Recognition: unknown
Filling the Gaps: Selective Knowledge Augmentation for LLM Recommenders
Pith reviewed 2026-05-10 17:31 UTC · model grok-4.3
The pith
Selective probing identifies LLM knowledge gaps so external information can be added only where needed for better recommendations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
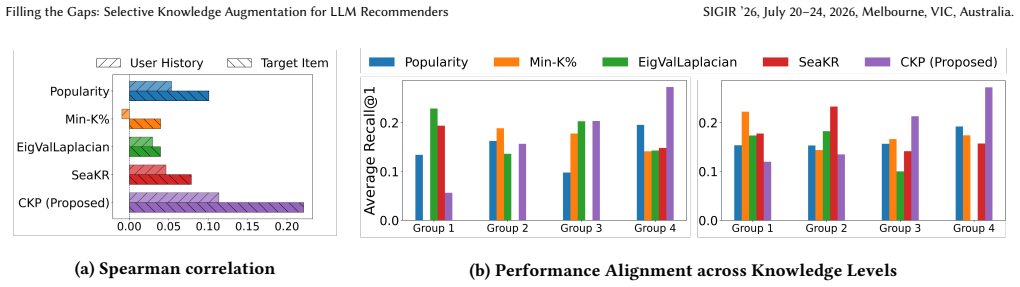
The paper establishes that an LLM's internal knowledge of items can be estimated through comparative probing of its ability to model collaborative patterns, allowing external information to be injected selectively rather than uniformly; this targeted supplementation improves recommendation performance by concentrating limited context resources on the items that most need it.
What carries the argument
KnowSA_CKP, which performs comparative knowledge probing to rank items by estimated knowledge gaps and then applies selective augmentation only to high-gap items.
If this is right
- Recommendation accuracy rises while total tokens in the prompt decrease because well-known items receive no extra text.
- The model avoids distraction from redundant facts and maintains stronger reasoning over the user history.
- The same probing-plus-selective pattern works across multiple datasets without requiring model retraining or parameter updates.
- Context budget is freed for longer user histories or more candidate items within the same token limit.
Where Pith is reading between the lines
- The probing technique could be adapted to detect gaps in other LLM tasks such as open-ended question answering or summarization.
- Combining the method with dynamic context allocation might further reduce costs in production recommendation systems.
- If the probe can be made cheaper, the approach scales to very large item catalogs where uniform augmentation is prohibitive.
Load-bearing premise
The model's performance on a collaborative-relationship probing task accurately reflects its true gaps in item-specific knowledge.
What would settle it
A controlled test in which items flagged as knowledge-gap items by the probe show no larger accuracy lift from augmentation than randomly selected items, or in which different probing tasks yield inconsistent gap rankings.
Figures



read the original abstract
Large language models (LLMs) have recently emerged as powerful training-free recommenders. However, their knowledge of individual items is inevitably uneven due to imbalanced information exposure during pretraining, a phenomenon we refer to as knowledge gap problem. To address this, most prior methods have employed a naive uniform augmentation that appends external information for every item in the input prompt. However, this approach not only wastes limited context budget on redundant augmentation for well-known items but can also hinder the model's effective reasoning. To this end, we propose KnowSA_CKP (Knowledge-aware Selective Augmentation with Comparative Knowledge Probing) to mitigate the knowledge gap problem. KnowSA_CKP estimates the LLM's internal knowledge by evaluating its capability to capture collaborative relationships and selectively injects additional information only where it is most needed. By avoiding unnecessary augmentation for well-known items, KnowSA_CKP focuses on items that benefit most from knowledge supplementation, thereby making more effective use of the context budget. KnowSA_CKP requires no fine-tuning step, and consistently improves both recommendation accuracy and context efficiency across four real-world datasets. Our code is available at https://github.com/nowhyun/KnowSA\_CKP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KnowSA_CKP, a training-free method for LLM-based recommenders to address uneven item knowledge ('knowledge gap problem') from pretraining imbalances. Rather than uniform external augmentation for all items (which wastes context and may impair reasoning), it employs Comparative Knowledge Probing to evaluate the LLM's ability to capture collaborative signals from user history, estimates per-item knowledge gaps, and selectively augments only the most needed items. The approach claims consistent gains in recommendation accuracy and context efficiency across four real-world datasets, with no fine-tuning and public code.
