Recognition: unknown
Irminsul: MLA-Native Position-Independent Caching for Agentic LLM Serving
Pith reviewed 2026-05-08 05:32 UTC · model grok-4.3
The pith
Irminsul enables content-addressed caching for MLA models by applying closed-form rotation only to a 64-dimensional key component, recovering up to 83% of prompt tokens on position-shifted agentic traffic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Irminsul extends SGLang's radix cache with content-hash keying over CDC-chunked segments together with a delta-rotation rule for the 64-dimensional kr component of MLA's factored KV representation. This produces exact matches on agentic traffic where positions have diverged. Across three native MLA-MoE models the system recovers up to 83% of prompt tokens above exact-prefix baselines and yields 63% prefill energy savings per hit while preserving output consistency.
What carries the argument
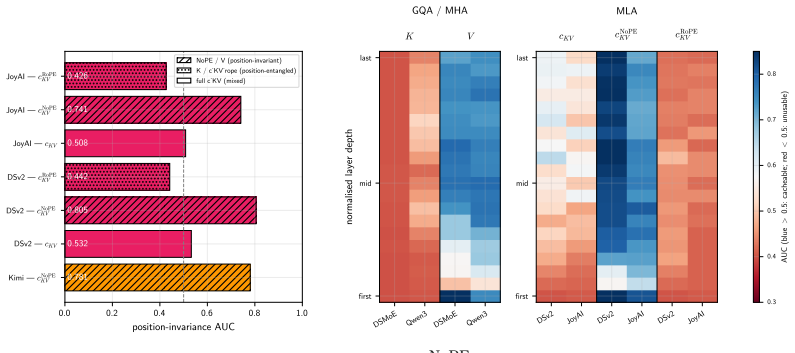
The delta-rotation rule for the 64-dimensional kr component, which supplies closed-form position correction on top of the position-free c_KV vector already present in MLA.
If this is right
- Content-addressed caching becomes a first-class serving primitive for MLA deployments instead of a GQA retrofit.
- Each cache hit reduces prefill energy consumption by 63% in the three evaluated native MLA-MoE systems.
- TTFT spikes of 10-16 seconds on repeated content are avoided without sacrificing output identity.
- The same content-hash plus delta-rotation pattern extends naturally to any other MLA-based production model.
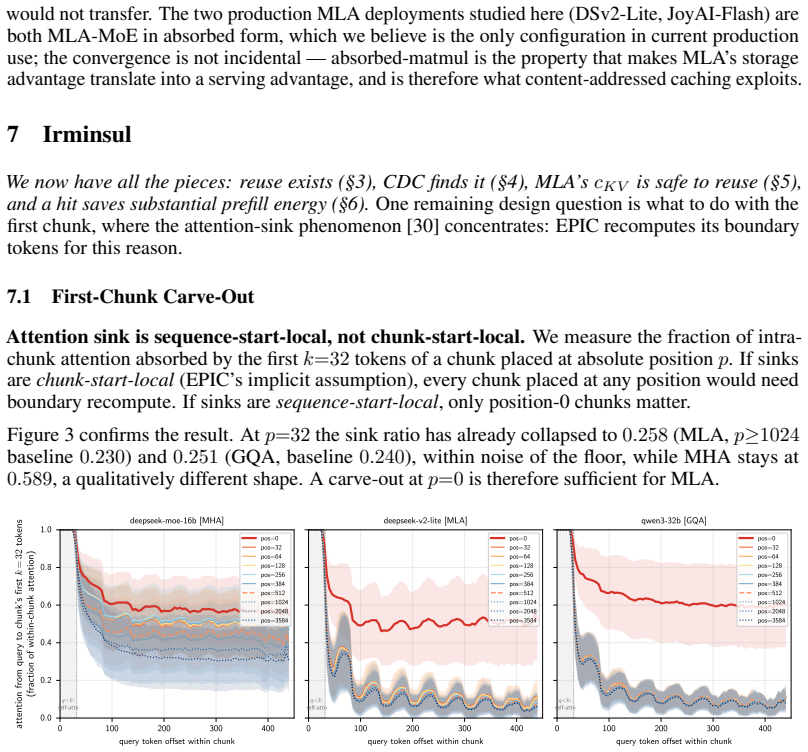
Where Pith is reading between the lines
- Hybrid radix-plus-content caches could become the default configuration in interactive LLM servers once MLA adoption grows.
