Recognition: 2 theorem links
· Lean TheoremMV-SAM3D: Adaptive Multi-View Fusion for Layout-Aware 3D Generation
Pith reviewed 2026-05-15 12:55 UTC · model grok-4.3
The pith
MV-SAM3D fuses multiple views into physically plausible 3D scenes without any retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MV-SAM3D formulates the combination of multiple views as a Multi-Diffusion process in 3D latent space. It introduces attention-entropy weighting and visibility weighting to fuse information according to each view's reliability. For scenes containing multiple objects, physics-aware optimization enforces collision and contact constraints both while generating and after, which produces arrangements that follow basic physical rules.
What carries the argument
The Multi-Diffusion process in 3D latent space together with adaptive attention-entropy and visibility weighting for fusion, plus physics-aware optimization to enforce collision and contact constraints.
If this is right
- Generated 3D scenes maintain geometric consistency when checked from the original input viewpoints.
- Object placements avoid common errors like interpenetration and floating positions.
- The method works directly on real-world multi-object scenes using only standard benchmarks for validation.
- Performance gains occur in both reconstruction accuracy and layout realism without any model updates.
Where Pith is reading between the lines
- Similar weighting and constraint approaches could be applied to video-based 3D reconstruction for temporal consistency.
- The training-free nature allows quick integration with newer single-view generators as they become available.
- Improved physical realism may make the outputs more suitable for simulation and robotics tasks where object interactions matter.
Load-bearing premise
The attention-entropy and visibility weighting plus the physics optimization will consistently deliver reliable and plausible 3D layouts from any arbitrary collection of input views without adding new errors or needing manual tuning for each scene.
What would settle it
Running the system on a set of views showing two objects that should touch but not overlap, then checking if the output 3D model has the objects penetrating each other or one floating above the surface.
Figures




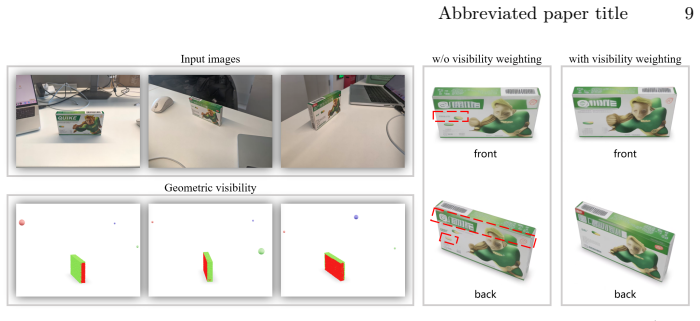
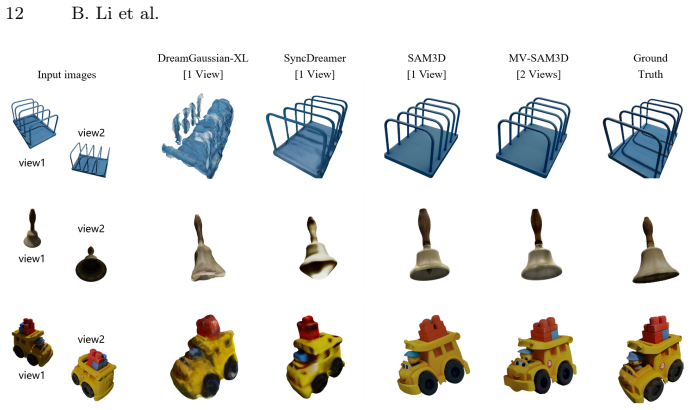

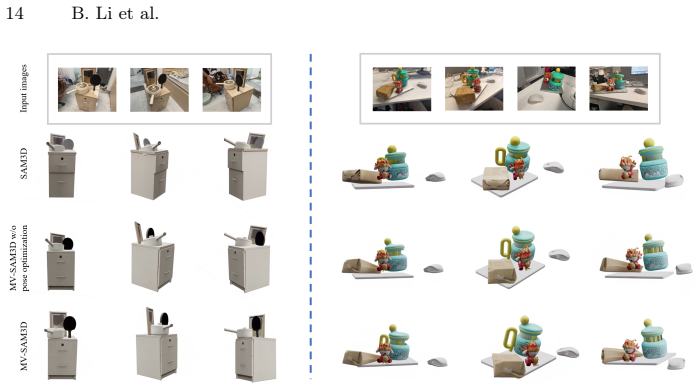
read the original abstract
Recent unified 3D generation models have made remarkable progress in producing high-quality 3D assets from a single image. Notably, layout-aware approaches such as SAM3D can reconstruct multiple objects while preserving their spatial arrangement, opening the door to practical scene-level 3D generation. However, current methods are limited to single-view input and cannot leverage complementary multi-view observations, while independently estimated object poses often lead to physically implausible layouts such as interpenetration and floating artifacts. We present MV-SAM3D, a training-free framework that extends layout-aware 3D generation with multi-view consistency and physical plausibility. We formulate multi-view fusion as a Multi-Diffusion process in 3D latent space and propose two adaptive weighting strategies -- attention-entropy weighting and visibility weighting -- that enable confidence-aware fusion, ensuring each viewpoint contributes according to its local observation reliability. For multi-object composition, we introduce physics-aware optimization that injects collision and contact constraints both during and after generation, yielding physically plausible object arrangements. Experiments on standard benchmarks and real-world multi-object scenes demonstrate significant improvements in reconstruction fidelity and layout plausibility, all without any additional training. Code is available at https://github.com/devinli123/MV-SAM3D.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MV-SAM3D, a training-free framework extending layout-aware 3D generation (e.g., SAM3D) to multi-view inputs. It formulates fusion as Multi-Diffusion in 3D latent space with two adaptive weighting strategies (attention-entropy weighting, where higher entropy receives lower weight, and visibility weighting) for confidence-aware combination of views, plus physics-aware optimization that injects collision and contact constraints during and after generation to produce plausible multi-object layouts. Experiments on standard benchmarks and real-world scenes are claimed to show improvements in reconstruction fidelity and layout plausibility without any additional training.
