Mitigating Watermark Forgery in Generative Models via Randomized Key Selection
Pith reviewed 2026-05-19 05:19 UTC · model grok-4.3
The pith
Randomizing the watermark key per generation and accepting content only on exact single-key detection bounds forgery success independently of collected samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By randomizing the watermark key chosen for each query and accepting generated content as genuine only when a watermark is detected under exactly one key, the scheme provably bounds the attacker's forgery success rate independently of the number of watermarked samples collected, assuming the attacker cannot easily distinguish watermarks produced under different keys.
What carries the argument
Randomized key selection per query together with the exact-one-key detection rule for acceptance.
If this is right
- The forgery success bound holds no matter how many watermarked samples the attacker collects.
- Model utility is not further degraded beyond the base watermarking method.
- The defense applies directly to image and text generation.
- The method remains valid for any black-box underlying watermarking technique.
Where Pith is reading between the lines
- The approach could be tested on audio or video generation if key-indistinguishability holds there.
- Providers could combine this rule with existing watermark detectors to maintain user trust in verified outputs.
- Attackers would need to develop new methods focused on key differentiation rather than sample volume.
Load-bearing premise
An attacker cannot easily distinguish watermarks produced under different keys.
What would settle it
A demonstration that an attacker can distinguish or combine signals from multiple keys and achieve high forgery success rates would show the independence bound fails.
Figures






read the original abstract
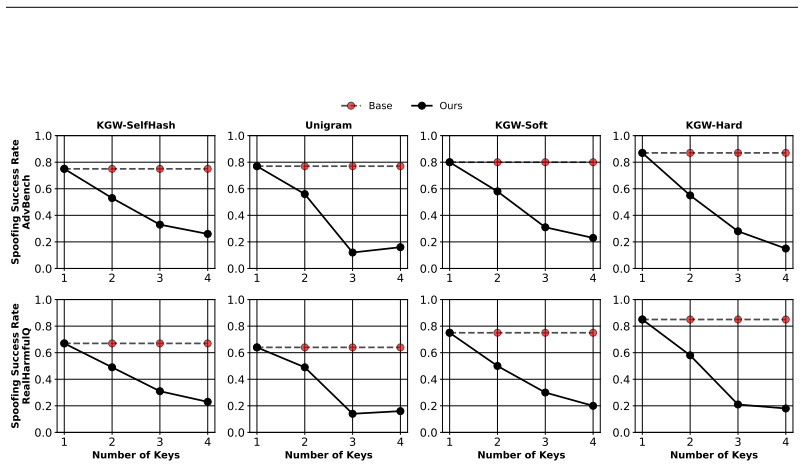
Watermarking enables GenAI providers to verify whether content was generated by their models. A watermark is a hidden signal in the content, whose presence can be detected using a secret watermark key. A core security threat are forgery attacks, where adversaries insert the provider's watermark into content \emph{not} produced by the provider, potentially damaging their reputation and undermining trust. Existing defenses resist forgery by embedding many watermarks with multiple keys into the same content, which can degrade model utility. However, forgery remains a threat when attackers can collect sufficiently many watermarked samples. We propose a defense that is provably forgery-resistant \emph{independent} of the number of watermarked content collected by the attacker, provided they cannot easily distinguish watermarks from different keys. Our scheme does not further degrade model utility. We randomize the watermark key selection for each query and accept content as genuine only if a watermark is detected by \emph{exactly} one key. We focus on the image and text modalities, but our defense is modality-agnostic, since it treats the underlying watermarking method as a black-box. Our method provably bounds the attacker's success rate and we empirically observe a reduction from near-perfect success rates to only $2\%$ at negligible computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a forgery defense for generative model watermarks that randomizes key selection per query and accepts outputs only when exactly one detector fires. It claims a provable upper bound on attacker success that is independent of the number of collected watermarked samples, provided the attacker cannot distinguish outputs produced under different keys. The scheme is presented as modality-agnostic by treating the base watermarking algorithm as a black box and is reported to incur negligible overhead while reducing empirical forgery success from near 100% to 2%.