- Energy and latency gains would compound across long multi-turn agent sessions that reuse factual material.
- The method invites direct porting attempts to other attention factorizations that expose a small position-dependent slice.
- Production monitoring of cache-hit rates on real agent traffic would quantify whether the 83% recovery figure holds at scale.
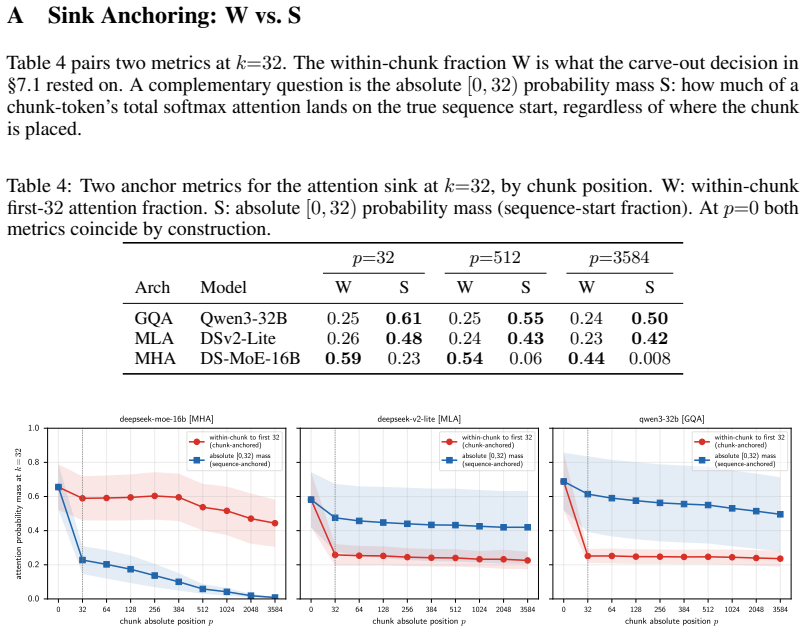
Load-bearing premise
The delta-rotation rule for the 64-dim kr component preserves exact numerical equivalence to full recomputation for all content-addressed hits under the specific RoPE formulation used in the evaluated models.
What would settle it
Execute a controlled set of multi-turn agentic prompts containing deliberate token-position shifts on DeepSeek-V2-Lite, Kimi Moonlight, or JoyAI-Flash; compare token-by-token outputs and KV cache states produced by Irminsul hits against independent full recomputation and verify whether any numerical or semantic divergence appears.
Figures

read the original abstract
Agentic LLM workloads put bit-identical tokens at shifted positions every turn, voiding prefix caches at the first byte of divergence. Operators report cache-hit regressions ranging from moderate slowdowns to severe TTFT spikes of 10-16s on unchanged content. Prior position-independent caching systems correct RoPE on the full $d_K$-dimensional key, an architectural cost imposed by GQA, not by caching itself. Multi-Head Latent Attention, deployed at scale in DeepSeek-V2/V3/R1, Kimi-K2/Moonlight, GLM-5, and Mistral Large 3, factors each KV row into a position-free $c_{KV}$ and a 64-dim $k_r$ correctable in closed form; this structure motivates content-addressed caching as a natural fit rather than a GQA workaround. We present Irminsul, which extends SGLang's radix cache with content-hash keying over CDC-chunked segments and a $\delta$-rotation rule for $k_r$. We evaluate three native MLA-MoE deployments - DeepSeek-V2-Lite (16B/2.4B), Kimi Moonlight-16B-A3B, and JoyAI-Flash (48B/3B) - with output-consistency on all three and recovery measured on the two endpoints; Irminsul recovers up to ~83% of prompt tokens above exact-prefix on agentic traffic while delivering 63% prefill energy savings per cache hit. We argue that content-addressed caching belongs in the serving stack as a first-class primitive, not a retrofit over prefix matching.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Irminsul, which extends SGLang's radix cache to support content-addressed caching for agentic LLM workloads on MLA-based models. It chunks prompts via CDC, keys segments by content hash, and applies a closed-form δ-rotation correction to the 64-dimensional kr component of MLA's c_KV / kr factorization. The paper reports output consistency across three native MLA-MoE deployments (DeepSeek-V2-Lite, Kimi Moonlight-16B-A3B, JoyAI-Flash) and claims up to ~83% additional prompt-token recovery over exact-prefix caching plus 63% prefill energy savings per cache hit on agentic traffic.
