Recognition: 2 theorem links
· Lean TheoremGUIDE: Interpretable GUI Agent Evaluation via Hierarchical Diagnosis
Pith reviewed 2026-05-10 19:20 UTC · model grok-4.3
The pith
A hierarchical three-stage process evaluates GUI agent trajectories more accurately and interpretably than single holistic judgments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
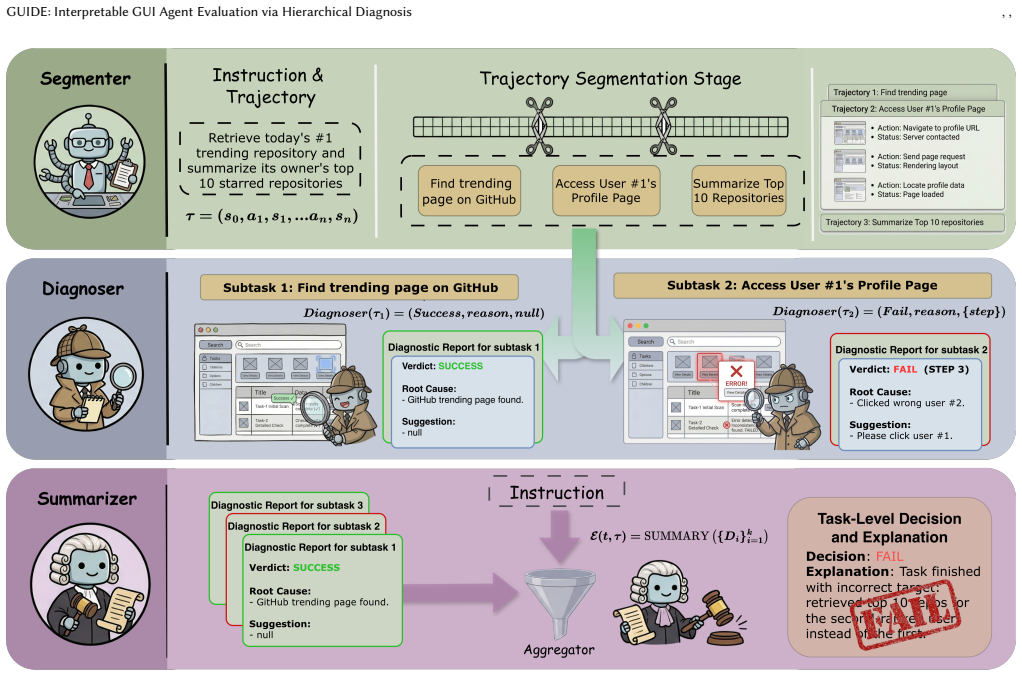
The paper establishes that decomposing trajectory assessment into Trajectory Segmentation, Subtask Diagnosis, and Overall Summary allows for accurate evaluation on bounded segments, mitigating context overload, and generating structured diagnostic reports with corrective recommendations that inform agent improvement.
What carries the argument
The key machinery is the hierarchical diagnosis pipeline that partitions trajectories into subtask units, evaluates them individually in context, and aggregates the results.
Load-bearing premise
That trajectories can be accurately segmented into semantically coherent subtasks and that subtask verdicts can be reliably aggregated without distorting the overall assessment.
What would settle it
Observing cases where human evaluators disagree with GUIDE's overall summary after subtask aggregation, or where segmentation misses critical transitions in the trajectory.
Figures


read the original abstract
Evaluating GUI agents presents a distinct challenge: trajectories are long, visually grounded, and open-ended, yet evaluation must be both accurate and interpretable. Existing approaches typically apply a single holistic judgment over the entire action-observation sequence-a strategy that proves unreliable on long-horizon tasks and yields binary verdicts offering no insight into where or why an agent fails. This opacity limits the utility of evaluation as a diagnostic tool for agent development. We introduce GUIDE (GUI Understanding and Interpretable Diagnostic Evaluation), a framework that decomposes trajectory assessment into three sequential stages mirroring the compositional structure of GUI tasks. Trajectory Segmentation partitions the full trace into semantically coherent subtask units. Subtask Diagnosis evaluates each unit in context, assigning a completion verdict and generating a structured error analysis with corrective recommendations. Overall Summary aggregates per-subtask diagnoses into a task-level judgment. By operating on bounded subtask segments rather than full trajectories, GUIDE mitigates the context overload that degrades existing evaluators as task complexity grows. We validate GUIDE on three benchmarks: an industrial e-commerce dataset of 932 trajectories, AGENTREWARDBENCH spanning five web agent tasks with 1302 trajectories, and AndroidBench for mobile device control. Across all settings, GUIDE substantially outperforms existing evaluators-achieving up to 5.35 percentage points higher accuracy than the strongest baseline-while producing structured diagnostic reports that directly inform agent improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GUIDE, a three-stage hierarchical framework for evaluating GUI agents on long, visually grounded trajectories. It decomposes assessment into Trajectory Segmentation (partitioning into semantically coherent subtasks), Subtask Diagnosis (per-unit completion verdicts plus structured error analysis and recommendations), and Overall Summary (aggregation to task-level judgment). The central claim is that operating on bounded segments mitigates context overload, yielding up to 5.35 percentage points higher accuracy than the strongest baseline across three benchmarks—an industrial e-commerce set (932 trajectories), AGENTREWARDBENCH (1302 trajectories), and AndroidBench—while producing interpretable diagnostic reports that aid agent improvement.
