Recognition: 1 theorem link
· Lean TheoremUniLACT: Depth-Aware RGB Latent Action Learning for Vision-Language-Action Models
Pith reviewed 2026-05-15 20:15 UTC · model grok-4.3
The pith
Depth integration into latent action pretraining strengthens spatial priors in vision-language-action models for robotic manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
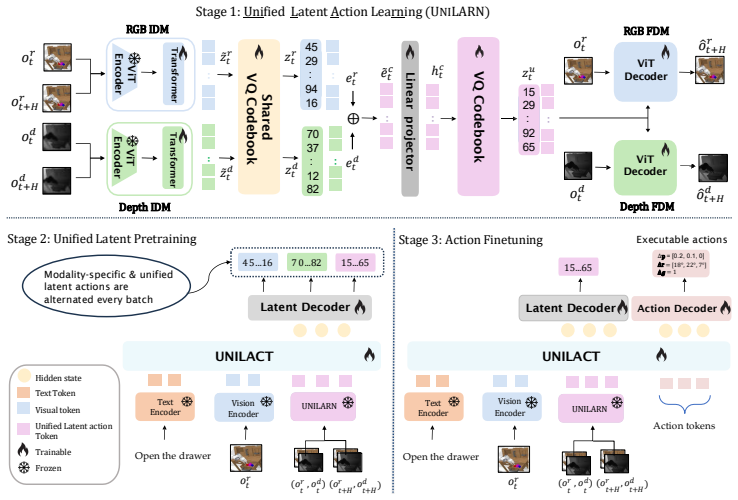
UniLACT is a transformer-based VLA model pretrained with depth-aware latent actions learned via UniLARN, a framework that models cross-modal interactions between RGB and depth to produce unified and modality-specific latent representations serving as action pseudo-labels.
What carries the argument
UniLARN, a unified latent action learning framework using inverse and forward dynamics to learn shared RGB-depth embeddings.
If this is right
- UniLACT outperforms RGB-based baselines in both in-domain and out-of-domain pretraining regimes.
- Performance improves on both seen and unseen manipulation tasks.
- Stronger spatial priors are inherited by downstream policies.
- The approach works in both simulated and real-world environments.
Where Pith is reading between the lines
- Combining depth with other sensors could further enhance the unified space for more complex tasks.
- Such pretraining might lower data requirements for training effective VLA models.
- Generalization to new robots or environments could benefit from the explicit 3D structure.
Load-bearing premise
That depth supplies critical 3D geometric structure absent in RGB and that the unified latent space transfers this structure to policies without introducing biases or noise.
What would settle it
Demonstrating no performance difference or degradation when using depth-aware pretraining compared to RGB-only on a suite of contact-rich manipulation tasks would falsify the central claim.
Figures



read the original abstract
Latent action representations learned from unlabeled videos have recently emerged as a promising paradigm for pretraining vision-language-action (VLA) models without explicit robot action supervision. However, latent actions derived solely from RGB observations primarily encode appearance-driven dynamics and lack explicit 3D geometric structure, which is essential for precise and contact-rich manipulation. To address this limitation, we introduce UniLACT, a transformer-based VLA model that incorporates geometric structure through depth-aware latent pretraining, enabling downstream policies to inherit stronger spatial priors. To facilitate this process, we propose UniLARN, a unified latent action learning framework based on inverse and forward dynamics objectives that learns a shared embedding space for RGB and depth while explicitly modeling their cross-modal interactions. This formulation produces modality-specific and unified latent action representations that serve as pseudo-labels for the depth-aware pretraining of UniLACT. Extensive experiments in both simulation and real-world settings demonstrate the effectiveness of depth-aware unified latent action representations. UniLACT consistently outperforms RGB-based latent action baselines under in-domain and out-of-domain pretraining regimes, as well as on both seen and unseen manipulation tasks.The project page is at https://manishgovind.github.io/unilact-vla/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UniLACT, a transformer-based vision-language-action model that incorporates depth observations into latent action pretraining via the UniLARN framework. UniLARN learns a shared embedding space for RGB and depth using inverse and forward dynamics objectives, producing modality-specific and unified latent actions as pseudo-labels. The central claim is that this depth-aware approach supplies explicit 3D geometric structure missing from RGB-only latent actions, yielding consistent outperformance over RGB baselines on in-domain/out-of-domain pretraining and seen/unseen manipulation tasks in simulation and real-world settings.
