Reference-Driven Multi-Speaker Audio Scene Generation from In-the-Wild Priors
Pith reviewed 2026-06-26 19:02 UTC · model grok-4.3
The pith
ScenA conditions a text-to-audio flow-matching model on reference voices and scene descriptions to produce natural multi-speaker conversations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
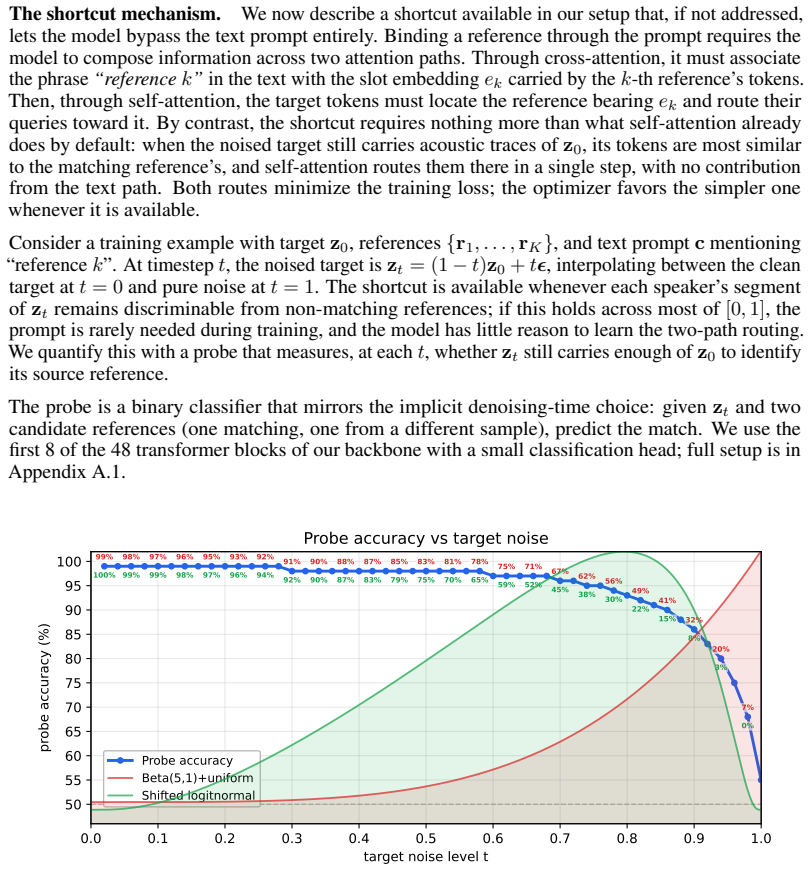
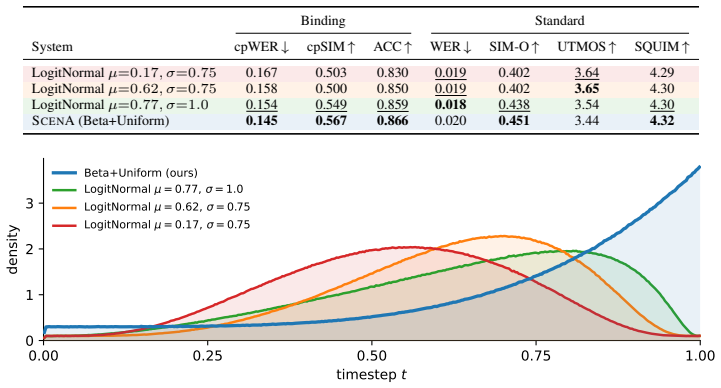
Our method, ScenA, conditions a text-to-audio flow-matching foundation model, pretrained on large-scale in-the-wild data, directly on multiple reference voices and a free-form natural language prompt that describes an entire multi-speaker audio scene. Leveraging such a foundational model allows us to inherit its capacity for natural, non-studio audio: background noise, room acoustics, overlapping dialogue, and spontaneous paralinguistic events, while adding multi-speaker control without any per-turn structure. Reference latents are concatenated into the model's token sequence and distinguished by lightweight identity-aware positional encodings. A high-noise-biased timestep distribution addre
What carries the argument
High-noise-biased timestep distribution that prevents the Reference Shortcut, where the model would otherwise match references by acoustic similarity instead of using the text prompt; reference latents concatenated with identity-aware positional encodings.
