Scalable Behavior Cloning with Open Data, Training, and Evaluation
Pith reviewed 2026-06-26 04:12 UTC · model grok-4.3
The pith
An open-source stack called ABC supplies the largest public teleoperation dataset of 130K episodes to scale behavior cloning for robot manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
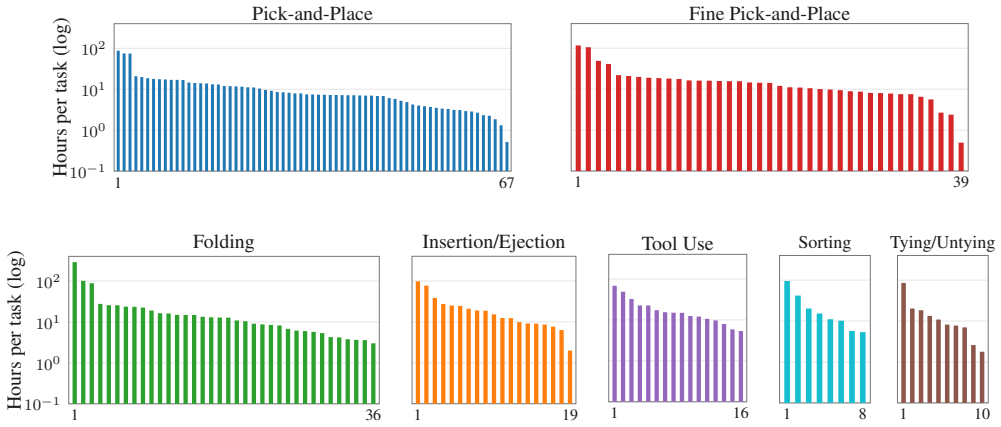
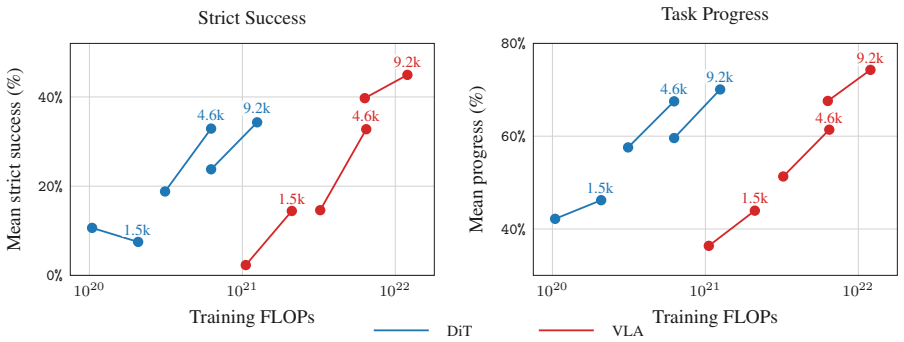
We introduce ABC, a fully open-source stack for manipulation with behavior cloning. At its core is ABC-130K: the largest open-source teleoperation dataset to date, featuring 3,500 hours of data spanning over 130K episodes across 195 diverse tasks. Furthermore, we open-source our accessible hardware setup, training infrastructure, and simulation pipeline. We also release 400 hours of sim-teleop data and provide a co-training recipe that produces correlated simulation and real-world evaluation, offering a reliable proxy for ablating model-design and training decisions before costly real-world evaluation. We explore various training recipes and compare common architectural choices for Diffusion
What carries the argument
ABC-130K, the teleoperation dataset of 130K episodes that supplies the training examples, paired with a co-training procedure that makes simulation results track real-robot performance.
If this is right
- Policies trained on the released data can perform concrete dexterous actions such as folding boxes and removing credit cards from wallets.
- The open hardware, training code, and simulation pipeline allow any lab to reproduce the same experimental conditions.
- Model comparisons between Diffusion Transformers and Vision-Language-Action networks rest on measured real-world success rates rather than simulation alone.
- The 400 hours of additional sim-teleop data can be mixed with real data during training without requiring new robot hardware.
- The 195-task coverage supplies a broad base for testing generalization across manipulation skills.
