Recognition: 1 theorem link
· Lean TheoremTraining Reasoning Models on Saturated Problems via Failure-Prefix Conditioning
Pith reviewed 2026-05-16 10:23 UTC · model grok-4.3
The pith
Conditioning on prefixes of rare incorrect trajectories unlocks learning signals in saturated reasoning problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
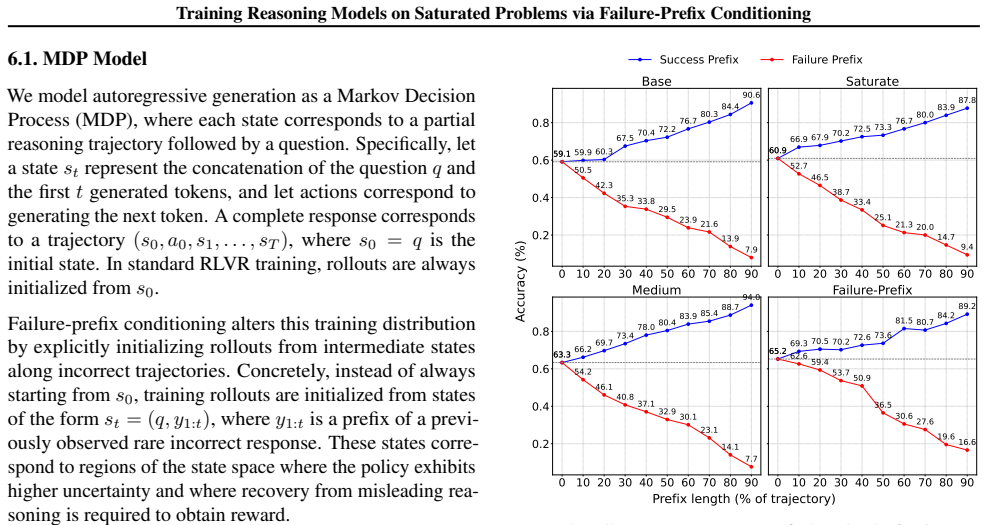
Failure-prefix conditioning conditions the model on prefixes drawn from rare incorrect trajectories within already-saturated problems. This shifts exploration toward failure-prone reasoning states and strengthens the ability to recover from misleading early steps. On saturated problems the method produces consistent performance lifts where standard RLVR stalls, reaches gains comparable to training on newly collected medium-difficulty items, reduces degradation under misleading prefixes, and yields further improvement when prefixes are refreshed iteratively.
What carries the argument
failure-prefix conditioning, which trains the policy by conditioning on prefixes of rare incorrect trajectories to improve recovery from misleading early reasoning states.
If this is right
- Performance continues to rise on problems where standard RLVR has already saturated.
- Improvements match those obtained by collecting new medium-difficulty problems.
- Robustness to misleading failure prefixes increases with only mild cost to correct early reasoning.
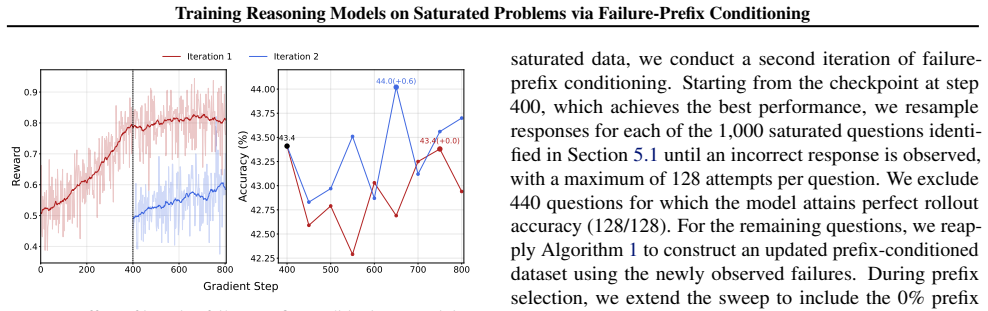
- Iterative refreshing of failure prefixes during training extracts further gains after initial plateaus.
Where Pith is reading between the lines
- The same prefix-conditioning idea could extend to other RL settings where easy examples dominate the data distribution.