Load-bearing premise
The high-noise-biased timestep distribution forces the model to rely on the text prompt for speaker assignment rather than acoustic similarity, and that this does not degrade other generation qualities or require additional unstated adjustments to the foundation model.
What would settle it
If ScenA fails to outperform existing systems on speaker-binding metrics when evaluated on the CoVoMix2-Dialogue benchmark, or if the high-noise bias is removed and the shortcut still appears without quality loss, the central mechanism would be shown ineffective.
Figures




read the original abstract
Existing multi-speaker dialogue systems bind speakers to utterances through structured supervision: per-turn tags, multi-stream transcriptions, or learnable speaker embeddings. These systems operate within speech-only pipelines that produce clean vocal sequences without the ambient texture of real conversations. We take a different approach. Our method, ScenA, conditions a text-to-audio flow-matching foundation model, pretrained on large-scale in-the-wild data, directly on multiple reference voices and a free-form natural language prompt that describes an entire multi-speaker audio scene. Leveraging such a foundational model allows us to inherit its capacity for natural, non-studio audio: background noise, room acoustics, overlapping dialogue, and spontaneous paralinguistic events, while adding multi-speaker control without any per-turn structure. Concretely, reference latents are concatenated into the model's token sequence and distinguished by lightweight identity-aware positional encodings. However, we identify a critical obstacle to this approach: the \textit{Reference Shortcut}. During training under standard noise schedules, the model can identify the matching reference by acoustic similarity to the noisy target, bypassing the text prompt entirely. We address this with a high-noise-biased timestep distribution that forces the model to rely on the text prompt for speaker assignment. We evaluate ScenA on the CoVoMix2-Dialogue benchmark, showing that it outperforms existing multi-speaker systems on speaker-binding metrics while generating rich conversational audio with overlapping speech, emotional vocalizations, and ambient sound. Our results demonstrate the advantage of using a general-purpose audio model conditioned on a free-form scene description, rather than passing structured dialog scripts through a speech-only pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ScenA, which conditions a pretrained text-to-audio flow-matching foundation model on multiple reference voice latents (concatenated with identity-aware positional encodings) and a free-form natural language scene prompt. It identifies a 'Reference Shortcut' under standard noise schedules and proposes a high-noise-biased timestep distribution to force reliance on the text prompt for speaker assignment rather than acoustic matching. The method is evaluated on the CoVoMix2-Dialogue benchmark and claims to outperform existing multi-speaker systems on speaker-binding metrics while generating rich conversational audio containing overlaps, emotional vocalizations, and ambient sounds.
Significance. If the central claims hold, the work would be significant for demonstrating that general-purpose in-the-wild audio foundation models can be adapted for multi-speaker control without structured supervision (per-turn tags or learnable embeddings), while preserving capabilities for non-studio audio. The approach avoids speech-only pipelines and inherits ambient and paralinguistic richness from the base model.
major comments (2)
- [Method (timestep distribution paragraph)] The high-noise-biased timestep distribution is presented as the solution to the Reference Shortcut (forcing text-prompt speaker assignment), yet no ablation is reported that isolates its effect—e.g., by removing the bias, using mismatched text prompts while keeping references, or measuring degradation on non-binding metrics (overlap quality, ambient sound fidelity) relative to the original foundation-model schedule. This verification is load-bearing for the claim that the schedule blocks acoustic shortcuts without side effects.
- [Abstract] Abstract: the central claim of outperformance on speaker-binding metrics is stated without any quantitative numbers, baselines, error bars, or ablation details, so the magnitude and validity of the reported gains on CoVoMix2-Dialogue cannot be assessed from the provided text.
minor comments (1)
- [Abstract] The abstract refers to the 'CoVoMix2-Dialogue benchmark' without a citation or brief description of its construction or speaker-binding metrics; this should be added for readers unfamiliar with the dataset.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (timestep distribution paragraph)] The high-noise-biased timestep distribution is presented as the solution to the Reference Shortcut (forcing text-prompt speaker assignment), yet no ablation is reported that isolates its effect—e.g., by removing the bias, using mismatched text prompts while keeping references, or measuring degradation on non-binding metrics (overlap quality, ambient sound fidelity) relative to the original foundation-model schedule. This verification is load-bearing for the claim that the schedule blocks acoustic shortcuts without side effects.