Where Pith is reading between the lines
- Labs without access to proprietary robot fleets could now run the same ablation studies that previously required closed data.
- The correlation between simulated and real performance could be tested on entirely new task families to see whether the proxy holds outside the original 195 tasks.
- Releasing both the dataset and the exact training scripts creates a fixed benchmark that later papers can cite when claiming improvements.
Load-bearing premise
The co-training recipe produces simulation results that reliably predict which models and training choices will work best on real robots.
What would settle it
Run the same set of models on real robots after selecting the best ones by the co-training proxy; if the ranking of models by real success rate differs from the ranking produced by the proxy, the claim that the proxy is reliable is falsified.
Figures















read the original abstract
We introduce ABC, a fully open-source stack for manipulation with behavior cloning. At its core is ABC-130K: the largest open-source teleoperation dataset to date, featuring 3,500 hours of data spanning over 130K episodes across 195 diverse tasks. Furthermore, we open-source our accessible hardware setup, training infrastructure, and simulation pipeline. We also release 400 hours of sim-teleop data and provide a co-training recipe that produces correlated simulation and real-world evaluation, offering a reliable proxy for ablating model-design and training decisions before costly real-world evaluation. We explore various training recipes and compare common architectural choices for Diffusion Transformers (DiT) and Vision-Language-Action (VLA) models, grounding our findings in real-world evaluations. The resulting policies successfully execute dexterous tasks such as box folding and extracting credit cards from wallets. By providing a reproducible toolkit, we aim to place researchers on an equal footing, establishing the necessary foundation to learn the ABCs of Behavior Cloning together as a community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ABC, a fully open-source stack for robotic manipulation via behavior cloning. Its primary contribution is the ABC-130K dataset—the largest open teleoperation dataset to date—with 3,500 hours of data across >130K episodes and 195 tasks. The authors also release their hardware setup, training infrastructure, simulation pipeline, and 400 hours of sim-teleop data. They describe a co-training recipe asserted to yield correlated simulation and real-world evaluations (serving as a proxy for model/training ablations), compare DiT and VLA architectures, and report that resulting policies execute dexterous tasks such as box folding and credit-card extraction from wallets.
Significance. If the scale, diversity, and openness of the released dataset, hardware, code, and simulation resources are as described, the work could meaningfully lower barriers to reproducible research in scalable behavior cloning for manipulation. The explicit data and tooling release is a concrete strength that directly addresses community needs for shared benchmarks and training pipelines.
major comments (2)
- [Abstract] Abstract: the claim that the co-training recipe 'produces correlated simulation and real-world evaluation, offering a reliable proxy for ablating model-design and training decisions' is unsupported by any reported quantitative evidence (correlation coefficients, scatter plots, per-task success tables, or coverage statistics across the 195 tasks). This assertion is load-bearing for the recipe's advertised utility.
- [Abstract] Abstract: the statement that 'the resulting policies successfully execute dexterous tasks such as box folding and extracting credit cards from wallets' and that findings are 'ground[ed] in real-world evaluations' supplies no success rates, trial counts, baselines, error bars, or exclusion criteria, leaving the architectural and training-recipe comparisons without visible empirical grounding.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment on the abstract below and will revise accordingly to ensure claims are properly supported.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the co-training recipe 'produces correlated simulation and real-world evaluation, offering a reliable proxy for ablating model-design and training decisions' is unsupported by any reported quantitative evidence (correlation coefficients, scatter plots, per-task success tables, or coverage statistics across the 195 tasks). This assertion is load-bearing for the recipe's advertised utility.
Authors: We agree the abstract statement lacks the requested quantitative metrics. The manuscript reports comparative simulation and real-world results but does not include explicit correlation coefficients or scatter plots. In revision we will either add these metrics drawn from the existing evaluations or revise the abstract language to avoid overclaiming correlation as a reliable proxy. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'the resulting policies successfully execute dexterous tasks such as box folding and extracting credit cards from wallets' and that findings are 'ground[ed] in real-world evaluations' supplies no success rates, trial counts, baselines, error bars, or exclusion criteria, leaving the architectural and training-recipe comparisons without visible empirical grounding.