Significance. If the central claims hold with supporting quantitative evidence, the work would be significant for practical scene-level 3D generation. It directly addresses single-view limitations such as pose-induced implausibilities and lack of cross-view consistency by providing a training-free pipeline that leverages complementary observations and enforces physical constraints. The open availability of code further strengthens potential impact on applications in AR/VR and robotics.
major comments (3)
- [Abstract] Abstract: the claim of 'significant improvements in reconstruction fidelity and layout plausibility' is load-bearing for the central contribution yet provides no quantitative metrics, baseline comparisons, error analysis, or ablation results on the weighting strategies or physics optimization.
- [Method] Method (multi-view fusion section): the Multi-Diffusion formulation in 3D latent space and the precise integration of attention-entropy weighting plus visibility weighting lack explicit equations or derivation; without these it is unclear how the proxies ensure alignment when pose estimates contain errors or view overlap is limited.
- [Experiments] Experiments: no robustness analysis or failure-mode discussion is provided for cases where independent pose estimates are inaccurate, which could cause the entropy/visibility heuristics to overweight conflicting signals and produce artifact-laden latents before physics optimization is applied.
minor comments (1)
- The abstract and method descriptions would benefit from explicit cross-references to any equations defining the weighting functions and the physics constraints.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'significant improvements in reconstruction fidelity and layout plausibility' is load-bearing for the central contribution yet provides no quantitative metrics, baseline comparisons, error analysis, or ablation results on the weighting strategies or physics optimization.
Authors: We agree that the abstract should be supported by concrete numbers. In the revision we will insert key quantitative results (e.g., fidelity gains in PSNR/SSIM and reductions in collision rate versus SAM3D) drawn directly from the experiments section, together with a brief mention of the ablation findings on the weighting and physics terms. revision: yes
-
Referee: [Method] Method (multi-view fusion section): the Multi-Diffusion formulation in 3D latent space and the precise integration of attention-entropy weighting plus visibility weighting lack explicit equations or derivation; without these it is unclear how the proxies ensure alignment when pose estimates contain errors or view overlap is limited.
Authors: The current text describes the weighting strategies at a high level but does not supply the full set of update equations or a derivation. We will add the explicit Multi-Diffusion fusion equation, the definitions of the attention-entropy and visibility weights, and a short derivation showing how the combined weights down-weight inconsistent or low-visibility observations, thereby improving robustness to moderate pose error. revision: yes
-
Referee: [Experiments] Experiments: no robustness analysis or failure-mode discussion is provided for cases where independent pose estimates are inaccurate, which could cause the entropy/visibility heuristics to overweight conflicting signals and produce artifact-laden latents before physics optimization is applied.