- Pairing the method with automatic problem generation might lower the cost of maintaining a useful training curriculum.
- The approach may scale favorably to larger models where the fraction of saturated problems grows quickly.
Load-bearing premise
Conditioning on prefixes of rare incorrect trajectories supplies a useful learning signal for recovering from misleading reasoning without introducing harmful biases or weakening correct-path adherence.
What would settle it
A controlled run on a fixed set of saturated problems in which failure-prefix conditioning produces no additional accuracy gain over standard RLVR after the same number of gradient steps.
Figures




read the original abstract
As Reinforcement Learning with Verifiable Rewards (RLVR) substantially improves the reasoning abilities of large language models (LLMs), a new bottleneck emerges: more training problems become saturated, that is, the LLM answers the questions correctly for nearly every rollout. On such problems, rewards provide little useful learning signal. While collecting harder problems is a natural response, it is costly and increasingly difficult. We propose failure-prefix conditioning, a simple method that unlocks the remaining signal in saturated problems by shifting exploration toward failure-prone reasoning states. By conditioning on prefixes of rare incorrect trajectories, the method improves the model's ability to recover from misleading early reasoning. We observe that failure-prefix conditioning consistently improves performance where standard RLVR stalls, and achieves gains comparable to training on newly collected medium-difficulty problems. We further analyze the model's robustness, finding that our method reduces performance degradation under misleading failure prefixes, albeit with a mild trade-off in adherence to correct early reasoning. Finally, we demonstrate that an iterative approach, which refreshes failure prefixes during training, unlocks additional gains after performance plateaus. Overall, our results show that saturated problems still contain valuable learning signal, and that failure-prefix conditioning provides an effective way to unlock it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes failure-prefix conditioning to continue improving LLM reasoning via RLVR on saturated problems, where standard rewards provide little signal. The method conditions training on prefixes of rare incorrect trajectories to enhance recovery from misleading early reasoning states. It reports consistent gains over standard RLVR that match those from newly collected medium-difficulty problems, plus robustness analysis showing reduced degradation under misleading prefixes (with a mild trade-off on correct paths) and further gains from iteratively refreshing failure prefixes.
Significance. If the gains are attributable to the conditioning mechanism rather than incidental exposure to failures, the result would be significant: it offers a low-cost way to unlock signal in already-collected saturated problems instead of relying on expensive new data collection. The iterative prefix-refresh procedure and the robustness measurements are practical strengths that could influence how future RLVR pipelines handle plateaus.
major comments (3)
- [§4] §4 (Experiments) and §4.2 (Ablations): the central claim that gains arise specifically from prefix conditioning on rare failure trajectories is not isolated from the confound of simply training on additional failure trajectories. No ablation is reported that applies standard RLVR or SFT to the identical set of collected failure trajectories without the prefix-conditioning mechanism; therefore it remains possible that the observed improvements are due to extra gradient steps on failures rather than the proposed conditioning.
- [§3] §3 (Method): the precise implementation of failure-prefix conditioning inside the RL objective is underspecified. It is unclear whether the conditioning is applied only at the start of each rollout, throughout the trajectory, or via a modified reward/advantage estimator, and how the sampling distribution over prefixes is constructed to avoid biasing toward the rare failures.
- [§4.3] §4.3 (Robustness analysis): the reported reduction in performance degradation under misleading prefixes is presented without error bars or statistical tests across multiple seeds; given that the method already shows a mild trade-off in adherence to correct prefixes, the net effect on overall accuracy needs quantitative confirmation that the robustness benefit outweighs the adherence cost.
minor comments (2)
- [Figures] Figure 2 and 3: axis labels and legend entries are too small to read in the printed version; increase font size and add a short caption explaining the exact meaning of 'failure-prefix' vs. 'standard' curves.