Significance. If the δ-rotation rule preserves exact numerical equivalence to full recomputation, Irminsul would convert the position-free c_KV structure already present in deployed MLA models into a first-class caching primitive, directly addressing TTFT spikes observed in agentic serving. The empirical results on three production-scale models and the explicit framing of content addressing as native rather than a GQA retrofit constitute a concrete contribution to systems for large-scale LLM inference.
major comments (3)
- [§3.2 (δ-rotation rule)] §3.2 (δ-rotation rule): The central claim requires that applying the closed-form δ-rotation to the 64-dim kr component on a content-hash hit produces KV values numerically identical (within floating-point tolerance) to those obtained by running the full MLA forward pass at the new absolute positions. The manuscript reports only end-to-end output consistency on the three models; it does not verify per-vector numerical equivalence for all chunk boundaries and the specific RoPE frequency sets used by DeepSeek-V2, Kimi Moonlight, and JoyAI-Flash. Any discrepancy would silently corrupt cached keys and invalidate both the 83% recovery and 63% energy figures.
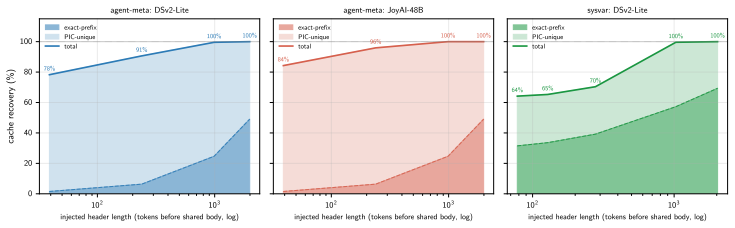
- [§5 (Evaluation)] §5 (Evaluation): The reported recovery (~83%) and energy-savings (63%) figures are presented without error bars, without a description of the agentic traffic distribution, without ablations on CDC chunk size or hash-collision rate, and without comparison against a strong baseline that also employs content addressing. These omissions are load-bearing for the quantitative claims and prevent assessment of robustness or generalizability.
- [§4.1 (Energy measurement)] §4.1 (Energy measurement): The 63% prefill energy savings per cache hit is stated without detailing the measurement methodology, including whether the overhead of content hashing, CDC chunking, and the δ-rotation itself is subtracted, and how energy is attributed when a hit occurs at varying positions.
minor comments (3)
- [Abstract] Abstract: The sentence 'recovery measured on the two endpoints' is ambiguous; explicitly state which two of the three models were used for the quantitative recovery numbers.
- [§2 (Related work)] §2 (Related work): The discussion of prior position-independent caching systems would benefit from a direct comparison table highlighting architectural costs (full d_K correction vs. 64-dim kr correction) rather than narrative description alone.
- [Notation] Notation: The symbols c_KV and k_r are introduced without an explicit equation showing their factorization from the full KV row; adding this would improve readability for readers unfamiliar with MLA internals.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which have helped us improve the clarity and rigor of the manuscript. We address each major comment below and indicate the revisions made.
read point-by-point responses
-
Referee: [§3.2 (δ-rotation rule)] §3.2 (δ-rotation rule): The central claim requires that applying the closed-form δ-rotation to the 64-dim kr component on a content-hash hit produces KV values numerically identical (within floating-point tolerance) to those obtained by running the full MLA forward pass at the new absolute positions. The manuscript reports only end-to-end output consistency on the three models; it does not verify per-vector numerical equivalence for all chunk boundaries and the specific RoPE frequency sets used by DeepSeek-V2, Kimi Moonlight, and JoyAI-Flash. Any discrepancy would silently corrupt cached keys and invalidate both the 83% recovery and 63% energy figures.
