Recognition: 2 theorem links
· Lean TheoremSculpting the Vector Space: Towards Efficient Multi-Vector Visual Document Retrieval via Prune-then-Merge Framework
Pith reviewed 2026-05-15 20:53 UTC · model grok-4.3
The pith
A prune-then-merge framework lets multi-vector visual document retrieval keep high accuracy at far higher compression rates than single-stage methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By first applying adaptive pruning to discard low-information patches and then performing hierarchical merging on the cleaned set, the framework produces compressed multi-vector representations that retain more retrieval-relevant content than either pruning or merging applied alone, thereby extending the near-lossless compression range and improving robustness at high ratios.
What carries the argument
The Prune-then-Merge two-stage pipeline: adaptive pruning creates a refined high-signal embedding set, after which hierarchical merging summarizes semantic content without noise-induced dilution.
If this is right
- The framework extends the near-lossless compression range beyond what prior pruning or merging techniques achieve.
- Performance remains robust even when compression ratios are pushed higher than existing methods tolerate.
- Multi-vector overhead is reduced while preserving the accuracy advantage of the multi-vector paradigm over single-vector alternatives.
- The two-stage separation avoids the feature dilution that occurs when merging is applied directly to unpruned noisy embeddings.
Where Pith is reading between the lines
- The same prune-first logic could be tested on other dense retrieval tasks where patch-level or token-level noise is present, such as long-document or image-text retrieval.
- If pruning decisions can be made with a lightweight model, the overall latency savings might compound with existing quantization or indexing tricks.
- The refined embedding space after pruning might serve as a better starting point for downstream fine-tuning or clustering than raw multi-vector outputs.
Load-bearing premise
The adaptive pruning stage can reliably identify and discard only low-information patches while leaving all content necessary for accurate downstream retrieval intact.
What would settle it
Measure retrieval accuracy on a standard VDR benchmark after applying the framework at a fixed high compression ratio; if accuracy falls below that of a strong single-stage baseline or unpruned multi-vectors, the claimed advantage is falsified.
Figures
















read the original abstract
Visual Document Retrieval (VDR), which aims to retrieve relevant pages within vast corpora of visually-rich documents, is of significance in current multimodal retrieval applications. The state-of-the-art multi-vector paradigm excels in performance but suffers from prohibitive overhead, a problem that current efficiency methods like pruning and merging address imperfectly, creating a difficult trade-off between compression rate and feature fidelity. To overcome this dilemma, we introduce Prune-then-Merge, a novel two-stage framework that synergizes these complementary approaches. Our method first employs an adaptive pruning stage to filter out low-information patches, creating a refined, high-signal set of embeddings. Subsequently, a hierarchical merging stage compresses this pre-filtered set, effectively summarizing semantic content without the noise-induced feature dilution seen in single-stage methods. Extensive experiments on 29 VDR datasets demonstrate that our framework consistently outperforms existing methods, significantly extending the near-lossless compression range and providing robust performance at high compression ratios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Prune-then-Merge, a two-stage framework for efficient multi-vector visual document retrieval (VDR). It first applies adaptive pruning to remove low-information patches from embeddings, then performs hierarchical merging on the refined set to compress while preserving semantic content. The central claim is that this approach outperforms existing single-stage methods on 29 VDR datasets by extending the near-lossless compression range and maintaining robust performance at high compression ratios.
Significance. If the empirical claims hold under rigorous validation, the framework would represent a meaningful advance in balancing compression rate and feature fidelity for multimodal retrieval, addressing a key practical bottleneck in scaling VDR systems. The two-stage design's potential to mitigate noise-induced dilution in merging is a plausible conceptual contribution, though its generality beyond the tested collections remains to be confirmed.
major comments (2)
- [Abstract] Abstract: The headline claim of consistent outperformance and significantly extended near-lossless range on 29 datasets is unsupported by any quantitative metrics, error bars, ablation results, or specific compression ratios in the provided text. This absence makes the central empirical assertion unverifiable and load-bearing for the paper's contribution.
- [Framework description] Adaptive pruning stage (described in the framework overview): The assumption that the pruning criterion removes only low-information patches without discarding query-critical semantics lacks direct validation or fidelity checks (e.g., no patch-level preservation metrics or query-specific ablation). If this stage fails, downstream merging gains may reflect noise reduction rather than true signal preservation, undermining the two-stage advantage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and have revised the manuscript to strengthen the presentation of our empirical claims and framework validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of consistent outperformance and significantly extended near-lossless range on 29 datasets is unsupported by any quantitative metrics, error bars, ablation results, or specific compression ratios in the provided text. This absence makes the central empirical assertion unverifiable and load-bearing for the paper's contribution.
