Recognition: no theorem link
Addressing Performance Saturation for LLM RL via Precise Entropy Curve Control
Pith reviewed 2026-05-12 01:52 UTC · model grok-4.3
The pith
Rejection sampling on advantages lets users set exact entropy curves during LLM reinforcement learning to avoid saturation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Entrocraft is a rejection-sampling procedure that selectively accepts or rejects trajectories so the distribution of advantages produces a prescribed change in policy entropy at every step. Under minimal assumptions this procedure relates the per-step entropy shift directly to the advantage distribution, which accounts for why prior regularization and clipping methods behave as they do. Systematic tests show that a linear-annealing schedule starting high and ending slightly lower outperforms constant or other shapes.
What carries the argument
Rejection sampling that filters trajectories according to the advantage values needed to hit a target entropy increment, thereby shaping the entropy curve without altering the underlying policy-gradient objective.
If this is right
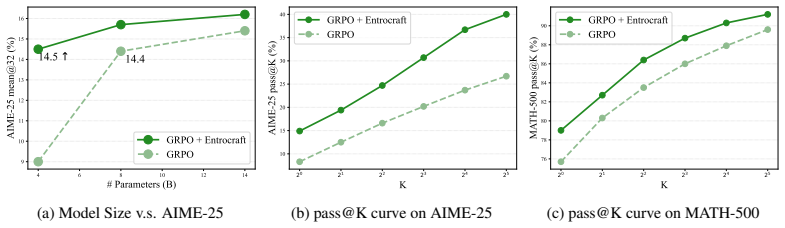
- Models continue to improve for up to four times as many training steps before plateauing.
- A 4-billion-parameter model trained with the method outperforms an 8-billion-parameter baseline.
- Pass@K scores increase by roughly 50 percent relative to standard RL training.
- Output diversity remains higher throughout the run, aiding generalization.
Where Pith is reading between the lines
- The same rejection-sampling logic could be tested in non-language RL settings where entropy collapse also limits long-horizon learning.
- If advantage biasing proves robust, future algorithms might treat entropy schedule design as a primary hyperparameter rather than a secondary regularizer.
- One could measure whether the method still works when advantage estimators are noisy or when the policy is updated in very large batches.
Load-bearing premise
That selectively keeping or discarding samples on the basis of their advantages can steer entropy to any desired schedule without distorting the policy updates or introducing new optimization biases.
What would settle it
Apply Entrocraft to a standard math-reasoning RL run with a chosen linear entropy schedule and observe whether the measured entropy at each step matches the target within a small tolerance; if the entropy deviates or accuracy plateaus at the usual step count, the central claim is falsified.
Figures





read the original abstract
Reinforcement learning (RL) has enabled complex reasoning abilities in large language models (LLMs). However, most RL algorithms suffer from performance saturation, preventing continued gains as RL training scales. This problem can be characterized by the collapse of entropy, a key diagnostic for exploration in RL. Existing attempts focus on preventing entropy collapse through regularization or clipping. However, their resulting entropy curves often exhibit instability in the long term, which hinders performance gains. In this paper, we introduce Entrocraft, a simple rejection-sampling approach that realizes user-customized entropy schedule by biasing the advantage distributions. Entrocraft requires no objective regularization and is advantage-estimator-agnostic. Theoretically, we relate per-step entropy change to the advantage distribution under minimal assumptions. This explains the behavior of existing RL and entropy-preserving methods. Entrocraft also enables a systematic study of entropy schedules, which reveals that linear annealing, which starts high and decays to a slightly lower target, performs best. Empirically, Entrocraft addresses performance saturation, significantly improving generalization, output diversity, and long-term training. It enables a 4B model to outperform an 8B baseline, sustains improvement for up to 4x longer before plateauing, and raises pass@K by 50% over the baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Entrocraft, a rejection-sampling approach that realizes user-customized entropy schedules in LLM RL by biasing advantage distributions. It claims to be advantage-estimator-agnostic and require no objective regularization, derives a per-step relation between entropy change and the advantage distribution under minimal assumptions, identifies linear annealing as the optimal schedule via systematic study, and reports empirical gains including 4x longer training before plateauing, 50% higher pass@K, improved generalization and diversity, and a 4B model outperforming an 8B baseline.
