EO-WM: A Physically Informed World Model for Probabilistic Earth Observation Forecasting
Pith reviewed 2026-06-26 04:29 UTC · model grok-4.3
The pith
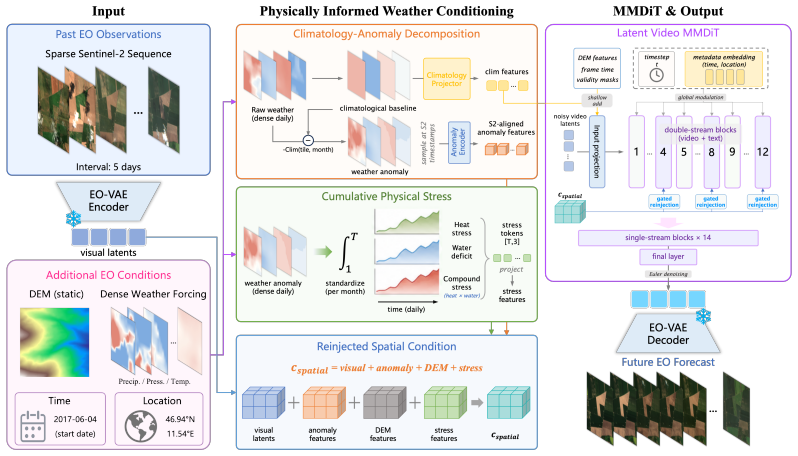
EO-WM conditions a video diffusion transformer on separate pathways for climatological baseline, weather anomalies, and accumulated physical stress to produce weather-responsive Earth surface forecasts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
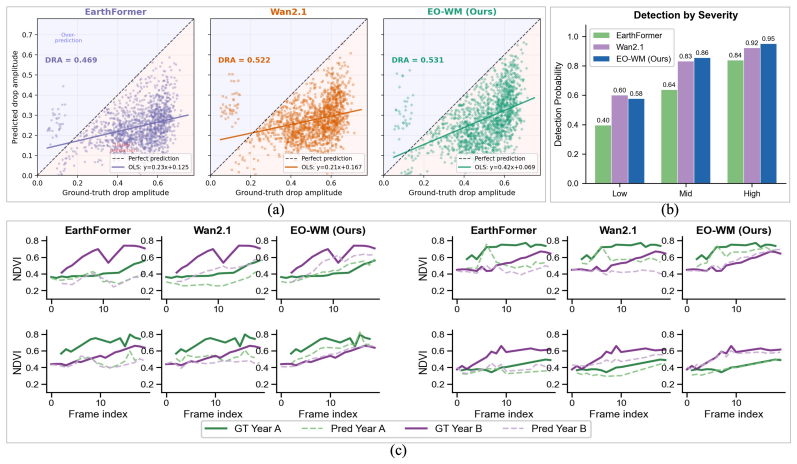
EO-WM is a video diffusion transformer for multispectral EO forecasting that incorporates a physically informed conditioning framework representing meteorological forcing through a climatological baseline, weather anomalies, and cumulative physical stress signals. It separates baseline and anomaly through distinct conditioning pathways and accumulates anomalous forcing over time to capture sustained heat and drought stress. On the introduced Extreme Summer Benchmark and Seasonal Matched-Pair Benchmark this yields a relative 5.63 percent reduction in error for predicted NDVI decline amplitude and a relative 7.80 percent improvement in directional hit rate while remaining competitive on pixel-
What carries the argument
The physically informed conditioning framework that separates meteorological forcing into climatological baseline, weather anomalies, and cumulative physical stress signals through distinct pathways with temporal accumulation.
If this is right
- Forecasts show reduced error in the amplitude of NDVI decline during extreme summer conditions.
- Directional accuracy improves when testing response to deliberately changed weather forcing.
- Performance stays competitive on conventional pixel-level reconstruction metrics.
- Diagnostic benchmarks shift evaluation from reconstruction accuracy toward weather-response fidelity.
