Recognition: no theorem link
Agentic Much? Adoption of Coding Agents on GitHub
Pith reviewed 2026-05-16 10:55 UTC · model grok-4.3
The pith
Coding agents have been adopted in 22 to 29 percent of GitHub projects within months of emergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We leverage explicit traces such as co-authoring commits or pull requests to present the first large-scale study of 128,018 projects, finding an estimated adoption rate of 22.20%--28.66% for coding agents, which is very high for a technology only a few months old and increasing. Adoption is broad across project maturity, established organizations, and diverse languages or topics. Commits assisted by coding agents are larger than those authored only by humans and have a large proportion of features and bug fixes.
What carries the argument
Explicit traces in software engineering artifacts, such as co-authoring commits or pull requests, used to identify coding agent usage.
If this is right
- Adoption spans the entire spectrum of project maturity.
- It includes established organizations.
- It concerns diverse programming languages or project topics.
- Commits assisted by coding agents are larger than those authored only by humans.
- These assisted commits contain a large proportion of features and bug fixes.
Where Pith is reading between the lines
- Review processes may need to adapt to handle larger, agent-generated changes.
- Development workflows could shift toward higher-level task descriptions rather than line-by-line editing.
- Software engineering education may require new emphasis on supervising and integrating agent outputs.
- Longitudinal tracking could reveal whether adoption stabilizes or accelerates further.
Load-bearing premise
That explicit traces such as co-authoring commits or pull requests reliably and comprehensively identify coding agent usage without substantial false positives or negatives from other tools or manual attribution.
What would settle it
A manual audit of a random sample of flagged projects that finds no evidence of actual coding agent use, or a sample of non-flagged projects that reveals widespread hidden agent activity.