Significance. If the probing mechanism reliably isolates true item-level knowledge gaps, the selective augmentation could meaningfully improve context utilization and performance for LLM recommenders without training costs. Public code and training-free design are clear strengths that support reproducibility. However, the result's significance depends on whether the empirical gains hold under rigorous controls and whether the probing assumption is validated rather than assumed.
major comments (2)
- [§3 (KnowSA_CKP method and probing description)] The central assumption that comparative knowledge probing success directly measures the LLM's internal item knowledge (rather than reasoning ability, prompt sensitivity, or dataset-specific patterns) is load-bearing for the selective-injection claim but receives insufficient validation. If probing failures arise from non-knowledge factors, the method may augment the wrong items or skip real gaps, weakening both accuracy and efficiency results.
- [§4 (Experiments)] The experimental section reports consistent improvements on four datasets but provides no details on exact baselines, metrics, statistical significance tests, or controls for prompt variations and augmentation volume. Without these, it is impossible to assess whether the gains are attributable to selective augmentation or other factors.
minor comments (2)
- [Abstract] The abstract would benefit from naming the specific datasets, metrics, and magnitude of improvements to allow readers to gauge the claims immediately.
- [§3] Notation for the probing score and augmentation threshold should be defined more explicitly with an equation or pseudocode for clarity.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us identify areas for improvement in the manuscript. We address each major comment below and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: The central assumption that comparative knowledge probing success directly measures the LLM's internal item knowledge (rather than reasoning ability, prompt sensitivity, or dataset-specific patterns) is load-bearing for the selective-injection claim but receives insufficient validation. If probing failures arise from non-knowledge factors, the method may augment the wrong items or skip real gaps, weakening both accuracy and efficiency results.
Authors: We appreciate this concern regarding the validation of the probing mechanism. The design of Comparative Knowledge Probing is intended to assess the LLM's ability to leverage collaborative signals from user history for item prediction, which we argue serves as a proxy for internal knowledge of the item. To provide stronger evidence, we will include additional experiments in the revised manuscript, such as correlating probing scores with item popularity (as a proxy for pretraining exposure) and testing probing robustness across different prompt phrasings. This will help isolate knowledge gaps from other factors. revision: yes
-
Referee: The experimental section reports consistent improvements on four datasets but provides no details on exact baselines, metrics, statistical significance tests, or controls for prompt variations and augmentation volume. Without these, it is impossible to assess whether the gains are attributable to selective augmentation or other factors.
Authors: We regret that the experimental details were not sufficiently clear in the initial submission. We will revise the experimental section to explicitly detail the baselines used, the evaluation metrics, the statistical significance tests performed, and include additional controls for prompt variations and augmentation volume to better attribute the observed gains to the selective augmentation approach. revision: yes
Circularity Check
Empirical method with no derivation chain or self-referential reductions
full rationale
The paper introduces KnowSA_CKP as a practical, training-free algorithm that uses comparative knowledge probing to decide selective augmentation for LLM recommenders. It contains no equations, first-principles derivations, or mathematical predictions that could reduce to fitted parameters or self-definitions. Claims rest on experimental results across four datasets and public code, with no load-bearing self-citations or ansatzes that collapse the method to its inputs. This is self-contained empirical work; the central mechanism (probing success as proxy for knowledge gaps) is an explicit design choice, not a hidden equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Davide Abbattista, Vito Walter Anelli, Tommaso Di Noia, Craig Macdonald, and Aleksandr Vladimirovich Petrov. 2024. Enhancing sequential music recommen- dation with personalized popularity awareness. InProceedings of the 18th ACM Conference on Recommender Systems. 1168–1173