Significance. If the theoretical relation is sound and rejection sampling preserves unbiased policy gradients, the work could be significant for mitigating performance saturation in LLM RL by enabling precise, customizable entropy control without added regularization terms. The systematic empirical comparison of entropy schedules and the advantage-estimator-agnostic framing are strengths that could aid reproducibility and extension.
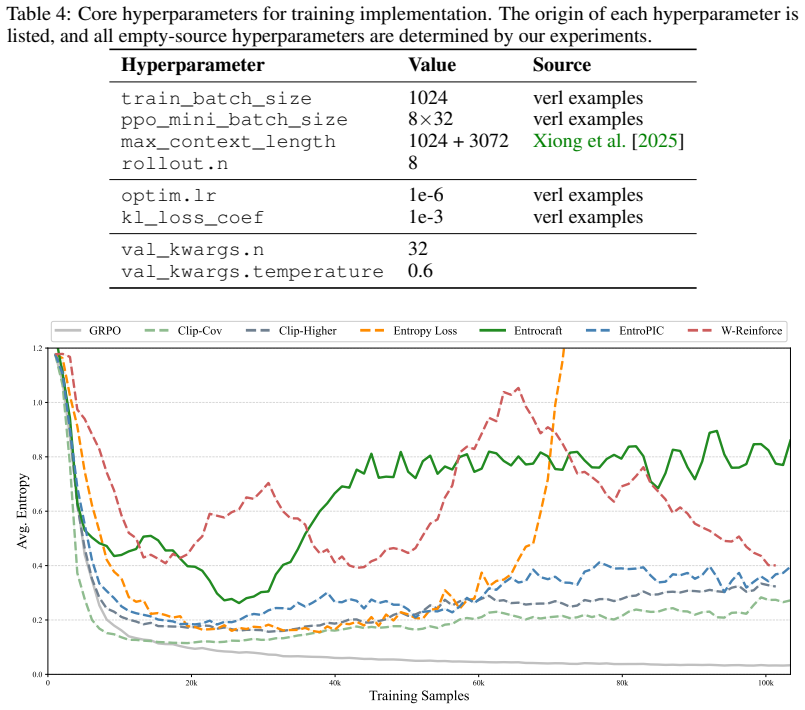
major comments (2)
- [Theoretical analysis and method description] The central claim that Entrocraft preserves valid RL policy gradient updates is load-bearing but unsupported: rejection sampling on advantages changes the effective trajectory distribution away from the current policy, yet no importance-weight correction for the acceptance probability is provided. This biases standard estimators (REINFORCE, PPO) and directly threatens the assertion that only entropy is controlled while the underlying objective remains unchanged.
- [Empirical evaluation and entropy schedule study] The identification of linear annealing as best-performing rests on an empirical study whose schedule parameters may be fitted post-hoc; without pre-specified schedules, ablations isolating the rejection mechanism, or controls for confounding factors such as effective batch size after rejection, the cross-schedule comparison and the reported 4x training extension / 50% pass@K lift cannot be taken as conclusive.
minor comments (2)
- [Abstract and introduction] The abstract and introduction would benefit from explicit statements of the minimal assumptions used in the entropy-change derivation and a clear definition of the acceptance probability in the rejection step.
- [Experiments] Reported gains lack error bars, number of runs, and precise baseline configurations; adding these would strengthen the empirical claims without altering the core contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and proposed revisions that we believe will strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: The central claim that Entrocraft preserves valid RL policy gradient updates is load-bearing but unsupported: rejection sampling on advantages changes the effective trajectory distribution away from the current policy, yet no importance-weight correction for the acceptance probability is provided. This biases standard estimators (REINFORCE, PPO) and directly threatens the assertion that only entropy is controlled while the underlying objective remains unchanged.