Significance. If the performance gains and diagnostic utility are robustly supported, GUIDE would advance interpretable evaluation for open-ended GUI agents by turning opaque holistic judgments into actionable, subtask-level feedback. The compositional mirroring of GUI task structure is a conceptually sound response to the limitations of single-pass evaluators on long-horizon tasks. No machine-checked proofs or parameter-free derivations are present, but the emphasis on structured reports offers a falsifiable path for future agent improvement studies.
major comments (3)
- [Abstract] Abstract: The claim that GUIDE 'substantially outperforms existing evaluators—achieving up to 5.35 percentage points higher accuracy' is load-bearing for the paper's contribution, yet the manuscript supplies no information on baseline implementations, prompt templates, statistical testing (e.g., significance of the 5.35 pp delta), or variance across runs. Without these, the accuracy lift cannot be confidently attributed to the hierarchical stages rather than implementation differences.
- [Trajectory Segmentation stage] Trajectory Segmentation stage (described in the abstract and presumably §3): This step is presented as reliably producing 'semantically coherent subtask units' whose diagnoses aggregate faithfully, but no quantitative validation is reported—boundary precision/recall, human inter-annotator agreement, or ablation removing segmentation. The skeptic's concern is warranted here; if segmentation boundaries are noisy or break causal context, both the accuracy gains and the 'structured diagnostic reports' lose grounding, directly undermining the central claim that bounded segments mitigate context overload.
- [Subtask Diagnosis and Overall Summary stages] Subtask Diagnosis and Overall Summary stages (abstract): The paper asserts that per-subtask verdicts can be aggregated without losing long-range context, yet no evidence is given on how aggregation handles conflicting subtask outcomes or on inter-annotator agreement for the generated error analyses and recommendations. This is required to support the interpretability advantage over binary holistic verdicts.
minor comments (2)
- [Abstract] Abstract: The three benchmarks are named but their task distributions and trajectory lengths are not summarized; adding a short table or sentence would clarify the scope of the claimed gains.
- The manuscript should explicitly state whether the segmentation and diagnosis stages use the same LLM backbone or different ones, as this affects reproducibility of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas where additional empirical details and validation would strengthen the paper's claims. We address each major comment below and will incorporate the suggested revisions into the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that GUIDE 'substantially outperforms existing evaluators—achieving up to 5.35 percentage points higher accuracy' is load-bearing for the paper's contribution, yet the manuscript supplies no information on baseline implementations, prompt templates, statistical testing (e.g., significance of the 5.35 pp delta), or variance across runs. Without these, the accuracy lift cannot be confidently attributed to the hierarchical stages rather than implementation differences.
Authors: We agree that the performance claim in the abstract requires supporting methodological details to attribute gains specifically to the hierarchical design. The experiments section of the manuscript describes the three benchmarks and baseline evaluators, but we will revise to add a dedicated paragraph (or appendix) explicitly listing baseline implementations, the full prompt templates used for both GUIDE and baselines, accuracy results with standard deviations across multiple runs, and statistical significance tests (e.g., McNemar's test or bootstrap confidence intervals) for the reported deltas including the 5.35 pp figure. revision: yes
-
Referee: [Trajectory Segmentation stage] Trajectory Segmentation stage (described in the abstract and presumably §3): This step is presented as reliably producing 'semantically coherent subtask units' whose diagnoses aggregate faithfully, but no quantitative validation is reported—boundary precision/recall, human inter-annotator agreement, or ablation removing segmentation. The skeptic's concern is warranted here; if segmentation boundaries are noisy or break causal context, both the accuracy gains and the 'structured diagnostic reports' lose grounding, directly undermining the central claim that bounded segments mitigate context overload.
Authors: We acknowledge that direct quantitative validation of the segmentation stage is necessary to ground the claim that bounded segments reduce context overload. While end-to-end accuracy improvements and report quality offer indirect support, we will add the requested analyses in the revision: boundary precision/recall against human-annotated subtask boundaries on a sampled subset of trajectories from each benchmark, inter-annotator agreement statistics for those boundaries, and an ablation that disables segmentation (replacing it with holistic evaluation) to isolate its contribution to accuracy and diagnostic quality. revision: yes
-
Referee: [Subtask Diagnosis and Overall Summary stages] Subtask Diagnosis and Overall Summary stages (abstract): The paper asserts that per-subtask verdicts can be aggregated without losing long-range context, yet no evidence is given on how aggregation handles conflicting subtask outcomes or on inter-annotator agreement for the generated error analyses and recommendations. This is required to support the interpretability advantage over binary holistic verdicts.