Authors: We acknowledge the absence of a dedicated robustness study. We will add a new subsection that (i) quantifies performance under controlled pose noise, (ii) visualizes failure cases where conflicting views produce artifacts, and (iii) demonstrates how the subsequent physics-aware optimization mitigates many of these artifacts. This analysis will be supported by additional quantitative tables and qualitative examples. revision: yes
Circularity Check
No circularity: framework extends prior models via independent heuristics and optimization
full rationale
The paper describes MV-SAM3D as a training-free extension that formulates fusion as multi-diffusion in 3D latent space, applies attention-entropy and visibility weighting heuristics, and adds physics-aware optimization for constraints. No equations, predictions, or central claims reduce by construction to quantities fitted from the same work or to self-citations whose validity depends on the current paper. The method is presented as a composition of existing diffusion processes with new weighting rules and post-processing, with performance claims supported by external benchmark experiments rather than internal redefinitions. This keeps the derivation chain self-contained and non-circular.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate multi-view fusion as a Multi-Diffusion process in 3D latent space and propose two adaptive weighting strategies — attention-entropy weighting and visibility weighting
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
physics-aware optimization that injects collision and contact constraints both during and after generation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Mix3R: Mixing Feed-forward Reconstruction and Generative 3D Priors for Joint Multi-view Aligned 3D Reconstruction and Pose Estimation
Mix3R mixes feed-forward reconstruction and generative 3D priors via Mixture-of-Transformers and overlap-based attention bias to achieve better-aligned 3D shapes and more accurate poses than either approach alone.
Reference graph
Works this paper leans on
- [1]
-
[2]
Bar-Tal, O., Yariv, L., Lipman, Y., Dekel, T.: MultiDiffusion: Fusing diffusion paths for controlled image generation. In: ICML (2023)
work page 2023
-
[3]
SAM 3D: 3Dfy Anything in Images
Chen, X., Chu, F.J., Gleize, P., Liang, K.J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., et al.: SAM 3D: 3Dfy anything in images. arXiv preprint arXiv:2511.16624 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [4]
-
[5]
Advances in Neural Information Processing Systems36, 35799–35813 (2023)
Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., Voleti, V., Gadre, S.Y., et al.: Objaverse-XL: A universe of 10M+ 3D objects. Advances in Neural Information Processing Systems36, 35799–35813 (2023)
work page 2023
-
[6]
Dhariwal, P., Nichol, A.: Diffusion models beat GANs on image synthesis. In: NeurIPS (2021)
work page 2021
-
[7]
Downs, L., Francis, A., Koenig, N., Kinber, B., Hickman, R., Reymann, K., McHugh, T.B., Vanhoucke, V.: Google scanned objects: A high-quality dataset of 3D scanned household items. In: ICRA (2022)
work page 2022
-
[8]
arXiv preprint arXiv:2602.05293 (2026)
Feng, W., Wu, M., Chen, Z., Yang, C., Qin, H., Li, Y., Liu, X., Fan, G., An, Z., Huang, L., et al.: Fast-SAM3D: 3Dfy anything in images but faster. arXiv preprint arXiv:2602.05293 (2026)
- [9]
-
[10]
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: LRM: Large reconstruction model for single image to 3D. In: ICLR (2024)
work page 2024
-
[11]
arXiv preprint arXiv:2501.04689 (2025)
Huang, Z., Boss, M., Vasishta, A., Rehg, J.M., Jampani, V.: SPAR3D: Sta- ble point-aware reconstruction of 3D objects from single images. arXiv preprint arXiv:2501.04689 (2025)
-
[12]
Kong, X., Liu, S., Lyu, X., Taher, M., Qi, X., Davison, A.J.: EscherNet: A gener- ative model for scalable view synthesis. In: CVPR (2024)
work page 2024
-
[13]
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3D with MASt3R. In: ECCV (2024)
work page 2024
-
[14]
Li, W., Liu, J., Yan, H., Chen, R., Liang, Y., Chen, X., Tan, P., Long, X.: Crafts- Man3D: High-fidelity mesh generation with 3D native diffusion and interactive geometry refiner. In: CVPR (2025)