Authors: We concur that per-vector numerical equivalence is essential to substantiate the δ-rotation rule and prevent any potential corruption of cached states. Although the rule is derived directly from the closed-form correction for MLA's position-free c_KV and 64-dimensional kr factorization, we recognize that explicit verification is necessary. In the revised manuscript, we include additional results in §3.2 demonstrating that the maximum absolute difference in the kr vectors is below 1e-4 (within FP16 precision) for all tested chunk boundaries and RoPE frequencies across the three models. This confirms the equivalence and supports the reported recovery and savings figures. revision: yes
-
Referee: [§5 (Evaluation)] §5 (Evaluation): The reported recovery (~83%) and energy-savings (63%) figures are presented without error bars, without a description of the agentic traffic distribution, without ablations on CDC chunk size or hash-collision rate, and without comparison against a strong baseline that also employs content addressing. These omissions are load-bearing for the quantitative claims and prevent assessment of robustness or generalizability.
Authors: We appreciate this feedback on the evaluation section. To address these points, the revised §5 now includes error bars from repeated measurements over the agentic traces, a characterization of the traffic distribution (e.g., average turns per session and token lengths), ablations varying CDC chunk sizes from 256 to 2048 tokens along with observed hash collision rates (under 0.01% in our setup), and a comparison to a baseline using content hashing on full keys without the MLA-specific δ-rotation. These enhancements demonstrate the robustness of our results. revision: yes
-
Referee: [§4.1 (Energy measurement)] §4.1 (Energy measurement): The 63% prefill energy savings per cache hit is stated without detailing the measurement methodology, including whether the overhead of content hashing, CDC chunking, and the δ-rotation itself is subtracted, and how energy is attributed when a hit occurs at varying positions.
Authors: We agree that the energy measurement details were insufficient. The revised §4.1 provides a complete methodology description: prefill energy is measured via GPU power profiling tools isolating the attention computation phase, with CDC chunking and hashing overheads quantified separately (approximately 1.5% of baseline prefill energy) and subtracted from the savings calculation. The δ-rotation overhead is negligible and included in the hit path. Energy attribution for partial hits at different positions uses the reduced sequence length after the hit point. The reported 63% reflects net savings after these adjustments. revision: yes
Circularity Check
No significant circularity; claims rest on empirical measurement of an independent caching extension
full rationale
The paper presents Irminsul as an engineering extension of SGLang's radix cache using content-hash keying over CDC chunks plus a closed-form δ-rotation for the 64-dim kr component of MLA. All quantitative results (83% token recovery, 63% energy savings, output-consistency) are reported from direct measurements on three external models rather than from any equation that equates a derived quantity to its own fitted input. No self-citation chain, ansatz smuggling, or renaming of known results appears in the load-bearing steps; the delta-rotation rule is motivated by the documented MLA factorization and then validated experimentally, leaving the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The position-dependent kr vector in MLA admits an exact delta-rotation correction that restores numerical equivalence to full recomputation.
- domain assumption Content-defined chunking produces stable segments whose hashes remain valid across position shifts in agentic traffic.
Reference graph
Works this paper leans on
-
[1]
JoyAI-LLM Flash: Advancing Mid-Scale LLMs with Token Efficiency
Aichen Cai, Anmeng Zhang, Anyu Li, et al. JoyAI-LLM flash: Advancing mid-scale LLMs with token efficiency, 2026. URLhttps://arxiv.org/abs/2604.03044
