Recognition: no theorem link
Watermarking Should Be Treated as a Monitoring Primitive
Pith reviewed 2026-05-15 05:53 UTC · model grok-4.3
The pith
Even zero-bit watermarking enables entity attribution when observers aggregate signals across multiple outputs under multi-key conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that watermarking should be treated as a monitoring primitive because internal monitoring is unavoidable when per-entity attribution keys and messages are paired with detector access. Even zero-bit watermarking supports attribution in multi-key settings through observer aggregation of signals across outputs from the same entity. External monitoring can additionally emerge from persistent, key-dependent statistical structure, depending on the watermark design, and may be mitigated by distribution-preserving or undetectable schemes.
What carries the argument
Observer aggregation of watermark signals across multiple outputs from the same entity in a multi-key setting.
If this is right
- Zero-bit watermarking still permits entity-level attribution when observers collect multiple samples over time.
- Persistent statistical structure tied to keys can enable external monitoring without direct detector access.
- Distribution-preserving watermark designs reduce the risk of such external monitoring emerging.
- Evaluation of watermarking must extend beyond single-sample robustness to include aggregation and observer capabilities.
Where Pith is reading between the lines
- Watermark designers may need to balance attribution strength against the ease of long-term signal aggregation.
- Deployments of watermarked models in open environments could face unexpected monitoring uses not intended by the creators.
- Testing specific watermark schemes for resistance to aggregation under realistic output volumes would clarify practical limits.
- Similar aggregation risks might appear in other provenance methods that embed persistent per-entity markers.
Load-bearing premise
Observers have sustained access to the detector and can collect sufficiently many outputs from the same entity to make statistical aggregation reliable.
What would settle it
An experiment showing that aggregated watermark signals from any number of outputs fail to distinguish entities reliably in a multi-key setup would disprove the core claim.
Figures

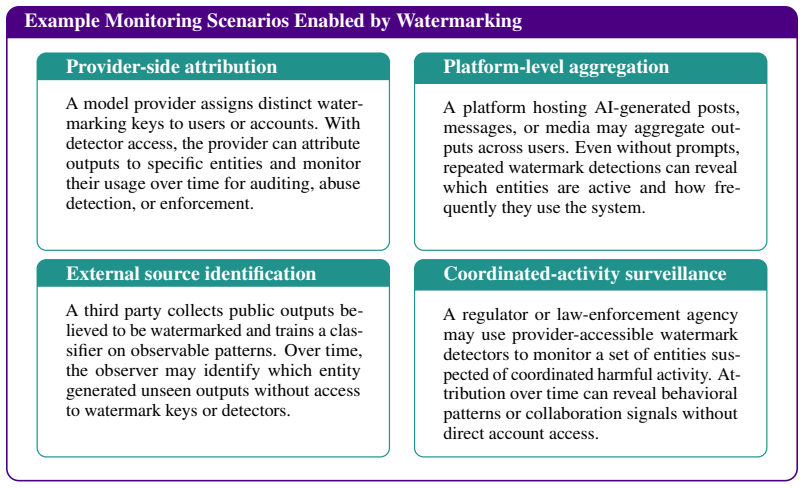

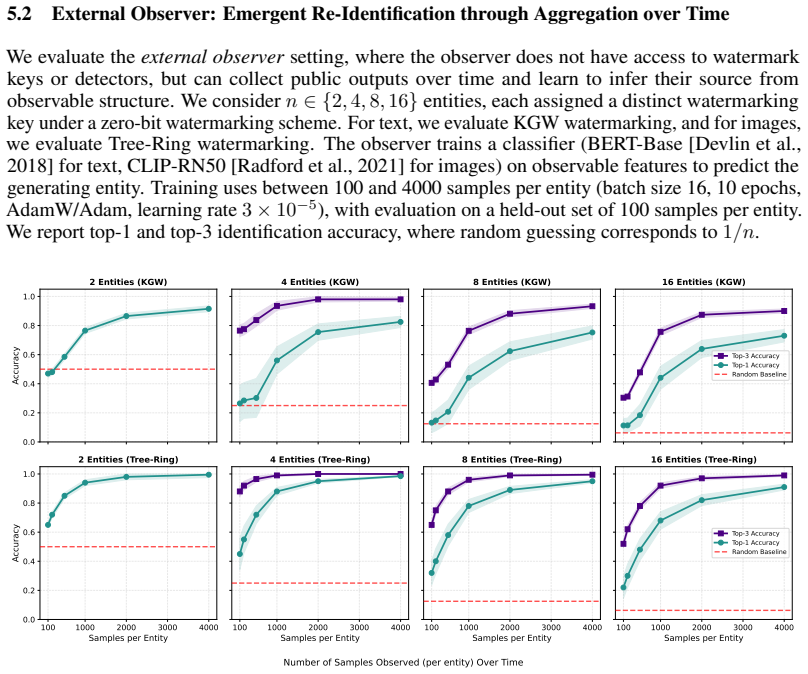

read the original abstract
Watermarking is widely proposed for provenance, attribution, and safety monitoring in generative models, yet is typically evaluated only under adversaries who attempt to evade detection or induce false positives at the level of individual samples. We argue that watermarking should be treated as a monitoring primitive, and that internal monitoring is unavoidable given per-entity attribution keys and messages, as well as detector access. We introduce an observer-based threat model in which observers can aggregate watermark signals across outputs to infer entity-level information, showing that even zero-bit watermarking enables attribution under multi-key settings. We further show that external monitoring can emerge over time from persistent, key-dependent statistical structure, although this depends on watermark design and may be mitigated by distribution-preserving or undetectable schemes. Our findings reveal a fundamental dual-use tension between attribution and monitoring, motivating evaluation of watermarking beyond per-sample robustness to account for aggregation and observer-based capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that watermarking in generative models should be treated as a monitoring primitive, not merely a per-sample detection tool. With per-entity attribution keys and detector access, an observer-based threat model allows aggregation of watermark signals across outputs to infer entity-level information, enabling attribution even with zero-bit watermarks in multi-key settings. It further argues that external monitoring can emerge from persistent key-dependent statistical structure, creating a dual-use tension that requires evaluations beyond per-sample robustness to account for aggregation and observer capabilities.