Where Pith is reading between the lines
- The same decomposition of forcing signals could be tested on forecasting other surface properties such as soil moisture or land surface temperature.
- Explicit separation of baseline, anomaly and stress may reduce the data needed to learn long-term land dynamics compared with undifferentiated conditioning.
- The new benchmarks could serve as a standard check for any EO forecasting model to verify sensitivity to specific weather perturbations.
- Extending the accumulation mechanism to multi-year stress signals might allow longer-horizon seasonal forecasts.
Load-bearing premise
Separating meteorological forcing into climatological baseline, weather anomalies, and cumulative physical stress signals through distinct conditioning pathways is sufficient to capture the relevant unobserved land-surface dynamics without additional state variables or more detailed physical process models.
What would settle it
A test that removes or swaps the cumulative stress pathway while keeping baseline and anomaly inputs fixed and measures whether the directional NDVI response under extreme weather collapses to random levels.
Figures

read the original abstract
Earth Observation (EO) forecasting aims to predict future Earth surface dynamics from satellite observations under changing meteorological conditions. In this paper, we view this task as a partially observed, weather-driven world modeling problem, in which weather acts as a conditioning signal, while forecasting remains uncertain due to sparse observations and unobserved land-surface states. However, existing methods do not fully capture this setting: deterministic models collapse uncertainty into a single future prediction, while diffusion-based methods typically treat weather variables as undifferentiated conditioning signals, and existing benchmarks focus mainly on reconstruction accuracy rather than whether forecasts respond correctly to changed weather forcing.We introduce EO-WM, a video diffusion transformer for multispectral EO forecasting. EO-WM incorporates a physically informed conditioning framework that represents meteorological forcing through a climatological baseline, weather anomalies, and cumulative physical stress signals. Specifically, it separates baseline and anomaly through distinct conditioning pathways, and accumulates anomalous forcing over time to capture sustained heat and drought stress. To evaluate weather-response behavior beyond standard metrics, we introduce two diagnostic benchmarks: an Extreme Summer Benchmark for severity-aware prediction of vegetation degradation under extreme weather, and a Seasonal Matched-Pair Benchmark for testing response fidelity under changed weather forcing. Experiments show that EO-WM reduces the error in predicted Normalized Difference Vegetation Index (NDVI) decline amplitude by a relative 5.63% and improves directional hit rate by a relative 7.80%, while remaining competitive on standard pixel-level metrics. The benchmarks and model will be made open-source at https://github.com/Luo-Z13/EO-WM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EO-WM, a video diffusion transformer for multispectral Earth Observation forecasting that incorporates a physically informed conditioning framework separating meteorological forcing into climatological baseline, weather anomalies, and cumulative physical stress signals through distinct pathways. It introduces two new diagnostic benchmarks (Extreme Summer Benchmark and Seasonal Matched-Pair Benchmark) to evaluate weather-response behavior beyond standard reconstruction metrics. Experiments report that EO-WM reduces error in predicted NDVI decline amplitude by a relative 5.63% and improves directional hit rate by a relative 7.80% while remaining competitive on pixel-level metrics; the model and benchmarks are to be open-sourced.
Significance. If the central claim holds, the work would be significant for embedding structured physical conditioning into probabilistic EO world models, addressing the gap between undifferentiated weather inputs and observable vegetation response to extremes. The focus on diagnostic benchmarks for directional fidelity and severity-aware prediction, rather than solely pixel-level accuracy, represents a constructive contribution. Open-sourcing the model and benchmarks strengthens reproducibility. However, the significance is limited by the absence of statistical validation and direct tests of the conditioning design's sufficiency.
major comments (2)
- [Abstract] Abstract: The reported relative gains (5.63% reduction in NDVI decline amplitude error; 7.80% improvement in directional hit rate) are presented without error bars, dataset sizes, statistical tests, or ablation details. These omissions are load-bearing for the central claim that the three-way conditioning improves weather-response behavior on the new benchmarks.