Authors: We agree that an ablation isolating the contribution of the high-noise-biased timestep distribution is necessary to substantiate its role in mitigating the Reference Shortcut. The current manuscript does not include such experiments. In the revision we will add targeted ablations comparing the biased schedule against the standard foundation-model schedule, including mismatched prompt conditions and quantitative assessment of non-binding metrics such as overlap quality and ambient fidelity. revision: yes
-
Referee: [Abstract] Abstract: the central claim of outperformance on speaker-binding metrics is stated without any quantitative numbers, baselines, error bars, or ablation details, so the magnitude and validity of the reported gains on CoVoMix2-Dialogue cannot be assessed from the provided text.
Authors: We accept that the abstract would be strengthened by including concrete quantitative results. The provided abstract summarizes the evaluation outcome without specific numbers or baselines. We will revise the abstract to report key speaker-binding metrics, primary baselines, and associated error bars while preserving its brevity. revision: yes
Circularity Check
No significant circularity; method is a conditioning extension on a pretrained model with an explicit schedule change.
full rationale
The paper presents ScenA as conditioning a pretrained text-to-audio flow-matching foundation model on reference latents via concatenation and identity-aware positional encodings, plus a high-noise-biased timestep distribution to avoid the 'Reference Shortcut'. No equations, derivations, or predictions are shown that reduce by construction to author-defined fits or self-citations. The timestep distribution is introduced as a training modification to force text-prompt reliance, not derived from prior self-work or fitted parameters renamed as outputs. The approach inherits capacity from the external foundation model and evaluates on an external benchmark (CoVoMix2-Dialogue). This is self-contained against external benchmarks with no load-bearing self-citation chains or self-definitional reductions.
Axiom & Free-Parameter Ledger
free parameters (1)
- high-noise-biased timestep distribution parameters
axioms (1)
- domain assumption The pretrained flow-matching foundation model already encodes natural room acoustics, overlaps, and paralinguistic events from in-the-wild data.
Reference graph
Works this paper leans on
-
[1]
Seed-TTS: A family of high-quality versatile speech generation models, 2024
Philip Anastassiou, Jiawei Chen, Jitong Chen, Yuanzhe Chen, Zhuo Chen, Ziyi Chen, Jian Cong, Lelai Deng, Chuang Ding, Lu Gao, Mingqing Gong, Peisong Huang, Qingqing Huang, Zhiying Huang, Yuanyuan Huo, Dongya Jia, Chumin Li, Feiya Li, Hui Li, Jiaxin Li, Xiaoyang Li, Xingxing Li, Lin Liu, Shouda Liu, Sichao Liu, Xudong Liu, Yuchen Liu, Zhengxi Liu, Lu Lu, J...
2024
-
[2]
pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe
Hervé Bredin. pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe. InProc. INTERSPEECH 2023, pages 1983–1987, 2023
2023
-
[3]
XTTS: A massively multilingual zero-shot text-to-speech model
Edresson Casanova, Kelly Davis, Eren Gölge, Görkem Göknar, Iulian Gulea, Logan Hart, Aya Aljafari, Joshua Meyer, Reuben Morais, Samuel Olayemi, and Julian Weber. XTTS: A massively multilingual zero-shot text-to-speech model. InProc. INTERSPEECH, 2024
2024
-
[4]
WavLM: Large-scale self-supervised pre-training for full stack speech processing.IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518, 2022
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Xiangzhan Yu, and Furu Wei. WavLM: Large-scale self-supervised pre-training for full stack speech processing.IEEE Journal of Selected Topics in Signal Pr...
