Recognition: 2 theorem links
· Lean TheoremCodeOCR: On the Effectiveness of Vision Language Models in Code Understanding
Pith reviewed 2026-05-16 08:28 UTC · model grok-4.3
The pith
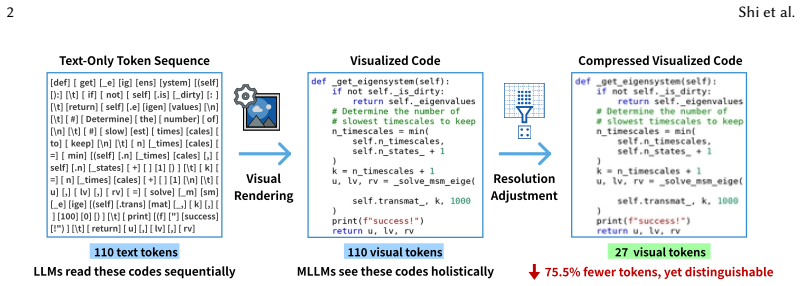
Vision language models understand source code rendered as images with up to 8x token reduction compared to text inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
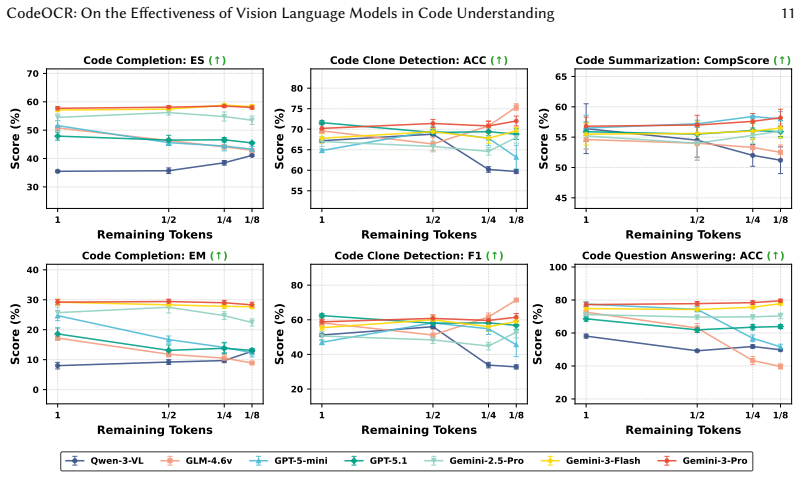
MLLMs can effectively understand code with substantial token reduction, achieving up to 8x compression; MLLMs can leverage visual cues such as syntax highlighting, improving code completion performance under 4x compression; and code-understanding tasks like clone detection exhibit exceptional resilience to visual compression, with some compression ratios even slightly outperforming raw text inputs.
What carries the argument
Rendering source code as images for MLLM input, with adjustable resolution to achieve token compression while keeping the code visually recognizable.
If this is right
- MLLMs achieve effective code understanding with up to 8x token reduction compared to text inputs.
- Syntax highlighting in rendered images improves code completion at 4x compression.
- Clone detection remains resilient to visual compression and can slightly exceed text performance at certain ratios.
- Image-modality representation offers a pathway to lower computational costs for code inference tasks.
Where Pith is reading between the lines
- Larger codebases could be handled in a single context window by visually compressing sections that text models would truncate.
- Training specialized MLLMs on code-image pairs might further close any remaining gaps with text models.
- IDE plugins could render live code views for lighter-weight analysis without full text tokenization.
Load-bearing premise
Rendering source code as images preserves enough semantic and structural information for MLLMs to perform code tasks at levels comparable to text inputs.
What would settle it
A controlled test showing MLLM accuracy on image-rendered code falling below text baselines on clone detection and completion at the 4x and 8x compression levels reported in the experiments.
