Recognition: 1 theorem link
· Lean TheoremItemRAG: Item-Based Retrieval-Augmented Generation for LLM-Based Recommendation
Pith reviewed 2026-05-17 21:16 UTC · model grok-4.3
The pith
ItemRAG improves LLM recommendations by retrieving relevant items using semantic and co-purchase data instead of similar user histories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
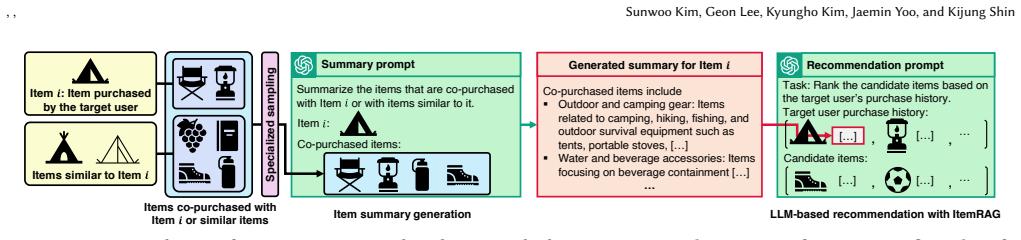
ItemRAG augments the description of each item in the target user's history or the candidate set by retrieving items relevant to each through a combination of semantic similarity and co-purchase information, thereby prioritizing informative retrievals and benefiting cold-start items.
What carries the argument
Item-level retrieval that combines semantic similarity with co-purchase patterns to select informative items for augmenting prompts to the LLM.
If this is right
- Outperforms existing RAG approaches in standard recommendation settings.
- Provides better performance for cold-start item recommendations.
- Reduces the impact of noisy or weakly relevant user history information.
- Delivers consistent improvements across multiple datasets without per-dataset retuning.
Where Pith is reading between the lines
- This item-focused retrieval could be tested in other sequence prediction tasks involving LLMs such as playlist generation.
- Varying the weight between semantic and co-purchase signals may optimize performance for specific recommendation domains.
- The method may integrate with graph-based models to strengthen the co-purchase component.
Load-bearing premise
The combination of semantic similarity and co-purchase information will reliably surface informative retrievals rather than noisy ones across datasets without extensive per-dataset retuning or introducing new biases.
What would settle it
Experiments showing that ItemRAG does not outperform baseline RAG methods on recommendation accuracy metrics like hit rate or NDCG in either standard or cold-start settings.
Figures


read the original abstract
Recently, large language models (LLMs) have been widely used as recommender systems, owing to their reasoning capability and effectiveness in handling cold-start items. A common approach prompts an LLM with a target user's purchase history to recommend items from a candidate set, often enhanced with retrieval-augmented generation (RAG). Most existing RAG approaches retrieve purchase histories of users similar to the target user; however, these histories often contain noisy or weakly relevant information and provide little or no useful information for candidate items. To address these limitations, we propose ItemRAG, a novel RAG approach that shifts focus from coarse user-history retrieval to fine-grained item-level retrieval. ItemRAG augments the description of each item in the target user's history or the candidate set by retrieving items relevant to each. To retrieve items not merely semantically similar but informative for recommendation, ItemRAG leverages co-purchase information alongside semantic information. Especially, through their careful combination, ItemRAG prioritizes more informative retrievals and also benefits cold-start items. Through extensive experiments, we demonstrate that ItemRAG consistently outperforms existing RAG approaches under both standard and cold-start item recommendation settings. Supplementary materials, code, and datasets are provided at https://github.com/kswoo97/ItemRAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ItemRAG, an item-based retrieval-augmented generation method for LLM-based recommendation. Rather than retrieving similar user purchase histories, ItemRAG augments each item in the target user's history or the candidate set by retrieving relevant items via a combination of semantic embeddings and co-purchase co-occurrence information. The central claim is that this item-level approach yields more informative augmentations than prior user-history RAG methods and produces consistent gains in both standard and cold-start recommendation settings, supported by experiments on multiple datasets with released code and data.