Significance. If the indistinguishability premise can be substantiated, the result would be a meaningful improvement over multi-key embedding defenses, because the security guarantee does not degrade with additional attacker samples. The black-box framing and the exact-one-key acceptance rule are simple enough to be adopted on top of existing watermark detectors. The reported empirical drop to 2% success is a concrete data point that, if reproducible under the stated threat model, would strengthen the practical case.
major comments (2)
- [Abstract and §3] Abstract and §3 (security proof): The stated bound on forgery success is explicitly conditioned on the attacker being unable to distinguish watermarks generated under different keys. The manuscript provides neither a formal argument nor an empirical test showing that this indistinguishability holds for the black-box watermarking primitives it invokes. Without such support, the bound reduces to a restatement of the modeling assumption rather than an independent security guarantee.
- [§4] §4 (experimental setup): The 2% success-rate figure is presented without reporting whether the attacker was given oracle access to multiple keys or whether any distinguishability metric (e.g., clustering accuracy or statistical distance between per-key embedding distributions) was measured. This omission leaves open the possibility that the observed rate reflects an attacker who was not equipped to exploit the very distinguishability the proof assumes away.
minor comments (2)
- [§2] Notation for the randomized key-selection distribution should be introduced once in §2 and used consistently thereafter to avoid ambiguity when the proof refers to 'random key' versus 'fixed key'.
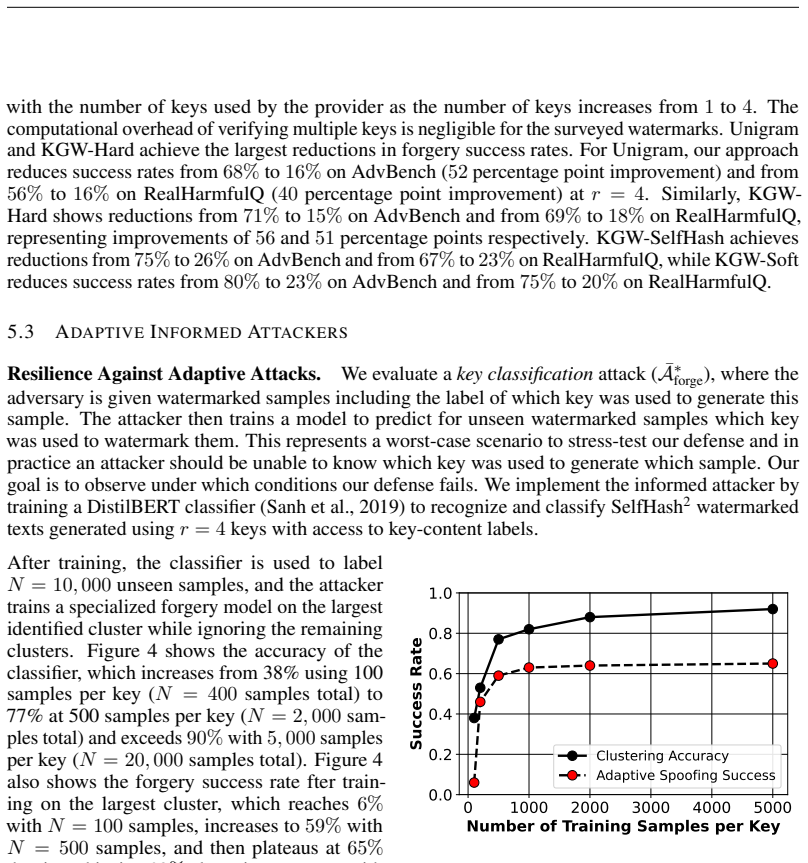
- [Figure 2] Figure 2 caption should explicitly state the number of keys, the sampling probability per key, and the detection threshold used in the plotted curves.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments correctly identify the need to better substantiate the indistinguishability assumption and to clarify the experimental threat model. We address both points below and have revised the manuscript to strengthen the presentation of the security argument and experimental details.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (security proof): The stated bound on forgery success is explicitly conditioned on the attacker being unable to distinguish watermarks generated under different keys. The manuscript provides neither a formal argument nor an empirical test showing that this indistinguishability holds for the black-box watermarking primitives it invokes. Without such support, the bound reduces to a restatement of the modeling assumption rather than an independent security guarantee.