2022
-
[5]
V ALL-E 2: Neural codec language models are human parity zero-shot text to speech synthesizers, 2024
Sanyuan Chen, Shujie Liu, Long Zhou, Yanqing Liu, Xu Tan, Jinyu Li, Sheng Zhao, Yao Qian, and Furu Wei. V ALL-E 2: Neural codec language models are human parity zero-shot text to speech synthesizers, 2024
2024
-
[6]
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, Jian Zhao, Kai Yu, and Xie Chen. F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching.arXiv preprint arXiv:2410.06885, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Simple and controllable music generation
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. Simple and controllable music generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[8]
MAGREF: Masked guidance for any-reference video generation with subject disentanglement, 2025
Yufan Deng, Yuanyang Yin, Xun Guo, Yizhi Wang, Jacob Zhiyuan Fang, Shenghai Yuan, Yiding Yang, Angtian Wang, Bo Liu, Haibin Huang, and Chongyang Ma. MAGREF: Masked guidance for any-reference video generation with subject disentanglement, 2025
2025
-
[9]
CosyV oice 2: Scalable streaming speech synthesis with large language models, 2024
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, Fan Yu, Huadai Liu, Zhengyan Sheng, Yue Gu, Chong Deng, Wen Wang, Shiliang Zhang, Zhijie Yan, and Jingren Zhou. CosyV oice 2: Scalable streaming speech synthesis with large language models, 2024
2024
-
[10]
CosyV oice 3: Towards in-the-wild speech generation via scaling-up and post-training, 2025
Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tianyu Zhao, Hao Wang, Xiang Lv, Hui Wang, Chongjia Ni, Xian Shi, Keyu An, Guanrou Yang, Yabin Li, Yanni Chen, Zhifu Gao, Qian Chen, Yue Gu, Mengzhe Chen, Yafeng Chen, Shiliang Zhang, Wen Wang, and Jieping Ye. CosyV oice 3: Towards in-the-wild speech generation via scaling-up and post-training, 2025
2025
-
[11]
E2 TTS: Embarrassingly easy fully non-autoregressive zero-shot TTS
Sefik Emre Eskimez, Xiaofei Wang, Manthan Thakker, Canrun Li, Chung-Hsien Tsai, Zhen Xiao, Hemin Yang, Zirun Zhu, Min Tang, Xu Tan, Yanqing Liu, Sheng Zhao, and Naoyuki Kanda. E2 TTS: Embarrassingly easy fully non-autoregressive zero-shot TTS. InIEEE Spoken Language Technology Workshop (SLT), 2024
2024
-
[12]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InInternational Conference on Machin...
2024
-
[13]
LTX-2: Efficient joint audio-visual foundation model, 2026
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, Eitan Richardson, Guy Shiran, Itay Chachy, Jonathan Chetboun, Michael Finkelson, Michael Kupchick, Nir Zabari, Nitzan Guetta, Noa Kotler, Ofir Bibi, Ori Gordon, Poriya Panet, Roi Benita, Shahar Armon, V...
2026
-
[14]
Efficient diffusion training via Min-SNR weighting strategy
Tiankai Hang, Shuyang Gu, Chen Li, Jianmin Bao, Dong Chen, Han Hu, Xin Geng, and Baining Guo. Efficient diffusion training via Min-SNR weighting strategy. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[15]
Simple diffusion: End-to-end diffusion for high resolution images
Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. Simple diffusion: End-to-end diffusion for high resolution images. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[16]
In-context LoRA for diffusion transformers, 2024
Lianghua Huang, Wei Wang, Zhi-Fan Wu, Yupeng Shi, Huanzhang Dou, Chen Liang, Yutong Feng, Yu Liu, and Jingren Zhou. In-context LoRA for diffusion transformers, 2024
2024
-
[17]
Identity decoupling for multi- subject personalization of text-to-image models, 2024
Sangwon Jang, Jaehyeong Jo, Kimin Lee, and Sung Ju Hwang. Identity decoupling for multi- subject personalization of text-to-image models, 2024
2024
-
[18]
Megatts 3: Sparse alignment enhanced latent diffusion transformer for zero-shot speech synthe- sis,
Ziyue Jiang, Yi Ren, Ruiqi Li, Shengpeng Ji, Boyang Zhang, Zhenhui Ye, Chen Zhang, Jionghao Bai, Xiaoda Yang, Jialong Zuo, Yu Zhang, Rui Liu, Xiang Yin, and Zhou Zhao. MegaTTS 3: Sparse alignment enhanced latent diffusion transformer for zero-shot speech synthesis.arXiv preprint arXiv:2502.18924, 2025
-
[19]
NaturalSpeech 3: Zero-shot speech synthesis with factorized codec and diffusion models
Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Yanqing Liu, Yichong Leng, Kaitao Song, Siliang Tang, Zhizheng Wu, Tao Qin, Xiang-Yang Li, Wei Ye, Shikun Zhang, Jiang Bian, Lei He, Jinyu Li, and Sheng Zhao. NaturalSpeech 3: Zero-shot speech synthesis with factorized codec and diffusion models. InInternational Conference on Machine L...
