Which Nash Equilibrium? Solver-Dependent Selection on Zero-Sum Nash Polytopes
Pith reviewed 2026-06-29 01:43 UTC · model grok-4.3
The pith
In zero-sum games with multiple Nash equilibria, solver algorithm determines which member of the set is selected rather than random seed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
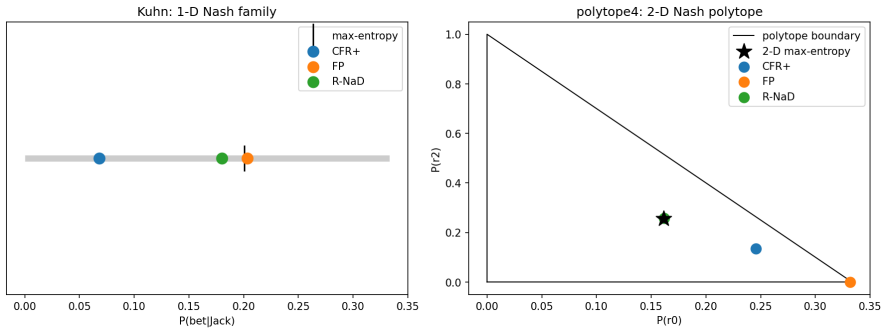
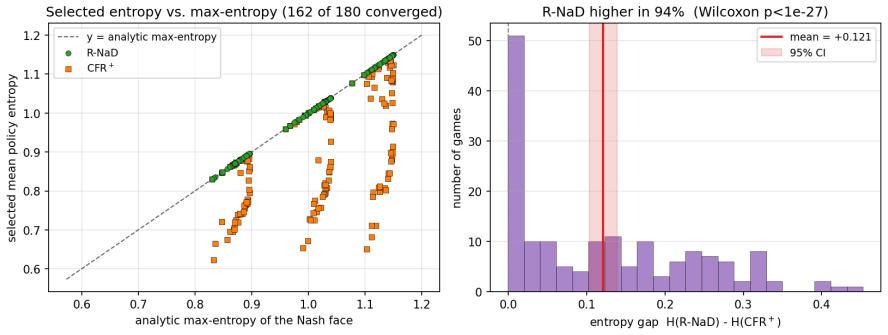
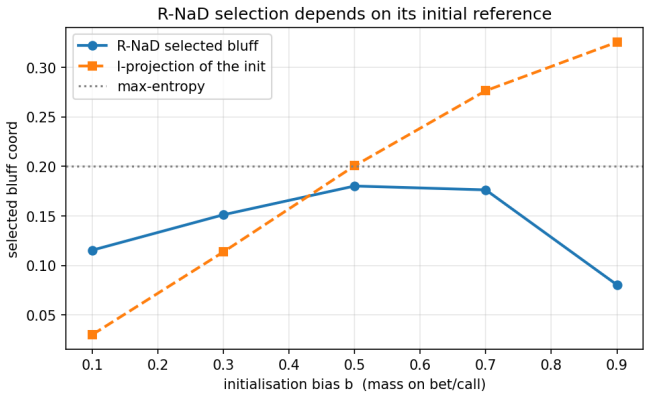
Regularized last-iterate methods such as R-NaD and magnetic mirror descent select the maximum-entropy member of the Nash set—the information projection of their uniform reference onto the Nash polytope—exactly on the two-dimensional polytope and at 99.7 percent of maximum entropy in Kuhn poker, whereas regret-averaging methods such as CFR, CFR+, and fictitious play drift to a lower-entropy face; the pattern holds throughout a randomized 180-game ensemble where the regularized method attains the maximum-entropy member in 100 percent of converged games while the regret method sits strictly below it in 94 percent.
What carries the argument
The maximum-entropy member of the Nash set, defined as the information projection of the uniform reference onto the Nash polytope, which regularized last-iterate methods follow through their anchor mechanism.