- [Method and Experiments] Method and Experiments sections: No comparison is reported to an otherwise identical architecture augmented with explicit state variables (e.g., recurrent soil-moisture or vegetation-state buffer) or to a version replacing the cumulative stress accumulator with a more detailed process model. This is load-bearing because the gains on the author-introduced benchmarks are attributed to the sufficiency of the baseline/anomaly/stress pathways for capturing unobserved land-surface dynamics.
minor comments (1)
- [Experiments] The high-level description of benchmark construction leaves open the possibility that metric choices influence the reported improvements; more explicit details on how the Extreme Summer and Seasonal Matched-Pair benchmarks are constructed would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify areas where additional statistical detail and justification of design choices would strengthen the manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported relative gains (5.63% reduction in NDVI decline amplitude error; 7.80% improvement in directional hit rate) are presented without error bars, dataset sizes, statistical tests, or ablation details. These omissions are load-bearing for the central claim that the three-way conditioning improves weather-response behavior on the new benchmarks.
Authors: We agree that the abstract and results would benefit from explicit statistical support. In the revised manuscript we will report mean performance with standard deviations across multiple random seeds, the exact sizes of the Extreme Summer and Seasonal Matched-Pair benchmarks, and the outcomes of paired statistical tests (e.g., Wilcoxon signed-rank) for the reported relative improvements. revision: yes
-
Referee: [Method and Experiments] Method and Experiments sections: No comparison is reported to an otherwise identical architecture augmented with explicit state variables (e.g., recurrent soil-moisture or vegetation-state buffer) or to a version replacing the cumulative stress accumulator with a more detailed process model. This is load-bearing because the gains on the author-introduced benchmarks are attributed to the sufficiency of the baseline/anomaly/stress pathways for capturing unobserved land-surface dynamics.
Authors: The EO setting is defined by partially observed inputs; explicit recurrent state buffers would require auxiliary variables (soil moisture, vegetation state) that are not part of the multispectral observation stream used in our benchmarks. We will add a dedicated paragraph in the revised Method section clarifying this modeling choice and will include additional pathway-specific ablations that isolate the contribution of the cumulative-stress accumulator to the directional and amplitude metrics. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a conditioning framework and evaluates empirical performance gains on newly proposed benchmarks using independent metrics (NDVI decline amplitude error, directional hit rate). These outcomes are measured results on held-out or constructed test cases rather than quantities defined in terms of the fitted parameters or model architecture. No self-citations, self-definitional equations, or fitted-input-as-prediction patterns appear in the abstract or described claims. The derivation remains self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Weather acts as a conditioning signal while forecasting remains uncertain due to sparse observations and unobserved land-surface states.
invented entities (1)
-
cumulative physical stress signals
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Pith/arXiv arXiv 2025
-
[2]
Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Processing Systems, 37:58757–58791, 2024
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Processing Systems, 37:58757–58791, 2024
2024
-
[3]
Multi-modal learning for geospatial vegetation forecasting