2024
-
[20]
MoonCast: High-quality zero-shot podcast generation
Zeqian Ju, Dongchao Yang, Jianwei Yu, Kai Shen, Yichong Leng, Zhengtao Wang, Xu Tan, Xinyu Zhou, Tao Qin, and Xiangyang Li. MoonCast: High-quality zero-shot podcast generation. arXiv preprint arXiv:2503.14345, 2025
-
[21]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[22]
TorchAudio-Squim: Reference-less speech quality and intelligibility measures in TorchAudio
Anurag Kumar, Ke Tan, Zhaoheng Ni, Pranay Manocha, Xiaohui Zhang, Ethan Henderson, and Buye Xu. TorchAudio-Squim: Reference-less speech quality and intelligibility measures in TorchAudio. InICASSP 2023 – 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
2023
-
[23]
V oicebox: Text-guided multilingual universal speech generation at scale
Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, and Wei-Ning Hsu. V oicebox: Text-guided multilingual universal speech generation at scale. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), 2023
2023
-
[24]
DailyDialog: A manually labelled multi-turn dialogue dataset
Yanran Li, Hui Su, Xiaoyu Shen, Wenjie Li, Ziqiang Cao, and Shuzi Niu. DailyDialog: A manually labelled multi-turn dialogue dataset. InProceedings of the Eighth International Joint Conference on Natural Language Processing (IJCNLP), 2017
2017
-
[25]
Raghavan, Gavin Mischler, and Nima Mesgarani
Yinghao Aaron Li, Cong Han, Vinay S. Raghavan, Gavin Mischler, and Nima Mesgarani. StyleTTS 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[26]
PhotoMaker: Customizing realistic human photos via stacked ID embedding
Zhen Li, Mingdeng Cao, Xintao Wang, Zhongang Qi, Ming-Ming Cheng, and Ying Shan. PhotoMaker: Customizing realistic human photos via stacked ID embedding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[27]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[28]
Plumbley
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, and Mark D. Plumbley. AudioLDM 2: Learning holistic audio generation with self-supervised pretraining, 2023
2023
-
[29]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[30]
Dia: A TTS model capable of generating ultra-realistic dialogue in one pass
Nari Labs. Dia: A TTS model capable of generating ultra-realistic dialogue in one pass. GitHub repository, 2024. Open-weights release.https://github.com/nari-labs/dia. 11
2024
-
[31]
Librispeech: An ASR corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: An ASR corpus based on public domain audio books. In2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5206–5210, 2015. doi: 10.1109/ ICASSP.2015.7178964
-
[32]
V oiceStar: Robust zero-shot autoregressive TTS with duration control and extrapolation, 2025
Puyuan Peng, Shang-Wen Li, Abdelrahman Mohamed, and David Harwath. V oiceStar: Robust zero-shot autoregressive TTS with duration control and extrapolation, 2025
2025
-
[33]
VibeV oice technical report, 2025
Zhiliang Peng, Jianwei Yu, Wenhui Wang, Yaoyao Chang, Yutao Sun, Li Dong, Yi Zhu, Weijiang Xu, Hangbo Bao, Zehua Wang, Shaohan Huang, Yan Xia, and Furu Wei. VibeV oice technical report, 2025
2025
-
[34]
Scaling speech technology to 1,000+ languages.Journal of Machine Learning Research, 25(97):1–52, 2024
Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, and Michael Auli. Scaling speech technology to 1,000+ languages.Journal of Machine Learning Research, 25(97):1–52, 2024
2024
-
[35]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InProceedings of the 40th International Conference on Machine Learning (ICML), 2023
2023
-
[36]
UTMOS: UTokyo-SaruLab system for V oiceMOS challenge 2022
Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. UTMOS: UTokyo-SaruLab system for V oiceMOS challenge 2022. InProc. INTERSPEECH 2022, pages 4521–4525, 2022
2022
-
[37]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.arXiv preprint arXiv:2104.09864, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[38]
Audiobox: Unified audio generation with natural language prompts, 2023
Apoorv Vyas, Bowen Shi, Matthew Le, Andros Tjandra, Yi-Chiao Wu, Baishan Guo, Jiemin Zhang, Xinyue Zhang, Robert Adkins, William Ngan, Jeff Wang, Ivan Cruz, Bapi Akula, Akinniyi Akinyemi, Brian Ellis, Rashel Moritz, Yael Yungster, Alice Rakotoarison, Liang Tan, Chris Summers, Carleigh Wood, Joshua Lane, Mary Williamson, and Wei-Ning Hsu. Audiobox: Unified...