If this is right
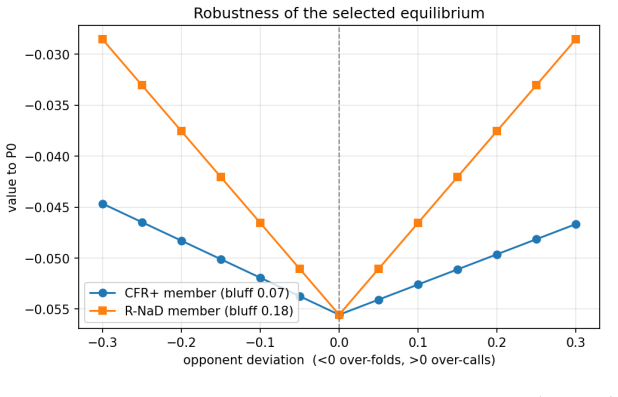
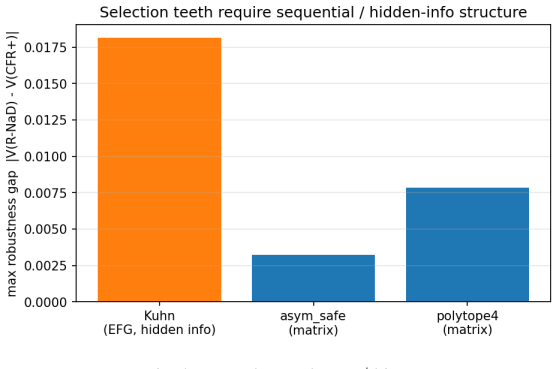
- The selected equilibrium affects performance against suboptimal opponents, with the maximum-entropy member acting as a strictly better hedge in sequential games such as Kuhn poker.
- Differences between equilibria remain bounded on matrix games and do not produce dominance of one member over another.
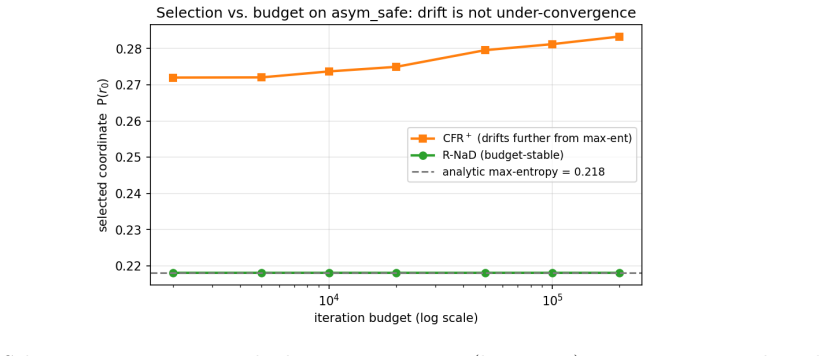
- Removing the positive-orthant projection from CFR does not eliminate boundary drift to lower-entropy equilibria.
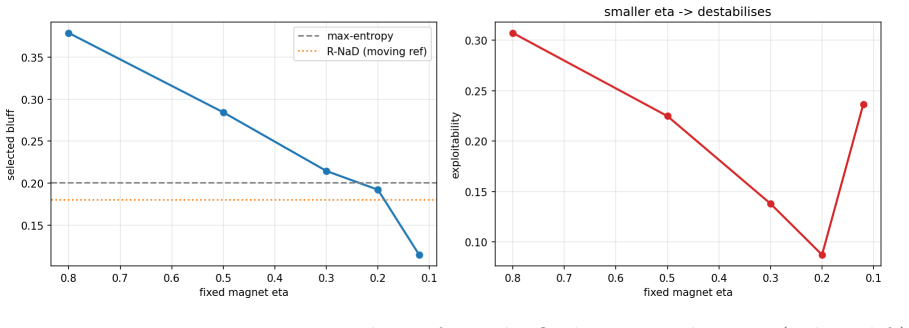
- R-NaD selection is anchor-following and therefore not initialization-independent.
Where Pith is reading between the lines
- Users of equilibrium solvers may need to select the algorithm according to the entropy or robustness properties desired in the output equilibrium.
- The observed pattern suggests testing whether the maximum-entropy selection persists in games with continuous action spaces or more than two players.
- The distinction between last-iterate and average-regret families could inform design of hybrid solvers that target specific locations inside Nash polytopes.
- Performance gaps against suboptimal opponents may become practically relevant in domains with sequential structure and imperfect information.
Load-bearing premise
The six analytically solvable testbed games together with the randomized 180-game ensemble are representative of the broader class of zero-sum games that possess non-unique Nash equilibria.
What would settle it
A zero-sum game with an analytically known Nash polytope in which a regularized last-iterate method converges to a non-maximum-entropy equilibrium or a regret-averaging method converges to the maximum-entropy equilibrium would falsify the reported selection pattern.
