Making Time Editable in Video Diffusion Transformers
Pith reviewed 2026-06-27 16:34 UTC · model grok-4.3
The pith
Adding a lightweight temporal module to pretrained video diffusion transformers enables explicit control over motion speed and temporal structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
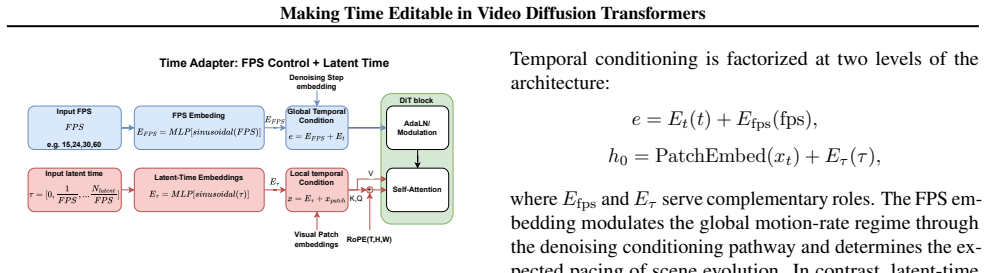
The temporal-control methodology extends a pretrained DiT with explicit time editing, allowing control over motion speed and temporal structure without redesigning the backbone. Its core implementation augments the pretrained model with a lightweight temporal module, preserving the original generative prior while expanding its controllable dynamic range.
What carries the argument
The lightweight temporal module that augments the pretrained Diffusion Transformer to enable explicit time editing.
If this is right
- Motion speed becomes directly controllable in generated videos.
- Temporal structure editing is possible without backbone changes.
- The original generative prior stays preserved after augmentation.
- The range of controllable dynamic features for time expands.
Where Pith is reading between the lines
- The same augmentation pattern might apply to other pretrained diffusion models for adding new controls.
- Downstream video editing tools could incorporate this module to offer users time-based adjustments.
- Fewer full retrainings of large models may be needed when adding temporal features.
Load-bearing premise
That a lightweight temporal module can be added to a pretrained DiT to provide explicit time editing without redesigning the backbone or degrading the generative prior.
What would settle it
A direct comparison experiment in which the augmented model produces videos that either lose visual quality or fail to respond to time-editing inputs relative to the unmodified pretrained model.
Figures


read the original abstract
Modern Diffusion Transformers for video generation provide limited control over the progression of time and the editing of temporal dynamics. We propose a temporal-control methodology that extends a pretrained DiT with explicit time editing, allowing control over motion speed and temporal structure without redesigning the backbone. Its core implementation augments the pretrained model with a lightweight temporal module, preserving the original generative prior while expanding its controllable dynamic range.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a temporal-control methodology for video Diffusion Transformers that augments a pretrained DiT with a lightweight temporal module. This enables explicit editing of motion speed and temporal structure while preserving the original generative prior and expanding controllable dynamic range, without redesigning the backbone.
Significance. If the lightweight module can be shown to deliver the claimed control without degrading the pretrained prior, the result would be significant for efficient extension of existing video DiT models. However, the abstract provides no equations, training details, or results, so the significance cannot be assessed from the given material.
major comments (1)
- [Abstract] Abstract: The central claim that the lightweight temporal module 'preserves the original generative prior' while expanding controllable dynamic range is load-bearing for the contribution, yet the manuscript supplies no derivation, objective function, architecture diagram, or experimental evidence (e.g., FID, temporal consistency metrics, or ablation on prior preservation) to support it. This prevents verification of the weakest assumption identified in the stress test.
Simulated Author's Rebuttal
We thank the referee for their review. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the lightweight temporal module 'preserves the original generative prior' while expanding controllable dynamic range is load-bearing for the contribution, yet the manuscript supplies no derivation, objective function, architecture diagram, or experimental evidence (e.g., FID, temporal consistency metrics, or ablation on prior preservation) to support it. This prevents verification of the weakest assumption identified in the stress test.