2023
-
[39]
Neural codec language models are zero-shot text to speech synthesizers, 2023
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, Lei He, Sheng Zhao, and Furu Wei. Neural codec language models are zero-shot text to speech synthesizers, 2023
2023
-
[40]
InstantID: Zero-shot identity-preserving generation in seconds, 2024
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, Anthony Chen, Huaxia Li, Xu Tang, and Yao Hu. InstantID: Zero-shot identity-preserving generation in seconds, 2024
2024
-
[41]
MS-Diffusion: Multi- subject zero-shot image personalization with layout guidance, 2024
Xierui Wang, Siming Fu, Qihan Huang, Wanggui He, and Hao Jiang. MS-Diffusion: Multi- subject zero-shot image personalization with layout guidance, 2024
2024
-
[42]
Spark-TTS: An efficient LLM-based text-to-speech model with single-stream decoupled speech tokens, 2025
Xinsheng Wang, Mingqi Jiang, Ziyang Ma, Ziyu Zhang, Songxiang Liu, Linqin Li, Zheng Liang, Qixi Zheng, Rui Wang, Xiaoqin Feng, Weizhen Bian, Zhen Ye, Sitong Cheng, Ruibin Yuan, Zhixian Zhao, Xinfa Zhu, Jiahao Pan, Liumeng Xue, Pengcheng Zhu, Yunlin Chen, Zhifei Li, Xie Chen, Lei Xie, Yike Guo, and Wei Xue. Spark-TTS: An efficient LLM-based text-to-speech ...
2025
-
[43]
CHiME-6 challenge: Tackling multispeaker speech recognition for unsegmented recordings
Shinji Watanabe, Michael Mandel, Jon Barker, Emmanuel Vincent, Ashish Arora, Xu- ankai Chang, Sanjeev Khudanpur, Vimal Manohar, Daniel Povey, Desh Raj, David Snyder, Aswin Shanmugam Subramanian, Jan Trmal, Bar Ben Yair, Christoph Boeddeker, Zhaoheng Ni, Yusuke Fujita, Shota Horiguchi, Naoyuki Kanda, Takuya Yoshioka, and Neville Ryant. CHiME-6 challenge: T...
2020
-
[44]
Less-to-more generalization: Unlocking more controllability by in-context generation, 2025
Shaojin Wu, Mengqi Huang, Wenxu Wu, Yufeng Cheng, Fei Ding, and Qian He. Less-to-more generalization: Unlocking more controllability by in-context generation, 2025
2025
-
[45]
Freeman, Frédo Durand, and Song Han
Guangxuan Xiao, Tianwei Yin, William T. Freeman, Frédo Durand, and Song Han. FastCom- poser: Tuning-free multi-subject image generation with localized attention, 2023
2023
-
[46]
OmniGen: Unified image generation, 2024
Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xingrun Xing, Ruiran Yan, Chaofan Li, Shuting Wang, Tiejun Huang, and Zheng Liu. OmniGen: Unified image generation, 2024
2024
-
[47]
DialoSpeech: Dual-speaker dialogue generation with LLM and flow matching, 2025
Hanke Xie, Dake Guo, Chengyou Wang, Yue Li, Wenjie Tian, Xinfa Zhu, Xinsheng Wang, Xiulin Li, Guanqiong Miao, Bo Liu, and Lei Xie. DialoSpeech: Dual-speaker dialogue generation with LLM and flow matching, 2025. 12
2025
-
[48]
SoulX-Podcast: Towards realistic long-form podcasts with dialectal and paralinguistic diversity, 2025
Hanke Xie, Haopeng Lin, Wenxiao Cao, Dake Guo, Wenjie Tian, Jun Wu, Hanlin Wen, Ruixuan Shang, Hongmei Liu, Zhiqi Jiang, Yuepeng Jiang, Wenxi Chen, Ruiqi Yan, Jiale Qian, Yichao Yan, Shunshun Yin, Ming Tao, Xie Chen, Lei Xie, and Xinsheng Wang. SoulX-Podcast: Towards realistic long-form podcasts with dialectal and paralinguistic diversity, 2025
2025
-
[49]