Figures






read the original abstract
Large Language Models (LLMs) have achieved remarkable success in source code understanding, yet as software systems grow in scale, computational efficiency has become a critical bottleneck. Currently, these models rely on a text-based paradigm that treats source code as a linear sequence of tokens, which leads to a linear increase in context length and associated computational costs. The rapid advancement of Multimodal LLMs (MLLMs) introduces an opportunity to optimize efficiency by representing source code as rendered images. Unlike text, which is difficult to compress without losing semantic meaning, the image modality is inherently suitable for compression. By adjusting resolution, images can be scaled to a fraction of their original token cost while remaining recognizable to vision-capable models. To explore the feasibility of this approach, we conduct the first systematic study on the effectiveness of MLLMs for code understanding. Our experiments reveal that: (1) MLLMs can effectively understand code with substantial token reduction, achieving up to 8x compression; (2) MLLMs can effectively leverage visual cues such as syntax highlighting, improving code completion performance under 4x compression; and (3) Code-understanding tasks like clone detection exhibit exceptional resilience to visual compression, with some compression ratios even slightly outperforming raw text inputs. Our findings highlight both the potential and current limitations of MLLMs in code understanding, which points out a shift toward image-modality code representation as a pathway to more efficient inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CodeOCR, an empirical study exploring the use of Multimodal LLMs (MLLMs) for source code understanding by rendering code as images instead of text tokens. It reports that this approach enables up to 8x token compression while preserving effectiveness on tasks such as code completion and clone detection, with additional gains from visual cues like syntax highlighting and notable resilience in clone detection where some compressed ratios slightly exceed text baselines.
Significance. If the reported compression ratios and task performances hold under standard controls, the work demonstrates a viable shift from linear text tokenization to compressible image representations for code, which could substantially lower inference costs for large-scale code models without requiring architectural changes to the underlying MLLMs. This is particularly relevant given the scaling challenges in code LLMs.
major comments (2)
- [§4] §4 (Experimental Setup): The abstract reports up to 8x compression and resilience in clone detection, but without explicit details on the image rendering parameters (resolution, font size, highlighting method), baseline tokenizers, or exact dataset sizes and splits, it is impossible to assess whether the gains are robust to standard controls such as different MLLM backbones or code formatting variations.
- [Table 2] Table 2 (Clone Detection Results): The claim that some compression ratios 'slightly outperform' raw text inputs requires error bars, statistical tests, and ablation on whether this holds across multiple random seeds or code domains; otherwise the resilience conclusion rests on potentially noisy point estimates.
minor comments (2)
- [Abstract] The abstract uses 'CodeOCR' as the title but does not define the acronym or method name in the body; clarify whether this refers to a specific rendering pipeline or is simply the study name.
- [Figure 1] Figure 1 (Example Renderings): Ensure that the visual examples include both highlighted and plain-text versions at the claimed compression ratios so readers can directly inspect information loss.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We address each major comment below and plan to incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup): The abstract reports up to 8x compression and resilience in clone detection, but without explicit details on the image rendering parameters (resolution, font size, highlighting method), baseline tokenizers, or exact dataset sizes and splits, it is impossible to assess whether the gains are robust to standard controls such as different MLLM backbones or code formatting variations.
Authors: We agree that additional details are essential for reproducibility and robustness assessment. In the revised manuscript, we will expand Section 4 to explicitly specify the image rendering parameters, including resolution (e.g., 512x512 pixels), font size (12pt), and highlighting method (using Pygments with the 'monokai' style). We will also detail the baseline tokenizers (GPT-2 tokenizer for text inputs) and provide exact dataset sizes and splits (e.g., 5,000 samples from the CodeXGLUE clone detection dataset with an 80/10/10 train/validation/test split). Furthermore, we will include results from additional MLLM backbones such as LLaVA-1.5 and Qwen-VL to demonstrate robustness across models. revision: yes
-
Referee: [Table 2] Table 2 (Clone Detection Results): The claim that some compression ratios 'slightly outperform' raw text inputs requires error bars, statistical tests, and ablation on whether this holds across multiple random seeds or code domains; otherwise the resilience conclusion rests on potentially noisy point estimates.