Vitus Benson, Claire Robin, Christian Requena-Mesa, Lazaro Alonso, Nuno Carvalhais, José Cortés, Zhihan Gao, Nora Linscheid, Mélanie Weynants, and Markus Reichstein. Multi-modal learning for geospatial vegetation forecasting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27788–27799, 2024
2024
-
[4]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
2024
-
[5]
Insights from earth system model initial-condition large ensembles and future prospects.Nature climate change, 10 (4):277–286, 2020
Clara Deser, Flavio Lehner, Keith B Rodgers, Toby Ault, Thomas L Delworth, Pedro N DiNezio, Arlene Fiore, Claude Frankignoul, John C Fyfe, Daniel E Horton, et al. Insights from earth system model initial-condition large ensembles and future prospects.Nature climate change, 10 (4):277–286, 2020
2020
-
[6]
Understand- ing the role of weather data for earth surface forecasting using a convlstm-based model
Codrut,-Andrei Diaconu, Sudipan Saha, Stephan Günnemann, and Xiao Xiang Zhu. Understand- ing the role of weather data for earth surface forecasting using a convlstm-based model. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1362–1371, 2022
2022
-
[7]
Simvp: Simpler yet better video prediction
Zhangyang Gao, Cheng Tan, Lirong Wu, and Stan Z Li. Simvp: Simpler yet better video prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3170–3180, 2022
2022
-
[8]
Earthformer: Exploring space-time transformers for earth system forecasting.Advances in Neural Information Processing Systems, 35:25390–25403, 2022
Zhihan Gao, Xingjian Shi, Hao Wang, Yi Zhu, Yuyang Bernie Wang, Mu Li, and Dit-Yan Yeung. Earthformer: Exploring space-time transformers for earth system forecasting.Advances in Neural Information Processing Systems, 35:25390–25403, 2022
2022
-
[9]
Ecomapper: Generative modeling for climate-aware satellite imagery
Muhammed Goktepe, Amir hossein Shamseddin, Erencan Uysal, Javier Muinelo Monteagudo, Lukas Drees, Aysim Toker, Senthold Asseng, and Malte V on Bloh. Ecomapper: Generative modeling for climate-aware satellite imagery. InForty-second International Conference on Machine Learning, 2025
2025
-
[10]
Disentangling physical dynamics from unknown factors for unsupervised video prediction
Vincent Le Guen and Nicolas Thome. Disentangling physical dynamics from unknown factors for unsupervised video prediction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11474–11484, 2020
2020
-
[11]
World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
Pith/arXiv arXiv 2018
-
[12]
Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019. 10
Pith/arXiv arXiv 1912
-
[13]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. InInternational conference on machine learning, pages 2555–2565. PMLR, 2019
2019
-
[14]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2022
2021
-
[15]
Diffusion models for video prediction and infilling.Transactions on Machine Learning Research, 2022, 2022
Tobias Höppe, Arash Mehrjou, Stefan Bauer, Didrik Nielsen, and Andrea Dittadi. Diffusion models for video prediction and infilling.Transactions on Machine Learning Research, 2022, 2022
2022
-
[16]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=nZeVKeeFYf9
2022
-
[17]
Siqiao Huang, Jialong Wu, Qixing Zhou, Shangchen Miao, and Mingsheng Long. Vid2world: Crafting video diffusion models to interactive world models.arXiv preprint arXiv:2505.14357, 2025
arXiv 2025
-
[18]
Pascal Janetzky, Florian Gallusser, Simon Hentschel, Andreas Hotho, and Anna Krause. Global vegetation modeling with pre-trained weather transformers.arXiv preprint arXiv:2403.18438, 2024
arXiv 2024
-
[19]
Diffusionsat: A generative foundation model for satellite imagery
Samar Khanna, Patrick Liu, Linqi Zhou, Chenlin Meng, Robin Rombach, Marshall Burke, David B Lobell, and Stefano Ermon. Diffusionsat: A generative foundation model for satellite imagery. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[20]
Enhanced prediction of vegetation responses to extreme drought using deep learning and earth observation data.Ecological Informatics, 80:102474, 2024