Figures


read the original abstract
Many two-player zero-sum games admit not a unique Nash equilibrium but a convex set of them: a polytope of profiles that all share the minimax value V* yet prescribe different behaviour. Standard solvers each converge to some equilibrium and are treated as interchangeable. We ask whether they instead select different members of the Nash set, systematically as a function of the algorithm rather than the seed. Using a tabular, exactly solvable testbed of six games with analytically known Nash sets -- including a two-dimensional Nash polytope and Kuhn poker -- we find that (i) selection is determined by the algorithm, not the seed, but families differ only on asymmetric Nash sets; (ii) regularized last-iterate methods (R-NaD, magnetic mirror descent) select the maximum-entropy member, the information projection of their uniform reference onto the Nash set -- exactly on the 2-D polytope and at 99.7% of maximum entropy in Kuhn -- while regret-averaging methods (CFR, CFR+, fictitious play) drift to a lower-entropy face; we confirm this on a randomized 180-game ensemble, where R-NaD attains the maximum-entropy member in 100% of converged games while CFR+ sits strictly below it in 94% (paired Wilcoxon p < 10^-27); (iii) the selected member has downstream consequences against sub-optimal opponents that scale with sequential/hidden-information structure but stay bounded -- in Kuhn the max-entropy member is a strictly better hedge, whereas on the matrix games the members differ without either dominating. We also report two negative results correcting common intuitions: removing CFR's positive-orthant (max(R,0)) projection does not eliminate boundary drift; and R-NaD's selection is anchor-following, not initialization-independent. We state the maximum-entropy / I-projection characterization as a strongly data-supported conjecture, checked throughout against analytic ground truth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Nash equilibrium solvers are not interchangeable in zero-sum games whose Nash set is a non-singleton polytope: regularized last-iterate methods (R-NaD, magnetic mirror descent) select the maximum-entropy member (the information projection of a uniform reference onto the Nash set), while regret-averaging methods (CFR, CFR+, fictitious play) select lower-entropy faces. This is shown exactly on six analytically solvable testbed games (including a 2-D polytope and Kuhn poker at 99.7% of max entropy) and statistically on a randomized 180-game ensemble (R-NaD attains the max-entropy member in 100% of converged games; CFR+ is strictly below in 94%, paired Wilcoxon p < 10^{-27}). The selected member has downstream consequences against suboptimal opponents that scale with sequential structure but remain bounded; two negative results correct common intuitions about CFR's projection and R-NaD's initialization dependence. The max-entropy/I-projection characterization is stated as a strongly data-supported conjecture.
Significance. If the results hold, the work shows that algorithm choice induces systematic, non-arbitrary selection within the Nash set, with measurable effects on entropy and robustness, particularly in sequential/hidden-information games. Credit is due for the verification against exact analytic Nash sets on the small testbeds, the inclusion of negative results that test intuitions, and the statistical confirmation (with p-values) on the ensemble; these elements make the empirical component unusually well-grounded for an algorithmic study in game theory.
major comments (1)
- [Methods (randomized 180-game ensemble)] Methods (description of the randomized 180-game ensemble): the randomization procedure is not explicitly characterized (distribution over matrix sizes, payoff ranges, or constraints on Nash polytope dimension or symmetry). This is load-bearing for the generalization of the 100%/94% selection split and the I-projection conjecture, because the ensemble could over-sample low-dimensional or symmetric polytopes similar to the six hand-chosen testbeds.
minor comments (1)
- [Abstract] Abstract: the phrase 'the information projection of their uniform reference onto the Nash set' is used without a one-sentence gloss or forward reference, which may hinder readers who encounter the term for the first time.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for noting the positive aspects of the empirical design. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Methods (randomized 180-game ensemble)] Methods (description of the randomized 180-game ensemble): the randomization procedure is not explicitly characterized (distribution over matrix sizes, payoff ranges, or constraints on Nash polytope dimension or symmetry). This is load-bearing for the generalization of the 100%/94% selection split and the I-projection conjecture, because the ensemble could over-sample low-dimensional or symmetric polytopes similar to the six hand-chosen testbeds.
