Chain-of-Zoom: Extreme Super-Resolution via Scale Autoregression and Preference Alignment
Pith reviewed 2026-05-19 13:27 UTC · model grok-4.3
The pith
A standard 4x diffusion super-resolution model chained through intermediate scales reaches beyond 256x enlargement while preserving perceptual quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
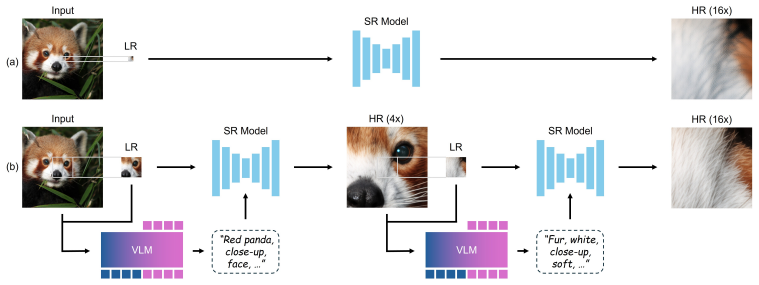
Factorizing extreme super-resolution into an autoregressive chain of intermediate scale states, each augmented by multi-scale-aware text prompts generated by a vision-language model and aligned via Generalized Reward Policy Optimization, lets a standard 4x diffusion model produce images beyond 256x with high perceptual quality and fidelity.
What carries the argument
Chain-of-Zoom (CoZ), an autoregressive factorization that decomposes the conditional probability of large-scale enlargement into repeated applications of a fixed backbone SR model plus VLM-generated prompts at each step.
If this is right
- A pretrained 4x diffusion model can be reused directly for 256x or greater enlargement without any new training.
- Perceptual quality and fidelity hold at extreme magnifications when guidance is supplied at every intermediate scale.
- Multi-scale-aware text prompts compensate for the loss of visual detail that occurs at high zoom factors.
- Preference alignment of the prompt generator improves output alignment with human judgments across the chain.
Where Pith is reading between the lines
- The same stepwise decomposition could be tested on other generative tasks where direct large jumps currently fail, such as video frame synthesis.
- Reducing the number of zoom steps while keeping prompt quality high would be a direct next measurement to assess efficiency.
- The approach implies that preference-tuned language guidance can substitute for missing visual information in any iterative image process.
Load-bearing premise
Errors do not accumulate across the sequence of intermediate scales and the vision-language prompts remain accurate rather than hallucinated once most original visual cues have disappeared.
What would settle it
A side-by-side comparison at 256x showing whether output images contain accumulating artifacts or lose fidelity relative to the sequence of lower-scale intermediates.
Figures















read the original abstract
Modern single-image super-resolution (SISR) models deliver photo-realistic results at the scale factors on which they are trained, but collapse when asked to magnify far beyond that regime. We address this scalability bottleneck with Chain-of-Zoom (CoZ), a model-agnostic framework that factorizes SISR into an autoregressive chain of intermediate scale-states with multi-scale-aware prompts. CoZ repeatedly re-uses a backbone SR model, decomposing the conditional probability into tractable sub-problems to achieve extreme resolutions without additional training. Because visual cues diminish at high magnifications, we augment each zoom step with multi-scale-aware text prompts generated by a vision-language model (VLM). The prompt extractor itself is fine-tuned using Generalized Reward Policy Optimization (GRPO) with a critic VLM, aligning text guidance towards human preference. Experiments show that a standard 4x diffusion SR model wrapped in CoZ attains beyond 256x enlargement with high perceptual quality and fidelity. Project Page: https://bryanswkim.github.io/chain-of-zoom/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Chain-of-Zoom (CoZ), a model-agnostic framework that factorizes extreme single-image super-resolution into an autoregressive chain of intermediate 4x scale steps using a fixed backbone diffusion SR model augmented by multi-scale-aware VLM prompts. The prompt extractor is fine-tuned via Generalized Reward Policy Optimization (GRPO) with a critic VLM to align outputs with human preferences. The central claim is that this enables a standard 4x model to achieve beyond 256x enlargement with high perceptual quality and fidelity without retraining on extreme scales.
