MMed-Bench-IR: A Heterogeneous Benchmark for Multilingual Medical Information Retrieval
Pith reviewed 2026-06-26 00:29 UTC · model grok-4.3
The pith
A benchmark with three non-overlapping tasks shows biomedical encoders drop from 0.818 to 0.056 nDCG@10 when tested in Japanese.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
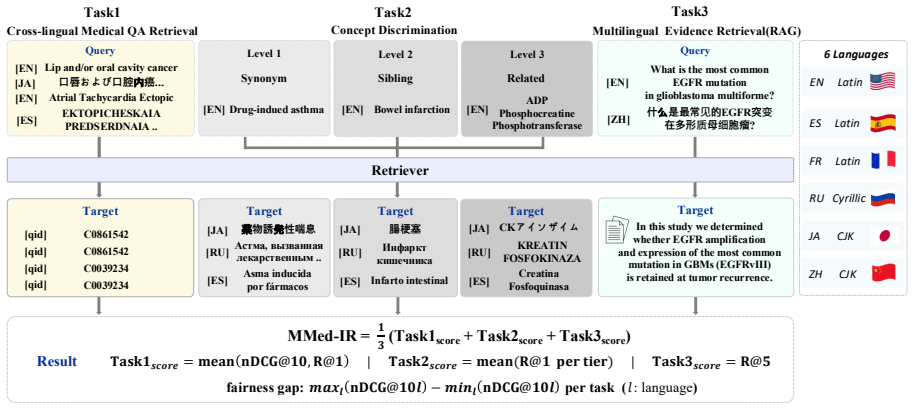
MMed-Bench-IR disentangles the required capabilities for multilingual medical retrieval by providing three structurally heterogeneous tasks across six languages: cross-lingual medical QA retrieval with 6,127 UMLS-grounded queries, concept discrimination over 4,975 confusion sets at three difficulty tiers, and multilingual evidence retrieval for RAG with 2,040 quality-assured queries. The tasks share zero concept and query overlap by design. Evaluation reveals severe cross-lingual failure where biomedical encoders scoring 0.818 nDCG@10 in English drop to 0.056 in Japanese, a gap invisible to English-only benchmarks.
What carries the argument
MMed-Bench-IR, a benchmark whose three structurally heterogeneous tasks with zero concept and query overlap separately measure cross-lingual alignment, concept discrimination, and evidence retrieval.
If this is right
- Aggregate scores on the benchmark indicate breadth across distinct skills rather than performance on any single task.
- English-only benchmarks cannot detect the cross-lingual failures present in multilingual medical retrieval.
- Clinical RAG systems require explicit testing on non-English languages to ensure reliable evidence retrieval.
Where Pith is reading between the lines
- The observed gaps suggest current biomedical encoders lack sufficient cross-lingual medical concept alignment.
- Using this benchmark during model development could guide training to reduce language-specific weaknesses.
- Similar heterogeneous designs might apply to retrieval benchmarks in other specialized domains beyond medicine.
Load-bearing premise
The three tasks share zero concept and query overlap by design, ensuring that aggregate scores reflect genuine capability breadth.
What would settle it
Finding substantial concept or query overlap between the three tasks, or re-running the ten systems and observing no large drop from English to Japanese scores, would falsify the central claims.
Figures

read the original abstract
Retrieval-augmented generation (RAG) in clinical settings increasingly requires multilingual retrieval against predominantly English evidence corpora. Multilingual medical retrieval demands three capabilities: cross-lingual alignment, concept discrimination, and evidence retrieval. However, existing benchmarks evaluate these only in isolation, leaving the interaction between biomedical expertise and multilingual coverage unmeasured. We introduce MMed-Bench-IR, a benchmark designed to disentangle these axes across 6 languages and three structurally heterogeneous tasks: (1) cross-lingual medical QA retrieval with 6,127 queries grounded in the Unified Medical Language System (UMLS), (2) concept discrimination over 4,975 confusion sets at three difficulty tiers, and (3) multilingual evidence retrieval for RAG with 2,040 quality-assured queries. The three tasks share zero concept and query overlap by design, ensuring that aggregate scores reflect genuine capability breadth. Evaluation of ten systems across six paradigm families reveals severe cross-lingual failure: biomedical encoders that score 0.818 nDCG@10 in English drop to 0.056 in Japanese, a gap that English-only benchmarks cannot detect.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MMed-Bench-IR, a heterogeneous benchmark for multilingual medical information retrieval across six languages. It comprises three tasks with zero concept and query overlap by design: (1) cross-lingual medical QA retrieval using 6,127 UMLS-grounded queries, (2) concept discrimination over 4,975 confusion sets at three difficulty tiers, and (3) multilingual evidence retrieval for RAG with 2,040 quality-assured queries. Evaluation of ten systems from six paradigm families shows severe cross-lingual degradation, including biomedical encoders dropping from 0.818 nDCG@10 in English to 0.056 in Japanese.