FireRedTTS-2: Towards long conversational speech generation for podcast and chatbot, 2025
Kun Xie, Feiyu Shen, Junjie Li, Fenglong Xie, Xu Tang, and Yao Hu. FireRedTTS-2: Towards long conversational speech generation for podcast and chatbot, 2025
2025
-
[50]
IP-Adapter: Text compatible image prompt adapter for text-to-image diffusion models, 2023
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. IP-Adapter: Text compatible image prompt adapter for text-to-image diffusion models, 2023
2023
-
[51]
JoyV oice: Long-context conditioning for anthropomorphic multi-speaker conversational synthesis, 2025
Fan Yu, Tao Wang, You Wu, Lin Zhu, Wei Deng, Weisheng Han, Wenchao Wang, Lin Hu, Xiangyu Liang, Xiaodong He, Yankun Huang, Yu Gu, Yuan Liu, Yuxuan Wang, Zhangyu Xiao, Ziteng Wang, Boya Dong, Feng Dang, Jinming Chen, Jingdong Li, Jun Wang, Yechen Jin, Yuan Zhang, Zhengyan Sheng, and Xin Wang. JoyV oice: Long-context conditioning for anthropomorphic multi-s...
2025
-
[52]
Bowen Zhang, Congchao Guo, Geng Yang, Hang Yu, Haozhe Zhang, Heidi Lei, Jialong Mai, Junjie Yan, Kaiyue Yang, Mingqi Yang, Peikai Huang, Ruiyang Jin, Sitan Jiang, Weihua Cheng, Yawei Li, Yichen Xiao, Yiying Zhou, Yongmao Zhang, Yuan Lu, and Yucen He. MiniMax- Speech: Intrinsic zero-shot text-to-speech with a learnable speaker encoder.arXiv preprint arXiv:...
-
[53]
CoV oMix: Advancing zero-shot speech generation for human-like multi-talker conversations
Leying Zhang, Yao Qian, Long Zhou, Shujie Liu, Dongmei Wang, Xiaofei Wang, Midia Yousefi, Yanmin Qian, Jinyu Li, Lei He, Sheng Zhao, and Michael Zeng. CoV oMix: Advancing zero-shot speech generation for human-like multi-talker conversations. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[54]
CoV oMix2: Advancing zero-shot dialogue generation with fully non-autoregressive flow matching, 2025
Leying Zhang, Yao Qian, Xiaofei Wang, Manthan Thakker, Dongmei Wang, Jianwei Yu, Haibin Wu, Yuxuan Hu, Jinyu Li, Yanmin Qian, and Sheng Zhao. CoV oMix2: Advancing zero-shot dialogue generation with fully non-autoregressive flow matching, 2025
2025
-
[55]
MOSS-TTSD: Text to spoken dialogue generation, 2026
Yuqian Zhang, Donghua Yu, Zhengyuan Lin, Botian Jiang, Mingshu Chen, Yaozhou Jiang, Yiwei Zhao, Yiyang Zhang, Yucheng Yuan, Hanfu Chen, Kexin Huang, Jun Zhan, Cheng Chang, Zhaoye Fei, Shimin Li, Xiaogui Yang, Qinyuan Cheng, and Xipeng Qiu. MOSS-TTSD: Text to spoken dialogue generation, 2026
2026
-
[56]
ZipV oice-Dialog: Non-autoregressive spoken dialogue generation with flow matching, 2025
Han Zhu, Wei Kang, Liyong Guo, Zengwei Yao, Fangjun Kuang, Weiji Zhuang, Zhaoqing Li, Zhifeng Han, Dong Zhang, Xin Zhang, Xingchen Song, Lingxuan Ye, Long Lin, and Daniel Povey. ZipV oice-Dialog: Non-autoregressive spoken dialogue generation with flow matching, 2025
2025
-
[57]
Han Zhu, Wei Kang, Zengwei Yao, Liyong Guo, Fangjun Kuang, Zhaoqing Li, Weiji Zhuang, Long Lin, and Daniel Povey. ZipV oice: Fast and high-quality zero-shot text-to-speech with flow matching. InIEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2025. 13 A Supplementary A.1 Reference Shortcut Probe Setup The probe is trained on a binary c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.