Significance. If the experimental claims are substantiated with rigorous metrics, the work would be significant for computer vision as it offers a practical, training-free route to extreme magnifications by leveraging existing backbones and prompt-based guidance. The GRPO alignment step and the autoregressive decomposition are constructive ideas that could generalize beyond SR. The approach directly targets the scalability limitation of current SISR models.
major comments (2)
- Abstract: The central claim of attaining beyond 256x enlargement with high perceptual quality and fidelity is supported only by qualitative descriptions; no quantitative metrics (e.g., PSNR, LPIPS, or perceptual scores at 256x), error analysis, or ablations on chain length versus prompt quality are provided, leaving the load-bearing experimental validation unverified.
- Method description (autoregressive chaining): The framework assumes that stochastic hallucinations and artifacts from early 4x steps do not compound across the approximately four iterations needed for 256x, yet no analysis, bounds, or ablation on error propagation is given. GRPO alignment is applied only to the prompt extractor, not the SR chain itself, so later prompts may become uninformative when visual cues degrade.
minor comments (2)
- The abstract and introduction could more clearly distinguish the contributions of the chaining procedure from those of the GRPO-tuned prompt extractor.
- Notation for scale states and prompt conditioning could be formalized with a diagram or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of the significance of our work. We address each of the major comments in detail below.
read point-by-point responses
-
Referee: Abstract: The central claim of attaining beyond 256x enlargement with high perceptual quality and fidelity is supported only by qualitative descriptions; no quantitative metrics (e.g., PSNR, LPIPS, or perceptual scores at 256x), error analysis, or ablations on chain length versus prompt quality are provided, leaving the load-bearing experimental validation unverified.
Authors: We acknowledge that the abstract and some sections rely primarily on qualitative results for the extreme 256x magnification to demonstrate the framework's capability. The manuscript does include quantitative metrics like PSNR and LPIPS for scales up to 16x-32x where ground truth is available, along with perceptual user studies. For 256x on real images, reference-based metrics are inherently limited without high-resolution ground truth. In the revised version, we will add more detailed ablations on chain length and prompt quality, and include additional perceptual scores where feasible. We will also clarify the experimental setup in the abstract. revision: yes
-
Referee: Method description (autoregressive chaining): The framework assumes that stochastic hallucinations and artifacts from early 4x steps do not compound across the approximately four iterations needed for 256x, yet no analysis, bounds, or ablation on error propagation is given. GRPO alignment is applied only to the prompt extractor, not the SR chain itself, so later prompts may become uninformative when visual cues degrade.
Authors: This is a valid concern regarding potential error accumulation in the autoregressive chain. Our design mitigates this through the use of multi-scale-aware VLM prompts that adapt to the current resolution state, providing contextual guidance even when low-level details are sparse. The GRPO optimization ensures that the prompt extractor generates preference-aligned prompts that help steer the SR model towards high-quality outputs at each step. While we do not provide theoretical bounds in the current manuscript, we will include an empirical ablation study on error propagation by varying the number of zoom steps and analyzing intermediate outputs in the revision. We will also discuss how the prompt extractor maintains informativeness. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces Chain-of-Zoom as a procedural wrapper around an existing 4x diffusion SR backbone, factorizing extreme upscaling into an autoregressive sequence of intermediate steps augmented by VLM-generated prompts that are separately fine-tuned via GRPO. No load-bearing equation or claim reduces by construction to a fitted parameter, self-citation, or renamed input; the autoregressive decomposition is presented as an engineering factorization whose validity is tested empirically rather than asserted tautologically. The framework remains self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work to force its central result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Autoregressive decomposition of the conditional probability over scale states remains tractable and stable
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CoZ repeatedly re-uses a backbone SR model, decomposing the conditional probability into tractable sub-problems... multi-scale-aware text prompts generated by a vision-language model (VLM).