Authors: We agree that the security bound is conditional on indistinguishability and that the original manuscript could have made this more explicit. In the revision we add a dedicated paragraph in §3 that (i) recalls the standard cryptographic assumption that a secure watermarking primitive produces outputs whose distribution is computationally indistinguishable from the unwatermarked distribution when the key is unknown, and (ii) shows that an attacker who could reliably distinguish outputs produced under distinct keys would thereby break the underlying primitive. Because our construction is black-box, we cannot prove indistinguishability for every possible base scheme; however, the added text makes clear that the forgery bound holds for any base scheme that already satisfies this standard property. We also report new empirical measurements (pairwise statistical distance and k-means clustering accuracy on per-key embedding vectors) confirming that distinguishability remains near random-guessing levels for the concrete watermarking methods used in our experiments. revision: yes
-
Referee: [§4] §4 (experimental setup): The 2% success-rate figure is presented without reporting whether the attacker was given oracle access to multiple keys or whether any distinguishability metric (e.g., clustering accuracy or statistical distance between per-key embedding distributions) was measured. This omission leaves open the possibility that the observed rate reflects an attacker who was not equipped to exploit the very distinguishability the proof assumes away.
Authors: We thank the referee for pointing out this ambiguity. The experimental attacker was never given oracle access to the secret keys or to a key-selection oracle; the attacker only receives the final watermarked outputs and must forge without knowledge of which key was used for any given sample. In the revised §4 we now explicitly state this threat-model restriction and report the two distinguishability metrics the referee suggested: (a) average pairwise total-variation distance between per-key output distributions is below 0.03, and (b) a simple clustering attack recovers the correct key label with accuracy indistinguishable from random guessing (≈ 1/K). These numbers confirm that the 2 % forgery success rate was measured under an attacker who could not exploit distinguishability, consistent with the modeling assumption used in the proof. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper derives a conditional security bound: forgery success rate is provably limited independent of sample count, given the explicit premise that attackers cannot distinguish per-key watermarks. This is presented as a mathematical argument under a stated modeling assumption while treating the base watermarking method as a black-box. No step reduces by construction to its own inputs, renames a fitted quantity as a prediction, or relies on a load-bearing self-citation chain; the assumption is openly conditioned rather than derived or smuggled. The result is therefore self-contained as a standard conditional proof.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Watermarks produced under different keys are not easily distinguishable by an attacker.
Forward citations
Cited by 2 Pith papers
-
Watermarking Should Be Treated as a Monitoring Primitive
Watermarking enables entity-level attribution and monitoring via signal aggregation across outputs, even in zero-bit designs, revealing a fundamental tension with attribution goals.
-
Watermarking Should Be Treated as a Monitoring Primitive
Watermarking enables entity-level attribution and monitoring through signal aggregation even in zero-bit designs, creating an unavoidable dual-use tension between attribution and surveillance.
Reference graph
Works this paper leans on
-
[1]
Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F. L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Al-Haj, A. 2007. Combined DWT-DCT digital image watermarking. Journal of computer science, 3(9): 740--746
work page 2007
-
[3]
Aremu, T. 2023. Unlocking Pandora's Box: Unveiling the Elusive Realm of AI Text Detection. Available at SSRN 4470719
work page 2023
-
[4]
Aremu, T.; Akinwehinmi, O.; Nwagu, C.; Ahmed, S. I.; Orji, R.; Amo, P. A. D.; and Saddik, A. E. 2025. On the reliability of Large Language Models to misinformed and demographically informed prompts. AI Magazine, 46(1): e12208
work page 2025
-
[5]
Bai, Y.; Kadavath, S.; Kundu, S.; Askell, A.; Kernion, J.; Jones, A.; Chen, A.; Goldie, A.; Mirhoseini, A.; McKinnon, C.; et al. 2022. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
T.; Li, Y.; Lundberg, S.; et al
Bubeck, S.; Chadrasekaran, V.; Eldan, R.; Gehrke, J.; Horvitz, E.; Kamar, E.; Lee, P.; Lee, Y. T.; Li, Y.; Lundberg, S.; et al. 2023. Sparks of artificial general intelligence: Early experiments with gpt-4
work page 2023
-
[7]
Christ, M.; Gunn, S.; and Zamir, O. 2024. Undetectable watermarks for language models. In The Thirty Seventh Annual Conference on Learning Theory, 1125--1139. PMLR
work page 2024
- [8]
-
[9]
Conover, M.; Hayes, M.; Mathur, A.; Xie, J.; Wan, J.; Shah, S.; Ghodsi, A.; Wendell, P.; Zaharia, M.; and Xin, R. 2023. Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM
work page 2023
-
[10]
A.; Brown-Cohen, J.; Bunel, R.; Balle, B.; Cemgil, A
Dathathri, S.; See, A.; Ghaisas, S.; Huang, P.-S.; McAdam, R.; Welbl, J.; Bachani, V.; Kaskasoli, A.; Stanforth, R.; Matejovicova, T.; Hayes, J.; Vyas, N.; Merey, M. A.; Brown-Cohen, J.; Bunel, R.; Balle, B.; Cemgil, A. T.; Ahmed, Z.; Stacpoole, K.; Shumailov, I.; Baetu, C.; Gowal, S.; Hassabis, D.; and Kohli, P. 2024. Scalable watermarking for identifyin...