Significance. If the performance gains can be isolated to the depth contribution and shown to reflect transferable 3D priors rather than capacity or formulation differences, the work would meaningfully advance latent-action pretraining for VLAs by addressing a plausible limitation of appearance-driven dynamics in contact-rich manipulation. The unified cross-modal formulation is a reasonable technical direction, but its value hinges on evidence that the shared latents measurably encode richer geometry.
major comments (2)
- [Abstract] Abstract: The headline claim of consistent outperformance over RGB-based latent action baselines is stated without any quantitative results (success rates, metrics, number of trials, statistical tests, or data splits), preventing evaluation of whether the depth-aware component drives the reported gains or whether they arise from extra capacity, longer pretraining, or the inverse/forward dynamics formulation itself.
- [Method] Method (UniLARN description): No auxiliary evaluations are provided (e.g., depth reconstruction error, 3D keypoint prediction accuracy, or contact-point metrics) to demonstrate that the unified RGB+depth latents contain measurably richer geometric information than RGB-only latents. Without such isolation, the central assumption that depth supplies essential 3D structure and that the cross-modal objectives transfer it effectively remains untested.
minor comments (1)
- [Abstract] The project page link is a positive addition for reproducibility; consider adding a brief summary of key hyperparameters or training details in the main text to aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the concerns by revising the abstract to include quantitative results and by adding auxiliary evaluations of the latent representations to better isolate the contribution of depth. These changes will strengthen the evidence for our claims without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of consistent outperformance over RGB-based latent action baselines is stated without any quantitative results (success rates, metrics, number of trials, statistical tests, or data splits), preventing evaluation of whether the depth-aware component drives the reported gains or whether they arise from extra capacity, longer pretraining, or the inverse/forward dynamics formulation itself.
Authors: We agree that the abstract would benefit from quantitative details to allow immediate assessment of the gains. In the revised manuscript, we will incorporate specific success rates (e.g., average improvements of X% on seen tasks and Y% on unseen tasks), the number of trials, data splits, and statistical significance where applicable. These numbers are drawn directly from the experimental tables in the full paper and will clarify that the improvements stem from the depth-aware unified latents rather than capacity or training differences. revision: yes
-
Referee: [Method] Method (UniLARN description): No auxiliary evaluations are provided (e.g., depth reconstruction error, 3D keypoint prediction accuracy, or contact-point metrics) to demonstrate that the unified RGB+depth latents contain measurably richer geometric information than RGB-only latents. Without such isolation, the central assumption that depth supplies essential 3D structure and that the cross-modal objectives transfer it effectively remains untested.
Authors: We acknowledge the value of auxiliary metrics for isolating the geometric contribution. While the primary evidence comes from downstream task performance, we will add in the revision a new subsection with auxiliary evaluations, including depth reconstruction error and 3D keypoint prediction accuracy comparisons between RGB-only and unified latents. These will show quantitatively that the cross-modal objectives yield richer 3D structure, directly addressing the assumption. revision: yes
Circularity Check
Minor self-citation present; core derivation independent of fitted inputs
full rationale
The paper's method rests on standard inverse/forward dynamics objectives applied to RGB+depth inputs to produce unified latent actions, with no equations that reduce claimed performance gains to a parameter fit by construction. No self-definitional loops, uniqueness theorems imported from the same authors, or ansatzes smuggled via citation are present. Any self-citations are non-load-bearing and do not substitute for the cross-modal pretraining logic. The derivation chain is therefore self-contained against external benchmarks and receives a low circularity score.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer architectures can effectively model cross-modal interactions between RGB and depth modalities
Forward citations
Cited by 1 Pith paper
-
RotVLA: Rotational Latent Action for Vision-Language-Action Model
RotVLA models latent actions as continuous SO(n) rotations with triplet-frame supervision and flow-matching to reach 98.2% success on LIBERO and 89.6%/88.5% on RoboTwin2.0 using a 1.7B-parameter model.