Figures









read the original abstract
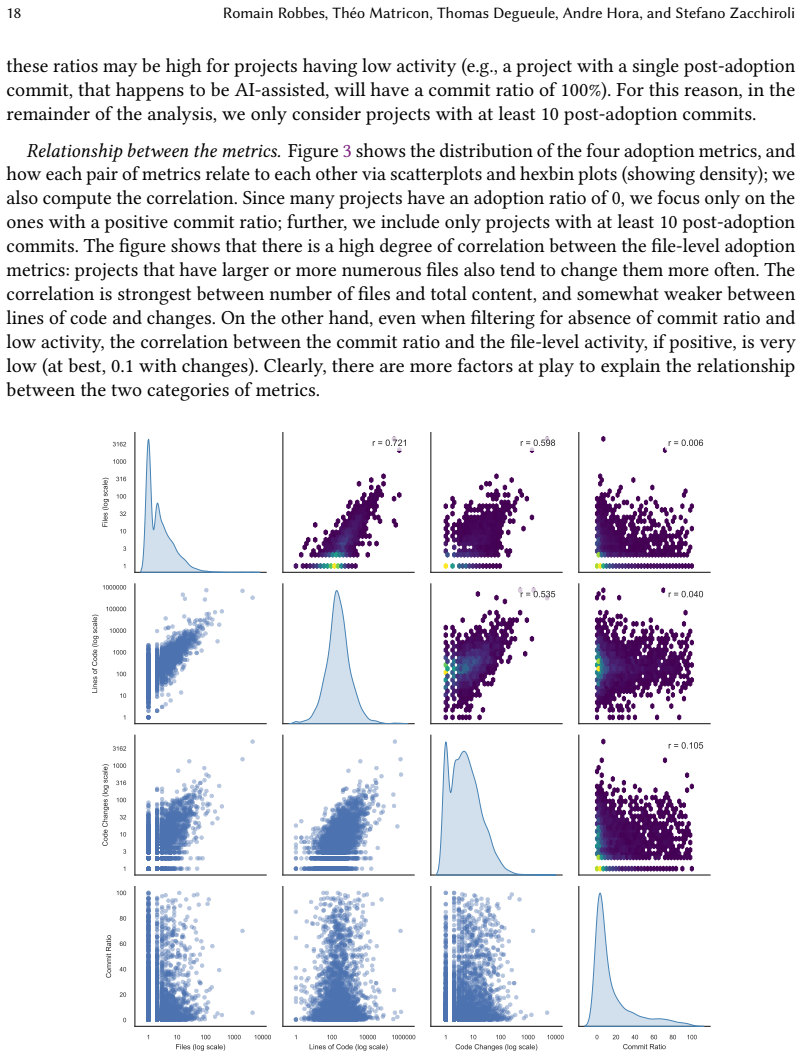
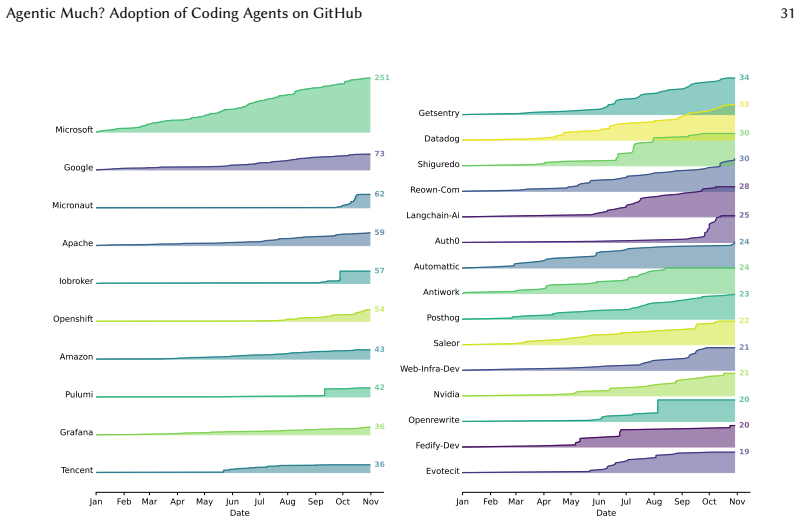
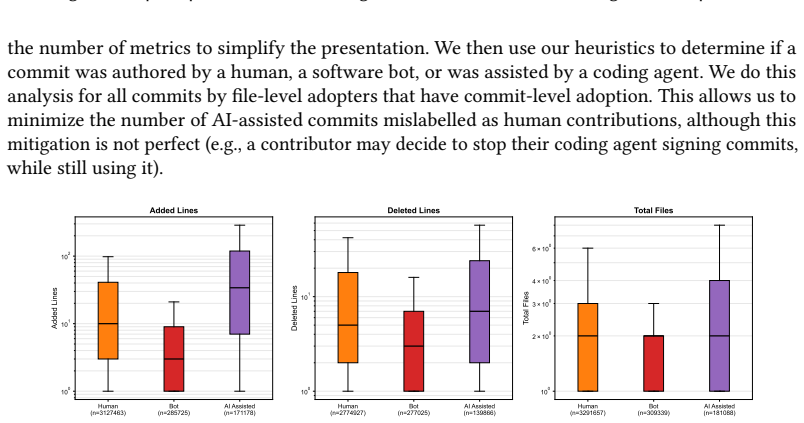
In the first half of 2025, coding agents have emerged as a category of development tools that have very quickly transitioned to the practice. Unlike ''traditional'' code completion LLMs such as Copilot, agents like Cursor, Claude Code, or Codex operate with high degrees of autonomy, up to generating complete pull requests starting from a developer-provided task description. This new mode of operation is poised to change the landscape in an even larger way than code completion LLMs did, making the need to study their impact critical. Also, unlike traditional LLMs, coding agents tend to leave more explicit traces in software engineering artifacts, such as co-authoring commits or pull requests. We leverage these traces to present the first large-scale study (128,018 projects) of the adoption of coding agents on GitHub, finding an estimated adoption rate of 22.20%--28.66%, which is very high for a technology only a few months old--and increasing. We carry out an in-depth study of the adopters we identified, finding that adoption is broad: it spans the entire spectrum of project maturity; it includes established organizations; and it concerns diverse programming languages or project topics. At the commit level, we find that commits assisted by coding agents are larger than commits only authored by human developers, and have a large proportion of features and bug fixes. These findings highlight the need for further investigation into the practical use of coding agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first large-scale study of coding agent adoption on GitHub, analyzing explicit traces (such as co-authored commits and pull requests) across 128,018 projects to estimate an adoption rate of 22.20%–28.66% in the first half of 2025. It characterizes adopters as spanning project maturity levels, established organizations, and diverse languages/topics, and reports that agent-assisted commits are larger than human-only commits with a higher proportion of features and bug fixes.