2024
- [2]
- [3]
-
[4]
Keqin Bao, Jizhi Zhang, Wenjie Wang, Yang Zhang, Zhengyi Yang, Yanchen Luo, Chong Chen, Fuli Feng, and Qi Tian. 2025. A bi-step grounding paradigm for large language models in recommendation systems.ACM Transactions on Recommender Systems3, 4 (2025), 1–27
2025
-
[5]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. Tallrec: An effective and efficient tuning framework to align large language model with recommendation. InProceedings of the 17th ACM Conference on Recommender Systems. 1007–1014
2023
-
[6]
Zhe Cao, Tao Qin, Tie-Yan Liu, Ming-Feng Tsai, and Hang Li. 2007. Learning to rank: from pairwise approach to listwise approach. InProceedings of the 24th international conference on Machine learning. 129–136
2007
-
[7]
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert- Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. 2021. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21). 2633–2650
2021
-
[8]
Jiaju Chen, Chongming Gao, Shuai Yuan, Shuchang Liu, Qingpeng Cai, and Peng Jiang. 2025. Dlcrec: A novel approach for managing diversity in llm- based recommender systems. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining. 857–865
2025
-
[9]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. InProceedings of the 10th ACM conference on recommender systems. 191–198
2016
-
[10]
Jinhao Duan, Hao Cheng, Shiqi Wang, Alex Zavalny, Chenan Wang, Renjing Xu, Bhavya Kailkhura, and Kaidi Xu. 2024. Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 5050–5063
2024
-
[11]
Ekaterina Fadeeva, Aleksandr Rubashevskii, Artem Shelmanov, Sergey Petrakov, Haonan Li, Hamdy Mubarak, Evgenii Tsymbalov, Gleb Kuzmin, Alexander Panchenko, Timothy Baldwin, et al . 2024. Fact-checking the output of large language models via token-level uncertainty quantification.arXiv preprint arXiv:2403.04696(2024)
-
[12]
Marina Fomicheva, Shuo Sun, Lisa Yankovskaya, Frédéric Blain, Francisco Guzmán, Mark Fishel, Nikolaos Aletras, Vishrav Chaudhary, and Lucia Specia
-
[13]
Unsupervised quality estimation for neural machine translation.Transac- tions of the Association for Computational Linguistics8 (2020), 539–555
2020
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
F Maxwell Harper and Joseph A Konstan. 2015. The movielens datasets: History and context.Acm transactions on interactive intelligent systems (tiis)5, 4 (2015), 1–19
2015
-
[16]
Jesse Harte, Wouter Zorgdrager, Panos Louridas, Asterios Katsifodimos, Diet- mar Jannach, and Marios Fragkoulis. 2023. Leveraging large language models for sequential recommendation. InProceedings of the 17th ACM Conference on Recommender Systems. 1096–1102
2023
-
[17]
Yupeng Hou, Junjie Zhang, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian McAuley, and Wayne Xin Zhao. 2024. Large language models are zero-shot rankers for recommender systems. InEuropean Conference on Information Retrieval. Springer, 364–381. Filling the Gaps: Selective Knowledge Augmentation for LLM Recommenders SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia
2024
-
[18]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[19]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong Park
-
[21]
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Kevin Duh, Helena Gomez, and Steven Bethard (Eds.). Association for Computational Li...
-
[22]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B.ArXivabs/2310.0...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 7969–7992
2023
- [24]
-
[25]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[26]
Wang-Cheng Kang and Julian McAuley. 2019. Candidate generation with binary codes for large-scale top-n recommendation. InProceedings of the 28th ACM international conference on information and knowledge management. 1523–1532
2019
-
[27]
Jieyong Kim, Hyunseo Kim, Hyunjin Cho, SeongKu Kang, Buru Chang, Jinyoung Yeo, and Dongha Lee. 2025. Review-driven Personalized Preference Reasoning with Large Language Models for Recommendation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’25). Association for Computing Machiner...