Authors: We acknowledge that the current presentation relies on point estimates and would benefit from statistical validation. In the revision, we will add error bars representing standard deviation over 5 random seeds, conduct paired t-tests to assess significance of the slight outperformance, and include ablations across multiple code domains (Python, Java, C++). We believe these additions will substantiate the resilience claim without altering the core findings. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a purely empirical study reporting experimental results on MLLM performance for code tasks under image-based rendering and compression. No derivations, equations, fitted parameters, or self-citations are used to derive claims; performance metrics (e.g., 8x compression, clone detection resilience) are direct experimental measurements. The central claims rest on observed outcomes across tasks rather than any self-referential loop or imported uniqueness theorem. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (Jcost uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MLLMs can effectively understand code with substantial token reduction, achieving up to 8x compression; clone detection exhibits exceptional resilience to visual compression
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
visual enhancements (syntax highlighting, bold rendering) ... at 1x-4x compression
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
ClassEval-Pro: A Cross-Domain Benchmark for Class-Level Code Generation
ClassEval-Pro benchmark shows frontier LLMs achieve at most 45.6% Pass@1 on class-level code tasks, with logic errors (56%) and dependency errors (38%) as dominant failure modes.
-
ShredBench: Evaluating the Semantic Reasoning Capabilities of Multimodal LLMs in Document Reconstruction
ShredBench shows state-of-the-art MLLMs perform well on intact documents but suffer sharp drops in restoration accuracy as fragmentation increases to 8-16 pieces, indicating insufficient cross-modal semantic reasoning...
-
Zero-Shot Vulnerability Detection in Low-Resource Smart Contracts Through Solidity-Only Training
Sol2Vy transfers vulnerability detection from Solidity to Vyper in zero-shot fashion, outperforming prior methods on reentrancy, weak randomness, and unchecked transfers.
Reference graph
Works this paper leans on
-
[1]
Megha Agarwal, Asfandyar Qureshi, Nikhil Sardana, Linden Li, Julian Quevedo, and Daya Khudia. 2023. LLM Inference Performance Engineering: Best Practices. Databricks Blog. https://www.databricks.com/blog/llm-inference- performance-engineering-best-practices Accessed: 2025-01-24
work page 2023
- [2]
- [3]
-
[4]
Wasi Uddin Ahmad, Md Golam Rahman Tushar, Saikat Chakraborty, and Kai-Wei Chang. 2023. AVATAR: A Parallel Corpus for Java-Python Program Translation. InFindings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics, Toronto, Canada, 2268–2281
work page 2023
-
[5]
Alireza Alaei, Vinh Bui, David Doermann, and Umapada Pal. 2023. Document Image Quality Assessment: A Survey. ACM Comput. Surv.56, 2, Article 29 (Sept. 2023), 36 pages. doi:10.1145/3606692
-
[6]
Ajmain Inqiad Alam, Palash Ranjan Roy, Farouq Al-omari, Chanchal Kumar Roy, Banani Roy, and Kevin Schneider
-
[7]
InProceedings of the 39th International Conference on Software Maintenance and Evolution (ICSME)
GPTCloneBench: A comprehensive benchmark of semantic clones and cross-language clones using GPT-3 model and SemanticCloneBench. InProceedings of the 39th International Conference on Software Maintenance and Evolution (ICSME). IEEE, Bogota, Colombia, 1–12
-
[8]
Anonymous. 2025. CodeOCR: Replication Package. https://anonymous.4open.science/r/CodeOCR-FBBA/. Source code, datasets, and reproduction scripts
work page 2025
-
[9]
Gilles Baechler, Srinivas Sunkara, Maria Wang, Fedir Zubach, Hassan Mansoor, Vincent Etter, Victor Cărbune, Jason Lin, Jindong Chen, and Abhanshu Sharma. 2024. ScreenAI: A Vision-Language Model for UI and Visually-Situated Language Understanding. arXiv:2402.04615 [cs.CV] https://arxiv.org/abs/2402.04615