Significance. If the argument holds, the result would shift how watermarking schemes are evaluated and deployed for provenance and safety, emphasizing that internal monitoring is unavoidable and that designs must address long-term aggregation risks. This could inform standards for distribution-preserving or undetectable watermarks and highlight trade-offs in AI monitoring primitives.
major comments (1)
- [observer-based threat model (as described in abstract)] The central claim that zero-bit watermarking enables attribution under multi-key settings via observer aggregation (abstract) rests on the assumption that observers can obtain and correctly group a sufficient number of outputs from the same entity for statistical inference. The manuscript provides only high-level reasoning without deriving or bounding the required sample counts or modeling entity partitioning without prior attribution information, leaving the attribution result dependent on unverified conditions.
minor comments (1)
- The abstract would benefit from explicitly naming the watermark designs considered for mitigating external monitoring to clarify the scope of the mitigation claim.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We appreciate the constructive feedback on the observer-based threat model and the assumptions underlying the attribution claims. We address the major comment below and commit to revisions that strengthen the rigor of the analysis without altering the core argument.
read point-by-point responses
-
Referee: [observer-based threat model (as described in abstract)] The central claim that zero-bit watermarking enables attribution under multi-key settings via observer aggregation (abstract) rests on the assumption that observers can obtain and correctly group a sufficient number of outputs from the same entity for statistical inference. The manuscript provides only high-level reasoning without deriving or bounding the required sample counts or modeling entity partitioning without prior attribution information, leaving the attribution result dependent on unverified conditions.
Authors: We agree that the manuscript currently relies on high-level reasoning to demonstrate the feasibility of entity-level attribution via signal aggregation in multi-key, zero-bit settings under the observer-based threat model. The primary goal is to establish the dual-use tension and motivate broader evaluation criteria rather than to deliver a fully quantified analysis of sample complexity. To address this directly, we will revise the paper by adding a dedicated subsection that derives preliminary bounds on the number of samples required for reliable inference (using standard concentration inequalities for aggregated watermark signals) and discusses practical approaches to entity partitioning, such as clustering on statistical patterns or scenarios with partial prior information. These additions will make the conditions for attribution more explicit and reduce dependence on unverified assumptions. revision: yes
Circularity Check
No significant circularity; argument is definitional and threat-model based
full rationale
The manuscript advances a conceptual reframing of watermarking as a monitoring primitive under an observer-based threat model, asserting that aggregation enables attribution even for zero-bit schemes. This claim is introduced directly as part of the model definition rather than derived from equations, fitted parameters, or self-citations. No load-bearing step reduces by construction to its inputs, and the paper contains no mathematical derivations or uniqueness theorems that could create self-referential loops. The reasoning remains self-contained as a high-level threat-model analysis, consistent with the absence of any quoted reduction to prior fitted results or author-specific ansatzes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Observers have access to the watermark detector and can collect multiple outputs from the same entity.