Klaus-Rudolf Kladny, Marco Milanta, Oto Mraz, Koen Hufkens, and Benjamin D Stocker. Enhanced prediction of vegetation responses to extreme drought using deep learning and earth observation data.Ecological Informatics, 80:102474, 2024
2024
-
[21]
Nils Lehmann, Yi Wang, Zhitong Xiong, and Xiaoxiang Zhu. Eo-vae: Towards a multi-sensor tokenizer for earth observation data.arXiv preprint arXiv:2602.12177, 2026
arXiv 2026
-
[22]
Stiv: Scalable text and image conditioned video generation
Zongyu Lin, Wei Liu, Chen Chen, Jiasen Lu, Wenze Hu, Tsu-Jui Fu, Jesse Allardice, Zhengfeng Lai, Liangchen Song, Bowen Zhang, et al. Stiv: Scalable text and image conditioned video generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16249–16259, 2025
2025
-
[23]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[24]
Vdt: General-purpose video diffusion transformers via mask modeling
Haoyu Lu, Guoxing Yang, Nanyi Fei, Yuqi Huo, Zhiwu Lu, Ping Luo, and Mingyu Ding. Vdt: General-purpose video diffusion transformers via mask modeling. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[25]
Remote sensing-oriented world model.arXiv preprint arXiv:2509.17808, 2025
Yuxi Lu, Biao Wu, Zhidong Li, Kunqi Li, Chenya Huang, Huacan Wang, Qizhen Lan, Ronghao Chen, Ling Chen, and Bin Liang. Remote sensing-oriented world model.arXiv preprint arXiv:2509.17808, 2025
arXiv 2025
-
[26]
Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048, 2024
Xin Ma, Yaohui Wang, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048, 2024
Pith/arXiv arXiv 2024
-
[27]
Controllable video generation: A survey.arXiv preprint arXiv:2507.16869, 2025
Yue Ma, Kunyu Feng, Zhongyuan Hu, Xinyu Wang, Yucheng Wang, Mingzhe Zheng, Bingyuan Wang, Qinghe Wang, Xuanhua He, Hongfa Wang, et al. Controllable video generation: A survey.arXiv preprint arXiv:2507.16869, 2025
arXiv 2025
-
[28]
Driveworld: 4d pre-trained scene understanding via world models for autonomous driving
Chen Min, Dawei Zhao, Liang Xiao, Jian Zhao, Xinli Xu, Zheng Zhu, Lei Jin, Jianshu Li, Yulan Guo, Junliang Xing, et al. Driveworld: 4d pre-trained scene understanding via world models for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15522–15533, 2024. 11
2024
-
[29]
Syncvp: joint diffusion for synchronous multi-modal video prediction
Enrico Pallotta, Sina Mokhtarzadeh Azar, Shuai Li, Olga Zatsarynna, and Juergen Gall. Syncvp: joint diffusion for synchronous multi-modal video prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13787–13797, 2025
2025
-
[30]
Explainable earth surface forecasting under extreme events.Earth’s Future, 13(9):e2024EF005446, 2025
Oscar J Pellicer-Valero, Miguel-Ángel Fernández-Torres, Chaonan Ji, Miguel D Mahecha, and Gustau Camps-Valls. Explainable earth surface forecasting under extreme events.Earth’s Future, 13(9):e2024EF005446, 2025
2025
-
[31]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[32]
Earthnet2021: A large-scale dataset and challenge for earth surface forecasting as a guided video prediction task
Christian Requena-Mesa, Vitus Benson, Markus Reichstein, Jakob Runge, and Joachim Denzler. Earthnet2021: A large-scale dataset and challenge for earth surface forecasting as a guided video prediction task. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1132–1142, 2021
2021
-
[33]
Avid: Adapting video diffusion models to world models.arXiv preprint arXiv:2410.12822, 2024
Marc Rigter, Tarun Gupta, Agrin Hilmkil, and Chao Ma. Avid: Adapting video diffusion models to world models.arXiv preprint arXiv:2410.12822, 2024
arXiv 2024
-
[34]
Yu Shang, Zhuohang Li, Yiding Ma, Weikang Su, Xin Jin, Ziyou Wang, Lei Jin, Xin Zhang, Yinzhou Tang, Haisheng Su, et al. Worldarena: A unified benchmark for evaluating perception and functional utility of embodied world models.arXiv preprint arXiv:2602.08971, 2026
arXiv 2026
-
[35]
Vit-koop: Vision-transformer-koopman operators for efficient time-series forecasting of earth-observation data