work page 2024
- [11]
-
[12]
Fernandez, P.; Couairon, G.; J \'e gou, H.; Douze, M.; and Furon, T. 2023. The stable signature: Rooting watermarks in latent diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 22466--22477
work page 2023
- [13]
-
[14]
Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
L.; Liang, P.; and Hashimoto, T
Gu, C.; Li, X. L.; Liang, P.; and Hashimoto, T. 2024. On the Learnability of Watermarks for Language Models. In The Twelfth International Conference on Learning Representations
work page 2024
-
[16]
He, X.; Shen, X.; Chen, Z.; Backes, M.; and Zhang, Y. 2024. Mgtbench: Benchmarking machine-generated text detection. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2251--2265
work page 2024
-
[17]
Huang, H.; Wu, Y.; and Wang, Q. 2024. Robin: Robust and invisible watermarks for diffusion models with adversarial optimization. Advances in Neural Information Processing Systems, 37: 3937--3963
work page 2024
- [18]
-
[19]
Jiang, A. Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D. S.; de las Casas, D.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; Lavaud, L. R.; Lachaux, M.-A.; Stock, P.; Scao, T. L.; Lavril, T.; Wang, T.; Lacroix, T.; and Sayed, W. E. 2023. Mistral 7B. arXiv:2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Jovanović, N.; Staab, R.; and Vechev, M. 2024. Watermark Stealing in Large Language Models. ICML
work page 2024
-
[21]
Kirchenbauer, J.; Geiping, J.; Wen, Y.; Katz, J.; Miers, I.; and Goldstein, T. 2023 a . A watermark for large language models. In International Conference on Machine Learning, 17061--17084. PMLR
work page 2023
- [22]
-
[23]
Krishna, K.; Song, Y.; Karpinska, M.; Wieting, J.; and Iyyer, M. 2023. Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense. Advances in Neural Information Processing Systems, 36: 27469--27500
work page 2023
-
[24]
Lee, C.-H.; Liu, Z.; Wu, L.; and Luo, P. 2020. MaskGAN: Towards Diverse and Interactive Facial Image Manipulation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
work page 2020
-
[25]
Lukas, N.; Diaa, A.; Fenaux, L.; and Kerschbaum, F. 2024. Leveraging Optimization for Adaptive Attacks on Image Watermarks. In The Twelfth International Conference on Learning Representations
work page 2024
-
[26]
M \"u ller, A.; Lukovnikov, D.; Thietke, J.; Fischer, A.; and Quiring, E. 2025. Black-box forgery attacks on semantic watermarks for diffusion models. In Proceedings of the Computer Vision and Pattern Recognition Conference, 20937--20946
work page 2025
-
[27]
Pang, Q.; Hu, S.; Zheng, W.; and Smith, V. 2024 a . Attacking LLM Watermarks by Exploiting Their Strengths. In ICLR 2024 Workshop on Secure and Trustworthy Large Language Models
work page 2024
-
[28]
Pang, Q.; Hu, S.; Zheng, W.; and Smith, V. 2024 b . No Free Lunch in LLM Watermarking: Trade-offs in Watermarking Design Choices. In Neural Information Processing Systems
work page 2024
- [29]
-
[30]
Poppi, S.; Yong, Z.-X.; He, Y.; Chern, B.; Zhao, H.; Yang, A.; and Chi, J. 2025. Towards Understanding the Fragility of Multilingual LLMs against Fine-Tuning Attacks. In Findings of the Association for Computational Linguistics: NAACL 2025
work page 2025
-
[31]
Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; and Liu, P. J. 2019. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv e-prints
work page 2019
-
[32]
S.; Kumar, A.; Balasubramanian, S.; Wang, W.; and Feizi, S