- domain assumption Watermark signals remain detectable and aggregatable across independent outputs.
invented entities (1)
-
Observer-based threat model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Simons Institute, YouTube video. J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
-
[3]
Mitigating Watermark Forgery in Generative Models via Randomized Key Selection
T. Aremu, N. Hussein, M. Nwadike, S. Poppi, J. Zhang, K. Nandakumar, N. Gong, and N. Lukas. Mitigating watermark forgery in generative models via randomized key selection.arXiv preprint arXiv:2507.07871,
work page internal anchor Pith review Pith/arXiv arXiv
- [4]
-
[5]
URL https://www.reuters.com/technology/ openai-google-others-pledge-watermark-ai-content-safety-white-house-2023-07-21/. S. Bubeck, V . Chadrasekaran, R. Eldan, J. Gehrke, E. Horvitz, E. Kamar, P. Lee, Y . T. Lee, Y . Li, S. Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4,
work page 2023
-
[6]
Chapter 291, Statutes of 2024; operative Jan 1,
URL https://leginfo.legislature.ca.gov/faces/billTextClient.xhtml?bill_ id=202320240SB942. Chapter 291, Statutes of 2024; operative Jan 1,
work page 2024
-
[7]
M. Christ, S. Gunn, T. Malkin, and M. Raykova. Provably robust watermarks for open-source language models. arXiv preprint arXiv:2410.18861, 2024a. M. Christ, S. Gunn, and O. Zamir. Undetectable watermarks for language models. InThe Thirty Seventh Annual Conference on Learning Theory, pages 1125–1139. PMLR, 2024b. S. Dathathri, A. See, S. Ghaisas, P.-S. Hu...
-
[8]
URL https: //doi.org/10.1038/s41586-024-08025-4. J. Devlin, M. Chang, K. Lee, and K. Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding.CoRR, abs/1810.04805,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-024-08025-4
-
[9]
URLhttp://arxiv.org/abs/1810.04805. A. Diaa, T. Aremu, and N. Lukas. Optimizing adaptive attacks against watermarks for language models.arXiv preprint arXiv:2410.02440,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Adopted 13 June 2024; OJ L, 12 July
URL http: //data.europa.eu/eli/reg/2024/1689/oj. Adopted 13 June 2024; OJ L, 12 July
work page 2024
-
[11]
T. Gloaguen, N. Jovanovi´c, R. Staab, and M. Vechev. Discovering clues of spoofed lm watermarks.arXiv preprint arXiv:2410.02693,
-
[12]
URL https://openreview.net/ forum?id=9k0krNzvlV. 10 T. Gu, Z. Wang, K. Huang, Y . Yao, X. Zhang, Y . Yang, and X. Chen. Invisible entropy: Towards safe and efficient low-entropy llm watermarking. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6727–6744,
work page 2025
- [13]
- [14]
-
[15]
On the reliability of watermarks for large language mod- els.arXiv preprint arXiv:2306.04634, 2023
J. Kirchenbauer, J. Geiping, Y . Wen, J. Katz, I. Miers, and T. Goldstein. A watermark for large language models. InInternational Conference on Machine Learning, pages 17061–17084. PMLR, 2023a. J. Kirchenbauer, J. Geiping, Y . Wen, M. Shu, K. Saifullah, K. Kong, K. Fernando, A. Saha, M. Goldblum, and T. Goldstein. On the reliability of watermarks for larg...
-
[16]
R. Kuditipudi, J. Thickstun, T. Hashimoto, and P. Liang. Robust distortion-free watermarks for language models.Trans. Mach. Learn. Res., 2024,
work page 2024
-
[17]
T. Kumarage, J. Garland, A. Bhattacharjee, K. Trapeznikov, S. Ruston, and H. Liu. Stylometric detection of ai-generated text in twitter timelines.arXiv preprint arXiv:2303.03697,
-
[18]
T. Kumarage, G. Agrawal, P. Sheth, R. Moraffah, A. Chadha, J. Garland, and H. Liu. A survey of ai-generated text forensic systems: Detection, attribution, and characterization.arXiv preprint arXiv:2403.01152,
-
[19]
URL https://openreview.net/forum?id=gMLQwKDY3N. Y . Liu, X. Zhao, D. X. Song, G. W. Wornell, and Y . Bu. Position: Llm watermarking should align stakeholders’ incentives for practical adoption.ArXiv, abs/2510.18333,
work page internal anchor Pith review Pith/arXiv arXiv
- [20]
- [21]
-
[22]
11 Q. Pang, S. Hu, W. Zheng, and V . Smith. No free lunch in llm watermarking: Trade-offs in watermarking design choices. InNeural Information Processing Systems, 2024a. URLhttps://api.semanticscholar.org/ CorpusID:267938448. Q. Pang, S. Hu, W. Zheng, and V . Smith. Attacking LLM watermarks by exploiting their strengths. InICLR 2024 Workshop on Secure and...
- [23]
-
[24]
X. Zhao, P. V . Ananth, L. Li, and Y .-X. Wang. Provable robust watermarking for AI-generated text. InThe Twelfth International Conference on Learning Representations, 2024a. URL https://openreview.net/ forum?id=SsmT8aO45L. X. Zhao, S. Gunn, M. Christ, J. Fairoze, A. Fabrega, N. Carlini, S. Garg, S. Hong, M. Nasr, F. Tramer, et al. Sok: Watermarking for a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.