PatchRecall: Patch-Driven Retrieval for Automated Program Repair
Pith reviewed 2026-05-10 16:21 UTC · model grok-4.3
The pith
A hybrid retrieval method for automated program repair combines matching the current bug report to the codebase with using similar past bugs to find relevant files, achieving higher recall at similar file counts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
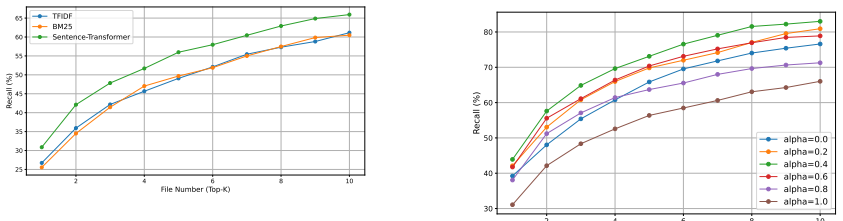
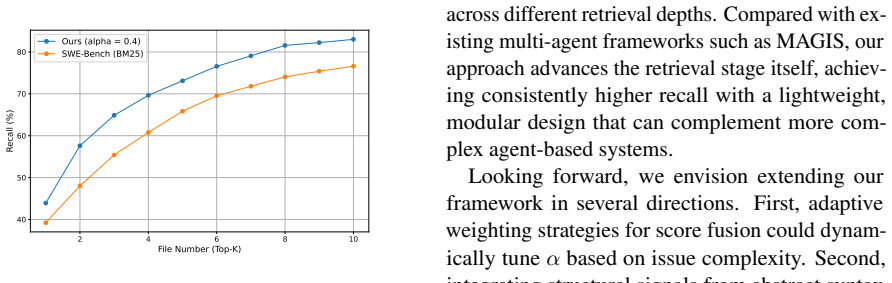
PatchRecall is a hybrid retrieval approach that merges results from codebase retrieval, where the issue description is matched against the codebase to surface relevant files, and history-based retrieval, where similar past issues are used to identify edited files. Candidate files from both strategies are merged and reranked to produce the final set. Experiments on SWE-Bench demonstrate that this yields higher recall without a significant increase in the number of retrieved files, enabling more effective automated program repair.
What carries the argument
The hybrid strategy of merging and reranking candidates from issue-to-codebase matching and past-issue-to-edited-files lookup.
If this is right
- Relevant files for a bug fix are more likely to be included in the retrieval set for the repair process.
- The number of files passed downstream stays low, which limits noise and keeps the repair step efficient.
- Existing APR pipelines can adopt the merged retrieval step to improve their success rates on benchmarks.
- The complementarity of direct matching and historical patterns can be reused for other file-identification tasks in software engineering.
Where Pith is reading between the lines
- The same merging pattern could apply to related tasks such as test-case selection or change-impact analysis where identifying the right files matters.
- If the gains hold when the history of past issues is limited or drawn from different projects, the method would require less project-specific data.
- The reranking step could be replaced or augmented by a learned model that scores candidates based on repair outcomes rather than simple heuristics.
Load-bearing premise
That the two retrieval strategies are sufficiently complementary and that simple merging plus reranking will consistently produce a concise yet high-recall set across diverse issues and codebases.
What would settle it
Running PatchRecall on SWE-Bench or a similar benchmark and finding that it does not increase recall over either strategy alone, or that it requires substantially more files to reach the reported recall levels.
Figures



read the original abstract
Retrieving the correct set of files from a large codebase is a crucial step in Automated Program Repair (APR). High recall is necessary to ensure that the relevant files are included, but simply increasing the number of retrieved files introduces noise and degrades efficiency. To address this tradeoff, we propose PatchRecall, a hybrid retrieval approach that balances recall with conciseness. Our method combines two complementary strategies: (1) codebase retrieval, where the current issue description is matched against the codebase to surface potentially relevant files, and (2) history-based retrieval, where similar past issues are leveraged to identify edited files as candidate targets. Candidate files from both strategies are merged and reranked to produce the final retrieval set. Experiments on SWE-Bench demonstrate that PatchRecall achieves higher recall without significantly increasing retrieved file count, enabling more effective APR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PatchRecall, a hybrid retrieval approach for Automated Program Repair (APR) that combines (1) codebase retrieval matching the issue description to source files and (2) history-based retrieval that identifies files edited in similar past issues. Candidate files from both are merged and reranked to produce a concise, high-recall set. The central claim is that experiments on SWE-Bench show this yields higher recall than baselines without substantially increasing the number of retrieved files, thereby improving downstream APR effectiveness.
