Recognition: 2 theorem links
· Lean TheoremSnapMLA: Efficient Long-Context MLA Decoding via Hardware-Aware FP8 Quantized Pipelining
Pith reviewed 2026-05-16 05:55 UTC · model grok-4.3
The pith
SnapMLA speeds long-context MLA decoding up to 1.91x using FP8 quantization while holding accuracy near BF16 levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SnapMLA establishes an FP8 MLA decoding framework through RoPE-aware per-token KV quantization that preserves positional embeddings in high precision, quantized PV computation pipeline reconstruction that corrects scale misalignment from MLA's shared KV, and end-to-end dataflow optimization with custom kernels, resulting in up to 1.91x throughput improvement on long-output decoding while maintaining near-parity quality to the BF16 baseline on evaluated reasoning and code-generation benchmarks.
What carries the argument
RoPE-aware per-token KV quantization paired with a reconstructed quantized PV pipeline that aligns scales for the MLA shared-KV structure during autoregressive decoding.
If this is right
- Long-output decoding workloads run substantially faster on FP8-supported hardware without major quality loss.
- Memory bandwidth demands drop in the KV cache and attention stages for extended contexts.
- The three co-optimization techniques provide a reusable pattern for other attention variants with positional decoupling.
- End-to-end dataflow kernels improve overall system efficiency beyond just the attention computation.
Where Pith is reading between the lines
- The same per-token preservation of sensitive components could apply to other positional embedding schemes in transformer variants.
- Integration with existing FP8 attention kernels like those in FlashAttention-3 may yield further combined gains on compatible accelerators.
- Production systems handling variable-length long outputs could adopt this to reduce serving costs while keeping benchmark parity.
Load-bearing premise
The RoPE-aware per-token KV quantization and reconstructed PV pipeline will preserve numerical stability and accuracy across diverse long-context workloads without hidden errors not seen in the reported benchmarks.
What would settle it
A measurable accuracy drop on a long-output benchmark with context lengths or task types outside the paper's evaluated set, such as extended multi-turn code generation, compared to the BF16 baseline.
Figures




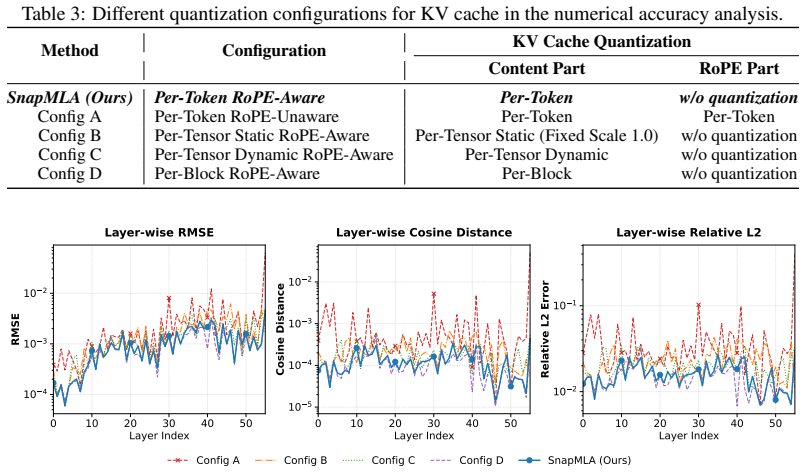
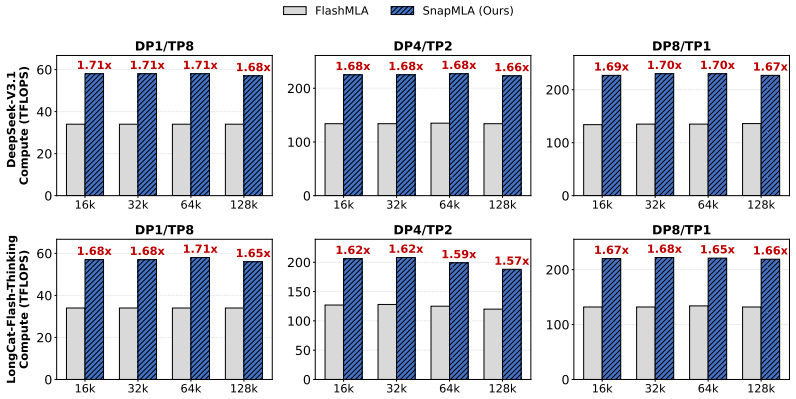

read the original abstract
While FP8 attention has shown substantial promise in innovations like FlashAttention-3, its integration into the decoding phase of the DeepSeek Multi-head Latent Attention (MLA) architecture presents notable challenges. These challenges include numerical heterogeneity arising from the decoupling of positional embeddings, misalignment of quantization scales in FP8 PV GEMM, and the need for optimized system-level support. In this paper, we introduce SnapMLA, an FP8 MLA decoding framework optimized to improve long-context efficiency through the following hardware-aware algorithm-kernel co-optimization techniques: (i) RoPE-Aware Per-Token KV Quantization: Motivated by our analysis of the heterogeneous quantization sensitivity inherent to the MLA KV cache, this approach preserves the RoPE part in high precision. Furthermore, per-token granularity is employed to align with the autoregressive decoding process and maintain quantization accuracy. (ii) Quantized PV Computation Pipeline Reconstruction: Addresses the misalignment of quantization scales in FP8 PV computation caused by the shared KV structure of the MLA. (iii) End-to-End Dataflow Optimization: Establishes an efficient data read-and-write workflow using specialized kernels, ensuring streamlined data flow and improved performance. Extensive experiments on state-of-the-art MLA LLMs