- [§2] §2 (Related Work): the discussion of prior work on curriculum learning and failure-driven exploration omits recent papers on synthetic data filtering for reasoning (e.g., works using self-consistency or process supervision); adding 2–3 citations would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback on our manuscript. We appreciate the recognition of the potential significance of failure-prefix conditioning for unlocking signal in saturated RLVR problems. We address each major comment below, providing clarifications from the manuscript and indicating revisions where appropriate.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and §4.2 (Ablations): the central claim that gains arise specifically from prefix conditioning on rare failure trajectories is not isolated from the confound of simply training on additional failure trajectories. No ablation is reported that applies standard RLVR or SFT to the identical set of collected failure trajectories without the prefix-conditioning mechanism; therefore it remains possible that the observed improvements are due to extra gradient steps on failures rather than the proposed conditioning.
Authors: We agree this is a valid concern and that the current comparisons (standard RLVR on saturated problems vs. failure-prefix conditioning) do not fully isolate the conditioning mechanism from extra exposure to failure trajectories. The manuscript does not include an ablation applying standard RLVR or SFT directly to the collected failure trajectories without prefix conditioning. We will add this control experiment in the revised §4.2, training standard RLVR on the identical failure trajectories and reporting the resulting gains (or lack thereof) relative to our method. This will strengthen the evidence that improvements stem from the conditioning rather than additional gradient steps on failures. revision: yes
-
Referee: [§3] §3 (Method): the precise implementation of failure-prefix conditioning inside the RL objective is underspecified. It is unclear whether the conditioning is applied only at the start of each rollout, throughout the trajectory, or via a modified reward/advantage estimator, and how the sampling distribution over prefixes is constructed to avoid biasing toward the rare failures.
Authors: We apologize for the lack of detail in §3. In the implementation, failure prefixes are prepended only at the start of each rollout (as the initial prompt conditioning), after which the standard RLVR objective and advantage estimator are used on the full trajectory without modification. Prefixes are sampled from a small pool of rare incorrect trajectories collected from the current policy; we extract variable-length prefixes and sample with probability inversely proportional to their frequency to mitigate bias toward failures. We will revise §3 to include this precise description, along with pseudocode for the sampling procedure and conditioning application. revision: yes
-
Referee: [§4.3] §4.3 (Robustness analysis): the reported reduction in performance degradation under misleading prefixes is presented without error bars or statistical tests across multiple seeds; given that the method already shows a mild trade-off in adherence to correct prefixes, the net effect on overall accuracy needs quantitative confirmation that the robustness benefit outweighs the adherence cost.
Authors: We agree that the robustness analysis in §4.3 would be strengthened by error bars, statistical tests, and explicit quantification of the net effect. The reported results reflect averages over multiple seeds but omit variance and formal tests. In the revision, we will add error bars (standard deviation across 5 seeds), paired statistical tests (e.g., t-tests) for the degradation reduction, and a direct comparison of net accuracy impact to confirm the robustness benefit outweighs the mild trade-off on correct prefixes. revision: yes
Circularity Check
No circularity: empirical method with independent experimental validation
full rationale
The paper proposes failure-prefix conditioning as an empirical technique for RLVR on saturated problems and reports performance gains from experiments. No derivation chain, equations, or self-citations reduce the central claim to a tautology or fitted input by construction. The method is presented as a practical intervention whose value is assessed via direct comparison to baselines, with no load-bearing uniqueness theorems or ansatzes imported from prior self-work. The skeptic concern about missing ablations addresses experimental design validity rather than circularity in any claimed derivation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We select a single prefix s(q) whose rollout accuracy is closest to a target value τ ∈ (0,1) ... τ=0.5, where binary rewards exhibit the highest variance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Addressing Performance Saturation for LLM RL via Precise Entropy Curve Control
Entrocraft uses rejection sampling to enforce custom entropy curves in LLM RL, sustaining longer training, better generalization, and higher output diversity than prior regularization approaches.
-
Addressing Performance Saturation for LLM RL via Precise Entropy Curve Control
Entrocraft uses rejection sampling to enforce precise entropy schedules in LLM RL by biasing advantages, enabling longer training, better generalization, and higher performance than baselines.