Takayuki Shinohara. Vit-koop: Vision-transformer-koopman operators for efficient time-series forecasting of earth-observation data. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 2835–2844, October 2025
2025
-
[36]
Restore-dit: Reliable satellite image time series reconstruction by multimodal sequential diffusion transformer.Remote Sensing of Environment, 328:114872, 2025
Qidi Shu, Xiaolin Zhu, Shuai Xu, Yan Wang, and Denghong Liu. Restore-dit: Reliable satellite image time series reconstruction by multimodal sequential diffusion transformer.Remote Sensing of Environment, 328:114872, 2025
2025
-
[37]
Earthpt: a foundation model for earth observation.European Geosciences Union General Assembly 2024 (EGU24), page 1760, 2024
Michael Smith, Luke Fleming, and James Geach. Earthpt: a foundation model for earth observation.European Geosciences Union General Assembly 2024 (EGU24), page 1760, 2024
2024
-
[38]
Jason Stock, Jaideep Pathak, Yair Cohen, Mike Pritchard, Piyush Garg, Dale Durran, Morteza Mardani, and Noah Brenowitz. Diffobs: Generative diffusion for global forecasting of satellite observations.arXiv preprint arXiv:2404.06517, 2024
arXiv 2024
-
[39]
Temporal attention unit: Towards efficient spatiotemporal predictive learning
Cheng Tan, Zhangyang Gao, Lirong Wu, Yongjie Xu, Jun Xia, Siyuan Li, and Stan Z Li. Temporal attention unit: Towards efficient spatiotemporal predictive learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18770–18782, 2023
2023
-
[40]
Openstl: A comprehensive benchmark of spatio-temporal predictive learning
Cheng Tan, Siyuan Li, Zhangyang Gao, Wenfei Guan, Zedong Wang, Zicheng Liu, Lirong Wu, and Stan Z Li. Openstl: A comprehensive benchmark of spatio-temporal predictive learning. In Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023
2023
-
[41]
Advancing open-source world models
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, et al. Advancing open-source world models. arXiv preprint arXiv:2601.20540, 2026
Pith/arXiv arXiv 2026
-
[42]
Forecasting dryland vegetation condition months in advance through satellite data assimilation.Nature Communica- tions, 10(1):469, 2019
Siyuan Tian, Albert IJM Van Dijk, Paul Tregoning, and Luigi J Renzullo. Forecasting dryland vegetation condition months in advance through satellite data assimilation.Nature Communica- tions, 10(1):469, 2019
2019
-
[43]
A control-centric benchmark for video prediction
Stephen Tian, Chelsea Finn, and Jiajun Wu. A control-centric benchmark for video prediction. InInternational Conference on Learning Representations, 2023
2023
-
[44]
Attribution of climate extreme events.Nature climate change, 5(8):725–730, 2015
Kevin E Trenberth, John T Fasullo, and Theodore G Shepherd. Attribution of climate extreme events.Nature climate change, 5(8):725–730, 2015
2015
-
[45]
Crop yield prediction using machine learning: A systematic literature review.Computers and electronics in agriculture, 177:105709, 2020
Thomas Van Klompenburg, Ayalew Kassahun, and Cagatay Catal. Crop yield prediction using machine learning: A systematic literature review.Computers and electronics in agriculture, 177:105709, 2020. 12
2020
-
[46]
Mcvd-masked conditional video dif- fusion for prediction, generation, and interpolation.Advances in neural information processing systems, 35:23371–23385, 2022
Vikram V oleti, Alexia Jolicoeur-Martineau, and Chris Pal. Mcvd-masked conditional video dif- fusion for prediction, generation, and interpolation.Advances in neural information processing systems, 35:23371–23385, 2022
2022
-
[47]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[48]
Angtian Wang, Haibin Huang, Jacob Zhiyuan Fang, Yiding Yang, and Chongyang Ma. Ati: Any trajectory instruction for controllable video generation.arXiv preprint arXiv:2505.22944, 2025
arXiv 2025
-
[49]
Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms.Advances in neural information processing systems, 30, 2017