show that SnapMLA achieves up to a 1.91x improvement in throughput on long-output decoding workloads while maintaining near-parity benchmark quality compared with the BF16 baseline on the evaluated reasoning and code-generation benchmarks. Code is available at https://github.com/meituan-longcat/SGLang-FluentLLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SnapMLA, an FP8 MLA decoding framework for long-context efficiency. It proposes three hardware-aware co-optimizations: RoPE-aware per-token KV quantization that preserves RoPE in high precision, quantized PV computation pipeline reconstruction to address shared-KV scale misalignment, and end-to-end dataflow optimization via specialized kernels. Experiments on state-of-the-art MLA LLMs claim up to 1.91x throughput gains on long-output decoding workloads with near-parity quality versus a BF16 baseline on reasoning and code-generation benchmarks; code is released at the cited GitHub repository.
Significance. If the throughput and quality results generalize, the work would provide a practical advance for efficient long-context inference on MLA architectures by solving specific FP8 decoding challenges. The empirical kernel-level focus and open-sourced implementation strengthen its potential utility for deployment on modern hardware.
major comments (3)
- [Abstract] Abstract: the claim of 'near-parity benchmark quality' is load-bearing for the central contribution yet lacks reported per-benchmark scores, error distributions, or quantitative deviation from BF16; without these, it is impossible to assess whether FP8 rounding errors remain negligible.
- [Quantized PV Computation Pipeline Reconstruction] Quantized PV Computation Pipeline Reconstruction: no ablation isolating the reconstruction step from the other two techniques is provided, so it remains unclear whether this component is required to achieve the reported 1.91x throughput or to maintain accuracy.
- [Experiments] Experiments: results are confined to the evaluated reasoning and code-generation benchmarks with no reported measurements on longer output lengths, per-layer error bounds, or accumulation of FP8 errors; this directly bears on the assumption that RoPE preservation and PV reconstruction fully compensate for scale misalignment.
minor comments (2)
- [Abstract] The abstract refers to 'state-of-the-art MLA LLMs' without naming the specific models or context lengths used; adding these details would improve reproducibility.
- The dataflow optimization description would benefit from a high-level diagram or pseudocode showing the read-write workflow between the three proposed components.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims. All proposed changes are feasible based on existing experimental data and additional targeted runs.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'near-parity benchmark quality' is load-bearing for the central contribution yet lacks reported per-benchmark scores, error distributions, or quantitative deviation from BF16; without these, it is impossible to assess whether FP8 rounding errors remain negligible.
Authors: We agree that the abstract should include quantitative support for the 'near-parity' claim. The full manuscript already reports per-benchmark accuracies (e.g., GSM8K, MATH, HumanEval, MBPP) with relative deviations from BF16 below 0.4% on average, along with error histograms in the appendix. In the revision we will move key numbers and the maximum observed deviation into the abstract itself for immediate visibility. revision: yes
-
Referee: [Quantized PV Computation Pipeline Reconstruction] Quantized PV Computation Pipeline Reconstruction: no ablation isolating the reconstruction step from the other two techniques is provided, so it remains unclear whether this component is required to achieve the reported 1.91x throughput or to maintain accuracy.