Authors: We agree the abstract is insufficiently specific. The full manuscript contains real-world evaluation results for the cited tasks, but the abstract does not report success rates or trial details. We will revise the abstract to reference the quantitative results from the evaluations section or remove the unsupported phrasing. revision: yes
Circularity Check
No circularity; paper is a data/infrastructure release with no derivation chain
full rationale
The paper introduces an open dataset (ABC-130K), hardware setup, simulation pipeline, and a co-training recipe for behavior cloning. Its central statements concern the scale of released data and the empirical outcome of the recipe ('produces correlated simulation and real-world evaluation'). No equations, fitted parameters, or predictions are presented that reduce by construction to the paper's own inputs. No self-citations are invoked to justify uniqueness theorems or ansatzes. The contribution is the explicit release of artifacts rather than a result obtained by fitting or deriving from itself, rendering the work self-contained with independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gordon, and J
Stephane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning, 2011. URLhttps://arxiv.org/abs/1011. 0686
2011
-
[2]
Scalable diffusion models with transformers, 2023
William Peebles and Saining Xie. Scalable diffusion models with transformers, 2023. URLhttps: //arxiv.org/abs/2212.09748
Pith/arXiv arXiv 2023
-
[3]
Rt-2: Vision-language-action models transfer web knowledge to robotic control, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choro- manski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexan- der Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalash-...
Pith/arXiv arXiv 2023
-
[4]
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, Peter David Fagan, Joey Hejna, Masha Itkina, Marion Lepert, Yecheng Jason Ma, Patrick Tree Miller, Jimmy Wu, Suneel Belkhale, Shivin Dass, Huy Ha, Arhan Jain, Abraham Lee, You...
Pith/arXiv arXiv 2025
-
[5]
Open X-embodiment: Robotic learning datasets and RT-X models
Open X-Embodiment Collaboration. Open X-embodiment: Robotic learning datasets and RT-X models. In IEEE International Conference on Robotics and Automation (ICRA), 2024
2024
-
[6]
BridgeData V2: A dataset for robot learning at scale
Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen-Estruch, Quan Vuong, Andre He, Vivek Myers, Kuan Fang, Chelsea Finn, and Sergey Levine. BridgeData V2: A dataset for robot learning at scale. In Conference on Robot Learning (CoRL), 2023
2023
-
[7]
Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Xindong He, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. In 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025
2025
-
[8]
Molmoact2: Action reasoning models for real-world deployment,
Haoquan Fang, Jiafei Duan, Donovan Clay, Sam Wang, Shuo Liu, Weikai Huang, Xiang Fan, Wei- Chuan Tsai, Shirui Chen, Yi Ru Wang, Shanli Xing, Jaemin Cho, Jae Sung Park, Ainaz Eftekhar, 14 Peter Sushko, Karen Farley, Angad Wadhwa, Cole Harrison, Winson Han, Ying-Chun Lee, Eli Van- derBilt, Rose Hendrix, Suveen Ellawela, Lucas Ngoo, Joyce Chai, Zhongzheng Re...
-
[9]
URLhttps://arxiv.org/abs/2605.02881
-
[10]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[11]
A care- ful examination of large behavior models for multitask dexterous manipulation
Jose Barreiros, Andrew Beaulieu, Aditya Bhat, Rick Cory, Eric Cousineau, Hongkai Dai, Ching- Hsin Fang, Kunimatsu Hashimoto, Muhammad Zubair Irshad, Masha Itkina, et al. A care- ful examination of large behavior models for multitask dexterous manipulation. arXiv preprint arXiv:2507.05331, 2025
Pith/arXiv arXiv 2025
-
[12]
GR00T N1: An open foundation model for generalist humanoid robots
Johan Bjorck, Abhinav Prasad, Aleksei Grigoriev, Feiyu Xia, Peng Ding, Zhengyi Luo, et al. GR00T N1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[13]
URLhttps://arxiv.org/abs/ 2410.24164
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π 0: A visi...