2025
-
[28]
Sein Kim, Hongseok Kang, Seungyoon Choi, Donghyun Kim, Minchul Yang, and Chanyoung Park. 2024. Large language models meet collaborative filtering: An efficient all-round llm-based recommender system. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1395–1406
2024
-
[29]
Sunwoo Kim, Geon Lee, Kyungho Kim, Jaemin Yoo, and Kijung Shin. 2025. Item- RAG: Item-Based Retrieval-Augmented Generation for LLM-Based Recommen- dation.arXiv preprint arXiv:2511.15141(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [30]
-
[31]
Jiayi Liao, Sihang Li, Zhengyi Yang, Jiancan Wu, Yancheng Yuan, and Xiang Wang
-
[32]
Llara: Aligning large language models with sequential recommenders.CoRR (2023)
2023
-
[33]
Jianghao Lin, Rong Shan, Chenxu Zhu, Kounianhua Du, Bo Chen, Shigang Quan, Ruiming Tang, Yong Yu, and Weinan Zhang. 2024. Rella: Retrieval-enhanced large language models for lifelong sequential behavior comprehension in recom- mendation. InProceedings of the ACM Web Conference 2024. 3497–3508
2024
-
[34]
Xinyu Lin, Wenjie Wang, Yongqi Li, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua
-
[35]
InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Bridging items and language: A transition paradigm for large language model-based recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1816–1826
-
[36]
Xinyu Lin, Wenjie Wang, Yongqi Li, Shuo Yang, Fuli Feng, Yinwei Wei, and Tat- Seng Chua. 2024. Data-efficient Fine-tuning for LLM-based Recommendation. InProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval. 365–374
2024
-
[37]
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. 2024. Generating with Confi- dence: Uncertainty Quantification for Black-box Large Language Models.Trans- actions on Machine Learning Research(2024). https://openreview.net/forum?id= DWkJCSxKU5
2024
-
[38]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. Lost in the middle: How language models use long contexts.arXiv preprint arXiv:2307.03172(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Qidong Liu, Xian Wu, Yejing Wang, Zijian Zhang, Feng Tian, Yefeng Zheng, and Xiangyu Zhao. 2024. Llm-esr: Large language models enhancement for long- tailed sequential recommendation.Advances in Neural Information Processing Systems37 (2024), 26701–26727
2024
-
[40]
Sichun Luo, Bowei He, Haohan Zhao, Wei Shao, Yanlin Qi, Yinya Huang, Aojun Zhou, Yuxuan Yao, Zongpeng Li, Yuanzhang Xiao, et al. 2024. Recranker: Instruc- tion tuning large language model as ranker for top-k recommendation.ACM Transactions on Information Systems(2024)
2024
- [41]
-
[42]
Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 188–197
2019
-
[43]
Aleksandr Petrov and Craig Macdonald. 2024. RSS: effective and efficient training for sequential recommendation using recency sampling.ACM Transactions on Recommender Systems3, 1 (2024), 1–32
2024
-
[44]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks.arXiv preprint arXiv:1908.10084(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[45]
Xubin Ren, Wei Wei, Lianghao Xia, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2024. Representation learning with large language models for recommendation. InProceedings of the ACM Web Conference 2024. 3464–3475
2024
-
[46]
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme
-
[47]
BPR: Bayesian personalized ranking from implicit feedback.arXiv preprint arXiv:1205.2618(2012)
work page internal anchor Pith review arXiv 2012
- [48]
-
[49]
Weihang Su, Yichen Tang, Qingyao Ai, Zhijing Wu, and Yiqun Liu. 2024. DRAGIN: Dynamic Retrieval Augmented Generation based on the Real-time Information Needs of Large Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Asso...
-
[50]
Qwen Team. 2024. Qwen2.5 Technical Report.ArXivabs/2412.15115 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [51]
-
[52]
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. 2021. Finetuned language models are zero-shot learners.arXiv preprint arXiv:2109.01652(2021)
work page internal anchor Pith review arXiv 2021
- [53]
- [54]
-
[55]
Yuqing Yang, Lei Jiao, and Yuedong Xu. 2024. A queueing theoretic perspective on low-latency llm inference with variable token length. In2024 22nd Interna- tional Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOpt). IEEE, 273–280
2024
-
[56]
Zijun Yao, Weijian Qi, Liangming Pan, Shulin Cao, Linmei Hu, Liu Weichuan, Lei Hou, and Juanzi Li. 2025. SeaKR: Self-aware Knowledge Retrieval for Adaptive Retrieval Augmented Generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vienna, Aus...
- [57]
- [58]
- [59]
-
[60]
Yang Zhang, Keqin Bao, Ming Yan, Wenjie Wang, Fuli Feng, and Xiangnan He
- [61]
-
[62]
Yang Zhang, Fuli Feng, Jizhi Zhang, Keqin Bao, Qifan Wang, and Xiangnan He
-
[63]
Collm: Integrating collaborative embeddings into large language models for recommendation.IEEE Transactions on Knowledge and Data Engineering(2025)
2025
-
[64]
Zhi Zheng, Wenshuo Chao, Zhaopeng Qiu, Hengshu Zhu, and Hui Xiong. 2024. Harnessing large language models for text-rich sequential recommendation. In Proceedings of the ACM Web Conference 2024. 3207–3216
2024
-
[65]
Baohang Zhou, Zezhong Wang, Lingzhi Wang, Hongru Wang, Ying Zhang, Kehui Song, Xuhui Sui, and Kam-Fai Wong. 2024. DPDLLM: A Black-box Framework for Detecting Pre-training Data from Large Language Models. InFindings of the Association for Computational Linguistics ACL 2024. 644–653
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.