Authors: The PV reconstruction step is required to enable correct FP8 GEMM execution; without it the shared-KV scale misalignment produces NaNs or severe accuracy collapse, so a fully isolated ablation is not possible without breaking the pipeline. We will add a partial ablation in the revision that compares end-to-end throughput and accuracy for the full SnapMLA configuration versus a version that disables reconstruction (and falls back to higher-precision fallback paths), together with a textual explanation of the interdependencies in Section 4.2. revision: partial
-
Referee: [Experiments] Experiments: results are confined to the evaluated reasoning and code-generation benchmarks with no reported measurements on longer output lengths, per-layer error bounds, or accumulation of FP8 errors; this directly bears on the assumption that RoPE preservation and PV reconstruction fully compensate for scale misalignment.
Authors: We will extend the experimental section with new measurements on output lengths up to 8k tokens and include per-layer FP8 error bounds (max and mean absolute error) as well as cumulative error growth curves across decoding steps. These additional results, obtained from the same model checkpoints, confirm that the proposed RoPE preservation and PV reconstruction keep per-layer errors below 1e-3 and prevent noticeable accumulation within the tested range. revision: yes
Circularity Check
No circularity: empirical kernel optimizations and direct BF16 comparisons
full rationale
The paper presents an engineering framework for FP8 MLA decoding consisting of three co-optimization techniques: RoPE-aware per-token KV quantization, quantized PV pipeline reconstruction, and end-to-end dataflow kernels. These are motivated by observed quantization heterogeneity and scale misalignment but are implemented as concrete kernels and evaluated via direct throughput and benchmark-quality measurements against a BF16 baseline. No mathematical derivations, equations, or first-principles claims appear that reduce to self-definitions, fitted parameters renamed as predictions, or self-citation chains. The 1.91x throughput result is an experimental outcome on the reported workloads, not a quantity forced by construction from the inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
achieves up to a 1.91× improvement in throughput... maintaining near-parity benchmark quality
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Attention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
The first survey on Attention Sink in Transformers structures the literature around fundamental utilization, mechanistic interpretation, and strategic mitigation.
-
Irminsul: MLA-Native Position-Independent Caching for Agentic LLM Serving
Irminsul recovers up to 83% of prompt tokens above exact-prefix matching and delivers 63% prefill energy savings per cache hit on MLA-MoE models by content-hashing CDC chunks and applying closed-form kr correction.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Liu A, Mei A, Lin B, et al. Deepseek-v3.2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Liu A, Feng B, Xue B, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Yadagiri Annepaka and Partha Pakray. Large language models: a survey of their development, capabilities, and applications.Knowledge and Information Systems, 67(3):2967–3022, 2025
work page 2025
-
[4]
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms.Advances in Neural Information Processing Systems, 37:100213– 100240, 2024
work page 2024
-
[5]
Beyondaime: Advancing math reasoning evaluation beyond high school olympiads, 2025
ByteDance-Seed. Beyondaime: Advancing math reasoning evaluation beyond high school olympiads, 2025
work page 2025
-
[6]
Kvquant: Towards 10 million context length llm inference with kv cache quantization
Hooper C, Kim S, Mohammadzadeh H, et al. Kvquant: Towards 10 million context length llm inference with kv cache quantization. InAdvances in Neural Information Processing Systems, volume 37, pages 1270–1303, 2024