Significance. If the trace-identification method proves reliable, the work supplies a valuable early baseline on the rapid uptake of autonomous coding agents, leveraging a large sample size and direct GitHub artifacts. The broad adoption findings and commit-level differences (size, content type) offer concrete observations that could guide subsequent empirical SE research on AI tooling impact.
major comments (1)
- [Abstract and methods section describing trace identification] The central adoption-rate estimate (22.20%–28.66%) rests on identification of 'explicit traces' such as co-authoring commits or PRs, yet the precise detection rules (keyword lists, commit-message patterns, co-author fields, or sampling strategy) are not specified, and no precision/recall figures or manual ground-truth audit are reported. This directly affects the validity of the headline percentage and the claim of 'very high' adoption for a months-old technology.
minor comments (1)
- [Abstract] The abstract states the study covers 'the first half of 2025' but does not list the exact months or data-collection cutoff; adding this would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the significance of this early baseline study on coding agent adoption. We address the major comment below and will revise the manuscript to improve methodological transparency.
read point-by-point responses
-
Referee: The central adoption-rate estimate (22.20%–28.66%) rests on identification of 'explicit traces' such as co-authoring commits or PRs, yet the precise detection rules (keyword lists, commit-message patterns, co-author fields, or sampling strategy) are not specified, and no precision/recall figures or manual ground-truth audit are reported. This directly affects the validity of the headline percentage and the claim of 'very high' adoption for a months-old technology.
Authors: We agree that the current manuscript provides only a high-level overview of the trace-identification process and that greater detail is needed for reproducibility and to substantiate the adoption-rate claims. In the revised version we will expand the methods section to explicitly list the keyword patterns used for commit messages and PR descriptions, the exact co-author field matching rules, the criteria for identifying agent-assisted commits versus PRs, and the full sampling strategy applied to the 128,018 projects. We will also perform a manual ground-truth audit on a stratified random sample of the detected traces, compute precision and recall, and report these figures together with the revised adoption-rate estimates. These additions will directly address the concern about the reliability of the 22.20%–28.66% range. revision: yes
Circularity Check
No circularity: adoption rate is a direct empirical count from observed GitHub traces.
full rationale
The paper's main result is an adoption rate of 22.20%–28.66% obtained by counting the proportion of 128,018 projects that exhibit explicit traces (co-authoring commits or pull requests). This is a straightforward observational tally with no equations, fitted parameters, self-citations, or ansatzes invoked to derive the percentage; the figure is literally the ratio of detected projects to the total corpus. No load-bearing step reduces to a prior result by construction, and the study is self-contained as an empirical measurement against external GitHub artifacts.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Commit and pull-request co-authorship traces accurately reflect coding agent involvement
Forward citations
Cited by 7 Pith papers
-
A Dataset of Agentic AI Coding Tool Configurations
A publicly released dataset of 15,591 configuration artifacts for five agentic AI coding tools, drawn from 4,738 GitHub repositories along with associated files and AI-co-authored commits.
-
Architecture Without Architects: How AI Coding Agents Shape Software Architecture
AI coding agents perform vibe architecting by making prompt-driven architectural choices that produce structurally different systems for identical tasks.
-
A Large-Scale Empirical Study of AI-Generated Code in Real-World Repositories
A large-scale study of real-world repositories finds that AI-generated code differs from human-written code in complexity, structural traits, defect indicators, and commit-level activity patterns.
-
Code Review Agent Benchmark
c-CRAB benchmark shows state-of-the-art code review agents solve only around 40% of tasks derived from human reviews, suggesting potential for human-AI collaboration.
-
ORBIT: Guided Agentic Orchestration for Autonomous C-to-Rust Transpilation
ORBIT achieves 100% compilation success and 91.7% test success on 24 mostly large programs from CRUST-Bench by using dependency-aware orchestration and iterative verification, outperforming prior static and baseline tools.
-
The Buy-or-Build Decision, Revisited: How Agentic AI Changes the Economics of Enterprise Software
Agentic AI transforms in-house software development into a hybrid governance model but does not overturn the advantages of buying SaaS for most enterprise application categories.
-
Tokalator: A Context Engineering Toolkit for Artificial Intelligence Coding Assistants
Tokalator is a toolkit with VS Code extension, calculators, and community resources to monitor and optimize token usage in AI coding environments.
