SciHorizon-GENE: Benchmarking LLM for Life Sciences Inference from Gene Knowledge to Functional Understanding
Pith reviewed 2026-05-25 07:02 UTC · model grok-4.3
The pith
LLMs display wide variation in gene reasoning and often fail to produce complete, literature-grounded functional interpretations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
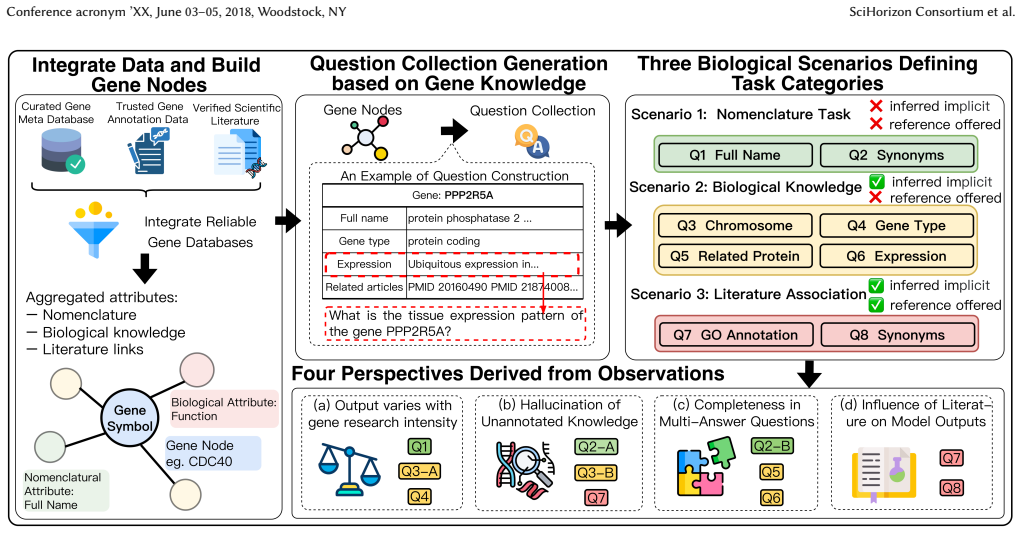
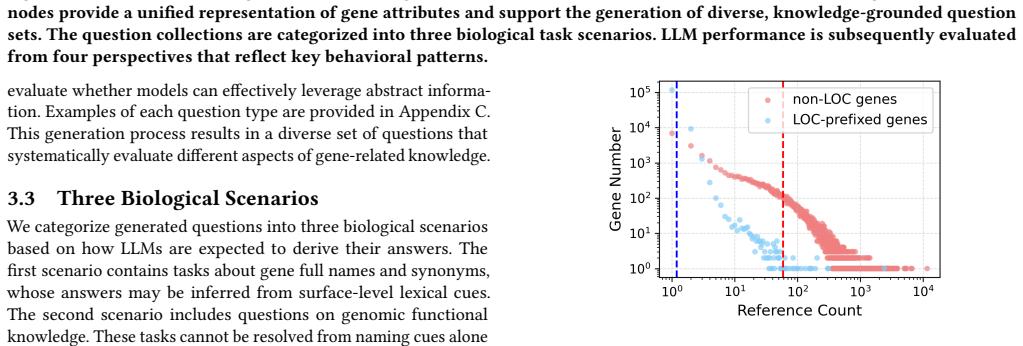
SciHorizon-GENE integrates knowledge for over 190K human genes into more than 540K questions and evaluates LLMs on research attention sensitivity, hallucination tendency, answer completeness, and literature influence, exposing substantial heterogeneity in gene-level reasoning capabilities together with persistent shortfalls in faithful, complete, and literature-grounded functional interpretations.
What carries the argument
The SciHorizon-GENE benchmark, which organizes questions around four biologically critical perspectives to expose failure modes in gene-to-function reasoning.
If this is right
- LLMs require explicit model selection and validation before deployment in knowledge-enhanced cell atlas interpretation.
- Development efforts should target improvements in faithfulness, completeness, and literature grounding for gene-level outputs.
- The benchmark supplies a reusable test bed for tracking progress in biological reasoning capabilities.
- Heterogeneity across models indicates that current general-purpose and biomedical LLMs are not interchangeable for gene-function tasks.
Where Pith is reading between the lines
- Extending the benchmark to multi-gene or pathway-level questions could reveal whether the observed gaps scale with task complexity.
- The four evaluation perspectives might be adapted to measure similar reasoning limits in other scientific domains that rely on curated knowledge bases.
- If the heterogeneity persists after retrieval augmentation, it would point to deeper architectural constraints rather than simple knowledge gaps.
Load-bearing premise
The questions drawn from authoritative databases accurately represent the range of gene-to-function scenarios and failure modes that would affect LLM use in biological interpretation pipelines.