Authors: We appreciate the referee's identification of this critical point on gradient validity. The manuscript derives the per-step entropy-advantage relation under the assumption that rejection shapes the advantage distribution while preserving the underlying policy objective, and presents Entrocraft as estimator-agnostic. However, we acknowledge that the current description does not explicitly include an importance-weight correction for the altered trajectory distribution induced by rejection. In the revision, we will add this correction as a multiplicative factor on the advantages (computed from the acceptance probability), demonstrate that it restores unbiasedness for standard estimators, and update the theoretical section to show that the original objective is preserved up to the controlled entropy term. This addition maintains the advantage-estimator-agnostic property. revision: yes
-
Referee: The identification of linear annealing as best-performing rests on an empirical study whose schedule parameters may be fitted post-hoc; without pre-specified schedules, ablations isolating the rejection mechanism, or controls for confounding factors such as effective batch size after rejection, the cross-schedule comparison and the reported 4x training extension / 50% pass@K lift cannot be taken as conclusive.
Authors: We thank the referee for this observation on the empirical rigor. The schedules, including linear annealing, were selected according to the theoretical per-step entropy change relation derived in the paper, with the systematic study intended to validate the predictions. To address concerns about post-hoc fitting and confounding factors, we will revise the experimental section to explicitly document the pre-specification of all schedule parameters, add ablations that isolate the rejection-sampling component (e.g., comparing against direct advantage biasing without rejection), and include controls that maintain constant effective batch size by oversampling before rejection. These changes will provide stronger support for the reported gains in training length, generalization, and pass@K. revision: yes
Circularity Check
No circularity: theoretical relation and empirical schedule study are independent of inputs
full rationale
The paper derives a relation between per-step entropy change and advantage distribution under minimal assumptions, presented as explanatory for existing methods rather than tautological. The identification of linear annealing as optimal arises from a systematic empirical study of schedules enabled by the rejection-sampling approach, not from any fitted parameter being renamed as a prediction. No load-bearing step reduces by construction to self-definition, self-citation chains, or ansatz smuggling; the method is explicitly advantage-estimator-agnostic with no regularization, keeping the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- entropy target schedule =
linear decay to slightly lower target
axioms (1)
- domain assumption Per-step entropy change relates to the advantage distribution under minimal assumptions
Reference graph
Works this paper leans on
-
[1]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Michael Beukman, Khimya Khetarpal, Zeyu Zheng, Will Dabney, Jakob Foerster, Michael Dennis, and Clare Lyle. Preventing learning stagnation in ppo by scaling to 1 million parallel environments.arXiv preprint arXiv:2603.06009,
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models. arXiv preprint arXiv:2505.22617,
work page internal anchor Pith review arXiv
-
[6]
Raft: Reward ranked finetuning for generative foundation model alignment
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. Raft: Reward ranked finetuning for generative foundation model alignment. Transactions on Machine Learning Research, 2023,
work page 2023
-
[7]
Benchmarking music generation models and metrics via human preference studies
10 Florian Grötschla, Ahmet Solak, Luca A Lanzendörfer, and Roger Wattenhofer. Benchmarking music generation models and metrics via human preference studies. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE,
work page 2025
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Does RLHF Scale? Exploring the Impacts From Data, Model, and Method,
Zhenyu Hou, Pengfan Du, Yilin Niu, Zhengxiao Du, Aohan Zeng, Xiao Liu, Minlie Huang, Hongning Wang, Jie Tang, and Yuxiao Dong. Does rlhf scale? exploring the impacts from data, model, and method.arXiv preprint arXiv:2412.06000,
-
[10]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Reasoning with sampling: Your base model is smarter than you think.arXiv preprint arXiv:2510.14901,
Aayush Karan and Yilun Du. Reasoning with sampling: Your base model is smarter than you think.arXiv preprint arXiv:2510.14901,
-
[12]
Training Reasoning Models on Saturated Problems via Failure-Prefix Conditioning