Reference graph
Works this paper leans on
-
[1]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim,et al., “Openvla: An open-source vision-language-action model,” 2024. [Online]. Available: https://arxiv.org/abs/2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black,et al., “π 0: A vision-language-action flow model for general robot control,” 2024. [Online]. Available: https: //arxiv.org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Vla-0: Building state-of-the-art vlas with zero modification,
A. Goyal, H. Hadfield, X. Yang, V . Blukis, and F. Ramos, “Vla-0: Building state-of-the-art vlas with zero modification,” 2025. [Online]. Available: https://arxiv.org/abs/2510.13054
-
[5]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
C.-L. Cheang,et al., “Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation,” 2024. [Online]. Available: https://arxiv.org/abs/2410.06158
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [6]
-
[7]
D. Schmidt and M. Jiang, “Learning to act without actions,” 2024. [Online]. Available: https://arxiv.org/abs/2312.10812
-
[8]
Dynamo: In-domain dynamics pretraining for visuo-motor control,
Z. J. Cui, H. Pan, A. Iyer, S. Haldar, and L. Pinto, “Dynamo: In-domain dynamics pretraining for visuo-motor control,” 2024. [Online]. Available: https://arxiv.org/abs/2409.12192
-
[9]
Latent Action Pretraining from Videos
S. Ye,et al., “Latent action pretraining from videos,” 2025. [Online]. Available: https://arxiv.org/abs/2410.11758
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Y . Chen, Y . Ge, W. Tang, Y . Li, Y . Ge, M. Ding, Y . Shan, and X. Liu, “Moto: Latent Motion Token as the Bridging Language for Learning Robot Manipulation from Videos,” Mar. 2025, arXiv:2412.04445 [cs]. [Online]. Available: http://arxiv.org/abs/2412.04445
-
[11]
Univla: Learning to act anywhere with task-centric latent actions,
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li, “Univla: Learning to act anywhere with task-centric latent actions,”
-
[12]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
[Online]. Available: https://arxiv.org/abs/2505.06111
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Imitating Latent Policies from Observation
A. D. Edwards, H. Sahni, Y . Schroecker, and C. L. Isbell, “Imitating latent policies from observation,” 2019. [Online]. Available: https://arxRobotiv.org/abs/1805.07914
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[14]
V . Bhat, Y .-H. Lan, P. Krishnamurthy, R. Karri, and F. Khorrami, “3d cavla: Leveraging depth and 3d context to generalize vision language action models for unseen tasks,” 2025. [Online]. Available: https://arxiv.org/abs/2505.05800
-
[15]
Depthvla: Enhancing vision-language-action models with depth-aware spatial reasoning,
T. Yuan, Y . Liu, C. Lu, Z. Chen, T. Jiang, and H. Zhao, “Depthvla: Enhancing vision-language-action models with depth-aware spatial reasoning,” 2025. [Online]. Available: https://arxiv.org/abs/2510.13375
-
[16]
Qdepth-vla: Quantized depth prediction as auxiliary supervision for vision-language-action models,
Y . Li, Y . Chen, M. Zhou, and H. Li, “Qdepth-vla: Quantized depth prediction as auxiliary supervision for vision-language-action models,” 2025. [Online]. Available: https://arxiv.org/abs/2510.14836
-
[17]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
D. Qu,et al., “Spatialvla: Exploring spatial representations for visual-language-action model,” 2025. [Online]. Available: https: //arxiv.org/abs/2501.15830
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Uniskill: Imitating human videos via cross-embodiment skill representations,
H. Kim, J. Kang, H. Kang, M. Cho, S. J. Kim, and Y . Lee, “Uniskill: Imitating human videos via cross-embodiment skill representations,”
-
[19]
Available: https://arxiv.org/abs/2505.08787
[Online]. Available: https://arxiv.org/abs/2505.08787
-
[20]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan,et al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” 2023. [Online]. Available: https://arxiv.org/abs/2307.15818
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
O. X.-E. Collaboration,et al., “Open X-Embodiment: Robotic learning datasets and RT-X models,” https://arxiv.org/abs/2310.08864, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Q. Zhao,et al., “Cot-vla: Visual chain-of-thought reasoning for vision-language-action models,” 2025. [Online]. Available: https://arxiv.org/abs/2503.22020
-
[23]
Llara: Supercharging robot learning data for vision-language policy,
X. Li,et al., “Llara: Supercharging robot learning data for vision-language policy,” 2025. [Online]. Available: https://arxiv.org/ abs/2406.20095
-
[24]
Q. Li,et al., “Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation,” 2024. [Online]. Available: https://arxiv.org/abs/2411.19650
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA,et al., “Gr00t n1: An open foundation model for generalist humanoid robots,” 2025. [Online]. Available: https: //arxiv.org/abs/2503.14734
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Palm-e: An embodied multimodal language model,
D. Driess,et al., “Palm-e: An embodied multimodal language model,”
-
[27]
PaLM-E: An Embodied Multimodal Language Model
[Online]. Available: https://arxiv.org/abs/2303.03378
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Chatvla: Unified multimodal understanding and robot control with vision-language-action model,
Z. Zhou,et al., “Chatvla: Unified multimodal understanding and robot control with vision-language-action model,” 2025. [Online]. Available: https://arxiv.org/abs/2502.14420
-
[29]