Authors: We agree that the randomization procedure must be fully specified for the statistical results and conjecture to be interpretable. In the revised manuscript we will add an explicit description of the ensemble generation process, including the distributions over matrix dimensions, payoff ranges, and any constraints or sampling rules used to control Nash polytope dimension and symmetry. This addition will allow independent verification that the ensemble is not inadvertently biased toward the low-dimensional or symmetric cases already examined in the analytic testbeds. revision: yes
Circularity Check
No circularity: empirical claims rest on external analytic ground truth and randomized ensemble
full rationale
The paper presents an empirical study comparing solver behavior on six analytically solvable games (with known Nash sets) and a 180-game randomized ensemble. The maximum-entropy / I-projection characterization is explicitly labeled a 'strongly data-supported conjecture' checked against analytic ground truth rather than derived from the paper's own equations. No self-citations, fitted parameters renamed as predictions, or self-definitional steps appear in the provided text. The central observations (algorithm-dependent selection, 100%/94% split, downstream consequences) are direct measurements on external benchmarks, satisfying the criteria for a self-contained result against independent verification. Representativeness of the ensemble is an assumption about scope, not a circular reduction in the derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Nash equilibrium sets in two-player zero-sum games are convex polytopes
Reference graph
Works this paper leans on
-
[1]
J. P. Bailey and G. Piliouras. Multiplicative weights update in zero-sum games. ACM Conference on Economics and Computation (EC), 2018. DOI: 10.1145/3219166.3219235
-
[2]
D. Balduzzi, K. Tuyls, J. P\'erolat, and T. Graepel. Re-evaluating evaluation. NeurIPS, 2018. arXiv:1806.02643
Pith/arXiv arXiv 2018
-
[3]
M. Bowling, N. Burch, M. Johanson, and O. Tammelin. Heads-up limit hold'em poker is solved. Science, 347(6218):145--149, 2015. DOI: 10.1126/science.1259433
-
[4]
G. W. Brown. Iterative solution of games by fictitious play. Activity Analysis of Production and Allocation, 1951
1951
-
[5]
I. Csisz\'ar. I -divergence geometry of probability distributions and minimization problems. Annals of Probability, 3(1):146--158, 1975. DOI: 10.1214/aop/1176996454
-
[6]
M. Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. NeurIPS, 2013
2013
-
[7]
L. Flokas, E.-V. Vlatakis-Gkaragkounis, T. Lianeas, P. Mertikopoulos, and G. Piliouras. No-regret learning and mixed Nash equilibria: They do not mix. NeurIPS, 2020. DOI: 10.48550/arxiv.2010.09514
-
[8]
I. Gemp et al. Sample-based approximation of Nash in large many-player games via gradient descent. AAMAS, 2022. arXiv:2106.01285
arXiv 2022
-
[9]
J. C. Harsanyi and R. Selten. A General Theory of Equilibrium Selection in Games. MIT Press, 1988
1988
-
[10]
D. Hennes et al. Neural replicator dynamics: Multiagent learning via hedging policy gradients. AAMAS, 2020. DOI: 10.65109/gjmw6851
-
[11]
E. T. Jaynes. Information theory and statistical mechanics. Physical Review, 106(4):620--630, 1957. DOI: 10.1103/physrev.106.620
-
[12]
R. D. McKelvey and T. R. Palfrey. Quantal response equilibria for normal form games. Games and Economic Behavior, 10(1):6--38, 1995. DOI: 10.1006/game.1995.1023
-
[13]
P. Mertikopoulos, C. Papadimitriou, and G. Piliouras. Cycles in adversarial regularized learning. ACM-SIAM Symposium on Discrete Algorithms (SODA), 2018. DOI: 10.1137/1.9781611975031.172
-
[14]
P\'erolat et al
J. P\'erolat et al. From Poincar\'e recurrence to convergence in imperfect-information games: Finding equilibrium via regularization. ICML, 2021
2021
-
[15]
J. P\'erolat et al. Mastering the game of Stratego with model-free multiagent reinforcement learning. Science, 378(6623):990--996, 2022. DOI: 10.1126/science.add4679
-
[16]
J. Robinson. An iterative method of solving a game. Annals of Mathematics, 54(2):296--301, 1951. DOI: 10.2307/1969530
-
[17]
S. Sokota et al. A unified approach to reinforcement learning, quantal response equilibria, and two-player zero-sum games. ICLR, 2023. arXiv:2206.05825
arXiv 2023
-
[18]
O. Tammelin. Solving large imperfect information games using CFR+. arXiv:1407.5042, 2014
Pith/arXiv arXiv 2014
-
[19]
T. L. Turocy. A dynamic homotopy interpretation of the logistic quantal response equilibrium correspondence. Games and Economic Behavior, 51(2):243--263, 2005. DOI: 10.1016/j.geb.2004.04.003
-
[20]
J. Weed. An explicit analysis of the entropic penalty in linear programming. Conference on Learning Theory (COLT), PMLR 75, 2018. DOI: 10.48550/arxiv.1806.01879
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1806.01879 2018
-
[21]
Zinkevich, M
M. Zinkevich, M. Johanson, M. Bowling, and C. Piccione. Regret minimization in games with incomplete information. NeurIPS, 2007
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.