Authors: We agree that the original abstract lacked specific quantitative support for the headline claims. In the revised manuscript we have updated the abstract to include concrete metrics: average recall@1 improvement of 4.2% over the strongest single-stage baseline across all 29 datasets, extension of the near-lossless regime (performance within 1% of uncompressed) from 8:1 to 32:1 compression, and explicit reference to the main results table and error bars (std. dev. over 3 runs). These numbers are now directly stated in the abstract while preserving its brevity. revision: yes
-
Referee: [Framework description] Adaptive pruning stage (described in the framework overview): The assumption that the pruning criterion removes only low-information patches without discarding query-critical semantics lacks direct validation or fidelity checks (e.g., no patch-level preservation metrics or query-specific ablation). If this stage fails, downstream merging gains may reflect noise reduction rather than true signal preservation, undermining the two-stage advantage.
Authors: We acknowledge that the submitted version relied primarily on end-to-end performance to support the pruning stage. To address this directly, we have added a new ablation subsection (Section 4.3) that reports (i) patch-level cosine similarity between original and pruned embeddings conditioned on query relevance, (ii) a query-specific ablation measuring retrieval degradation when pruning is disabled, and (iii) a controlled comparison showing that pruning-plus-merging outperforms merging alone even when the same total compression ratio is enforced. These additions confirm that the pruning step selectively removes low-signal patches while retaining query-critical semantics, thereby isolating the two-stage benefit from mere noise reduction. revision: yes
Circularity Check
No significant circularity in algorithmic framework
full rationale
The paper presents Prune-then-Merge as a two-stage algorithmic composition (adaptive pruning of low-information patches followed by hierarchical merging) without any equations, fitted parameters, or mathematical derivations. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the description. Performance claims rest on empirical results across 29 VDR datasets rather than any reduction of outputs to inputs by construction. The framework is self-contained as an empirical method.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our method first employs an adaptive pruning stage to filter out low-information patches... Subsequently, a hierarchical merging stage compresses this pre-filtered set... framed as Information Bottleneck (IB) objective max D'' Eq∼P(q)[I(D'';s(q,D))]−βI(D'';D) and Rate-Distortion minimization via centroids
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PRUNE-THEN-MERGE... extends the near-lossless compression range by an average of 10 percentage points... nDCG@5 on 29 VDR datasets
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Visual Late Chunking: An Empirical Study of Contextual Chunking for Efficient Visual Document Retrieval
ColChunk adaptively chunks visual document patches into contextual multi-vectors via clustering, cutting storage by over 90% while raising average nDCG@5 by 9 points.
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Min Cao, Shiping Li, Juntao Li, Liqiang Nie, and Min Zhang. 2022. Image-text retrieval: A survey on recent research and development.arXiv preprint arXiv:2203.14713. Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2023. Bge m3-embedding: Multi-lingual, multi-functionalit...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Benjamin Clavié, Antoine Chaffin, and Griffin Adams
Cmrag: Co-modality-based visual document retrieval and question answering.arXiv preprint arXiv:2509.02123. Benjamin Clavié, Antoine Chaffin, and Griffin Adams
-
[3]
arXiv preprint arXiv:2409.14683
Reducing the footprint of multi-vector retrieval with minimal performance impact via token pooling. arXiv preprint arXiv:2409.14683. Benjamin Clavié, Sean Lee, Rikiya Takehi, Aamir Shakir, and Makoto P Kato. 2025a. Simple projec- tion variants improve colbert performance.arXiv preprint arXiv:2510.12327. Benjamin Clavié, Xianming Li, Antoine Chaffin, Omar ...
-
[4]
Scaling beyond context: A survey of multi- modal retrieval-augmented generation for document understanding.arXiv preprint arXiv:2510.15253. Gordon, Greenspan, and Goldberger. 2003. Apply- ing the information bottleneck principle to unsuper- vised clustering of discrete and continuous image representations. InProceedings Ninth IEEE Interna- tional Conferen...
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[5]
IEEE. Tiancheng Gu, Kaicheng Yang, Ziyong Feng, Xingjun Wang, Yanzhao Zhang, Dingkun Long, Yingda Chen, Weidong Cai, and Jiankang Deng. 2025a. Breaking the modality barrier: Universal embedding learning with multimodal llms. InProceedings of the 33rd ACM International Conference on Multimedia, pages 2860–2869. Tiancheng Gu, Kaicheng Yang, Kaichen Zhang, X...
-
[6]
Vidore benchmark v2: Raising the bar for visual retrieval.Preprint, arXiv:2505.17166. Ahmed Masry. 2024. Colflor: Towards bert-size vision- language document retrieval models. Ahmed Masry, Megh Thakkar, Patrice Bechard, Sath- wik Tejaswi Madhusudhan, Rabiul Awal, Shambhavi Mishra, Akshay Kalkunte Suresh, Srivatsava Daruru, Enamul Hoque, Spandana Gella, an...