Reference graph
Works this paper leans on
-
[1]
The unreasonable effectiveness of entropy minimization in LLM reasoning
Agarwal, S., Zhang, Z., Yuan, L., Han, J., and Peng, H. The unreasonable effectiveness of entropy minimization in LLM reasoning. InProceedings of the Thirty-Ninth Conference on Neural Information Processing Systems (NeurIPS 2025),
work page 2025
-
[2]
Hugging Face dataset. AI-MO. Amc12 2022, 2023 dataset. https://huggin gface.co/datasets/AI-MO/aimo-validat ion-amc,
work page 2022
-
[3]
Baker, B., Kanitscheider, I., Markov, T
Hugging Face dataset. Baker, B., Kanitscheider, I., Markov, T. M., Wu, Y ., Powell, G., McGrew, B., and Mordatch, I. Emergent tool use from multi-agent autocurricula. InProceedings of the International Conference on Learning Representations (ICLR 2020),
work page 2020
-
[4]
Self-evolving curriculum for llm reasoning.arXivpreprintarXiv:2505.14970, 2025
Chen, X., Lu, J., Kim, M., Zhang, D., Tang, J., Pich ´e, A., Gontier, N., Bengio, Y ., and Kamalloo, E. Self-evolving curriculum for llm reasoning.arXiv:2505.14970,
-
[5]
Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models, 2025a
Du, A., Gao, B., Xing, B., Jiang, C., Chen, C., Li, C., Xiao, C., Du, C., Liao, C., and ... Prorl: Prolonged reinforcement learning expands reasoning strategies. In Proceedings of the Thirty-Ninth Conference on Neural Information Processing Systems (NeurIPS 2025), 2025a. arXiv:2505.24864. Du, A., Gao, B., Xing, B., Jiang, C., Chen, C., Li, C., Xiao, C., D...
-
[6]
Gao, Z., Kim, J., Sun, W., Joachims, T., Wang, S., Pang, R. Y ., and Tan, L. Prompt curriculum learning for efficient llm post-training.arXiv:2510.01135,
-
[7]
doi: 10.1038/s41586-025-09422-z. Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the math dataset. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems (NeurIPS
-
[8]
Brorl: Scaling reinforcement learning via broadened exploration.arXiv:2510.01180,
Hu, J., Liu, M., Lu, X., Wu, F., Harchaoui, Z., Diao, S., Choi, Y ., Molchanov, P., Yang, J., Kautz, J., and Dong, Y . Brorl: Scaling reinforcement learning via broadened exploration.arXiv:2510.01180,
-
[9]
Jiang, M., Grefenstette, E., and Rockt¨aschel, T. Prioritized level replay. InProceedings of the 37th International Conference on Machine Learning (ICML 2020),
work page 2020
-
[10]
Kim, M., Shrestha, A., Shrestha, S., Nepal, A., and Ross, K. Reinforcement learning vs. distillation: Understanding ac- curacy and capability in llm reasoning.arXiv:2505.14216,
-
[11]
Association for Computing Machinery. doi: 10.1145/3600006.3613165. Lambert, N., Morrison, J., Pyatkin, V ., Huang, S., Ivison, H., Brahman, F., Miranda, L. J. V ., Liu, A., Dziri, N., Lyu, S., Gu, Y ., Malik, S., Graf, V ., Hwang, J. D., Yang, J., Le Bras, R., Tafjord, O., Wilhelm, C., Soldaini, L., Smith, N. A., Wang, Y ., Dasigi, P., and Hajishirzi, H. ...
-
[12]
arXiv:2505.12366. Liu, B., Guertler, L., Yu, S., Liu, Z., Qi, P., Balcells, D., Liu, M., Tan, C., Shi, W., Lin, M., Lee, W. S., and Jaques, 9 Training Reasoning Models on Saturated Problems via Failure-Prefix Conditioning N. Spiral: Self-play on zero-sum games incentivizes reasoning via multi-agent multi-turn reinforcement learn- ing. InProceedings of the...