Significance. If the empirical results are robust, the shift to fine-grained item-level retrieval could meaningfully improve LLM recommenders, especially for cold-start items where user-history signals are sparse. The public release of code, datasets, and supplementary materials strengthens reproducibility and enables direct follow-up work.
major comments (2)
- [§3.2 and Algorithm 1] §3.2 and Algorithm 1: the fusion of semantic similarity and co-purchase signals is presented as a linear or rank-fused score, yet no sensitivity analysis of NDCG/HR to the fusion hyperparameter (or weighting) is reported across the four datasets. If the optimal balance varies with graph density or popularity skew, the claimed consistent outperformance may depend on per-dataset retuning rather than an intrinsic property of the item-level design.
- [Experimental section] Experimental section: the abstract asserts consistent outperformance, but details on statistical significance testing, exact baseline re-implementations, and any post-hoc hyperparameter choices are not fully specified in the provided text, which is required to substantiate the central empirical claim.
minor comments (2)
- [§3.2] Clarify the exact definition of the rank-fusion or linear combination formula (including any normalization) so that the retrieval procedure can be reproduced without ambiguity.
- Add error bars or standard deviations to all reported NDCG/HR tables and indicate whether differences are statistically significant.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable suggestions. We address the major comments point-by-point below, outlining the revisions we plan to make to improve the manuscript.
read point-by-point responses
-
Referee: [§3.2 and Algorithm 1] §3.2 and Algorithm 1: the fusion of semantic similarity and co-purchase signals is presented as a linear or rank-fused score, yet no sensitivity analysis of NDCG/HR to the fusion hyperparameter (or weighting) is reported across the four datasets. If the optimal balance varies with graph density or popularity skew, the claimed consistent outperformance may depend on per-dataset retuning rather than an intrinsic property of the item-level design.
Authors: We agree that a sensitivity analysis would strengthen the claims regarding the robustness of the fusion approach. In the original manuscript, the fusion weight was determined via grid search on a validation split for each dataset to optimize performance, which is a standard practice. To directly address this point, we will add a new subsection or figure in the revised version that plots NDCG@10 and HR@10 as a function of the fusion hyperparameter (e.g., alpha in [0,1]) for all four datasets. This analysis will show the stability of the performance gains and clarify whether the optimal weight is consistent or dataset-dependent. We believe this will demonstrate that the item-level design provides benefits across a range of fusion weights. revision: yes
-
Referee: [Experimental section] Experimental section: the abstract asserts consistent outperformance, but details on statistical significance testing, exact baseline re-implementations, and any post-hoc hyperparameter choices are not fully specified in the provided text, which is required to substantiate the central empirical claim.
Authors: We appreciate this feedback on the experimental details. The manuscript includes experimental results on multiple datasets with code released for reproducibility. However, to enhance clarity, in the revision we will expand the experimental section to include: (1) explicit mention of statistical significance tests (such as paired t-tests over multiple runs with reported p-values), (2) detailed descriptions of how each baseline was re-implemented, including the exact hyperparameter search ranges and selection criteria based solely on validation performance, and (3) confirmation that no post-hoc tuning was performed on the test set. These additions will be incorporated without altering the reported results. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces ItemRAG as a procedural item-level retrieval method for RAG in LLM-based recommendation systems, combining semantic embeddings with co-purchase signals via a described algorithm. Central claims rest on empirical outperformance versus prior RAG baselines under standard and cold-start settings, measured by external metrics such as NDCG and HR on multiple datasets. No derivation chain, equation, or prediction reduces by construction to fitted parameters or self-referential inputs; the method is a new retrieval procedure whose results are validated independently rather than forced by definition or self-citation load-bearing steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- retrieval hyperparameters (k, semantic/co-purchase weighting)
axioms (1)
- domain assumption Co-purchase information is available and carries recommendation-relevant signal beyond pure semantics.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ItemRAG augments ... by retrieving items relevant to each ... leverages co-purchase information alongside semantic information ... sampling ... proportional to their co-purchase frequencies
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Filling the Gaps: Selective Knowledge Augmentation for LLM Recommenders
KnowSA_CKP uses comparative knowledge probing to selectively augment LLM prompts for items with knowledge gaps, improving recommendation accuracy and context efficiency.