Pith/arXiv arXiv 2026
-
[14]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
Pith/arXiv arXiv 2025
-
[15]
Rt-1: Robotics transformer for real-world control at scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[16]
Ren, Michael Equi, and Sergey Levine
Kevin Black, Allen Z. Ren, Michael Equi, and Sergey Levine. Training-time action conditioning for efficient real-time chunking, 2025. URLhttps://arxiv.org/abs/2512.05964
arXiv 2025
-
[17]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. URLhttps:// arxiv.org/abs/2103.00020
Pith/arXiv arXiv 2021
-
[18]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
Pith/arXiv arXiv 2025
-
[19]
Decoupled weight decay regularization, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. URLhttps: //arxiv.org/abs/1711.05101. 15
Pith/arXiv arXiv 2019
-
[20]
Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, et al. Gemma 3 tech- nical report. arXiv preprint arXiv:2503.19786, 4, 2025
Pith/arXiv arXiv 2025
-
[21]
Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, and Sergey Levine
Danny Driess, Jost Tobias Springenberg, Brian Ichter, Lili Yu, Adrian Li-Bell, Karl Pertsch, Allen Z. Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, and Sergey Levine. Knowl- edge insulating vision-language-action models: Train fast, run fast, generalize better, 2025. URL https://arxiv.org/abs/2505.23705
arXiv 2025
-
[22]
Fast: Efficient action tokenization for vision-language-action models, 2025
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models, 2025. URLhttps://arxiv.org/abs/2501.09747
Pith/arXiv arXiv 2025
-
[23]
Query-key normalization for transformers, 2020
Alex Henry, Prudhvi Raj Dachapally, Shubham Pawar, and Yuxuan Chen. Query-key normalization for transformers, 2020. URLhttps://arxiv.org/abs/2010.04245
arXiv 2020
-
[24]
Openvla: An open-source vision-language-action model, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Ben- jamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model, 2024. URLhttps://arxiv.org/abs/...
Pith/arXiv arXiv 2024
-
[25]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033,
2012
-
[26]
doi: 10.1109/IROS.2012.6386109
-
[27]
Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators, 2024
Philipp Wu, Yide Shentu, Zhongke Yi, Xingyu Lin, and Pieter Abbeel. Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators, 2024. URLhttps://arxiv.org/ abs/2309.13037
arXiv 2024
-
[28]
Dexhub and dart: Towards internet scale robot data collection
Younghyo Park, Jagdeep Singh Bhatia, Lars Lien Ankile, and Pulkit Agrawal. Dexhub and dart: Towards internet scale robot data collection. ArXiv, abs/2411.02214, 2024. URLhttps://api. semanticscholar.org/CorpusID:273821640
arXiv 2024
-
[29]
Lucid-xr: An extended-reality data engine for robotic manipulation, 2026
Yajvan Ravan, Adam Rashid, Alan Yu, Kai McClennen, Gio Huh, Kevin Yang, Zhutian Yang, Qinxi Yu, Xiaolong Wang, Phillip Isola, and Ge Yang. Lucid-xr: An extended-reality data engine for robotic manipulation, 2026. URLhttps://arxiv.org/abs/2605.00244
Pith/arXiv arXiv 2026
-
[30]
Iris: An immersive robot interac- tion system, 2025
Xinkai Jiang, Qihao Yuan, Enes Ulas Dincer, Hongyi Zhou, Ge Li, Xueyin Li, Julius Haag, Nicolas Schreiber, Kailai Li, Gerhard Neumann, and Rudolf Lioutikov. Iris: An immersive robot interac- tion system, 2025. URLhttps://arxiv.org/abs/2502.03297
arXiv 2025
-
[31]
RH20T: A comprehensive robotic dataset for learning diverse skills in one-shot
Hao-Shu Fang, Hongjie Fang, Zhenyu Tang, Jirong Liu, Junbo Wang, Haoyi Zhu, and Cewu Lu. RH20T: A comprehensive robotic dataset for learning diverse skills in one-shot. IEEE Robotics and Automation Letters, 2024
2024
-
[33]
Zhao, and Chelsea Finn
