Recognition: 1 theorem link
· Lean TheoremSpotIt+: Verification-based Text-to-SQL Evaluation with Database Constraints
Pith reviewed 2026-05-15 16:07 UTC · model grok-4.3
The pith
Mining database constraints lets a verification tool generate realistic instances that expose differences between Text-to-SQL queries missed by ordinary tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SpotIt+ performs bounded equivalence verification by searching for differentiating database instances; a best-effort constraint-mining pipeline that combines rule-based specification mining with LLM-based validation over example databases ensures the generated counterexamples reflect practically relevant discrepancies.
What carries the argument
Best-effort constraint-mining pipeline that combines rule-based specification mining with LLM-based validation over example databases.
If this is right
- On the BIRD dataset the approach generates more realistic differentiating databases than the version without mined constraints.
- The tool still efficiently finds numerous discrepancies between generated and gold SQL queries that standard test-based evaluation misses.
- The constraint pipeline preserves the original verification speed while improving the practical relevance of the counterexamples.
- The method supplies an open-source implementation that can be reused for other Text-to-SQL evaluation tasks.
Where Pith is reading between the lines
- The same mining-plus-validation pattern could be transferred to other query languages or to checking program equivalence in different domains.
- If the constraint set grows too large, the bounded search may need tighter limits or incremental solving to stay efficient.
- Current Text-to-SQL benchmarks may systematically understate error rates because they lack such constraint-guided test generation.
Load-bearing premise
The mined constraints accurately capture the database properties that matter for distinguishing practically relevant query discrepancies.
What would settle it
Apply SpotIt+ to a collection of query pairs where the mined constraints are known to be inaccurate or incomplete and observe whether the produced differentiating databases cease to be realistic or cease to reveal the expected discrepancies.
Figures




read the original abstract
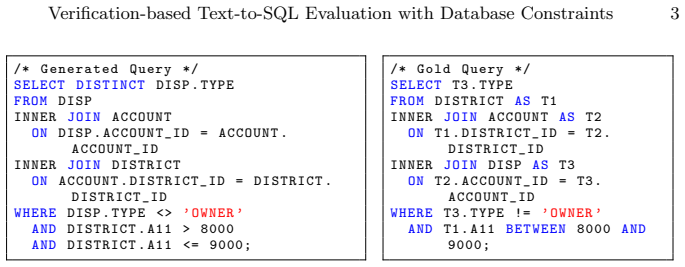
We present SpotIt+, an open-source tool for evaluating Text-to-SQL systems via bounded equivalence verification. Given a generated SQL query and the ground truth, SpotIt+ actively searches for database instances that differentiate the two queries. To ensure that the generated counterexamples reflect practically relevant discrepancies, we introduce a best-effort constraint-mining pipeline that combines rule-based specification mining with LLM-based validation over example databases. Experimental results on the BIRD dataset show that the mined constraints enable SpotIt+ to generate more realistic differentiating databases, while preserving its ability to efficiently uncover numerous discrepancies between generated and gold SQL queries that are missed by standard test-based evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SpotIt+, an open-source tool for evaluating Text-to-SQL systems via bounded equivalence verification. Given a generated SQL query and ground truth, it searches for database instances that differentiate the two. A best-effort constraint-mining pipeline combines rule-based specification mining with LLM-based validation over example databases to ensure counterexamples reflect practically relevant discrepancies. Experiments on the BIRD dataset claim that the mined constraints produce more realistic differentiating databases while preserving efficient discovery of discrepancies missed by standard test-based evaluation.
Significance. If the constraint-mining pipeline produces constraints whose counterexamples are verifiably more realistic and relevant, SpotIt+ would address a core weakness in Text-to-SQL benchmarking by moving beyond fixed test suites. The open-source release and verification-based approach are strengths that support reproducibility. The significance is tempered by the absence of quantitative metrics or independent validation of the pipeline's output quality.
major comments (2)
- [Abstract] Abstract, experimental results paragraph: the claim that mined constraints enable 'more realistic differentiating databases' and 'efficiently uncover numerous discrepancies' is stated without any quantitative details, error bars, ablation studies, or specific counts of additional discrepancies found versus baselines.