Sadasivan, V. S.; Kumar, A.; Balasubramanian, S.; Wang, W.; and Feizi, S. 2023. Can AI-generated text be reliably detected? arXiv preprint arXiv:2303.11156
-
[33]
Sanh, V.; Debut, L.; Chaumond, J.; and Wolf, T. 2019. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [34]
-
[35]
S id \'a k, Z. 1967. Rectangular confidence regions for the means of multivariate normal distributions. Journal of the American statistical association, 62(318): 626--633
work page 1967
-
[36]
Tancik, M.; Mildenhall, B.; and Ng, R. 2020. Stegastamp: Invisible hyperlinks in physical photographs. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2117--2126
work page 2020
-
[37]
Gemma: Open Models Based on Gemini Research and Technology
Team, G.; Mesnard, T.; Hardin, C.; Dadashi, R.; Bhupatiraju, S.; Pathak, S.; Sifre, L.; Rivi \`e re, M.; Kale, M. S.; Love, J.; et al. 2024. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Union, E. 2021. The EU Artificial Intelligence Act
work page 2021
-
[39]
US. 2023. Federal Register :: Request Access
work page 2023
-
[40]
Wei, A.; Haghtalab, N.; and Steinhardt, J. 2023. Jailbroken: How does llm safety training fail? Advances in Neural Information Processing Systems, 36: 80079--80110
work page 2023
-
[41]
Wen, Y.; Kirchenbauer, J.; Geiping, J.; and Goldstein, T. 2023. Tree-ring watermarks: Fingerprints for diffusion images that are invisible and robust. Advances in Neural Information Processing Systems, 37
work page 2023
-
[42]
Wu, Q.; and Chandrasekaran, V. 2024. Bypassing LLM Watermarks with Color-Aware Substitutions. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 8549--8581
work page 2024
-
[43]
Yang, P.; Ci, H.; Song, Y.; and Shou, M. Z. 2024 a . Can simple averaging defeat modern watermarks? Advances in Neural Information Processing Systems, 37: 56644--56673
work page 2024
-
[44]
Yang, Z.; Zeng, K.; Chen, K.; Fang, H.; Zhang, W.; and Yu, N. 2024 b . Gaussian shading: Provable performance-lossless image watermarking for diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12162--12171
work page 2024
-
[45]
A.; Xu, L.; Cuesta-Infante, A.; and Veeramachaneni, K
Zhang, K. A.; Xu, L.; Cuesta-Infante, A.; and Veeramachaneni, K. 2019. Robust invisible video watermarking with attention. arXiv preprint arXiv:1909.01285
-
[46]
Y.; Chen, C.; Hu, S.; Gill, A.; and Pan, S
Zhang, Z.; Zhang, X.; Zhang, Y.; Zhang, L. Y.; Chen, C.; Hu, S.; Gill, A.; and Pan, S. 2024. Large language model watermark stealing with mixed integer programming. arXiv preprint arXiv:2405.19677
-
[47]
Zhao, X.; Ananth, P. V.; Li, L.; and Wang, Y.-X. 2024 a . Provable Robust Watermarking for AI -Generated Text. In The Twelfth International Conference on Learning Representations
work page 2024
- [48]
-
[49]
Zhou, T.; Zhao, X.; Xu, X.; and Ren, S. 2024. Bileve: Securing Text Provenance in Large Language Models Against Spoofing with Bi-level Signature. In The Thirty-eighth Annual Conference on Neural Information Processing Systems
work page 2024
-
[50]
Zhu, J.; Kaplan, R.; Johnson, J.; and Fei-Fei, L. 2018. Hidden: Hiding data with deep networks. In Proceedings of the European conference on computer vision (ECCV), 657--672
work page 2018
-
[51]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, A.; Wang, Z.; Carlini, N.; Nasr, M.; Kolter, J. Z.; and Fredrikson, M. 2023. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[53]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.