Authors: We agree that explicit description of the aggregation procedure and validation of the diagnostic outputs are required to demonstrate the interpretability advantage. In the revised manuscript we will expand the Overall Summary stage description to detail the aggregation rules, including the mechanism for resolving conflicting subtask verdicts (e.g., priority-weighted voting or duration-based weighting). We will also add a human evaluation study reporting inter-annotator agreement on the usefulness and accuracy of the structured error analyses and recommendations, with direct comparison to holistic baseline outputs. revision: yes
Circularity Check
No circularity: procedural framework with independent empirical validation
full rationale
The paper presents GUIDE as a three-stage procedural method (Trajectory Segmentation, Subtask Diagnosis, Overall Summary) for decomposing GUI trajectory evaluation. No equations, fitted parameters, predictions, or self-referential definitions appear in the provided text. Performance claims rest on direct empirical comparison against baselines on three external benchmarks rather than any derivation that reduces to its own inputs by construction. The method is introduced as an independent framework without load-bearing self-citations or ansatzes smuggled from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GUI tasks possess a compositional structure that can be partitioned into semantically coherent subtask units
invented entities (2)
-
Trajectory Segmentation stage
no independent evidence
-
Subtask Diagnosis stage
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearTrajectory Segmentation partitions the full trace into semantically coherent subtask units. Subtask Diagnosis evaluates each unit in context... Overall Summary aggregates per-subtask diagnoses
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearBy operating on bounded subtask segments rather than full trajectories, GUIDE mitigates the context overload
Forward citations
Cited by 1 Pith paper
-
Securing Computer-Use Agents: A Unified Architecture-Lifecycle Framework for Deployment-Grounded Reliability
The paper develops a unified framework that organizes computer-use agent reliability around perception-decision-execution layers and creation-deployment-operation-maintenance stages to map security and alignment inter...
Reference graph
Works this paper leans on
-
[1]
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Haus- man, et al . 2022. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691(2022)
work page internal anchor Pith review arXiv 2022
-
[2]
Anthropic. 2024. Computer Use. (2024). https://docs.anthropic.com/en/docs/ agents-and-tools/computer-use
2024
-
[3]
Roshita Bhonsle, Rishav Dutta, Sneha Vavilapalli, Harsh Seth, Abubakarr Jaye, Yapei Chang, Mukund Rungta, Emmanuel Aboah Boateng, Sadid Hasan, Ehi Nosakhare, et al. 2025. Auto-Eval Judge: Towards a General Agentic Framework for Task Completion Evaluation.arXiv preprint arXiv:2508.05508(2025)
-
[4]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. 2023. Mind2web: Towards a generalist agent for the web. Advances in Neural Information Processing Systems36 (2023), 28091–28114
2023
-
[5]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. 2024. Webvoyager: Building an end-to-end web agent with large multimodal models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 6864–6890
2024
-
[6]
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. 2025. Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 32779–32798
2025
-
[7]
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. 2024. Vi- sualwebarena: Evaluating multimodal agents on realistic visual web tasks. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 881–905
2024
- [8]
-
[9]
Xing Han Lù, Amirhossein Kazemnejad, Nicholas Meade, Arkil Patel, Dongchan Shin, Alejandra Zambrano, Karolina Stańczak, Peter Shaw, Christopher J Pal, and Siva Reddy. 2025. Agentrewardbench: Evaluating automatic evaluations of web agent trajectories.arXiv preprint arXiv:2504.08942(2025)
-
[10]
Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhen- zhong Lan, Lingpeng Kong, and Junxian He. 2024. Agentboard: An analytical evaluation board of multi-turn llm agents.Advances in neural information pro- cessing systems37 (2024), 74325–74362
2024
-
[11]
OpenAI. 2025. Operator. (2025). https://openai.com/operator. GUIDE: Interpretable GUI Agent Evaluation via Hierarchical Diagnosis , ,
2025
- [12]
-
[13]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology. 1–22
2023
- [14]
-
[15]
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lilli- crap. 2023. Androidinthewild: A large-scale dataset for android device control. Advances in Neural Information Processing Systems36 (2023), 59708–59728
2023
-
[16]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in neural information processing systems36 (2023), 8634–8652
2023
-
[17]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. 2023. Plan-and-solve prompting: Improving zero-shot chain- of-thought reasoning by large language models. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers). 2609–2634
2023
-
[19]
Zihao Wang, Shaofei Cai, Guanzhou Chen, Anji Liu, Xiaojian Ma, and Yitao Liang
- [20]
- [21]
-
[22]
Qinzhuo Wu, Pengzhi Gao, Wei Liu, and Jian Luan. 2025. Backtrackagent: Enhanc- ing gui agent with error detection and backtracking mechanism. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 4250–4272
2025
- [23]
-
[24]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al . 2024. Os- world: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems37 (2024), 52040–52094
2024
- [25]
-
[26]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems36 (2023), 11809–11822
2023
- [27]
-
[28]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623
2023
-
[29]
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. 2023. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854(2023)
work page internal anchor Pith review arXiv 2023
- [30]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.