- [Constraint Mining Pipeline] Constraint-mining pipeline description: the LLM-based validation step performs consistency checks only over the same example databases used for rule-based mining, with no hold-out set, expert annotation of constraint fidelity, or comparison against BIRD schema documentation. This directly undermines the central claim that the constraints reflect 'practically relevant discrepancies'.
minor comments (1)
- [Abstract] The abstract uses 'best-effort' without defining its scope or known failure modes; a brief characterization would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating planned revisions where appropriate to strengthen the presentation of quantitative results and the description of the constraint-mining pipeline.
read point-by-point responses
-
Referee: [Abstract] Abstract, experimental results paragraph: the claim that mined constraints enable 'more realistic differentiating databases' and 'efficiently uncover numerous discrepancies' is stated without any quantitative details, error bars, ablation studies, or specific counts of additional discrepancies found versus baselines.
Authors: We agree that the abstract would be strengthened by including quantitative support for these claims. In the revised manuscript, we will update the abstract to report specific counts of additional discrepancies uncovered by SpotIt+ with mined constraints compared to the no-constraint baseline (drawing from the experimental results already detailed in Section 5), summarize key ablation findings on the contribution of the rule-based and LLM components, and include error bars from repeated runs where applicable. These additions will be kept concise while providing the requested evidence. revision: yes
-
Referee: [Constraint Mining Pipeline] Constraint-mining pipeline description: the LLM-based validation step performs consistency checks only over the same example databases used for rule-based mining, with no hold-out set, expert annotation of constraint fidelity, or comparison against BIRD schema documentation. This directly undermines the central claim that the constraints reflect 'practically relevant discrepancies'.
Authors: The referee correctly notes a limitation in our pipeline evaluation: the LLM consistency checks use the same example databases as the rule-based mining step, without a hold-out set or expert annotations. We will revise the manuscript to explicitly acknowledge this as a limitation of the best-effort approach, add a comparison of a sample of mined constraints to BIRD schema documentation, and discuss the implications for practical relevance. We maintain that the combination of data-driven rule mining and LLM validation still yields counterexamples exposing meaningful discrepancies (as shown in our qualitative analysis), but we will moderate the strength of the claims in the abstract and Section 4 to reflect the validation scope. revision: partial
Circularity Check
No significant circularity; method is self-contained against external benchmark
full rationale
The paper introduces SpotIt+ as a verification tool whose core value is demonstrated by its ability to surface discrepancies on the independent BIRD dataset. The constraint-mining pipeline is described as best-effort without equations, fitted parameters, or load-bearing self-citations that reduce claims to inputs by construction. Evaluation relies on external data and standard test-based comparison, satisfying the criteria for a non-circular, self-contained presentation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bounded equivalence verification can locate database instances that differentiate two SQL queries
invented entities (1)
-
best-effort constraint-mining pipeline
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SpotIt+ actively searches for database instances that differentiate the two queries... constraint-mining pipeline that combines rule-based specification mining with LLM-based validation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Data-aware candidate selection in NL2SQL translation via small separating instances
A selection technique based on separating instances and provenance outperforms baselines for choosing among 2-3 NL2SQL candidates on a BIRD-DEV subset without consistency scores.