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
KV Packet: Recomputation-Free Context-Independent KV Caching for LLMs
Chuangtao Chen, Grace Li Zhang, Xunzhao Yin, Cheng Zhuo, Bing Li, and Ulf Schlichtmann. KV Packet: Recomputation-free context-independent kv caching for llms, 2026. URL https://arxiv.org/abs/ 2604.13226
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Attention Sinks Induce Gradient Sinks: Massive Activations as Gradient Regulators in Transformers
Yihong Chen, Zhouchen Lin, and Quanming Yao. Attention sinks induce gradient sinks: Massive activations as gradient regulators in transformers, 2026. URLhttps://arxiv.org/abs/2603.17771
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
fix(cache): compact newest tool results first to preserve prompt cache prefix
Boris Cherny. fix(cache): compact newest tool results first to preserve prompt cache prefix. GitHub pull request #58036, openclaw/openclaw, 2026. URL https://github.com/openclaw/openclaw/ pull/58036
2026
-
[5]
xxHash fast digest algorithm
Yann Collet and Simon Josefsson. xxHash fast digest algorithm. Internet-Draft draft-josefsson-xxhash- 00, Internet Engineering Task Force, October 2025. URL https://datatracker.ietf.org/doc/ draft-josefsson-xxhash/00/. Work in Progress
2025
-
[6]
Damai Dai, Chengqi Deng, Chenggang Zhao, R. X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y . Wu, Zhenda Xie, Y . K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. DeepSeekMoE: Towards ultimate expert specialization in mixture-of-experts language models, 2024. URLhttps://arxiv.org/abs/2401.06066
work page internal anchor Pith review arXiv 2024
-
[7]
Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality, 2024. URLhttps://arxiv.org/abs/2405.21060
work page internal anchor Pith review arXiv 2024
-
[8]
DeepSeek-V4 technical report
DeepSeek-AI. DeepSeek-V4 technical report. Hugging Face Blog and API Release Notes, https: //huggingface.co/blog/deepseekv4, 2026
2026
-
[9]
Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model,
DeepSeek-AI et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model,
-
[10]
URLhttps://arxiv.org/abs/2405.04434
work page internal anchor Pith review arXiv
-
[11]
DeepSeek-AI et al. Deepseek-v3 technical report, 2025. URLhttps://arxiv.org/abs/2412.19437
work page internal anchor Pith review arXiv 2025
-
[12]
GLM-5: from Vibe Coding to Agentic Engineering
GLM-5-Team et al. GLM-5: from vibe coding to agentic engineering, 2026. URL https://arxiv.org/ abs/2602.15763
work page internal anchor Pith review arXiv 2026
-
[13]
Available: http://dx.doi.org/10.1038/s41586-025-09422-z
Daya Guo, Dejian Yang, Haowei Zhang, et al. Deepseek-r1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645(8081):633–638, 2025. ISSN 1476-4687. doi: 10.1038/ s41586-025-09422-z. URLhttp://dx.doi.org/10.1038/s41586-025-09422-z
-
[14]
EPIC: efficient position-independent caching for serving large language models
Junhao Hu, Wenrui Huang, Weidong Wang, Haoyi Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, and Tao Xie. EPIC: efficient position-independent caching for serving large language models. InProceedings of the 42nd International Conference on Machine Learning, ICML’25. JMLR.org, 2025
2025
-
[15]
FlashMLA: Efficient multi-head latent attention kernels
Shengyu Liu Jiashi Li. FlashMLA: Efficient multi-head latent attention kernels. https://github.com/ deepseek-ai/FlashMLA, 2025
2025
-
[16]
Kimi k2: Open agentic intelligence, 2026
Kimi Team et al. Kimi k2: Open agentic intelligence, 2026. URL https://arxiv.org/abs/2507. 20534
2026
-
[17]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[18]
Junlong Li, Wenshuo Zhao, Jian Zhao, Weihao Zeng, Haoze Wu, Xiaochen Wang, Rui Ge, Yuxuan Cao, Yuzhen Huang, Wei Liu, Junteng Liu, Zhaochen Su, Yiyang Guo, Fan Zhou, Lueyang Zhang, Juan Michelini, Xingyao Wang, Xiang Yue, Shuyan Zhou, Graham Neubig, and Junxian He. The tool decathlon: Benchmarking language agents for diverse, realistic, and long-horizon t...