Significance. If the benchmark construction and overlap claims hold, the work is significant for exposing limitations in current biomedical encoders that English-only benchmarks miss. The explicit design for task heterogeneity and the empirical evaluation against external systems provide a concrete, falsifiable demonstration of the need for multilingual medical IR benchmarks in RAG settings.
major comments (2)
- [Abstract and §3] Abstract and §3 (task construction): the claim that the three tasks share zero concept and query overlap 'by design' is load-bearing for the assertion that aggregate scores reflect genuine capability breadth, yet the manuscript provides no explicit verification statistics, overlap metrics, or enforcement procedure that would allow independent confirmation of this condition.
- [§4] §4 (evaluation): the reported nDCG@10 drops (e.g., 0.818 English to 0.056 Japanese) are presented without accompanying statistical significance tests or confidence intervals, which is necessary to establish that the cross-lingual failure is not attributable to variance in the constructed query sets.
minor comments (2)
- [Abstract] The abstract mentions 'quality-assured queries' for task 3 but does not define the assurance criteria or inter-annotator agreement; this should be clarified in the methods for reproducibility.
- [§3] Notation for the three difficulty tiers in the concept discrimination task is introduced without an accompanying table or example set; adding one would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the clarity and rigor of our benchmark paper. We address each major comment below and commit to revisions that directly incorporate the requested elements.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (task construction): the claim that the three tasks share zero concept and query overlap 'by design' is load-bearing for the assertion that aggregate scores reflect genuine capability breadth, yet the manuscript provides no explicit verification statistics, overlap metrics, or enforcement procedure that would allow independent confirmation of this condition.
Authors: We agree that explicit verification strengthens the claim. The three tasks were deliberately sourced from disjoint UMLS-derived subsets with no shared concept IDs or query text (QA retrieval uses question templates, concept discrimination uses confusion sets, and evidence retrieval uses passage-level queries), but the manuscript omitted the enforcement details. In the revision we will add a new subsection in §3 that (i) specifies the exact deduplication procedure (UMLS CUI matching + normalized string comparison), (ii) reports the computed overlap statistics (zero by construction), and (iii) provides the code snippet used for verification so that readers can replicate the check. revision: yes
-
Referee: [§4] §4 (evaluation): the reported nDCG@10 drops (e.g., 0.818 English to 0.056 Japanese) are presented without accompanying statistical significance tests or confidence intervals, which is necessary to establish that the cross-lingual failure is not attributable to variance in the constructed query sets.
