Learning Multi-Modal Whole-Body Control for Real-World Humanoid Robots
Pith reviewed 2026-05-23 22:28 UTC · model grok-4.3
The pith
A single learned controller executes diverse whole-body commands on real humanoid robots through masked target trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
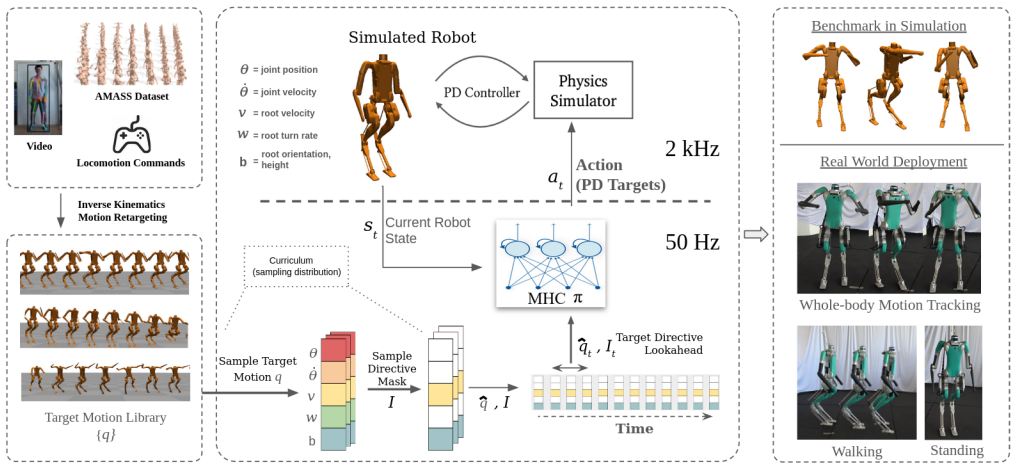
The Masked Humanoid Controller is a learned whole-body policy that receives masked target trajectories as input and outputs actions; after training in simulation across all listed input modalities it executes the same commands on the physical Digit V3 robot while preserving balance and disturbance rejection.
What carries the argument
The Masked Humanoid Controller (MHC), a policy that ingests masked target trajectories over arbitrary state subsets to generate whole-body actions.
If this is right
- High-level planners can mix command sources such as optimized trajectories, motion capture clips, video, and joystick signals through one common interface.
- The policy handles partial specifications while still keeping the robot upright and rejecting disturbances.
- A single training run in simulation suffices for both simulated and real-world deployment on Digit V3.
- No separate controllers are required for each behavior class once the masked interface is learned.
Where Pith is reading between the lines
- The masking mechanism may allow incremental addition of new command sources without retraining the entire policy.
- Success on one humanoid platform suggests the same interface could be tested on other legged robots with similar state spaces.
- If the curriculum order matters, reordering the modality exposure might improve transfer on hardware with different dynamics.
Load-bearing premise
A simulation curriculum that mixes all input modalities produces a policy whose balance and disturbance rejection properties carry over to the physical robot with no extra real-world adaptation.
What would settle it
Run the same trained policy on the physical Digit V3 using a held-out input modality such as re-targeted video and record whether the robot loses balance or fails to track the specified joints within the first ten seconds of execution.
Figures

read the original abstract
A major challenge in humanoid robotics is designing a unified interface for commanding diverse whole-body behaviors, from precise footstep sequences to partial-body mimicry and joystick teleoperation. We introduce the Masked Humanoid Controller (MHC), a learned whole-body controller that exposes a simple yet expressive interface: the specification of masked target trajectories over selected subsets of the robot's state variables. This unified abstraction allows high-level systems to issue commands in a flexible format that accommodates multi-modal inputs such as optimized trajectories, motion capture clips, re-targeted video, and real-time joystick signals. The MHC is trained in simulation using a curriculum that spans this full range of modalities, enabling robust execution of partially specified behaviors while maintaining balance and disturbance rejection. We demonstrate the MHC both in simulation and on the real-world Digit V3 humanoid, showing that a single learned controller is capable of executing such diverse whole-body commands in the real world through a common representational interface.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Masked Humanoid Controller (MHC), a learned whole-body policy for humanoid robots that accepts partially specified (masked) target trajectories as a unified interface for multi-modal commands including trajectories, mocap, video, and joystick inputs. The policy is trained in simulation via a curriculum spanning these modalities and is claimed to execute diverse behaviors while preserving balance and disturbance rejection, with demonstrations both in simulation and on the physical Digit V3 humanoid.