Reference graph
Works this paper leans on
-
[1]
Amazon: Build a text-to-sql solution for data consistency in generative ai using amazon nova (September 2025), https://aws.amazon.com/blogs/machine-lea rning/build-a-text-to-sql-solution-for-data-consistency-in-generativ e-ai-using-amazon-nova/
work page 2025
-
[2]
Amazon Web Services: How msd uses amazon bedrock to translate natural language into sql for complex healthcare databases. https://aws.amazon.com/blogs/m achine-learning/how-merck-uses-amazon-bedrock-to-translate-natural -language-into-sql-for-complex-healthcare-databases/ (2024), accessed: 2025-09-21
work page 2024
-
[3]
BitsAI, T.: Bits ai:scale your teams with autonomous ai agents across monitoring, development, and security (September 2025), https://www.datadoghq.com/prod uct/platform/bits-ai/
work page 2025
-
[4]
arXiv preprint arXiv:2411.00073 (2024)
Cao, Z., Zheng, Y., Fan, Z., Zhang, X., Chen, W., Bai, X.: Rsl-sql: Robust schema linking in text-to-sql generation. arXiv preprint arXiv:2411.00073 (2024)
-
[5]
In: Proceedings of the 2017 ACM International Conference on Management of Data
Chu, S., Li, D., Wang, C., Cheung, A., Suciu, D.: Demonstration of the cosette automated sql prover. In: Proceedings of the 2017 ACM International Conference on Management of Data. pp. 1591–1594 (2017)
work page 2017
-
[6]
Axiomatic Foundations and Algorithms for Deciding Semantic Equivalences of SQL Queries
Chu, S., Murphy, B., Roesch, J., Cheung, A., Suciu, D.: Axiomatic foundations and algorithms for deciding semantic equivalences of sql queries. arXiv preprint arXiv:1802.02229 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [7]
-
[8]
Acm sigplan notices52(6), 510–524 (2017)
Chu, S., Weitz, K., Cheung, A., Suciu, D.: Hottsql: Proving query rewrites with univalent sql semantics. Acm sigplan notices52(6), 510–524 (2017)
work page 2017
-
[9]
Cheaper, Better, Faster, Stronger: Robust Text-to-SQL without Chain-of-Thought or Fine-Tuning
D¨ onder, Y.D., Hommel, D., Wen-Yi, A.W., Mimno, D., Jo, U.E.S.: Cheaper, better, faster, stronger: Robust text-to-sql without chain-of-thought or fine-tuning. arXiv preprint arXiv:2505.14174 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
He, Y., Zhao, P., Wang, X., Wang, Y.: Verieql: Bounded equivalence verification for complex sql queries with integrity constraints. Proc. ACM Program. Lang. 8(OOPSLA1) (Apr 2024). https://doi.org/10.1145/3649849, https://doi.or g/10.1145/3649849
-
[11]
Klopfenstein, R., He, Y., Tremante, A., Wang, Y., Narodytska, N., Wu, H.: Spotit: Evaluating text-to-sql evaluation with formal verification. In: The Fourteenth International Conference on Learning Representations (2026), https://openrevi ew.net/forum?id=iMkvR2ICSE
work page 2026
-
[12]
arXiv preprint arXiv:2411.07763 (2024)
Lei, F., Chen, J., Ye, Y., Cao, R., Shin, D., Su, H., Suo, Z., Gao, H., Hu, W., Yin, P., et al.: Spider 2.0: Evaluating language models on real-world enterprise text-to-sql workflows. arXiv preprint arXiv:2411.07763 (2024)
-
[13]
arXiv preprint arXiv:2502.17248 (2025)
Li, B., Zhang, J., Fan, J., Xu, Y., Chen, C., Tang, N., Luo, Y.: Alpha-sql: Zero-shot text-to-sql using monte carlo tree search. arXiv preprint arXiv:2502.17248 (2025)
-
[14]
arXiv preprint arXiv:2503.02240 (2025)
Li, H., Wu, S., Zhang, X., Huang, X., Zhang, J., Jiang, F., Wang, S., Zhang, T., Chen, J., Shi, R., et al.: Omnisql: Synthesizing high-quality text-to-sql data at scale. arXiv preprint arXiv:2503.02240 (2025)
-
[15]
Li, J., Hui, B., Qu, G., Li, B., Yang, J., Li, B., Wang, B., Qin, B., Cao, R., Geng, R., Huo, N., Zhou, X., Ma, C., Li, G., Chang, K.C., Huang, F., Cheng, R., Li, Y.: BIRD SQ.https://bird-bench.github.io/(2024), accessed: Sep 2025
work page 2024
-
[16]
Sheng, L., Xu, S.S.: Csc-sql: Corrective self-consistency in text-to-sql via reinforce- ment learning. arXiv preprint arXiv:2505.13271 (2025) Verification-based Text-to-SQL Evaluation with Database Constraints 9