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
scale-level autoregressive (AR) framework... AR-2 modeling of the image generative process with multi-scale-aware prompts
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Tiled Prompts: Overcoming Prompt Misguidance in Image and Video Super-Resolution
Tiled Prompts generates tile-specific text prompts for each latent tile in diffusion super-resolution to reduce errors from global prompts and improve perceptual quality.
-
GaussianZoom: Progressive Zoom-in Generative 3D Gaussian Splatting with Geometric and Semantic Guidance
GaussianZoom enables high-fidelity extreme zoom-in 3D rendering from low-res inputs via an iterative framework combining geometry-consistent modeling, depth-based super-resolution, VLM detail synthesis, and an expanda...
Reference graph
Works this paper leans on
-
[1]
Ntire 2017 challenge on single image super-resolution: Dataset and study
Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 126–135, 2017
work page 2017
-
[2]
Eric Betzig, George H Patterson, Rachid Sougrat, O Wolf Lindwasser, Scott Olenych, Juan S Bonifacino, Michael W Davidson, Jennifer Lippincott-Schwartz, and Harald F Hess. Imaging intracellular fluorescent proteins at nanometer resolution.science, 313(5793):1642–1645, 2006
work page 2006
-
[3]
Any-resolution training for high-resolution image synthesis
Lucy Chai, Michael Gharbi, Eli Shechtman, Phillip Isola, and Richard Zhang. Any-resolution training for high-resolution image synthesis. InEuropean conference on computer vision, pages 170–188. Springer, 2022
work page 2022
-
[4]
Learning continuous image representation with local implicit image function
Yinbo Chen, Sifei Liu, and Xiaolong Wang. Learning continuous image representation with local implicit image function. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8628–8638, 2021
work page 2021
-
[5]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024
work page 2024
-
[6]
Improving diffusion models for inverse problems using manifold constraints
Hyungjin Chung, Byeongsu Sim, Dohoon Ryu, and Jong Chul Ye. Improving diffusion models for inverse problems using manifold constraints. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022. URL https: //openreview.net/forum?id=nJJjv0JDJju
work page 2022
-
[7]
Diffusion posterior sampling for general noisy inverse problems
Hyungjin Chung, Jeongsol Kim, Michael Thompson Mccann, Marc Louis Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. InInternational Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=OnD9zGAGT0k
work page 2023
-
[8]
Prompt-tuning latent diffusion models for inverse problems.arXiv preprint arXiv:2310.01110, 2023
Hyungjin Chung, Jong Chul Ye, Peyman Milanfar, and Mauricio Delbracio. Prompt-tuning latent diffusion models for inverse problems.arXiv preprint arXiv:2310.01110, 2023
-
[9]
Decomposed diffusion sampler for accelerating large-scale inverse problems
Hyungjin Chung, Suhyeon Lee, and Jong Chul Ye. Decomposed diffusion sampler for accelerating large-scale inverse problems. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=DsEhqQtfAG
work page 2024
-
[10]
Pixel recursive super resolution
Ryan Dahl, Mohammad Norouzi, and Jonathon Shlens. Pixel recursive super resolution. InProceedings of the IEEE international conference on computer vision, pages 5439–5448, 2017
work page 2017
-
[11]
Learning a deep convolutional network for image super-resolution
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Learning a deep convolutional network for image super-resolution. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part IV 13, pages 184–199. Springer, 2014
work page 2014
-
[12]
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Image super-resolution using deep convolutional networks.IEEE transactions on pattern analysis and machine intelligence, 38(2):295–307, 2015
work page 2015
-
[13]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[14]
Example-based super-resolution.IEEE Computer graphics and Applications, 22(2):56–65, 2002