work page 2025
-
[15]
Li, Y., Zou, Z.X., Liu, Z., Wang, D., Liang, Y., Yu, Z., Liu, X., Guo, Y.C., Liang, D., Ouyang, W., et al.: TripoSG: High-fidelity 3D shape synthesis using large-scale rectified flow models. arXiv preprint arXiv:2502.06608 (2025)
-
[16]
Lin, C.H., Gao, J., Tang, L., Takikawa, T., Zeng, X., Huang, X., Kreis, K., Fidler, S., Liu, M.Y., Lin, T.Y.: Magic3D: High-resolution text-to-3D content creation. In: CVPR (2023)
work page 2023
-
[17]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth Anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025) 16 B. Li et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: ICLR (2023)
work page 2023
- [19]
-
[20]
Liu, Y., Lin, C., Zeng, Z., Long, X., Liu, L., Komura, T., Wang, W.: SyncDreamer: Generating multiview-consistent images from a single-view image. In: ICLR (2024)
work page 2024
-
[21]
Long, X., Guo, Y.C., Lin, C., Liu, Y., Dou, Z., Liu, L., Ma, Y., Zhang, S.H., Habermann, M., Theobalt, C., Wang, W.: Wonder3D: Single image to 3D using cross-domain diffusion. In: CVPR (2024)
work page 2024
- [22]
-
[23]
Mur-Artal, R., Montiel, J.M.M., Tardos, J.D.: ORB-SLAM: A versatile and accu- rate monocular SLAM system. IEEE Trans. Robotics31(5), 1147–1163 (2015)
work page 2015
-
[24]
Advances in Neural Information Processing Systems37, 25747–25780 (2024)
Ni, J., Chen, Y., Jing, B., Jiang, N., Wang, B., Dai, B., Li, P., Zhu, Y., Zhu, S.C., Huang, S.: PhyRecon: Physically plausible neural scene reconstruction. Advances in Neural Information Processing Systems37, 25747–25780 (2024)
work page 2024
-
[25]
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: DreamFusion: Text-to-3D using 2D diffusion. In: ICLR (2023)
work page 2023
-
[26]
Schönberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: CVPR (2016)
work page 2016
-
[27]
Tang,J.,Ren,J.,Zhou,H.,Liu,Z.,Zeng,G.:DreamGaussian:GenerativeGaussian splatting for efficient 3D content creation. In: ICLR (2024)
work page 2024
- [28]
- [29]
-
[30]
arXiv preprint arXiv:2405.20343 (2024)
Wu,K.,Fang,J.,Ma,Z.,Wang,W.,Liu,K.,Chen,K.:Unique3D:High-qualityand efficient 3D mesh generation from a single image. arXiv preprint arXiv:2405.20343 (2024)
-
[31]
Wu, Q., Liu, X., Chen, Y., Li, K., Zheng, C., Cai, J., Zheng, J.: ObjectSDF++: Improved object-compositional neural implicit surfaces. In: ICCV (2023)
work page 2023
-
[32]
Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer
Wu, S., Lin, Y., Fang, F., Luo, W., Gong, S.: Direct3D: Scalable image-to-3D generation via 3D latent diffusion transformer. arXiv preprint arXiv:2405.14832 (2024)
-
[33]
Structured 3D Latents for Scalable and Versatile 3D Generation
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: TRELLIS: Structured 3D latents for scalable and versatile 3D generation. arXiv preprint arXiv:2412.01506 (2024)
work page internal anchor Pith review arXiv 2024
-
[34]
Xu, J., Cheng, W., Gao, Y., Wang, X., Gao, S., Shan, Y.: InstantMesh: Efficient 3D mesh generation from a single image with sparse-view large reconstruction models. In: NeurIPS (2024)
work page 2024
-
[35]
arXiv preprint arXiv:2411.18548 (2024)
Yan, H., Zhang, M., Li, Y., Ma, C., Ji, P.: PhyCAGE: Physically plausible compo- sitional 3D asset generation from a single image. arXiv preprint arXiv:2411.18548 (2024)
-
[36]
Yang, J., Sax, A., Liang, K.J., Henaff, M., Tang, H., Cao, A., Chai, J., Meier, F., Feiszli, M.: Fast3R: Towards 3D reconstruction of 1000+ images in one forward pass. In: CVPR (2025)
work page 2025
- [37]
- [38]
-
[39]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zhao, Z., Lai, Z., Lin, Q., et al.: Hunyuan3D 2.0: Scaling diffusion models for high resolution textured 3D assets generation. arXiv preprint arXiv:2501.12202 (2025) Abbreviated paper title 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Zhou, X., Ran, X., Xiong, Y., He, J., Lin, Z., Wang, Y., Sun, D., Yang, M.H.: GALA3D: Towards text-to-3D complex scene generation via layout-guided gener- ative Gaussian splatting. In: ICML (2024)
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.