Minwu Kim, Safal Shrestha, and Keith Ross. Training reasoning models on saturated problems via failure-prefix conditioning.arXiv preprint arXiv:2601.20829,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Pengyi Li, Elizaveta Goncharova, Andrey Kuznetsov, and Ivan Oseledets. Back to basics: Revisiting exploration in reinforcement learning for llm reasoning via generative probabilities.arXiv preprint arXiv:2602.05281,
-
[15]
URL https://zhuanlan.zhihu. com/p/28476703733. Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective. InSecond Conference on Language Modeling,
-
[16]
Asynchronous methods for deep reinforcement learning
V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. InInternational conference on machine learning, pages 1928–1937. PmLR,
work page 1928
-
[17]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
On entropy control in LLM-RL algorithms
Han Shen. On entropy control in llm-rl algorithms.arXiv preprint arXiv:2509.03493,
-
[20]
Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models
Haoxiang Sun, Yingqian Min, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, Zheng Liu, Zhongyuan Wang, and Ji-Rong Wen. Challenging the boundaries of reasoning: An olympiad-level math benchmark for large language models.arXiv preprint arXiv:2503.21380,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Shumin Wang, Yuexiang Xie, Wenhao Zhang, Yuchang Sun, Yanxi Chen, Yaliang Li, and Yanyong Zhang. On the entropy dynamics in reinforcement fine-tuning of large language models.arXiv preprint arXiv:2602.03392,
-
[22]
Ronald J Williams and Jing Peng
URL https: //lilianweng.github.io/posts/2024-11-28-reward-hacking/. Ronald J Williams and Jing Peng. Function optimization using connectionist reinforcement learning algorithms. Connection Science, 3(3):241–268,
work page 2024
-
[23]
A minimalist approach to llm reasoning: from rejection sampling to reinforce, 2025
Wei Xiong, Jiarui Yao, Yuhui Xu, Bo Pang, Lei Wang, Doyen Sahoo, Junnan Li, Nan Jiang, Tong Zhang, Caiming Xiong, et al. A minimalist approach to llm reasoning: from rejection sampling to reinforce.arXiv preprint arXiv:2504.11343,
-
[24]
Wujiang Xu, Wentian Zhao, Zhenting Wang, Yu-Jhe Li, Can Jin, Mingyu Jin, Kai Mei, Kun Wan, and Dimitris N Metaxas. Epo: Entropy-regularized policy optimization for llm agents reinforcement learning.arXiv preprint arXiv:2509.22576,
-
[25]
Kai Yang, Xin Xu, Yangkun Chen, Weijie Liu, Jiafei Lyu, Zichuan Lin, Deheng Ye, and Saiyong Yang. Entropic: Towards stable long-term training of llms via entropy stabilization with proportional-integral control.arXiv preprint arXiv:2511.15248,
-
[26]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
arXiv preprint arXiv:2512.01374 , year=
Chujie Zheng, Kai Dang, Bowen Yu, Mingze Li, Huiqiang Jiang, Junrong Lin, Yuqiong Liu, Hao Lin, Chencan Wu, Feng Hu, et al. Stabilizing reinforcement learning with llms: Formulation and practices.arXiv preprint arXiv:2512.01374, 2025a. Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al...
-
[28]
Defining the reward scores for LLMs’ trajectories is a critical challenge
13 A Discussion A.1 Related Works Reinforcement Learning with Verifiable RewardsReinforcement Learning [Kaelbling et al., 1996] has become the dominant approach in the post-training of LLMs, in which LLMs generate a set of rollout trajectories (exploration) and then enforce the rewarded trajectories while punishing the less-rewarded ones (exploitation). D...
work page 1996
-
[29]
14 Let p be the probability vector before the RL update and δp be the update
indicates that entropy loss only works well under traditional RL tasks where the discrete action space is small, and this effect is marginal for LLM RL. 14 Let p be the probability vector before the RL update and δp be the update. The entropy change can be approximated by Taylor expansion [Abramowitz and Stegun, 1948]: ∆H=H(p+δp)− H(p) = X i∈V ∂H ∂pi δpi ...
work page 1948
-
[30]
=−δp k logp k −log Y i∈V\{k} p − δpi δpk i +O(∥δp∥ 2 2). (9) Entropy decreases (∆H<0 ) when the term in parentheses is positive: logp k >log Q i∈V\{k} p − δpi δpk i . This condition holds with probability 1− Q i∈V\{k} p − δpi δpk i , which approaches 1 as probability mass concentrates on token k. Symmetrically, for tokens with negative advantage, e...
work page 1948
-
[31]
On top of GRPO, many entropy-preserving methods successfully alleviate the entropy-decreasing trend
Standard GRPO [Shao et al., 2024] exhibits entropy collapse. On top of GRPO, many entropy-preserving methods successfully alleviate the entropy-decreasing trend. However, they are not necessarily responsive enough to enable accurate entropy control and may cause the entropy curves to be unstable in the long term. In contrast, the proposed Entrocraft accur...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.