Authors: The abstract is necessarily concise and omits equations, diagrams, and detailed metrics, which is standard. The full manuscript supplies these elements: the architecture diagram appears in Figure 2, the derivation and objective function (a frozen-DiT diffusion loss plus a lightweight temporal loss) are given in Section 3 and Equation (4), and experimental support (FID scores comparable to the base model, temporal consistency metrics, and prior-preservation ablations) is reported in Section 5 and Table 2. We therefore disagree that the manuscript lacks supporting material and refer the referee to those sections. revision: no
Circularity Check
No derivation chain or equations present to inspect
full rationale
The supplied text is limited to an abstract describing a methodological proposal for extending a pretrained DiT with a lightweight temporal module. No equations, training objectives, uniqueness theorems, ansatzes, or derivation steps are stated. Without any claimed mathematical chain that could reduce to its inputs by construction, self-citation, or fitted prediction, no circularity of any enumerated kind can be identified. The central claim remains an engineering assertion whose validity would require the full architecture and results for evaluation, but none are available here to trigger a circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kim, K., Hyung, J., and Choo, J
URL https://arxiv.org/abs/2511.14993. Kim, K., Hyung, J., and Choo, J. Temporal in-context fine- tuning for versatile control of video diffusion models. arXiv preprint arXiv:2506.00996,
-
[2]
Li, Q., Xing, Z., Wang, R., Zhang, H., Dai, Q., and Wu, Z
URL https: //arxiv.org/abs/2506.00996. Li, Q., Xing, Z., Wang, R., Zhang, H., Dai, Q., and Wu, Z. Magicmotion: Controllable video generation with dense-to-sparse trajectory guidance.arXiv preprint arXiv:2503.16421,
-
[3]
URL https://arxiv. org/abs/2503.16421. Liao, X., Zeng, X., Wang, L., Yu, G., Lin, G., and Zhang, C. Motionagent: Fine-grained controllable video generation via motion field agent.arXiv preprint arXiv:2502.03207,
-
[4]
URL https://arxiv. org/abs/2502.03207. Lin, H., Cho, J., Zala, A., and Bansal, M. Ctrl-adapter: An efficient and versatile framework for adapting diverse controls to any diffusion model. InInternational Confer- ence on Learning Representations,
-
[5]
Liu, Z., Wang, J., Duan, Z., Rodriguez-Opazo, C., and van den Hengel, A
URLhttps://arxiv.org/abs/2503.10076. Liu, Z., Wang, J., Duan, Z., Rodriguez-Opazo, C., and van den Hengel, A. Frame-wise conditioning adapta- tion for fine-tuning diffusion models in text-to-video pre- diction.arXiv preprint arXiv:2503.12953,
-
[6]
Lu, H., Yang, G., Fei, N., Huo, Y ., Lu, Z., Luo, P., and Ding, M
URL https://arxiv.org/abs/2503.12953. Lu, H., Yang, G., Fei, N., Huo, Y ., Lu, Z., Luo, P., and Ding, M. Vdt: General-purpose video diffusion transformers via mask modeling
-
[7]
URL https://arxiv. org/abs/2305.13311. Ma, X., Wang, Y ., Chen, X., Jia, G., Liu, Z., Li, Y .-F., Chen, C., and Qiao, Y . Latte: Latent diffusion transformer for video generation
-
[8]
Su, J., Ahmed, M., Lu, Y ., Pan, S., Bo, W., and Liu, Y
URL https://arxiv.org/ abs/2401.03048. Su, J., Ahmed, M., Lu, Y ., Pan, S., Bo, W., and Liu, Y . Roformer: Enhanced transformer with rotary po- sition embedding.Neurocomput., 568(C), February
-
[9]
ISSN 0925-2312. doi: 10.1016/j.neucom. 2023.127063. URL https://doi.org/10.1016/ j.neucom.2023.127063. Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zha...
-
[10]
Xiao, Z., Ouyang, W., Zhou, Y ., Yang, S., Yang, L., Si, J., and Pan, X
URL https: //arxiv.org/abs/2503.20314. Xiao, Z., Ouyang, W., Zhou, Y ., Yang, S., Yang, L., Si, J., and Pan, X. Trajectory attention for fine-grained video motion control.arXiv preprint arXiv:2411.19324,
-
[11]
URLhttps://arxiv.org/abs/2411.19324. 5 Making Time Editable in Video Diffusion Transformers Xing, Z., Dai, Q., Hu, H., Wu, Z., and Jiang, Y .- G. Simda: Simple diffusion adapter for efficient video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion,
-
[12]
URL https://cvpr.thecvf.com/ virtual/2024/poster/31202. Yu, S., Fang, J. Z., Zheng, S., Sigurdsson, G., Ordonez, V ., Piramuthu, R., and Bansal, M. Zero-shot control- lable image-to-video animation via motion decomposi- tion.arXiv preprint, 2024a. Yu, S., Nie, W., Huang, D.-A., Li, B., Shin, J., and Anandkumar, A. Efficient video diffusion models via cont...
arXiv 2024
-
[13]
6 Making Time Editable in Video Diffusion Transformers A
URL https://arxiv.org/ abs/2505.20287. 6 Making Time Editable in Video Diffusion Transformers A. Related Work Adapter-based controllable diffusion.Recent work has shown that lightweight adapters are an effective way to extend pretrained diffusion backbones. Ctrl-Adapter (Lin et al.,
-
[14]
These methods make conditioning more flexible, but they do not directly address temporal controllability as a factorized problem
refines this direction through frame-wise text conditioning for video prediction. These methods make conditioning more flexible, but they do not directly address temporal controllability as a factorized problem. In particular, FCA adapts text conditioning at the frame level, whereas our method introduces an explicit decomposition of temporal control into ...
2025
-
[15]
These works motivate our perspective that temporal control should be represented more explicitly, yet editable time is still not treated as the primary control target
extends pretrained video diffusion models through temporally informed fine-tuning, but does not explicitly decompose time into global and local temporal variables. These works motivate our perspective that temporal control should be represented more explicitly, yet editable time is still not treated as the primary control target. Positioning of our method...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.