William T Freeman, Thouis R Jones, and Egon C Pasztor. Example-based super-resolution.IEEE Computer graphics and Applications, 22(2):56–65, 2002. 11
work page 2002
-
[15]
Div8k: Diverse 8k resolution image dataset
Shuhang Gu, Andreas Lugmayr, Martin Danelljan, Manuel Fritsche, Julien Lamour, and Radu Timofte. Div8k: Diverse 8k resolution image dataset. In2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pages 3512–3516. IEEE, 2019
work page 2019
-
[16]
Make a cheap scaling: A self-cascade diffusion model for higher-resolution adaptation
Lanqing Guo, Yingqing He, Haoxin Chen, Menghan Xia, Xiaodong Cun, Yufei Wang, Siyu Huang, Yong Zhang, Xintao Wang, Qifeng Chen, et al. Make a cheap scaling: A self-cascade diffusion model for higher-resolution adaptation. InEuropean Conference on Computer Vision, pages 39–55. Springer, 2024
work page 2024
-
[17]
Jonathan Ho, Chitwan Saharia, William Chan, David J Fleet, Mohammad Norouzi, and Tim Salimans. Cascaded diffusion models for high fidelity image generation.Journal of Machine Learning Research, 23 (47):1–33, 2022
work page 2022
-
[18]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4401–4410, 2019
work page 2019
-
[19]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021
work page 2021
-
[20]
Robert Keys. Cubic convolution interpolation for digital image processing.IEEE transactions on acoustics, speech, and signal processing, 29(6):1153–1160, 2003
work page 2003
-
[21]
Regularization by texts for latent diffusion inverse solvers.arXiv preprint arXiv:2311.15658, 2023
Jeongsol Kim, Geon Yeong Park, Hyungjin Chung, and Jong Chul Ye. Regularization by texts for latent diffusion inverse solvers.arXiv preprint arXiv:2311.15658, 2023
-
[22]
FlowDPS: Flow-Driven Posterior Sampling for Inverse Problems, March 2025
Jeongsol Kim, Bryan Sangwoo Kim, and Jong Chul Ye. Flowdps: Flow-driven posterior sampling for inverse problems.arXiv preprint arXiv:2503.08136, 2025
-
[23]
Photo-realistic single image super- resolution using a generative adversarial network
Christian Ledig, Lucas Theis, Ferenc Husz’ar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. Photo-realistic single image super- resolution using a generative adversarial network. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4681–4690, 2017
work page 2017
-
[24]
Lsdir: A large scale dataset for image restoration
Yawei Li, Kai Zhang, Jingyun Liang, Jiezhang Cao, Ce Liu, Rui Gong, Yulun Zhang, Hao Tang, Yun Liu, Denis Demandolx, et al. Lsdir: A large scale dataset for image restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1775–1787, 2023
work page 2023
-
[25]
Enhanced deep residual networks for single image super-resolution
Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 136–144, 2017
work page 2017
-
[26]
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Yuqi Liu, Bohao Peng, Zhisheng Zhong, Zihao Yue, Fanbin Lu, Bei Yu, and Jiaya Jia. Seg-zero: Reasoning- chain guided segmentation via cognitive reinforcement.arXiv preprint arXiv:2503.06520, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Pulse: Self-supervised photo upsampling via latent space exploration of generative models
Sachit Menon, Alexandru Damian, Shijia Hu, Nikhil Ravi, and Cynthia Rudin. Pulse: Self-supervised photo upsampling via latent space exploration of generative models. InProceedings of the ieee/cvf conference on computer vision and pattern recognition, pages 2437–2445, 2020
work page 2020
-
[28]
Brian B Moser, Stanislav Frolov, Tobias C Nauen, Federico Raue, and Andreas Dengel. Zoomed in, diffused out: Towards local degradation-aware multi-diffusion for extreme image super-resolution.arXiv preprint arXiv:2411.12072, 2024
-
[29]
Multi-input cardiac image super-resolution using convolutional neural networks
Ozan Oktay, Wenjia Bai, Matthew Lee, Ricardo Guerrero, Konstantinos Kamnitsas, Jose Caballero, Antonio de Marvao, Stuart Cook, Declan O’Regan, and Daniel Rueckert. Multi-input cardiac image super-resolution using convolutional neural networks. InMedical Image Computing and Computer- Assisted Intervention-MICCAI 2016: 19th International Conference, Athens,...