What would settle it
A single new LLM that scores uniformly high on all four evaluation perspectives across the full set of 540K questions without extra training or retrieval would contradict the reported persistent challenges.
Figures







read the original abstract
Large language models (LLMs) have shown growing promise in biomedical research, particularly for knowledge-driven interpretation tasks. However, their ability to reliably reason from gene-level knowledge to functional understanding, a core requirement for knowledge-enhanced cell atlas interpretation, remains largely underexplored. To address this gap, we introduce SciHorizon-GENE, a large-scale gene-centric benchmark constructed from authoritative biological databases. The benchmark integrates curated knowledge for over 190K human genes and comprises more than 540K questions covering diverse gene-to-function reasoning scenarios relevant to cell type annotation, functional interpretation, and mechanism-oriented analysis. Motivated by behavioral patterns observed in preliminary examinations, SciHorizon-GENE evaluates LLMs along four biologically critical perspectives: research attention sensitivity, hallucination tendency, answer completeness, and literature influence, explicitly targeting failure modes that limit the safe adoption of LLMs in biological interpretation pipelines. We systematically evaluate a wide range of state-of-the-art general-purpose and biomedical LLMs, revealing substantial heterogeneity in gene-level reasoning capabilities and persistent challenges in generating faithful, complete, and literature-grounded functional interpretations. Our benchmark establishes a systematic foundation for analyzing LLM behavior at the gene scale and offers insights for model selection and development, with direct relevance to knowledge-enhanced biological interpretation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SciHorizon-GENE, a large-scale benchmark constructed from authoritative biological databases containing curated knowledge for over 190K human genes and more than 540K questions. It evaluates state-of-the-art LLMs on four perspectives—research attention sensitivity, hallucination tendency, answer completeness, and literature influence—revealing substantial heterogeneity in gene-level reasoning capabilities and persistent challenges in generating faithful, complete, and literature-grounded functional interpretations relevant to cell atlas interpretation.
Significance. If the benchmark questions validly capture real-world failure modes in gene-to-function reasoning, the findings would provide a valuable systematic foundation for analyzing LLM behavior at the gene scale and informing model selection and development in biomedical applications.
major comments (1)
- [Abstract] Abstract: The central claims of substantial heterogeneity and persistent challenges in LLM gene-to-function reasoning rest on SciHorizon-GENE accurately representing diverse real-world scenarios. The description provides no details on question validation, bias controls, sampling strategy, coverage of mechanism-oriented analysis, or validation of the curation process against expert workflows in cell-type annotation tasks.
minor comments (1)
- [Abstract] Abstract: Specific performance metrics, example questions, and quantitative results are absent, making it difficult to assess the scale of reported heterogeneity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback emphasizing the need for greater methodological transparency to support the benchmark's claims. We address the single major comment below and will incorporate clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of substantial heterogeneity and persistent challenges in LLM gene-to-function reasoning rest on SciHorizon-GENE accurately representing diverse real-world scenarios. The description provides no details on question validation, bias controls, sampling strategy, coverage of mechanism-oriented analysis, or validation of the curation process against expert workflows in cell-type annotation tasks.
Authors: The abstract is intentionally brief. The full manuscript (Section 3) describes construction from authoritative databases covering >190K genes and >540K questions, with explicit inclusion of mechanism-oriented scenarios via pathway, interaction, and regulatory data relevant to cell-type annotation. Sampling is exhaustive (all curated entries) rather than subsampled. We acknowledge the abstract and main text lack explicit subsections on question validation procedures, bias controls, and direct comparison to expert cell-type annotation workflows. We will add a dedicated 'Benchmark Validation and Bias Controls' subsection detailing curation validation steps, relevance checks for cell atlas tasks, and any bias mitigation (e.g., source diversity), plus a brief reference in the abstract. This addresses the concern without changing results. revision: yes
Circularity Check
No circularity: benchmark constructed from external databases; LLM evaluations independent of paper inputs
full rationale
The paper introduces SciHorizon-GENE as a benchmark built directly from authoritative external biological databases covering 190K genes and 540K questions. The central claims concern observed heterogeneity in LLM performance across four perspectives (research attention sensitivity, hallucination tendency, answer completeness, literature influence) when evaluated on this benchmark. No equations, parameter fits, self-citations, or ansatzes are invoked as load-bearing steps in the derivation chain. The benchmark construction and evaluation results do not reduce to the paper's own inputs by definition or construction, satisfying the criteria for a self-contained, non-circular analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Authoritative biological databases provide accurate and representative gene knowledge sufficient for constructing a benchmark that reflects real-world functional interpretation needs.
Forward citations
Cited by 1 Pith paper
-
BioHarness: Substrate-Aware Evidence Assembly for Biomedical Question Answering across Literature, Knowledge Bases, and Biological Atlases
BioHarness improves pooled biomedical QA score from 65.9 to 71.0 on 19,302 items by using staged, substrate-aware evidence assembly that escalates only when needed.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.