Reference graph
Works this paper leans on
-
[1]
2025.Anthropic Economic Index: Uneven Geographic and Enterprise AI Adoption
Anthropic. 2025.Anthropic Economic Index: Uneven Geographic and Enterprise AI Adoption. Technical Report. Anthropic PBC. https://assets.anthropic.com/m/218c82b858610fac/original/Economic-Index.pdf Report, 15 Sept 2025
work page 2025
- [2]
-
[3]
Shraddha Barke, Michael B James, and Nadia Polikarpova. 2023. Grounded copilot: How programmers interact with code-generating models.Proceedings of the ACM on Programming Languages7, OOPSLA1 (2023), 85–111
work page 2023
- [4]
-
[5]
Christian Bird, Peter C Rigby, Earl T Barr, David J Hamilton, Daniel M German, and Prem Devanbu. 2009. The promises and perils of mining git. In2009 6th IEEE International Working Conference on Mining Software Repositories. IEEE, 1–10
work page 2009
- [6]
-
[7]
Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry
Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E. Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry. 2024. Introducing SWE-bench Verified. https://openai.com/index/introducing-swe-bench-verified/
work page 2024
-
[8]
William G. Cochran. 1977.Sampling Techniques(3rd ed.). John Wiley & Sons, New York
work page 1977
-
[9]
Roberto Di Cosmo and Stefano Zacchiroli. 2017. Software Heritage: Why and How to Preserve Software Source Code. InProceedings of the 14th International Conference on Digital Preservation (iPRES 2017). ACM, 1–10. doi:10.1145/ nnnnnnn.nnnnnnn
work page 2017
-
[10]
Ozren Dabic, Emad Aghajani, and Gabriele Bavota. 2021. Sampling projects in github for MSR studies. In2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR). IEEE, 560–564
work page 2021
-
[11]
Michael W Godfrey and Lijie Zou. 2005. Using origin analysis to detect merging and splitting of source code entities. IEEE Transactions on Software Engineering31, 2 (2005), 166–181
work page 2005
-
[12]
Leo A Goodman. 1965. On simultaneous confidence intervals for multinomial proportions.Technometrics7, 2 (1965), 247–254
work page 1965
-
[13]
William Harding. 2025. AI Copilot Code Quality: Evaluating 2024’s Increased Defect Rate via Code Quality Metrics. https://www.gitclear.com/ai_assistant_code_quality_2025_research Accessed on October 13th, 2025
work page 2025
-
[14]
William Harding and Matthew Kloster. 2024. Coding on Copilot: 2023 Data Suggests Downward Pressure on Code Qual- ity. https://www.gitclear.com/coding_on_copilot_data_shows_ais_downward_pressure_on_code_quality Accessed on 03 24, 2024
work page 2024
- [15]
-
[16]
Andre Hora, Danilo Silva, Marco Tulio Valente, and Romain Robbes. 2018. Assessing the threat of untracked changes in software evolution. InProceedings of the 40th International Conference on Software Engineering. 1102–1113
work page 2018
-
[17]
Saki Imai. 2022. Is github copilot a substitute for human pair-programming? an empirical study. InProceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings. 319–321
work page 2022
-
[18]
Maliheh Izadi, Jonathan Katzy, Tim Van Dam, Marc Otten, Razvan Mihai Popescu, and Arie Van Deursen. 2024. Language models for code completion: A practical evaluation. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
work page 2024
-
[19]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net
work page 2024
-
[20]
Aayush Kumar, Yasharth Bajpai, Sumit Gulwani, Gustavo Soares, and Emerson Murphy-Hill. 2025. Sharp Tools: How Developers Wield Agentic AI in Real Software Engineering Tasks.arXiv e-prints(2025), arXiv–2506
work page 2025
- [21]
-
[22]
Alexander Lex, Nils Gehlenborg, Hendrik Strobelt, Romain Vuillemot, and Hanspeter Pfister. 2014. UpSet: Visualization of intersecting sets.IEEE Transactions on Visualization and Computer Graphics20, 12 (2014), 1983–1992. doi:10.1109/ TVCG.2014.2346248 , Vol. 1, No. 1, Article . Publication date: January 2026. Agentic Much? Adoption of Coding Agents on GitHub 43
-
[23]
Hao Li, Haoxiang Zhang, and Ahmed E. Hassan. 2025. AIDev: Studying AI Coding Agents on GitHub. https: //doi.org/10.5281/zenodo.16919051. Accessed 2025-10-21