Z. Zhou, Y . Zhu, J. Wen, C. Shen, and Y . Xu, “Chatvla-2: Vision-language-action model with open-world embodied reasoning from pretrained knowledge,” 2025. [Online]. Available: https: //arxiv.org/abs/2505.21906
-
[30]
R., Ramos, F., Fox, D., Li, A., Gupta, A., and Goyal, A
Y . Li,et al., “Hamster: Hierarchical action models for open-world robot manipulation,” 2025. [Online]. Available: https://arxiv.org/abs/ 2502.05485
-
[31]
Hi Robot: Open-Ended Instruction Following with Hierarchical Vision-Language-Action Models
L. X. Shi,et al., “Hi robot: Open-ended instruction following with hierarchical vision-language-action models,” 2025. [Online]. Available: https://arxiv.org/abs/2502.19417
work page internal anchor Pith review arXiv 2025
-
[32]
X. Chen, J. Guo, T. He, C. Zhang, P. Zhang, D. C. Yang, L. Zhao, and J. Bian, “Igor: Image-goal representations are the atomic control units for foundation models in embodied ai,” 2024. [Online]. Available: https://arxiv.org/abs/2411.00785
-
[33]
Amplify: Actionless motion priors for robot learning from videos,
J. A. Collins, L. Cheng, K. Aneja, A. Wilcox, B. Joffe, and A. Garg, “Amplify: Actionless motion priors for robot learning from videos,”
-
[34]
Available: https://arxiv.org/abs/2506.14198
[Online]. Available: https://arxiv.org/abs/2506.14198
-
[35]
villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
X. Chen,et al., “villa-x: Enhancing latent action modeling in vision-language-action models,” 2025. [Online]. Available: https: //arxiv.org/abs/2507.23682
work page internal anchor Pith review arXiv 2025
-
[36]
AgiBot-World-Contributors,et al., “Agibot world colosseo: A large- scale manipulation platform for scalable and intelligent embodied systems,” 2025. [Online]. Available: https://arxiv.org/abs/2503.06669
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
AdaWorld: Learning adaptable world models with latent actions.arXiv preprint arXiv:2503.18938, 2025
S. Gao, S. Zhou, Y . Du, J. Zhang, and C. Gan, “Adaworld: Learning adaptable world models with latent actions,” 2025. [Online]. Available: https://arxiv.org/abs/2503.18938
-
[38]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
C. Zhu, R. Yu, S. Feng, B. Burchfiel, P. Shah, and A. Gupta, “Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets,” 2025. [Online]. Available: https://arxiv.org/abs/2504.02792
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Spatial traces: Enhancing vla models with spatial-temporal understanding,
M. A. Patratskiy, A. K. Kovalev, and A. I. Panov, “Spatial traces: Enhancing vla models with spatial-temporal understanding,” 2025. [Online]. Available: https://arxiv.org/abs/2508.09032
-
[40]
3D-VLA: A 3D Vision-Language-Action Generative World Model
H. Zhen, X. Qiu, P. Chen, J. Yang, X. Yan, Y . Du, Y . Hong, and C. Gan, “3d-vla: A 3d vision-language-action generative world model,” 2024. [Online]. Available: https://arxiv.org/abs/2403.09631
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy,et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” 2021. [Online]. Available: https://arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[42]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked autoencoders are scalable vision learners,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 000–16 009
work page 2022
-
[43]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyals,et al., “Neural discrete representation learning,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[44]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” 2019
work page 2019
-
[45]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”Journal of Machine Learning Research, vol. 21, no. 140, pp. 1–67, 2020. [Online]. Available: http://jmlr.org/papers/v21/20-074.html
work page 2020
-
[46]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard, “Calvin: A benchmark for language-conditioned policy learning for long- horizon robot manipulation tasks,” 2022. [Online]. Available: https://arxiv.org/abs/2112.03227
-
[48]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” 2024. [Online]. Available: https://arxiv.org/abs/2303.04137
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
What Matters in Language Conditioned Robotic Imitation Learning over Unstructured Data,
O. Mees, L. Hermann, and W. Burgard, “What Matters in Language Conditioned Robotic Imitation Learning over Unstructured Data,” Aug. 2022, arXiv:2204.06252 [cs]. [Online]. Available: http://arxiv.org/abs/2204.06252
-
[50]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan,et al., “Rt-1: Robotics transformer for real-world control at scale,” 2023. [Online]. Available: https://arxiv.org/abs/2212.06817
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Vision-language foundation models as effective robot imitators
X. Li,et al., “Vision-language foundation models as effective robot imitators,” 2024. [Online]. Available: https://arxiv.org/abs/2311.01378
-
[52]
Zero-shot robotic manipulation with pretrained image-editing diffusion models
K. Black, M. Nakamoto, P. Atreya, H. Walke, C. Finn, A. Kumar, and S. Levine, “Zero-shot robotic manipulation with pretrained image-editing diffusion models,” 2023. [Online]. Available: https: //arxiv.org/abs/2310.10639
-
[53]
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong, “Unleashing large-scale video generative pre-training for visual robot manipulation,” 2023. [Online]. Available: https://arxiv.org/abs/2312.13139
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky,et al., “Droid: A large-scale in-the-wild robot manipulation dataset,” 2025. [Online]. Available: https://arxiv.org/abs/ 2403.12945
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,” 2024. [Online]. Available: https://arxiv.org/abs/2406.09414
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.