-
[13]
arXiv:2506.24119. math-ai. Aime24 dataset. https://huggingface.co /datasets/math-ai/aime24 , 2025a. Hugging Face dataset. math-ai. Aime25 dataset. https://huggingface.co /datasets/math-ai/aime25 , 2025b. Hugging Face dataset. MathArena. Hmmt25 dataset (february 2025). https: //huggingface.co/datasets/MathArena/ hmmt_feb_2025,
-
[14]
arXiv:2412.16720. Portelas, R., Colas, C., Weng, L., Hofmann, K., and Oudeyer, P.-Y . Automatic curriculum learning for deep reinforcement learning: A short survey. InProceedings of the 29th International Joint Conference on Artificial Intelligence (IJCAI 2020),
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[15]
Qu, Y ., Setlur, A., Smith, V ., Salakhutdinov, R., and Kumar, A. How to explore to scale rl training of llms on hard problems? https://blog.ml.cmu.edu/2025/1 1/26/how-to-explore-to-scale-rl-train ing-of-llms-on-hard-problems ,
work page 2025
-
[16]
Razin, N., Zhou, H., Saremi, O., Thilak, V ., Bradley, A., Nakkiran, P., Susskind, J
CMU MLD Blog. Razin, N., Zhou, H., Saremi, O., Thilak, V ., Bradley, A., Nakkiran, P., Susskind, J. M., and Littwin, E. Vanishing gradients in reinforcement finetuning of language models. InInternational Conference on Learning Representations (ICLR 2024),
work page 2024
- [17]
-
[18]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
arXiv:2402.03300. Shi, T., Wu, Y ., Song, L., Zhou, T., and Zhao, J. Efficient reinforcement finetuning via adaptive curriculum learning. arXiv:2504.05520,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
arXiv:2504.20571. Wen, H., Su, Y ., Zhang, F., Liu, Y ., Liu, Y ., Zhang, Y .- Q., and Li, Y . Parathinker: Native parallel thinking as a new paradigm to scale llm test-time compute
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
arXiv:2503.14476. Yue, Y ., Chen, Z., Lu, R., Zhao, A., Wang, Z., Yue, Y ., Song, S., and Huang, G. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
arXiv:2504.13837. Zeng, Z., Ivison, H., Wang, Y ., Yuan, L., Li, S. S., Ye, Z., Li, S., He, J., Zhou, R., Chen, T., Zhao, C., Tsvetkov, Y ., Du, S. S., Jaques, N., Peng, H., Koh, P. W., and Hajishirzi, H. Rlve: Scaling up reinforcement learning for language models with adaptive verifiable environments. arXiv:2511.07317,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Zhang, X., Huang, Z., Li, Y ., Ni, C., Chen, J., and Oymak, S
arXiv:2510.02245. Zhang, X., Huang, Z., Li, Y ., Ni, C., Chen, J., and Oymak, S. Bread: Branched rollouts from expert anchors bridge sft & rl for reasoning. InProceedings of the Thirty-Ninth Conference on Neural Information Processing Systems (NeurIPS 2025),
-
[24]
arXiv:2506.17211. Zhao, A., Wu, Y ., Yue, Y ., Wu, T., Xu, Q., Lin, M., Wang, S., Wu, Q., Zheng, Z., and Huang, G. Absolute zero: Rein- forced self-play reasoning with zero data. InProceedings of the Thirty-Ninth Conference on Neural Information Processing Systems,
-
[25]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
arXiv:2505.03335. 10 Training Reasoning Models on Saturated Problems via Failure-Prefix Conditioning Zhu, X., Panigrahi, A., and Arora, S. On the power of context-enhanced learning in llms. InProceedings of the 42nd International Conference on Machine Learning (ICML 2025), 2025a. arXiv:2503.01821. Zhu, X., Xia, M., Wei, Z., Chen, W.-L., Chen, D., and Meng...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Hyperparameter Value Maximum token length 6000 Temperature 1.0 Top-p1.0 Number of rollouts per question 32 Table 5.Key hyperparameters used for inference for identifying saturated questions and determining best prefix length. Identifying saturated questionsAs described in Section 5, we identify saturated questions as those with rollout accuracy 31/32. If ...
work page 2025
-
[27]
Here,f(x, y)is a surrogate objective function inherited from PPO-style policy optimization
GRPO-style objectiveWe consider the expectation form of the GRPO-family objective (omitting KL regularization for clarity): J0(θ) =E qEo∼πold(·|q) 1 |o| |o|X t=1 f πθ(ot |q, o <t) πold(ot |q, o <t) , A(o|q) . Here,f(x, y)is a surrogate objective function inherited from PPO-style policy optimization. For GRPO specifically, f(x, y) = min xy,clip(x,1...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.