-
[17]
arXiv preprint arXiv:2507.22478 (2025)
Sheng, L., Xu, S.S.: Slm-sql: An exploration of small language models for text-to-sql. arXiv preprint arXiv:2507.22478 (2025)
-
[18]
Splunk: Ai assistant in observability cloud (September 2025), https://www.splunk .com/en_us/products/splunk-ai-assistant-in-observability-cloud.html
work page 2025
-
[19]
arXiv preprint arXiv:2405.16755 (2024)
Talaei, S., Pourreza, M., Chang, Y.C., Mirhoseini, A., Saberi, A.: Chess: Contextual harnessing for efficient sql synthesis. arXiv preprint arXiv:2405.16755 (2024)
-
[20]
In: International Conference on Logic for Programming Artificial Intelligence and Reasoning
Veanes, M., Tillmann, N., De Halleux, J.: Qex: Symbolic sql query explorer. In: International Conference on Logic for Programming Artificial Intelligence and Reasoning. pp. 425–446. Springer (2010)
work page 2010
-
[21]
Proceedings of the VLDB Endowment17(11), 3602–3614 (2024)
Wang, S., Pan, S., Cheung, A.: Qed: A powerful query equivalence decider for sql. Proceedings of the VLDB Endowment17(11), 3602–3614 (2024)
work page 2024
-
[22]
Zhou, A., Wang, K., Lu, Z., Shi, W., Luo, S., Qin, Z., Lu, S., Jia, A., Song, L., Zhan, M., Li, H.: Solving challenging math word problems using GPT-4 code interpreter with code-based self-verification. In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/forum?id=c8McWs4Av0
work page 2024
-
[23]
In: 2022 IEEE 38th International Conference on Data Engineering (ICDE)
Zhou, Q., Arulraj, J., Navathe, S.B., Harris, W., Wu, J.: Spes: A symbolic approach to proving query equivalence under bag semantics. In: 2022 IEEE 38th International Conference on Data Engineering (ICDE). pp. 2735–2748. IEEE (2022) 10 A. Tremante et al. A Background Determining whether two SQL queries produce identical results on all possible database in...
work page 2022
-
[24]
Strict boundsuse observed minimum and maximum values [min(c),max (c)], ensuring every current database value satisfies the constraint
-
[25]
For columns where observed minimum is≥0, we enforce a lower bound of 0
Loose boundsapply Tukey’s fence method (k = 3): [Q1−3·IQR, Q 3+3·IQR], accommodating outliers while excluding unrealistic extremes. For columns where observed minimum is≥0, we enforce a lower bound of 0
-
[26]
LLM-generated semantic boundsinfer domain-appropriate ranges from column metadata, observed statistics, and sample values (e.g., ages [0 , 120], percentages [0,100], one-sided bounds [0,∞) for counts). During validation, each range constraint is reviewed and one of these three bounding approaches is selected. In our experiments, the LLM validator chose be...
-
[27]
Extract the complete set of observed valuesV={v 1, . . . , vk}
-
[28]
Generate a candidate constraint:In(c, V). Columns with cardinality > 30 are automatically excluded to prevent over- constraining the counterexample search space. Null Constraints.For columns with zero observed null values, we generate a candidate constraint. The process of filtering primary key constraints occurs during validation. Functional Dependencies...
-
[29]
Computen a =|distinct(c a)|andn ab =|distinct(c a, cb)|
-
[30]
Verify that grouping by ca produces groups with exactly one unique cb value each
-
[31]
Ordering Dependencies.For each pair of numeric columns (c 1, c2):
Generate a candidate constraint:c a →c b. Ordering Dependencies.For each pair of numeric columns (c 1, c2):
-
[32]
Test whetherc 1[i]≤c 2[i] holds for all non-null rows
-
[33]
Test whetherc 1[i]≥c 2[i] holds for all non-null rows
-
[34]
If either relationship holds, generate a candidate constraint. B.2 Implementation Our extraction system is implemented in Python 3.11 and consists of approxi- mately 2,300 lines of code organized into five main modules: –extract constraints LLM.py (∼800 lines): Orchestrates theSpotIt + con- strain extraction pipeline. 12 A. Tremante et al. Table 3: Averag...