Yunbo Wang, Mingsheng Long, Jianmin Wang, Zhifeng Gao, and Philip S Yu. Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms.Advances in neural information processing systems, 30, 2017
2017
-
[50]
Predrnn: A recurrent neural network for spatiotemporal predictive learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):2208–2225, 2022
Yunbo Wang, Haixu Wu, Jianjin Zhang, Zhifeng Gao, Jianmin Wang, Philip S Yu, and Ming- sheng Long. Predrnn: A recurrent neural network for spatiotemporal predictive learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):2208–2225, 2022
2022
-
[51]
Rs-worldmodel: a unified model for remote sensing understanding and future sense forecasting
Linrui Xu, Zhongan Wang, Fei Shen, Gang Xu, Huiping Zhuang, Ming Li, and Haifeng Li. Rs-worldmodel: a unified model for remote sensing understanding and future sense forecasting. arXiv preprint arXiv:2603.14941, 2026
arXiv 2026
-
[52]
Xiaojie Xu, Zhengyuan Lin, Kang He, Yukang Feng, Xiaofeng Mao, Yuanyang Yin, Kaipeng Zhang, and Yongtao Ge. Worldmark: A unified benchmark suite for interactive video world models.arXiv preprint arXiv:2604.21686, 2026
Pith/arXiv arXiv 2026
-
[53]
Zhenya Yang, Zhe Liu, Yuxiang Lu, Liping Hou, Chenxuan Miao, Siyi Peng, Bailan Feng, Xiang Bai, and Hengshuang Zhao. Geniedrive: Towards physics-aware driving world model with 4d occupancy guided video generation.arXiv preprint arXiv:2512.12751, 2025
arXiv 2025
-
[54]
Stdiff: Spatio-temporal diffusion for continuous stochastic video prediction
Xi Ye and Guillaume-Alexandre Bilodeau. Stdiff: Spatio-temporal diffusion for continuous stochastic video prediction. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 6666–6674, 2024
2024
-
[55]
Units: Unified time series generative model for remote sensing.arXiv preprint arXiv:2512.04461, 2025
Yuxiang Zhang, Shunlin Liang, Wenyuan Li, Han Ma, Jianglei Xu, Yichuan Ma, Jiangwei Xie, Wei Li, Mengmeng Zhang, Ran Tao, et al. Units: Unified time series generative model for remote sensing.arXiv preprint arXiv:2512.04461, 2025
arXiv 2025
-
[56]
Extdm: Distri- bution extrapolation diffusion model for video prediction
Zhicheng Zhang, Junyao Hu, Wentao Cheng, Danda Paudel, and Jufeng Yang. Extdm: Distri- bution extrapolation diffusion model for video prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19310–19320, 2024
2024
-
[57]
Vegediff: Latent diffusion model for geospatial vegetation forecasting.IEEE Transactions on Geoscience and Remote Sensing, 2025
Sijie Zhao, Hao Chen, Xueliang Zhang, Pengfeng Xiao, and Lei Bai. Vegediff: Latent diffusion model for geospatial vegetation forecasting.IEEE Transactions on Geoscience and Remote Sensing, 2025
2025
-
[58]
Zangwei Zheng, Xiangyu Peng, Yuxuan Lou, Chenhui Shen, Tom Young, Xinying Guo, Binluo Wang, Hang Xu, Hongxin Liu, Mingyan Jiang, et al. Open-sora 2.0: Training a commercial-level video generation model in $200 k.arXiv preprint arXiv:2503.09642, 2025
Pith/arXiv arXiv 2025
-
[59]
EO cond
Zhuo Zheng, Stefano Ermon, Dongjun Kim, Liangpei Zhang, and Yanfei Zhong. Changen2: Multi-temporal remote sensing generative change foundation model.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(2):725–741, 2024. 13 A Technical appendices and supplementary material We organize our supplementary material as follows. Section A.1 provide...
2024
-
[60]
Within each track, we rank pairs by their respective divergence score (descending)
-
[61]
Per seasonal phase (3 phases: offsets 0, 20, 40), we select the top 50 highest-divergence pairs, yielding 150 pairs per track
-
[62]
A per-cube cap of 3 pairs prevents any single location from dominating the benchmark
-
[63]
how much
The three track selections are merged via union and deduplicated by pair identity. Each pair retains metadata indicating which track(s) selected it and its rank within each track. The final benchmark contains422 unique pairs(844 inference windows). Multi-track membership provides complementary evaluation perspectives: 394 pairs belong to a single paper-fa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.