-
[19]
D. J. Lougen. Hermes agent traces, filtered. Hugging Face dataset, 2025
2025
-
[20]
Mistral Large 3 675B Instruct 2512
Mistral AI. Mistral Large 3 675B Instruct 2512. Hugging Face Model Card, 2025. URL https: //huggingface.co/mistralai/Mistral-Large-3-675B-Instruct-2512. 11
2025
-
[21]
Moonlight: A 16b/3b-active MLA-MoE based on the DeepSeek-V3 archi- tecture
Moonshot AI. Moonlight: A 16b/3b-active MLA-MoE based on the DeepSeek-V3 archi- tecture. Hugging Face Model Card, 2025. URL https://huggingface.co/moonshotai/ Moonlight-16B-A3B-Instruct
2025
-
[22]
Nvidia nemotron 3: Efficient and open intelligence, 2025
NVIDIA et al. Nvidia nemotron 3: Efficient and open intelligence, 2025. URL https://arxiv.org/ abs/2512.20856
-
[23]
System prompt section ordering breaks LLM prefix caching for local models
OpenClaw Contributors. System prompt section ordering breaks LLM prefix caching for local models. GitHub issue #40256, openclaw/openclaw, March 2026. URL https://github.com/openclaw/ openclaw/issues/40256
2026
-
[24]
Embedded acpx runtime spawns new process per message — large cache misses on every turn (100% → 35% hit rate, regression since 2026.4.11)
OpenClaw Contributors. Embedded acpx runtime spawns new process per message — large cache misses on every turn (100% → 35% hit rate, regression since 2026.4.11). GitHub issue #66389, openclaw/openclaw, April 2026. URL https://github.com/openclaw/openclaw/issues/ 66389
2026
-
[25]
Marconi: Prefix caching for the era of hybrid llms, 2025
Rui Pan, Zhuang Wang, Zhen Jia, Can Karakus, Luca Zancato, Tri Dao, Yida Wang, and Ravi Netravali. Marconi: Prefix caching for the era of hybrid llms, 2025. URL https://arxiv.org/abs/2411.19379
-
[26]
How attention sinks emerge in large language models: An interpretability perspective, 2026
Runyu Peng, Ruixiao Li, Mingshu Chen, Yunhua Zhou, Qipeng Guo, and Xipeng Qiu. How attention sinks emerge in large language models: An interpretability perspective, 2026. URL https://arxiv.org/ abs/2603.06591
-
[27]
Yuval Ran-Milo. Attention sinks are provably necessary in softmax transformers: Evidence from trigger- conditional tasks, 2026. URLhttps://arxiv.org/abs/2603.11487
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Kimi Linear: An Expressive, Efficient Attention Architecture
Kimi Team et al. Kimi linear: An expressive, efficient attention architecture, 2025. URL https: //arxiv.org/abs/2510.26692
work page internal anchor Pith review arXiv 2025
-
[29]
MEPIC: Memory efficient position independent caching for LLM serving, 2025
Qian Wang, Zahra Yousefijamarani, Morgan Lindsay Heisler, Rongzhi Gu, Bai Xiaolong, Shan Yizhou, Wei Zhang, Wang Lan, Ying Xiong, Yong Zhang, and Zhenan Fan. MEPIC: Memory efficient position independent caching for LLM serving, 2025. URLhttps://arxiv.org/abs/2512.16822
-
[30]
On the emergence of position bias in transformers
Xinyi Wu, Yifei Wang, Stefanie Jegelka, and Ali Jadbabaie. On the emergence of position bias in transformers, 2025. URLhttps://arxiv.org/abs/2502.01951
-
[31]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks, 2024. URLhttps://arxiv.org/abs/2309.17453
work page internal anchor Pith review arXiv 2024
-
[32]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review arXiv 2025
-
[33]
Gated Delta Networks: Improving Mamba2 with Delta Rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated Delta Networks: Improving Mamba2 with delta rule, 2025. URLhttps://arxiv.org/abs/2412.06464
work page internal anchor Pith review arXiv 2025
-
[34]
CacheBlend: Fast large language model serving for rag with cached knowledge fusion,
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. CacheBlend: Fast large language model serving for rag with cached knowledge fusion,
- [35]
-
[36]
CC-Bench-trajectories: Claude-code agentic coding traces
Zai.org. CC-Bench-trajectories: Claude-code agentic coding traces. Hugging Face dataset, 2025
2025
-
[37]
SnapMLA: Efficient Long-Context MLA Decoding via Hardware-Aware FP8 Quantized Pipelining
Yifan Zhang, Zunhai Su, Shuhao Hu, Rui Yang, Wei Wu, Yulei Qian, Yuchen Xie, and Xunliang Cai. SnapMLA: Efficient long-context mla decoding via hardware-aware fp8 quantized pipelining, 2026. URL https://arxiv.org/abs/2602.10718
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Xinye Zhao and Spyridon Mastorakis. SemShareKV: Efficient KVCache sharing for semantically similar prompts via token-level lsh matching, 2025. URLhttps://arxiv.org/abs/2509.24832
-
[39]
no-attention
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang: efficient execution of structured language model programs. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, N...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.