work page 2016
- [30]
-
[31]
Saiprasad Ravishankar and Yoram Bresler. MR image reconstruction from highly undersampled k-space data by dictionary learning.IEEE transactions on medical imaging, 30(5):1028–1041, 2010
work page 2010
-
[32]
Chitwan Saharia, Jonathan Ho, William Chan, Tim Salimans, David J Fleet, and Mohammad Norouzi. Image super-resolution via iterative refinement.arXiv preprint arXiv:2104.07636, 2021. 12
-
[33]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [35]
-
[36]
Aligning Large Multimodal Models with Factually Augmented RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang- Yan Gui, Yu-Xiong Wang, Yiming Yang, et al. Aligning large multimodal models with factually augmented rlhf.arXiv preprint arXiv:2309.14525, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Qwen Team. Qwen2.5-vl, January 2025. URLhttps://qwenlm.github.io/blog/qwen2.5-vl/
work page 2025
-
[38]
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
work page 2024
-
[39]
Aaron Van den Oord, Nal Kalchbrenner, Lasse Espeholt, Oriol Vinyals, Alex Graves, et al. Conditional image generation with pixelcnn decoders.Advances in neural information processing systems, 29, 2016
work page 2016
-
[40]
Pixel recurrent neural networks
Aäron Van Den Oord, Nal Kalchbrenner, and Koray Kavukcuoglu. Pixel recurrent neural networks. In International conference on machine learning, pages 1747–1756. PMLR, 2016
work page 2016
-
[41]
Lena Wagner, Lukas Liebel, and Marco Körner. Deep residual learning for single-image super-resolution of multi-spectral satellite imagery.ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 4:189–196, 2019
work page 2019
-
[42]
Exploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Exploring clip for assessing the look and feel of images. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 2555–2563, 2023
work page 2023
-
[43]
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin CK Chan, and Chen Change Loy. Exploiting diffusion prior for real-world image super-resolution.International Journal of Computer Vision, 132(12): 5929–5949, 2024
work page 2024
-
[44]
Peijuan Wang, Bulent Bayram, and Elif Sertel. A comprehensive review on deep learning based remote sensing image super-resolution methods.Earth-Science Reviews, 232:104110, 2022
work page 2022
-
[45]
Xiaojuan Wang, Janne Kontkanen, Brian Curless, Steven M Seitz, Ira Kemelmacher-Shlizerman, Ben Mildenhall, Pratul Srinivasan, Dor Verbin, and Aleksander Holynski. Generative powers of ten. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7173–7182, 2024
work page 2024
-
[46]
Zhihao Wang, Jian Chen, and Steven CH Hoi. Deep learning for image super-resolution: A survey.IEEE transactions on pattern analysis and machine intelligence, 43(10):3365–3387, 2020
work page 2020
-
[47]
Krzysztof Wolski, Adarsh Djeacoumar, Alireza Javanmardi, Hans-Peter Seidel, Christian Theobalt, Guil- laume Cordonnier, Karol Myszkowski, George Drettakis, Xingang Pan, and Thomas Leimkühler. Learning images across scales using adversarial training.ACM Transactions on Graphics, 43(4):131, 2024
work page 2024
-
[48]
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. One-step effective diffusion network for real-world image super-resolution.Advances in Neural Information Processing Systems, 37:92529–92553, 2024
work page 2024
-
[49]
Seesr: Towards semantics-aware real-world image super-resolution
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, and Lei Zhang. Seesr: Towards semantics-aware real-world image super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 25456–25467, 2024
work page 2024
-
[50]
ArXiv preprint abs/2410.02712 (2024)
Tianyi Xiong, Xiyao Wang, Dong Guo, Qinghao Ye, Haoqi Fan, Quanquan Gu, Heng Huang, and Chunyuan Li. Llava-critic: Learning to evaluate multimodal models.arXiv preprint arXiv:2410.02712, 2024