Authors: We concur that statistical support is required. In the revised §4 we will augment all reported nDCG@10 figures with 95% bootstrap confidence intervals (1,000 resamples) and paired significance tests (Wilcoxon signed-rank with Bonferroni correction) comparing English versus each non-English language. These additions will confirm that the observed cross-lingual degradations exceed what could be explained by query-set variance alone. revision: yes
Circularity Check
No significant circularity in benchmark construction and evaluation
full rationale
The paper introduces a new benchmark via explicit design choices (zero concept/query overlap stated as construction rule) and reports empirical nDCG@10 results on external retrieval systems. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described content. The performance gap claim rests on observed evaluation, not internal reduction to inputs. This is standard benchmark work that is self-contained against external systems.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M 3 R etrieve: Benchmarking Multimodal Retrieval for Medicine
Acharya, Arkadeep and Ghosh, Akash and Verma, Pradeepika and Pasupa, Kitsuchart and Saha, Sriparna and Singh, Dr Priti. M 3 R etrieve: Benchmarking Multimodal Retrieval for Medicine. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.771
-
[2]
BMJ Health & Care Informatics , volume=
Artificial intelligence translation in healthcare: an urgent call for evidence-informed policy frameworks , author=. BMJ Health & Care Informatics , volume=
-
[3]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
CURE: A Dataset for Clinical Understanding & Retrieval Evaluation , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[4]
Nucleic acids research , volume=
The unified medical language system (UMLS): integrating biomedical terminology , author=. Nucleic acids research , volume=. 2004 , publisher=
2004
-
[5]
Chen, Jianlyu and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng. M 3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.137
-
[6]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Unsupervised cross-lingual representation learning at scale , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[7]
arXiv preprint arXiv:2207.04672 , year=
No language left behind: Scaling human-centered machine translation , author=. arXiv preprint arXiv:2207.04672 , year=
-
[8]
Bioinformatics , volume=
Medcpt: Contrastive pre-trained transformers with large-scale pubmed search logs for zero-shot biomedical information retrieval , author=. Bioinformatics , volume=. 2023 , publisher=
2023
-
[9]
JAMA Network Open , volume=
Association of language barriers with perioperative and surgical outcomes: a systematic review , author=. JAMA Network Open , volume=
-
[10]
Proceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
Self-alignment pretraining for biomedical entity representations , author=. Proceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
2021
-
[11]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Colbert-xm: A modular multi-vector representation model for zero-shot multilingual information retrieval , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[12]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
Mteb: Massive text embedding benchmark , author=. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
-
[13]
JAMA Network Open , volume=
Language equity in health technology for patients with Non--English language preference , author=. JAMA Network Open , volume=
-
[14]
Lifting the Curse of Multilinguality by Pre-training Modular Transformers
Pfeiffer, Jonas and Goyal, Naman and Lin, Xi Victoria and Li, Xian and Cross, James and Riedel, Sebastian and Artetxe, Mikel. Lifting the Curse of Multilinguality by Pre-training Modular Transformers. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10...
-
[15]
Nature Communications , volume=
Towards building multilingual language model for medicine , author=. Nature Communications , volume=. 2024 , publisher=
2024
-
[16]
arXiv preprint arXiv:2311.16075 , year=
Biolord-2023: Semantic textual representations fusing llm and clinical knowledge graph insights , author=. arXiv preprint arXiv:2311.16075 , year=
arXiv 2023
-
[17]
2009 , publisher=
The probabilistic relevance framework: BM25 and beyond , author=. 2009 , publisher=
2009
-
[18]
New England Journal of Medicine , volume=
Artificial intelligence in US health care delivery , author=. New England Journal of Medicine , volume=. 2023 , publisher=
2023
-
[19]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
Nandan Thakur and Nils Reimers and Andreas R. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
-
[20]
BMC bioinformatics , volume=
An overview of the BIOASQ large-scale biomedical semantic indexing and question answering competition , author=. BMC bioinformatics , volume=. 2015 , publisher=
2015
-
[21]
International Journal of Medical Informatics , volume=
Semantic annotation for concept-based cross-language medical information retrieval , author=. International Journal of Medical Informatics , volume=. 2002 , publisher=
2002
-
[22]
arXiv preprint arXiv:2403.03640 , year=
Apollo: A lightweight multilingual medical LLM towards democratizing medical AI to 6B people , author=. arXiv preprint arXiv:2403.03640 , year=
-
[23]
arXiv preprint arXiv:2402.05672 , year=
Multilingual e5 text embeddings: A technical report , author=. arXiv preprint arXiv:2402.05672 , year=
-
[24]
arXiv preprint arXiv:2007.00808 , year=
Approximate nearest neighbor negative contrastive learning for dense text retrieval , author=. arXiv preprint arXiv:2007.00808 , year=
arXiv 2007
-
[25]
Journal of biomedical informatics , volume=
CODER: Knowledge-infused cross-lingual medical term embedding for term normalization , author=. Journal of biomedical informatics , volume=. 2022 , publisher=
2022
-
[26]
TyDi: A multi-lingual benchmark for dense retrieval , author=
Mr. TyDi: A multi-lingual benchmark for dense retrieval , author=. Proceedings of the 1st workshop on multilingual representation learning , pages=
-
[27]
Transactions of the Association for Computational Linguistics , volume=
Miracl: A multilingual retrieval dataset covering 18 diverse languages , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.