Significance. If the sim-to-real transfer claim holds with the stated robustness, the MHC offers a practical unified abstraction that could simplify integration of high-level planners with low-level whole-body control on humanoids. The multi-modal curriculum approach, if accompanied by reproducible training details and quantitative transfer evidence, would be a useful contribution to scalable humanoid control.
major comments (2)
- [Abstract; methods (curriculum and sim-to-real)] Abstract and methods (training/simulation curriculum description): The central claim of direct transfer of balance and disturbance rejection to the physical Digit V3 relies on a simulation curriculum whose domain randomization, actuator delay modeling, friction variation, and sensor noise injection are not specified. For an unstable high-DoF platform, these parameters are load-bearing; their absence prevents evaluation of whether the reported real-world success is reproducible or due to unstated adaptation steps.
- [Results (real-world section)] Results (real-world experiments): No quantitative metrics (e.g., success rates, balance recovery times, or disturbance rejection statistics) are provided for the diverse command modalities on hardware, nor are failure modes or comparison baselines reported. This weakens the assertion that a single policy handles the full range of partially specified behaviors in the real world.
minor comments (2)
- [Introduction / Methods] Notation for the masking interface and state variables could be formalized earlier (e.g., with an explicit definition of the mask vector and its effect on the observation space) to improve clarity for readers implementing the controller.
- [Abstract] The abstract states the controller 'maintains balance and disturbance rejection' but does not define the disturbance types or magnitudes used in either simulation or hardware tests.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below and indicate where revisions will be made to improve clarity and reproducibility.
read point-by-point responses
-
Referee: Abstract and methods (training/simulation curriculum description): The central claim of direct transfer of balance and disturbance rejection to the physical Digit V3 relies on a simulation curriculum whose domain randomization, actuator delay modeling, friction variation, and sensor noise injection are not specified. For an unstable high-DoF platform, these parameters are load-bearing; their absence prevents evaluation of whether the reported real-world success is reproducible or due to unstated adaptation steps.
Authors: We agree that explicit specification of these simulation parameters is essential for assessing reproducibility of the sim-to-real transfer. The manuscript describes the curriculum at a high level but does not enumerate the exact randomization ranges or modeling choices. In the revised version we will add a dedicated subsection (or table) in the methods detailing the domain randomization parameters (mass, inertia, friction coefficients), actuator delay distributions, friction variation, and sensor noise models used during training. This addition will directly address the concern without changing the reported results. revision: yes
-
Referee: Results (real-world experiments): No quantitative metrics (e.g., success rates, balance recovery times, or disturbance rejection statistics) are provided for the diverse command modalities on hardware, nor are failure modes or comparison baselines reported. This weakens the assertion that a single policy handles the full range of partially specified behaviors in the real world.
Authors: We acknowledge that the real-world section relies on qualitative demonstrations rather than aggregated quantitative statistics. Systematic collection of success rates or recovery-time distributions across many trials was not performed due to hardware time constraints and the exploratory nature of testing multiple input modalities on a single physical platform. In revision we will expand the real-world results with (i) a description of observed failure modes encountered during testing, (ii) available per-trial tracking-error numbers where they were logged, and (iii) a brief note on why large-scale quantitative baselines were not feasible. We will also add a simulation-based comparison to a non-masked baseline to provide supporting quantitative context. revision: partial
Circularity Check
No circularity in derivation; empirical training and sim-to-real demo
full rationale
The paper describes training a Masked Humanoid Controller via simulation curriculum spanning input modalities, followed by real-world demonstration on Digit V3. No equations, parameter-fitting steps presented as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the abstract or described content. The central claim is an empirical result (policy transfer) rather than a mathematical derivation that reduces to its inputs by construction. This matches the default case of a non-circular learning paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 4 Pith papers
-
TeleGate: Whole-Body Humanoid Teleoperation via Gated Expert Selection with Motion Prior
TeleGate achieves high-precision real-time whole-body teleoperation of humanoid robots by dynamically gating between expert policies and using a VAE motion prior to infer future intent from history, outperforming dist...
-
Toward Seamless Physical Human-Humanoid Interaction: Insights from Control, Intent, and Modeling with a Vision for What Comes Next
A literature review of pHHI that proposes a taxonomy of interaction types by modality and engagement level while outlining pathways to integrate control, intent, and modeling for more seamless humanoid-human collaboration.
-
One-shot Adaptation of Humanoid Whole-body Motion with Walking Priors
A one-shot adaptation technique for humanoid whole-body motion that computes order-preserving optimal transport distances between walking and target sequences, interpolates geodesic intermediate poses, optimizes for c...
-
No More Marching: Learning Humanoid Locomotion for Short-Range SE(2) Targets
Reinforcement learning with a constellation-based reward enables direct, efficient humanoid locomotion to short-range SE(2) targets, outperforming velocity-tracking baselines in simulation and transferring to hardware.