- [10]
-
[11]
Shuai Bai, Jinze Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou
-
[12]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. arXiv:2308.12966 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, et al . 2025. Qwen3-VL Technical Report. arXiv:2511.21631 [cs.CV] https: //arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Lukas Blecher, Guillem Cucurull, Thomas Scialom, and Robert Stojnic. 2023. Nougat: Neural Optical Understanding for Academic Documents. arXiv:2308.13418 [cs.CL]
work page internal anchor Pith review arXiv 2023
-
[15]
Egor Bogomolov, Aleksandra Eliseeva, Timur Galimzyanov, Evgeniy Glukhov, Anton Shapkin, Maria Tigina, Yaroslav Golubev, Alexander Kovrigin, Arie van Deursen, Maliheh Izadi, and Timofey Bryksin. 2024. Long Code Arena: A Set of Benchmarks for Long-Context Code Models. arXiv:2406.11612 [cs] doi:10.48550/arXiv.2406.11612
-
[16]
Georg Brandl et al. 2006. Pygments: Python Syntax Highlighter. https://pygments.org/. Accessed: 2025-01-01
work page 2006
-
[17]
Raymond P.L. Buse and Westley R. Weimer. 2010. Learning a Metric for Code Readability.IEEE Transactions on Software Engineering36, 4 (2010), 546–558
work page 2010
-
[18]
Paterson, Carsten Schulte, Bonita Sharif, and Sascha Siebert
Teresa Busjahn, Roman Bednarik, Andrew Begel, Martha Crosby, James H. Paterson, Carsten Schulte, Bonita Sharif, and Sascha Siebert. 2015. Eye Movements in Code Reading: Relaxing the Linear Order. InProceedings of the 23rd IEEE International Conference on Program Comprehension (ICPC). IEEE, 255–265
work page 2015
-
[19]
Dongping Chen, Yue Huang, Siyuan Wu, Jingyu Tang, Liuyi Chen, Yilin Bai, Zhigang He, Chenlong Wang, Huichi Zhou, Yiqiang Li, Tianshuo Zhou, Yue Yu, Chujie Gao, Qihui Zhang, Yi Gui, Zhen Li, Yao Wan, Pan Zhou, Jianfeng Gao, and Lichao Sun. 2025. GUI-World: A Video Benchmark and Dataset for Multimodal GUI-oriented Understanding. arXiv:2406.10819 [cs.CV] htt...
-
[20]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al . 2021. Evaluating Large Language Models Trained on Code. arXiv:2107.03374 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [21]
-
[22]
Wei Chen, Liangmin Wu, Yunhai Hu, Zhiyuan Li, Zhiyuan Cheng, Yicheng Qian, Lingyue Zhu, Zhipeng Hu, Luoyi Liang, Qiang Tang, Zhen Liu, and Han Yang. 2025. AutoNeural: Co-Designing Vision-Language Models for NPU Inference. arXiv:2512.02924 [cs.CL] https://arxiv.org/abs/2512.02924
-
[23]
Xiaoyue Chen, Yuling Shi, Kaiyuan Li, Huandong Wang, Yong Li, Xiaodong Gu, Xinlei Chen, and Mingbao Lin. 2025. Progressive Supernet Training for Efficient Visual Autoregressive Modeling. arXiv:2511.16546 [cs.CV] , Vol. 1, No. 1, Article . Publication date: April 2026. CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding 21
-
[24]
Zhi Chen and Lingxiao Jiang. 2025. Evaluating software development agents: Patch patterns, code quality, and issue complexity in real-world github scenarios. In2025 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, Montreal, Canada, 657–668
work page 2025
-
[25]
Zhi Chen, Wei Ma, and Lingxiao Jiang. 2025. Unveiling Pitfalls: Understanding Why AI-driven Code Agents Fail at GitHub Issue Resolution. arXiv:2503.12374 [cs.SE]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. 2024. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks. arXiv:2312.14238 [cs.CV] https://arxiv.org/abs/2312.14238
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Alex Clark and Contributors. 2010. Pillow: The Friendly PIL Fork. https://python-pillow.org/. Accessed: 2025-01-01
work page 2010
-
[28]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, et al. 2025. Gemini 2.5: Pushing the Frontier with Ad- vanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities. arXiv:2507.06261 [cs.CL] https://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