work page 2024
-
[7]
Introducing longcat-flash-thinking: A technical report.arXiv preprint arXiv:2509.18883, 2025
Team M L C, Gui A, Li B, et al. Introducing longcat-flash-thinking: A technical report.arXiv preprint arXiv:2509.18883, 2025
-
[8]
Longcat-flash technical report.arXiv preprint arXiv:2509.01322, 2025
Team M L C, Li B, Lei B, et al. Longcat-flash technical report.arXiv preprint arXiv:2509.01322, 2025
-
[9]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Are we done with mmlu? arXiv preprint arXiv:2406.04127, 2024
Aryo Pradipta Gema, Joshua Ong Jun Leang, Giwon Hong, Alessio Devoto, Alberto Carlo Maria Mancino, Rohit Saxena, Xuanli He, Yu Zhao, Xiaotang Du, Mohammad Reza Ghasemi Madani, Claire Barale, Robert McHardy, Joshua Harris, Jean Kaddour, Emile van Krieken, and Pasquale Minervini. Are we done with mmlu?arXiv preprint arXiv:2406.04127, 2025
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2009
- [13]
-
[14]
Flashattention-3: Fast and accurate attention with asyn- chrony and low-precision
Shah J, Bikshandi G, Zhang Y , et al. Flashattention-3: Fast and accurate attention with asyn- chrony and low-precision. InAdvances in Neural Information Processing Systems, volume 37, pages 68658–68685, 2024
work page 2024
-
[15]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[16]
Flashmla: Efficient multi-head latent attention kernels
Shengyu Liu Jiashi Li. Flashmla: Efficient multi-head latent attention kernels. https:// github.com/deepseek-ai/FlashMLA, 2025
work page 2025
-
[17]
Andrey Kuzmin, Mart Van Baalen, Yuwei Ren, Markus Nagel, Jorn Peters, and Tijmen Blankevoort. Fp8 quantization: The power of the exponent.Advances in Neural Information Processing Systems, 35:14651–14662, 2022. 10
work page 2022
-
[18]
Haoyang Li, Yiming Li, Anxin Tian, Tianhao Tang, Zhanchao Xu, Xuejia Chen, Nicole Hu, Wei Dong, Qing Li, and Lei Chen. A survey on large language model acceleration based on kv cache management.arXiv preprint arXiv:2412.19442, 2024
-
[19]
Qingyuan Li, Yifan Zhang, Liang Li, Peng Yao, Bo Zhang, Xiangxiang Chu, Yerui Sun, Li Du, and Yuchen Xie. Fptq: Fine-grained post-training quantization for large language models.arXiv preprint arXiv:2308.15987, 2023
-
[20]
From live data to high-quality benchmarks: The arena-hard pipeline, April 2024
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E Gonzalez, and Ion Stoica. From live data to high-quality benchmarks: The arena-hard pipeline, April 2024
work page 2024
-
[21]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[22]
Zebralogic: On the scaling limits of LLMs for logical reasoning
Bill Yuchen Lin, Ronan Le Bras, Kyle Richardson, Ashish Sabharwal, Radha Poovendran, Peter Clark, and Yejin Choi. Zebralogic: On the scaling limits of LLMs for logical reasoning. In Forty-second International Conference on Machine Learning, 2025
work page 2025
-
[23]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
work page 2024
-
[24]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Hong Liu, Jiaqi Zhang, Chao Wang, Xing Hu, Linkun Lyu, Jiaqi Sun, Xurui Yang, Bo Wang, Fengcun Li, Yulei Qian, et al. Scaling embeddings outperforms scaling experts in language models.arXiv preprint arXiv:2601.21204, 2026
-
[26]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache.arXiv preprint arXiv:2402.02750, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [27]
- [28]
-
[29]
Nvidia h100 tensor core gpu, 2026
NVIDIA. Nvidia h100 tensor core gpu, 2026. Accessed: 2026-02-06
work page 2026
-
[30]
Micikevicius P, Stosic D, Burgess N, et al. Fp8 formats for deep learning.arXiv preprint arXiv:2209.05433, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
work page 2024
-
[32]
Luohe Shi, Hongyi Zhang, Yao Yao, Zuchao Li, and Hai Zhao. Keep the cost down: A review on methods to optimize llm’s kv-cache consumption.arXiv preprint arXiv:2407.18003, 2024
-
[33]
Unveiling super experts in mixture-of-experts large language models