-
[51]
Image super-resolution via sparse representation
Jianchao Yang, John Wright, Thomas S Huang, and Yi Ma. Image super-resolution via sparse representation. IEEE transactions on image processing, 19(11):2861–2873, 2010. 13
work page 2010
-
[52]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1191–1200, 2022
work page 2022
-
[53]
Srikar Yellapragada, Alexandros Graikos, Kostas Triaridis, Prateek Prasanna, Rajarsi R Gupta, Joel Saltz, and Dimitris Samaras. Zoomldm: Latent diffusion model for multi-scale image generation.arXiv preprint arXiv:2411.16969, 2024
-
[54]
Demystifying Long Chain-of-Thought Reasoning in LLMs
Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neubig, and Xiang Yue. Demystifying long chain-of- thought reasoning in llms, 2025. URLhttps://arxiv.org/abs/2502.03373
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Scaling up to excellence: Practicing model scaling for photo-realistic image restoration in the wild
Fanghua Yu, Jinjin Gu, Zheyuan Li, Jinfan Hu, Xiangtao Kong, Xintao Wang, Jingwen He, Yu Qiao, and Chao Dong. Scaling up to excellence: Practicing model scaling for photo-realistic image restoration in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25669–25680, 2024
work page 2024
-
[56]
Aiping Zhang, Zongsheng Yue, Renjing Pei, Wenqi Ren, and Xiaochun Cao. Degradation-guided one-step image super-resolution with diffusion priors.arXiv preprint arXiv:2409.17058, 2024
-
[57]
A feature-enriched completely blind image quality evaluator
Lin Zhang, Lei Zhang, and Alan C Bovik. A feature-enriched completely blind image quality evaluator. IEEE Transactions on Image Processing, 24(8):2579–2591, 2015
work page 2015
-
[58]
Image super-resolution using very deep residual channel attention networks
Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, and Yun Fu. Image super-resolution using very deep residual channel attention networks. InProceedings of the European conference on computer vision (ECCV), pages 286–301, 2018
work page 2018
-
[59]
Swift: a scalable lightweight infrastructure for fine-tuning
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, et al. Swift: a scalable lightweight infrastructure for fine-tuning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 29733–29735, 2025. 14 A Proofs Proposition 1.Given a sequence of scale-states xi tha...
-
[60]
A given LR image is resized to the target resolution and V AE encoding is done in tiles, allowing encoding to be performed even in settings of limited GPU memory
-
[61]
For latent sizes of 64×64, we find overlaps of 16 to work sufficiently well
The encoded (low-resolution) latent is tiled into overlapping patches. For latent sizes of 64×64, we find overlaps of 16 to work sufficiently well
-
[62]
Each low-resolution patch of 64×64 passes through the super-resolution network to become high-resolution patches, each guided by patch-specific prompts generated by the prompt- extractor VLM. Note that this step requires multiple passes of the VLM, a computational bottleneck to be solved by future work
-
[63]
The output high-resolution patches are multiplied by Gaussian weights in overlapping regions for smooth transposition between patches, and then combined to create the final high-resolution image
-
[64]
The whole process is repeated asscale autoregressionto achieve higher resolutions. 19 I Additional Qualitative Results Additional qualitative results of extreme super-resolution by CoZ are provided below. Figure 12: Extreme super-resolution of photorealistic images by CoZ up to64×magnification. 20 Figure 13: Extreme super-resolution of photorealistic imag...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.