Reference graph
Works this paper leans on
-
[1]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and powering graph convolution network for recommendation. InSIGIR
work page 2020
-
[2]
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. 2024. Bridging language and items for retrieval and recommenda- tion.arXiv:2403.03952(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Zheng Hu, Yongsen Pan, Zetao Li, Jiaming Huang, Satoshi Nakagawa, Jiawen Deng, Shimin Cai, and Fuji Ren. 2026. Retrieval-enhanced, Adaptively Collabora- tive, and Temporal-aware user behavior comprehension for LLM-based sequential recommendation.Information Processing & Management63, 1 (2026), 104354
work page 2026
-
[4]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. InICDM
work page 2018
-
[5]
Sein Kim, Hongseok Kang, Seungyoon Choi, Donghyun Kim, Minchul Yang, and Chanyoung Park. 2024. Large language models meet collaborative filtering: An efficient all-round llm-based recommender system. InKDD
work page 2024
-
[6]
Sunwoo Kim, Geon Lee, Kyungho Kim, Jaemin Yoo, and Kijung Shin. 2025. Sup- plementary materials, code, and datasets for this work.https://anonymous. 4open.science/r/ItemRAG-DBD2/
work page 2025
-
[7]
Genki Kusano, Kosuke Akimoto, and Kunihiro Takeoka. 2025. Revisiting Prompt Engineering: A Comprehensive Evaluation for LLM-based Personalized Recom- mendation. InRecSys
work page 2025
-
[8]
Geon Lee, Kyungho Kim, and Kijung Shin. 2024. Revisiting LightGCN: Unex- pected Inflexibility, Inconsistency, and A Remedy Towards Improved Recommen- dation. InRecSys
work page 2024
-
[9]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[10]
BERT4Rec: Sequential recommendation with bidirectional encoder repre- sentations from transformer. InCIKM
-
[11]
Lei Wang and Ee-Peng Lim. 2024. The whole is better than the sum: Using aggregated demonstrations in in-context learning for sequential recommendation. InNAACL
work page 2024
-
[12]
Shijie Wang, Wenqi Fan, Yue Feng, Shanru Lin, Xinyu Ma, Shuaiqiang Wang, and Dawei Yin. 2025. Knowledge graph retrieval-augmented generation for llm-based recommendation. InACL
work page 2025
-
[13]
Shuyao Wang, Zhi Zheng, Yongduo Sui, and Hui Xiong. 2025. Unleashing the Power of Large Language Model for Denoising Recommendation. InWWW
work page 2025
-
[14]
Junda Wu, Cheng-Chun Chang, Tong Yu, Zhankui He, Jianing Wang, Yupeng Hou, and Julian McAuley. 2024. Coral: collaborative retrieval-augmented large language models improve long-tail recommendation. InKDD
work page 2024
-
[15]
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, et al . 2024. A survey on large language models for recommendation.World Wide Web27, 5 (2024), 60
work page 2024
- [16]
-
[17]
Peilin Zhou, Chao Liu, Jing Ren, Xinfeng Zhou, Yueqi Xie, Meng Cao, Zhongtao Rao, You-Liang Huang, Dading Chong, Junling Liu, et al. 2025. When Large Vision Language Models Meet Multimodal Sequential Recommendation: An Empirical Study. InWWW
work page 2025
-
[18]
Yaochen Zhu, Chao Wan, Harald Steck, Dawen Liang, Yesu Feng, Nathan Kallus, and Jundong Li. 2025. Collaborative Retrieval for Large Language Model-based Conversational Recommender Systems. InWWW
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.