-
[24]
Jenny T Liang, Chenyang Yang, and Brad A Myers. 2024. A large-scale survey on the usability of ai programming assis- tants: Successes and challenges. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–13
work page 2024
- [25]
- [26]
- [27]
-
[28]
Nachiappan Nagappan and Thomas Ball. 2005. Use of relative code churn measures to predict system defect density. InProceedings of the 27th international conference on Software engineering. 284–292
work page 2005
-
[29]
What the data really shows about AI coding tools in 2025
Addy Osmani. 2025. The reality of AI-Assisted software engineering productivity. Substack blog post. https: //addyo.substack.com/p/the-reality-of-ai-assisted-software-engineering-productivity “What the data really shows about AI coding tools in 2025. ”
work page 2025
-
[30]
Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. 2023. The impact of ai on developer productivity: Evidence from github copilot.arXiv preprint arXiv:2302.06590(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Neil Perry, Megha Srivastava, Deepak Kumar, and Dan Boneh. 2023. Do users write more insecure code with AI assistants?. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security. 2785–2799
work page 2023
-
[32]
Romain Robbes, Théo Matricon, Thomas Degueule, Andre Hora, and Stefano Zacchiroli. 2025. Promises, Perils, and (Timely) Heuristics for Mining Coding Agent Activity.Under submission(2025)
work page 2025
-
[33]
G Rupert Jr et al. 2012. Simultaneous statistical inference. (2012)
work page 2012
-
[34]
Gustavo Sandoval, Hammond Pearce, Teo Nys, Ramesh Karri, Siddharth Garg, and Brendan Dolan-Gavitt. 2023. Lost at c: A user study on the security implications of large language model code assistants. In32nd USENIX Security Symposium (USENIX Security 23). 2205–2222
work page 2023
-
[35]
Klaas-Jan Stol and Brian Fitzgerald. 2018. The ABC of software engineering research.ACM Transactions on Software Engineering and Methodology (TOSEM)27, 3 (2018), 1–51
work page 2018
- [36]
-
[37]
A small, intense, word-sized graphic with typographic resolution
Edward R. Tufte. 2004. Sparkline Theory and Practice. Online article. https://www.edwardtufte.com/notebook/ sparkline-theory-and-practice-edward-tufte/ “A small, intense, word-sized graphic with typographic resolution. ”
work page 2004
-
[38]
Priyan Vaithilingam, Tianyi Zhang, and Elena L Glassman. 2022. Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models. InChi conference on human factors in computing systems extended abstracts. 1–7
work page 2022
- [39]
-
[40]
You Wang, Michael Pradel, and Zhongxin Liu. 2025. Are" Solved Issues" in SWE-bench Really Solved Correctly? An Empirical Study.arXiv preprint arXiv:2503.15223(2025)
-
[41]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2024. Agentless: Demystifying llm-based software engineering agents.arXiv preprint arXiv:2407.01489(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Tao Xiao, Youmei Fan, Fabio Calefato, Christoph Treude, Raula Gaikovina Kula, Hideaki Hata, and Sebastian Baltes
-
[43]
Self-Admitted GenAI Usage in Open-Source Software
Self-Admitted GenAI Usage in Open-Source Software.CoRRabs/2507.10422 (2025). arXiv:2507.10422 doi:10. 48550/ARXIV.2507.10422
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Qunhong Zeng, Yuxia Zhang, Zhiqing Qiu, and Hui Liu. 2025. A First Look at Conventional Commits Classification. In Proceedings of the IEEE/ACM 47th International Conference on Software Engineering. 2277–2289
work page 2025
-
[45]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Autocoderover: Autonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1592–1604
work page 2024
-
[46]
Albert Ziegler, Eirini Kalliamvakou, X Alice Li, Andrew Rice, Devon Rifkin, Shawn Simister, Ganesh Sittampalam, and Edward Aftandilian. 2022. Productivity assessment of neural code completion. InProceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming. 21–29. , Vol. 1, No. 1, Article . Publication date: January 2026
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.