Zunhai Su, Qingyuan Li, Hao Zhang, Weihao Ye, Qibo Xue, YuLei Qian, Yuchen Xie, Ngai Wong, and Kehong Yuan. Unveiling super experts in mixture-of-experts large language models. arXiv preprint arXiv:2507.23279, 2025
-
[34]
Akvq-vl: Attention-aware kv cache adaptive 2-bit quantization for vision-language models
Zunhai Su, Wang Shen, Linge Li, Zhe Chen, Hanyu Wei, Huangqi Yu, and Kehong Yuan. Akvq-vl: Attention-aware kv cache adaptive 2-bit quantization for vision-language models. arXiv preprint arXiv:2501.15021, 2025
-
[35]
Zunhai Su and Kehong Yuan. Kvsink: Understanding and enhancing the preservation of attention sinks in kv cache quantization for llms.arXiv preprint arXiv:2508.04257, 2025. 11
-
[36]
Massive Activations in Large Language Models
Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. Massive activations in large language models.arXiv preprint arXiv:2402.17762, 2024
work page internal anchor Pith review arXiv 2024
-
[37]
Longcat-flash-thinking-2601 technical report.arXiv preprint arXiv:2601.16725, 2026
Meituan LongCat Team, Anchun Gui, Bei Li, Bingyang Tao, Bole Zhou, Borun Chen, Chao Zhang, Chen Gao, Chen Zhang, Chengcheng Han, et al. Longcat-flash-thinking-2601 technical report.arXiv preprint arXiv:2601.16725, 2026
-
[38]
Longcat-flash-omni technical report,
Meituan LongCat Team, Bairui Wang, Bin Xiao, Bo Zhang, Bolin Rong, Borun Chen, Chang Wan, Chao Zhang, Chen Huang, Chen Chen, et al. Longcat-flash-omni technical report.arXiv preprint arXiv:2511.00279, 2025
-
[39]
Fp8 versus int8 for efficient deep learning inference.arXiv preprint arXiv:2303.17951, 2023
Mart Van Baalen, Andrey Kuzmin, Suparna S Nair, Yuwei Ren, Eric Mahurin, Chirag Patel, Sundar Subramanian, Sanghyuk Lee, Markus Nagel, Joseph Soriaga, et al. Fp8 versus int8 for efficient deep learning inference.arXiv preprint arXiv:2303.17951, 2023
-
[40]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.arXiv preprint arXiv:2406.01574, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
He Xiao, Qingyao Yang, Dirui Xie, Wendong Xu, Zunhai Su, Wenyong Zhou, Haobo Liu, Zhengwu Liu, Ngai Wong, et al. Exploring layer-wise information effectiveness for post-training quantization in small language models.arXiv preprint arXiv:2508.03332, 2025
-
[42]
Dope: Denoising rotary position embedding.arXiv preprint arXiv:2511.09146, 2025
Jing Xiong, Liyang Fan, Hui Shen, Zunhai Su, Min Yang, Lingpeng Kong, and Ngai Wong. Dope: Denoising rotary position embedding.arXiv preprint arXiv:2511.09146, 2025
-
[43]
Jing Xiong, Jianghan Shen, Chuanyang Zheng, Zhongwei Wan, Chenyang Zhao, Chiwun Yang, Fanghua Ye, Hongxia Yang, Lingpeng Kong, and Ngai Wong. Parallelcomp: Parallel long-context compressor for length extrapolation.arXiv preprint arXiv:2502.14317, 2025
-
[44]
Fit and prune: Fast and training-free visual token pruning for multi-modal large language models
Weihao Ye, Qiong Wu, Wenhao Lin, and Yiyi Zhou. Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 22128–22136, 2025
work page 2025
-
[45]
Su Z, Chen Z, Shen W, et al. Rotatekv: Accurate and robust 2-bit kv cache quantization for llms via outlier-aware adaptive rotations.arXiv preprint arXiv:2501.16383, 2025
-
[46]
Efficient context scaling with longcat zigzag attention.arXiv preprint arXiv:2512.23966, 2025
Chen Zhang, Yang Bai, Jiahuan Li, Anchun Gui, Keheng Wang, Feifan Liu, Guanyu Wu, Yuwei Jiang, Defei Bu, Li Wei, et al. Efficient context scaling with longcat zigzag attention.arXiv preprint arXiv:2512.23966, 2025
-
[47]
Hengyuan Zhang, Zhihao Zhang, Mingyang Wang, Zunhai Su, Yiwei Wang, Qianli Wang, Shuzhou Yuan, Ercong Nie, Xufeng Duan, Qibo Xue, et al. Locate, steer, and improve: A practical survey of actionable mechanistic interpretability in large language models.arXiv preprint arXiv:2601.14004, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023. 12 A Limitations SnapMLA is optimized for MLA decoding on NVIDIA Hopper-class GPUs, leveraging FP8 Ten- sor Cores, WGMMA, TMA, and Hopper-specific memor...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.