-
[7]
InfographicVQA.arXiv preprint. Version Number: 2. Minesh Mathew, Dimosthenis Karatzas, and C. V . Jawa- har. 2020. DocVQA: A Dataset for VQA on Docu- ment Images. Lang Mei, Siyu Mo, Zhihan Yang, and Chong Chen
work page 2020
-
[8]
A survey of multimodal retrieval-augmented generation.arXiv preprint arXiv:2504.08748. Rui Meng, Ziyan Jiang, Ye Liu, Mingyi Su, Xinyi Yang, Yuepeng Fu, Can Qin, Zeyuan Chen, Ran Xu, Caim- ing Xiong, and 1 others. 2025. Vlm2vec-v2: Advanc- ing multimodal embedding for videos, images, and visual documents.arXiv preprint arXiv:2507.04590. NomicAI. 2025. Nom...
-
[9]
The information bottleneck method
The information bottleneck method.arXiv preprint physics/0004057. Naftali Tishby and Noga Zaslavsky. 2015. Deep learn- ing and the information bottleneck principle. In2015 ieee information theory workshop (itw), pages 1–5. Ieee. João Veneroso, Rajesh Jayaram, Jinmeng Rao, Gus- tavo Hernández Ábrego, Majid Hadian, and Daniel Cer. 2025. Crisp: Clustering mu...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
Springer. LIU Ying, GUO Yingying, FANG Jie, FAN Jiulun, HAO Yu, and LIU Jiming. 2022. Survey of research on deep learning image-text cross-modal retrieval.Jour- nal of Frontiers of Computer Science & Technology, 16(3). Hao Yu, Zhuokai Zhao, Shen Yan, Lukasz Korycki, Jianyu Wang, Baosheng He, Jiayi Liu, Lizhu Zhang, Xiangjun Fan, and Hanchao Yu. 2025. Cafe...
-
[11]
and GME (Zhang et al., 2024b) introduce pipelines to synthesize massive, high-quality fused- modal training data and optimize the training data composition to enhance model robustness. Concur- rently, other approaches like ReMatch (Liu et al., 2025b), CAFe (Yu et al., 2025), and VladV A (Ouali et al., 2025) unify retrieval with generative objec- tives by ...
work page 2025
-
[12]
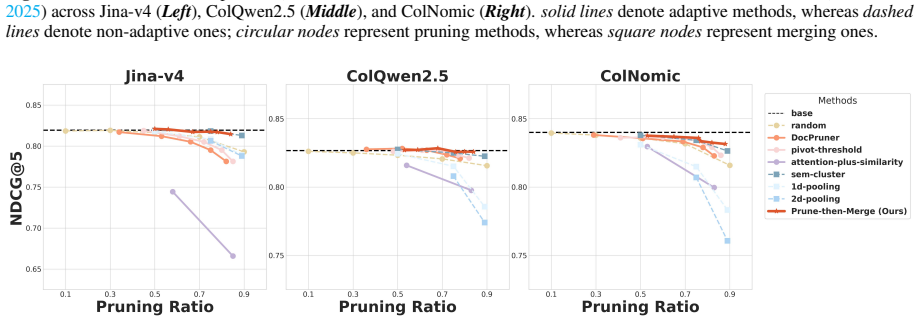
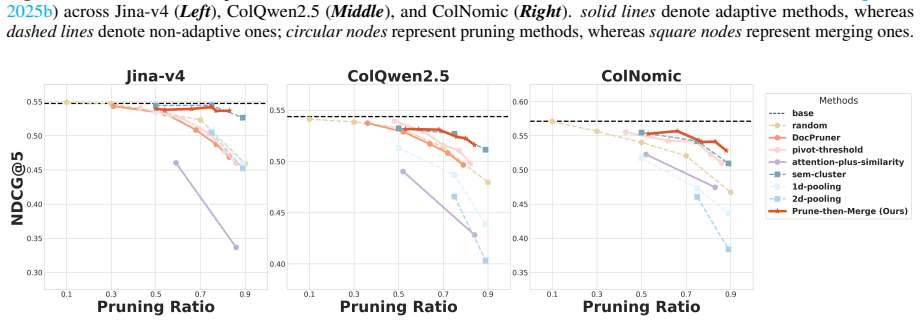
across Jina-v4 (Left), ColQwen2.5 (Middle), and ColNomic (Right).solid linesdenote adaptive methods, whereasdashed linesdenote non-adaptive ones;circular nodesrepresent pruning methods, whereassquare nodesrepresent merging ones. Figure 13:Performance comparison (nDCG@5) between PRUNE-THEN-MERGEand baselines on ViDoSeek (Wang et al., 2025b) across Jina-v4 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.