DeepSeek-AI. 2024. DeepSeek-V3 Technical Report. arXiv:2412.19437 [cs.CL] https://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Angela Fan, Beliz Gokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M. Zhang. 2023. Large Language Models for Software Engineering: Survey and Open Problems. InProceedings of the 45th International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE). IEEE, Melbourne, Australia, 31–53
work page 2023
- [31]
- [32]
-
[33]
Google Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al . 2023. Gemini: A Family of Highly Capable Multimodal Models. arXiv:2312.11805 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
GitHub. 2025. GitHub REST API Documentation. https://docs.github.com/en/rest. Accessed: January 2025
work page 2025
-
[35]
Google. 2025. Gemini Developer API Pricing. https://ai.google.dev/gemini-api/docs/pricing. Accessed: January 2025
work page 2025
-
[36]
Google DeepMind. 2025. Gemini-3-Flash Model Card. https://storage.googleapis.com/deepmind-media/Model- Cards/Gemini-3-Flash-Model-Card.pdf. Official model specification and capabilities document
work page 2025
-
[37]
Google DeepMind. 2025. Gemini-3-Pro Model Card. https://storage.googleapis.com/deepmind-media/Model-Cards/ Gemini-3-Pro-Model-Card.pdf. November 2025. Documents Gemini 3 Pro’s training on document understanding and OCR tasks
work page 2025
-
[38]
Alex Gu, Baptiste Rozière, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, and Sida Wang. 2024. CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235). PMLR, Vienna, Austria, 16568–16621
work page 2024
- [39]
-
[40]
Daya Guo, Canwen Xu, Nan Duan, Jian Yin, and Julian McAuley. 2023. LongCoder: A Long-Range Pre-trained Language Model for Code Completion. InProceedings of the 40th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 202). PMLR, Honolulu, Hawaii, USA, 11969–11984
work page 2023
-
[41]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming – The Rise of Code Intelligence. arXiv:2401.14196 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [42]
-
[43]
Chao Hu, Wenhao Zeng, Yuling Shi, Beijun Shen, and Xiaodong Gu. 2026. In Line with Context: Repository-Level Code Generation via Context Inlining. arXiv:2601.00376 [cs.SE]
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [44]
-
[45]
Minghao Hu, Qiang Zeng, and Lannan Luo. 2026. Zero-Shot Vulnerability Detection in Low-Resource Smart Contracts Through Solidity-Only Training. arXiv:2603.21058 [cs.CR] https://arxiv.org/abs/2603.21058
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2.5-Coder Technical Report. arXiv:2409.12186 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Max Jaderberg, Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. 2014. Reading Text in the Wild with Convolutional Neural Networks. arXiv:1412.1842 [cs.CV] https://arxiv.org/abs/1412.1842
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[48]
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2023. LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models. InProceedings of the 2023 Conference on Empirical Methods in , Vol. 1, No. 1, Article . Publication date: April 2026. 22 Shi et al. Natural Language Processing
work page 2023
-
[49]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A Survey on Large Language Models for Code Generation. arXiv:2406.00515 [cs.SE]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Anoop Raveendra Katti, Christian Reisswig, Cordula Guder, Sebastian Brarda, Steffen Bickel, Johannes Höhne, and Jean Baptiste Faddoul. 2018. Chargrid: Towards Understanding 2D Documents. arXiv:1809.08799 [cs.CL] https://arxiv.org/abs/1809.08799
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[51]
Saiful Bari, Xuan Long Do, Weishi Wang, Md Rizwan Parvez, and Shafiq Joty
Mohammad Abdullah Matin Khan, M. Saiful Bari, Xuan Long Do, Weishi Wang, Md Rizwan Parvez, and Shafiq Joty. 2024. XCodeEval: An Execution-based Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long...