Reference graph
Works this paper leans on
-
[1]
Optimizing bipedal locomotion for the 100m dash with comparison to human running,
D. Crowley, J. Dao, H. Duan, K. Green, J. Hurst, and A. Fern, “Optimizing bipedal locomotion for the 100m dash with comparison to human running,” in 2023 IEEE International Conference on Robotics and Automation (ICRA) , 2023, pp. 12 205–12 211
work page 2023
-
[2]
Robust feed- back motion policy design using reinforcement learning on a 3d digit bipedal robot,
G. A. Castillo, B. Weng, W. Zhang, and A. Hereid, “Robust feed- back motion policy design using reinforcement learning on a 3d digit bipedal robot,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . IEEE, 2021, pp. 5136–5143
work page 2021
-
[3]
Sim-to-real learning for humanoid box loco-manipulation,
J. Dao, H. Duan, and A. Fern, “Sim-to-real learning for humanoid box loco-manipulation,” arXiv preprint arXiv:2310.03191 , 2023
-
[4]
Learning human-to-humanoid real-time whole-body teleoperation,
T. He, Z. Luo, W. Xiao, C. Zhang, K. Kitani, C. Liu, and G. Shi, “Learning human-to-humanoid real-time whole-body teleoperation,” arXiv preprint arXiv:2403.04436 , 2024
-
[5]
Physics-based character controllers using conditional vaes,
J. Won, D. E. Gopinath, and J. K. Hodgins, “Physics-based character controllers using conditional vaes,” ACM Transactions on Graphics (TOG) , vol. 41, pp. 1 – 12, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:250956798
work page 2022
-
[6]
A scalable approach to control diverse behaviors for physically simulated characters,
——, “A scalable approach to control diverse behaviors for physically simulated characters,” ACM Transactions on Graphics (TOG), vol. 39, pp. 33:1 – 33:12, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:219569865
work page 2020
-
[7]
Perpetual humanoid control for real-time simulated avatars
Z. Luo, J. Cao, A. Winkler, K. Kitani, and W. Xu, “Perpetual humanoid control for real-time simulated avatars.” [Online]. Available: http://arxiv.org/abs/2305.06456
-
[8]
Neural probabilistic motor primitives for humanoid control
J. Merel, L. Hasenclever, A. Galashov, A. Ahuja, V . Pham, G. Wayne, Y . W. Teh, and N. M. O. Heess, “Neural probabilistic motor primitives for humanoid control,” ArXiv, vol. abs/1811.11711, 2018. [Online]. Available: https://api.semanticscholar.org/CorpusID:53831933
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
C·ase: Learning conditional adversarial skill embeddings for physics-based characters,
Z. Dou, X. Chen, Q. Fan, T. Komura, and W. Wang, “C·ase: Learning conditional adversarial skill embeddings for physics-based characters,” ArXiv, vol. abs/2309.11351, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:262064161
-
[10]
MoCapAct: A multi-task dataset for simulated humanoid control
N. Wagener, A. Kolobov, F. V . Frujeri, R. Loynd, C.-A. Cheng, and M. Hausknecht, “MoCapAct: A multi-task dataset for simulated humanoid control.” [Online]. Available: http://arxiv.org/abs/2208. 07363
-
[11]
Ase: Large- scale reusable adversarial skill embeddings for physically simulated characters,
X. B. Peng, Y . Guo, L. Halper, S. Levine, and S. Fidler, “Ase: Large- scale reusable adversarial skill embeddings for physically simulated characters,” ACM Transactions On Graphics (TOG) , vol. 41, no. 4, pp. 1–17, 2022
work page 2022
-
[12]
Calm: Conditional adversarial latent models for directable virtual characters,
C. Tessler, Y . Kasten, Y . Guo, S. Mannor, G. Chechik, and X. B. Peng, “Calm: Conditional adversarial latent models for directable virtual characters,” in ACM SIGGRAPH 2023 Conference Proceedings , 2023, pp. 1–9
work page 2023
-
[13]
A novel multi- modal teleoperation of a humanoid assistive robot with real-time motion mimic,
J. C. Cer ´on, M. S. H. Sunny, B. Brahmi, L. M. Mendez, R. Fareh, H. U. Ahmed, and M. H. Rahman, “A novel multi- modal teleoperation of a humanoid assistive robot with real-time motion mimic,” Micromachines, vol. 14, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:256964199
work page 2023
-
[14]
Avatars grow legs: Generating smooth human motion from sparse tracking inputs with diffusion model,
Y . Du, R. Kips, A. Pumarola, S. Starke, A. K. Thabet, and A. Sanakoyeu, “Avatars grow legs: Generating smooth human motion from sparse tracking inputs with diffusion model,” 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pp. 481–490, 2023. [Online]. Available: https://api.semanticscholar. org/CorpusID:258187221
work page 2023
-
[15]
Learning quadrupedal locomotion over challenging terrain,