-
[35]
6INSERT INTO TEAM VALUES ( -2147483648 , -2147483648 , -2147483647 , ’ HEART OF M I D L O T H I A N ’ , ’ 2 1 4 7 4 8 3 6 4 8 ’) ; 7INSERT INTO TEAM VALUES ( -2147483647 , -2147483648 , -2147483648 , ’ HEART OF M I D L O T H I A N ’ , ’ 2 1 4 7 4 8 3 6 4 8 ’) ; 8CREATE TABLE T E A M _ A T T R I B U T E S ( 9ID INTEGER , T E A M _ F I F A _ A P I _ I D INT...
-
[36]
12INSERT INTO T E A M _ A T T R I B U T E S VALUES ( -2147483648 , -2147483647 , -2147483648 , ’ 2 1 4 7 4 8 3 6 4 8 ’ , NULL , ...) ; 13INSERT INTO T E A M _ A T T R I B U T E S VALUES ( -2147483647 , -2147483647 , -2147483648 , ’ 2 1 4 7 4 8 3 6 4 8 ’ , -2 , ...) ; Fig. 3: Generated Query P , Gold Query Q, andSpotItcounterexample with bound K = 2 for NL...
-
[37]
AS T ; 1-- SpotIt Counterexample - - 2CREATE TABLE BOND ( 3BOND_ID VARCHAR (20) , M O L E C U L E _ I D VARCHAR (20) , B O N D _ T Y P E VARCHAR (20)
-
[38]
5INSERT INTO BOND VALUES ( ’ 2 1 4 7 4 8 3 6 4 8 ’ , ’ 2 1 4 7 4 8 3 6 4 9 ’ , NULL ) ; 6INSERT INTO BOND VALUES ( ’ 2 1 4 7 4 8 3 6 4 9 ’ , ’ 2 1 4 7 4 8 3 6 4 8 ’ , ’ 2 1 4 7 4 8 3 6 4 9 ’) ; Fig. 4: Generated Query P , Gold Query Q, andSpotItcounterexample with boundK= 2 for NL Question:”What is the most common bond type?”. Verification-based Text-to-S...
-
[39]
13INSERT INTO DRIVERS VALUES 14(1 , ’ 2 1 4 7 4 8 3 6 4 8 ’ , 0 , ’ 2 1 4 7 4 8 3 6 4 8 ’ , 15’ 2 1 4 7 4 8 3 6 4 8 ’ , ’ 2 1 4 7 4 8 3 6 4 8 ’ , 16’ 0001 -01 -01 ’ , NULL , ’ 2 1 4 7 4 8 3 6 4 8 ’) ; 17INSERT INTO DRIVERS VALUES 18(0 , ’ 2 1 4 7 4 8 3 6 4 8 ’ , 0 , ’ 2 1 4 7 4 8 3 6 4 8 ’ , 19’ 2 1 4 7 4 8 3 6 4 8 ’ , ’ 2 1 4 7 4 8 3 6 4 8 ’ , 20’ 0001 -...
-
[40]
13INSERT INTO DRIVERS VALUES 14(1 , ’ 2 1 4 7 4 8 3 6 4 8 ’ , 0 , ’ 2 1 4 7 4 8 3 6 4 8 ’ , 15’ 2 1 4 7 4 8 3 6 4 8 ’ , ’ 2 1 4 7 4 8 3 6 4 8 ’ , 16’ 0001 -01 -01 ’ , NULL , ’ 2 1 4 7 4 8 3 6 4 8 ’) ; 17INSERT INTO DRIVERS VALUES 18(2 , ’ 2 1 4 7 4 8 3 6 4 9 ’ , 0 , ’ 2 1 4 7 4 8 3 6 4 8 ’ , 19’ 2 1 4 7 4 8 3 6 4 8 ’ , ’ 2 1 4 7 4 8 3 6 4 9 ’ , 20’ 0001 -...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.