work page 2024
- [52]
-
[53]
Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, and Kristina Toutanova. 2023. Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding. arXiv:2210.03347 [cs.CL] https://arxiv.org/abs/2210.03347
-
[54]
Han Li, Yuling Shi, Shaoxin Lin, Xiaodong Gu, Heng Lian, Xin Wang, Yantao Jia, Tao Huang, and Qianxiang Wang
-
[55]
Swe-debate: Competitive multi-agent debate for software issue resolution. arXiv:2507.23348 [cs.SE]
-
[56]
Minghao Li, Tengchao Lv, Jingye Chen, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, and Furu Wei
-
[57]
TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models, September 2022
TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models. arXiv:2109.10282 [cs.CL] https://arxiv.org/abs/2109.10282
-
[58]
Yanhong Li, Zixuan Lan, and Jiawei Zhou. 2025. Text or Pixels? Evaluating Efficiency and Understanding of LLMs with Visual Text Inputs. InFindings of the Association for Computational Linguistics: EMNLP 2025. 10564–10578
work page 2025
- [59]
-
[60]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruction Tuning. InAdvances in Neural Information Processing Systems, Vol. 36. Curran Associates, Inc., 34892–34916
work page 2023
- [61]
-
[62]
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al . 2024. StarCoder 2 and The Stack v2: The Next Generation. arXiv:2402.19173 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
Maxfield, John Daggett, and Tab Atkins Jr
Myles C. Maxfield, John Daggett, and Tab Atkins Jr. 2024.CSS Fonts Module Level 4. W3C Working Draft. World Wide Web Consortium (W3C). https://www.w3.org/TR/css-fonts-4/#font-synthesis-style-prop
work page 2024
-
[64]
Microsoft Corporation. 2024. Visual Studio Code Documentation: Color Themes. https://code.visualstudio.com/docs/ getstarted/themes. Accessed: 2025-01-01
work page 2024
- [65]
-
[66]
OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[67]
OpenAI. 2025. GPT-5-mini Model Documentation. https://platform.openai.com/docs/models/gpt-5-mini. Accessed via OpenAI API
work page 2025
-
[68]
OpenAI. 2025. GPT-5.1 Model Documentation. https://platform.openai.com/docs/models/gpt-5.1. Accessed via OpenAI API
work page 2025
-
[69]
OpenAI. 2025. OpenAI API Pricing. https://openai.com/api/pricing/. Accessed: January 2025. Image tokens are priced at standard text token rates for vision-capable models
work page 2025
-
[70]
OpenRouter. 2025. OpenRouter: A Unified API for LLMs. https://openrouter.ai/. Accessed: January 2026. Provides unified API access to multiple LLM providers
work page 2025
- [71]
-
[72]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. InAdvances in Neural Information Processing Systems, Vol. 32. 8024–8035
work page 2019
-
[73]
Weihan Peng, Yuling Shi, Yuhang Wang, Xinyun Zhang, Beijun Shen, and Xiaodong Gu. 2025. SWE-QA: Can Language Models Answer Repository-level Code Questions? arXiv:2509.14635 [cs.SE] , Vol. 1, No. 1, Article . Publication date: April 2026. CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding 23
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [74]
- [75]
-
[76]
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. CodeBLEU: a Method for Automatic Evaluation of Code Synthesis. arXiv:2009.10297 [cs.SE]
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[77]
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. 2023. Code Llama: Open Foundation Models for Code. arXiv:2308.12950 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [78]
- [79]
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.