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning quadrupedal locomotion over challenging terrain,” Science robotics, vol. 5, no. 47, p. eabc5986, 2020
work page 2020
-
[16]
Learning a contact-adaptive controller for robust, efficient legged locomotion,
X. Da, Z. Xie, D. Hoeller, B. Boots, A. Anandkumar, Y . Zhu, B. Babich, and A. Garg, “Learning a contact-adaptive controller for robust, efficient legged locomotion,” inConference on Robot Learning. PMLR, 2021, pp. 883–894
work page 2021
-
[17]
Dynamic locomotion on slippery ground,
F. Jenelten, J. Hwangbo, F. Tresoldi, C. D. Bellicoso, and M. Hut- ter, “Dynamic locomotion on slippery ground,” IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 4170–4176, 2019
work page 2019
-
[18]
Deep whole-body control: Learning a unified policy for manipulation and locomotion,
Z. Fu, X. Cheng, and D. Pathak, “Deep whole-body control: Learning a unified policy for manipulation and locomotion,” in Conference on Robot Learning . PMLR, 2023, pp. 138–149
work page 2023
-
[19]
Lee, Matthew Tan, Yuke Zhu, and Jeannette Bohg
J. Siekmann, Y . Godse, A. Fern, and J. Hurst, “Sim-to-real learning of all common bipedal gaits via periodic reward composition,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE Press, 2021, p. 7309–7315. [Online]. Available: https://doi.org/10.1109/ICRA48506.2021.9561814
-
[20]
Reinforcement learning for robust parameterized locomotion control of bipedal robots,
Z. Li, X. Cheng, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, and K. Sreenath, “Reinforcement learning for robust parameterized locomotion control of bipedal robots,” in 2021 IEEE International Conference on Robotics and Automation (ICRA) . IEEE, 2021, pp. 2811–2817
work page 2021
-
[21]
Sim-to-real learning for bipedal locomotion under unsensed dynamic loads,
J. Dao, K. Green, H. Duan, A. Fern, and J. Hurst, “Sim-to-real learning for bipedal locomotion under unsensed dynamic loads,” in 2022 International Conference on Robotics and Automation (ICRA) . IEEE, 2022, pp. 10 449–10 455
work page 2022
-
[22]
Learning vision-based bipedal locomotion for challenging terrain,
H. Duan, B. Pandit, M. S. Gadde, B. van Marum, J. Dao, C. Kim, and A. Fern, “Learning vision-based bipedal locomotion for challenging terrain,” arXiv preprint arXiv:2309.14594 , 2023
-
[23]
Learning humanoid locomotion with transformers,
I. Radosavovic, T. Xiao, B. Zhang, T. Darrell, J. Malik, and K. Sreenath, “Learning humanoid locomotion with transformers,” arXiv preprint arXiv:2303.03381 , 2023
-
[24]
Revisiting reward design and evaluation for robust humanoid standing and walking,
B. van Marum, A. Shrestha, H. Duan, P. Dugar, J. Dao, and A. Fern, “Revisiting reward design and evaluation for robust humanoid standing and walking,” arXiv preprint arXiv:2404.19173 , 2024
-
[25]
Whole body humanoid control from human motion descriptors,
B. Dariush, M. Gienger, B. Jian, C. Goerick, and K. Fujimura, “Whole body humanoid control from human motion descriptors,” in2008 IEEE International Conference on Robotics and Automation . IEEE, 2008, pp. 2677–2684
work page 2008
-
[26]
Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control,
Z. Li, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, and K. Sreenath, “Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control,” arXiv preprint arXiv:2401.16889 , 2024
-
[27]
Amass: Archive of motion capture as surface shapes,
N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black, “Amass: Archive of motion capture as surface shapes,” 2019 IEEE/CVF International Conference on Computer Vision (ICCV) , pp. 5441–5450, 2019
work page 2019
- [28]
-
[29]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” ArXiv, vol. abs/1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
3d animation and 2d cartoons made simple
Reallusion, “3d animation and 2d cartoons made simple.” [Online]. Available: http://www.reallusion.com
-
[31]
Drake: Model-based design and verification for robotics,
R. Tedrake and the Drake Development Team, “Drake: Model-based design and verification for robotics,” 2019. [Online]. Available: https://drake.mit.edu
work page 2019
-
[32]
Snopt: An sqp algorithm for large-scale constrained optimization,
P. E. Gill, W. Murray, and M. A. Saunders, “Snopt: An sqp algorithm for large-scale constrained optimization,” SIAM review, vol. 47, no. 1, pp. 99–131, 2005
work page 2005
-
[33]
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Comput., vol. 9, no. 8, p. 1735–1780, nov 1997. [Online]. Available: https://doi.org/10.1162/neco.1997.9.8.1735
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.