foerster, and Mario Martin. Simplifying deep temporal difference learning.arXiv preprint arXiv:2407.04811,
-
[4]
Soft Actor-Critic Algorithms and Applications
Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, et al. Soft actor-critic algorithms and appli- cations.arXiv preprint arXiv:1812.05905,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
URLhttps://arxiv. org/abs/2504.16680. Zechu Li, Tao Chen, Zhang-Wei Hong, Anurag Ajay, and Pulkit Agrawal. Parallelq-learning: Scaling off-policy reinforcement learning under massively parallel simulation. InInternational Conference on Machine Learning, pp. 19440–19459. PMLR,
-
[6]
Mayank Mittal, Nikita Rudin, Victor Klemm, Arthur Allshire, and Marco Hutter
doi: 10.1109/LRA.2023.3270034. Mayank Mittal, Nikita Rudin, Victor Klemm, Arthur Allshire, and Marco Hutter. Symmetry con- siderations for learning task symmetric robot policies. In2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 7433–7439. IEEE,
-
[7]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
URLhttps://arxiv.org/abs/2511.04831. Antonin Raffin. Getting sac to work on a massive parallel simulator: An rl journey with off-policy algorithms.araffin.github.io, Feb
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Proximal Policy Optimization Algorithms
URLhttps://proceedings.mlr.press/v164/rudin22a.html. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Rsl-rl: A learning library for robotics research.arXiv preprint arXiv:2509.10771,
Clemens Schwarke, Mayank Mittal, Nikita Rudin, David Hoeller, and Marco Hutter. Rsl-rl: A learning library for robotics research.arXiv preprint arXiv:2509.10771,
-
[10]
Learning sim-to-real humanoid locomotion in 15 minutes, 2025a
Younggyo Seo, Carmelo Sferrazza, Juyue Chen, Guanya Shi, Rocky Duan, and Pieter Abbeel. Learning sim-to-real humanoid locomotion in 15 minutes, 2025a. URLhttps://arxiv. org/abs/2512.01996. Younggyo Seo, Carmelo Sferrazza, Haoran Geng, Michal Nauman, Zhao-Heng Yin, and Pieter Abbeel. Fasttd3: Simple, fast, and capable reinforcement learning for humanoid co...
-
[11]
com/p/speeding-up-sac-with-massively-parallel
URLhttps://arthshukla.substack. com/p/speeding-up-sac-with-massively-parallel. Ritvik Singh, Arthur Allshire, Ankur Handa, Nathan Ratliff, and Karl Van Wyk. Dextrah-rgb: Visuomotor policies to grasp anything with dexterous hands.arXiv preprint arXiv:2412.01791,
-
[12]
Laura Smith, Ilya Kostrikov, and Sergey Levine
URLhttps: //arxiv.org/abs/2110.05457. Laura Smith, Ilya Kostrikov, and Sergey Levine. A walk in the park: Learning to walk in 20 minutes with model-free reinforcement learning. InRobotics: Science and Systems,
-
[13]
Mujoco playground.arXiv preprint arXiv:2502.08844,
Kevin Zakka, Baruch Tabanpour, Qiayuan Liao, Mustafa Haiderbhai, Samuel Holt, Jing Yuan Luo, Arthur Allshire, Erik Frey, Koushil Sreenath, Lueder A Kahrs, et al. Mujoco playground.arXiv preprint arXiv:2502.08844,
- [14]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.