Zipeng Fu, Tony Z. Zhao, and Chelsea Finn. Mobile aloha: Learning bimanual mobile manip- ulation with low-cost whole-body teleoperation, 2024. URLhttps://arxiv.org/abs/2401. 02117
2024
-
[34]
Tony Z. Zhao, Jonathan Tompson, Danny Driess, Pete Florence, Kamyar Ghasemipour, Chelsea Finn, and Ayzaan Wahid. Aloha unleashed: A simple recipe for robot dexterity, 2024. URL https://arxiv.org/abs/2410.13126. 16
arXiv 2024
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[36]
Gr-2: A generative video-language-action model with web- scale knowledge for robot manipulation
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, et al. Gr-2: A generative video-language-action model with web- scale knowledge for robot manipulation. arXiv preprint arXiv:2410.06158, 2024
Pith/arXiv arXiv 2024
-
[37]
i2rt: Python API for I2RT Robots.https://github.com/i2rt-robotics/ i2rt, 2025
I2RT Robotics. i2rt: Python API for I2RT Robots.https://github.com/i2rt-robotics/ i2rt, 2025. Accessed: 2026-04-20
2025
-
[38]
ZeroMQ: An open-source universal messaging library.https://zeromq
The ZeroMQ authors. ZeroMQ: An open-source universal messaging library.https://zeromq. org, 2007. Accessed: 2026-05-31
2007
-
[39]
Robot oper- ating system 2: Design, architecture, and uses in the wild
Steven Macenski, Tully Foote, Brian Gerkey, Chris Lalancette, and William Woodall. Robot oper- ating system 2: Design, architecture, and uses in the wild. Science Robotics, 7(66):eabm6074,
-
[40]
Robot Operating System 2: Design, architecture, and uses in the wild,
doi: 10.1126/scirobotics.abm6074. URLhttps://www.science.org/doi/abs/10. 1126/scirobotics.abm6074
-
[41]
Learning fine-grained bimanual manipulation with low-cost hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware. arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
-
[42]
Factr: Force-attending curriculum training for contact-rich policy learning, 2025
Jason Jingzhou Liu, Yulong Li, Kenneth Shaw, Tony Tao, Ruslan Salakhutdinov, and Deepak Pathak. Factr: Force-attending curriculum training for contact-rich policy learning, 2025. URL https://arxiv.org/abs/2502.17432
arXiv 2025
-
[43]
Factr 2: Learning force sensing and force-aware policies for any robot arm
Steven Oh, Jason Jingzhou Liu, Tony Tao, Philip Han, Kenneth Shaw, Satoshi Funabashi, Ruslan Salakhutdinov, and Deepak Pathak. Factr 2: Learning force sensing and force-aware policies for any robot arm. 2026
2026
-
[44]
Mink: Python inverse kinematics based on MuJoCo, February 2026
Kevin Zakka. Mink: Python inverse kinematics based on MuJoCo, February 2026. URLhttps: //github.com/kevinzakka/mink
2026
-
[45]
SARM: Stage-aware reward modeling for long horizon robot manipulation
Qianzhong Chen, Justin Yu, Mac Schwager, Pieter Abbeel, Yide Shentu, and Philipp Wu. SARM: Stage-aware reward modeling for long horizon robot manipulation. InInternational Conference on Learning Representations (ICLR), 2026. 17 Appendices A ABC-130K Task Taxonomy 18 B Training & Model Details 19 B.1 Data Loading . . . . . . . . . . . . . . . . . . . . . ....
2026
-
[46]
Conditioning on Op-0, the highest-volume operator, whose training demonstrations are character- ized by short, deliberate execution (mean episode duration 59 s)
-
[47]
Conditioning on the task prompt alone, which marginalizes over operators by reverting to the training-time dropout target
-
[48]
Conditioning on Op-1, a long-duration operator with 226 episodes of training data whose demon- strations average 205 s per episode and exhibit lower fold quality Marginalized inference improves over the unconditioned baseline, indicating that operator-ID con- ditioning at training time is strictly beneficial even when the operator channel is not used at i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.