Significance. If the empirical claims hold after proper validation, the hybrid design could meaningfully advance APR by addressing the recall-efficiency tradeoff in file retrieval, a critical early step in repair pipelines. The explicit use of historical patch data alongside static search is a practical idea that may generalize to other retrieval-augmented software engineering tasks. However, the current absence of quantitative results, baselines, and ablations substantially limits the assessed significance.
major comments (3)
- [Experimental evaluation] Experimental evaluation section: The abstract asserts higher recall on SWE-Bench without supplying any quantitative metrics (e.g., recall@k values), baseline comparisons (pure codebase retrieval, history-only, or standard IR methods), statistical details, or ablation results. This omission makes the central performance claim impossible to evaluate and prevents determining whether gains arise from the hybrid design.
- [§3.1–§3.3] Method sections (§3.1–§3.3): No ablation studies compare the hybrid merge+rerank against the individual strategies. Without such breakdowns it is impossible to confirm the claimed complementarity or to isolate whether the reranking step actually preserves recall while controlling file count.
- [§3.2] §3.2 History-based retrieval and reranking: The similarity metric used to retrieve similar past issues and the features employed in the subsequent reranking step are not described. These details are load-bearing for reproducibility and for assessing why the two strategies are complementary.
minor comments (2)
- [Abstract] Abstract: Including at least one concrete performance number (e.g., recall improvement or average file count) would strengthen the summary of results.
- Notation and terminology: Ensure consistent use of terms such as “recall” and “file count” across sections; define any non-standard acronyms on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify gaps in the current manuscript that prevent full evaluation of our claims. We will revise to provide the requested quantitative results, ablations, and methodological details.
read point-by-point responses
-
Referee: [Experimental evaluation] Experimental evaluation section: The abstract asserts higher recall on SWE-Bench without supplying any quantitative metrics (e.g., recall@k values), baseline comparisons (pure codebase retrieval, history-only, or standard IR methods), statistical details, or ablation results. This omission makes the central performance claim impossible to evaluate and prevents determining whether gains arise from the hybrid design.
Authors: We agree that the current manuscript does not include the supporting quantitative details. In the revision we will expand the experimental evaluation section with recall@k results (for multiple k) on SWE-Bench, direct comparisons to codebase-only retrieval, history-only retrieval, and standard IR baselines such as BM25, plus statistical significance tests. Ablation results will also be added to isolate the hybrid contribution. revision: yes
-
Referee: [§3.1–§3.3] Method sections (§3.1–§3.3): No ablation studies compare the hybrid merge+rerank against the individual strategies. Without such breakdowns it is impossible to confirm the claimed complementarity or to isolate whether the reranking step actually preserves recall while controlling file count.
Authors: We concur that ablations are required. The revised manuscript will include a new subsection presenting results for (1) codebase retrieval alone, (2) history-based retrieval alone, (3) merge without reranking, and (4) the full hybrid approach. These will report both recall and average retrieved file count to demonstrate complementarity and the effect of reranking. revision: yes
-
Referee: [§3.2] §3.2 History-based retrieval and reranking: The similarity metric used to retrieve similar past issues and the features employed in the subsequent reranking step are not described. These details are load-bearing for reproducibility and for assessing why the two strategies are complementary.
Authors: We apologize for the missing description. The revised §3.2 will specify that past-issue similarity is computed via cosine similarity over TF-IDF vectors of issue descriptions, and that reranking combines historical edit frequency, semantic similarity to the current issue, and file size using a weighted linear score. Exact formulas, hyperparameters, and pseudocode will be provided. revision: yes
Circularity Check
No circularity: purely empirical hybrid retrieval method
full rationale
The paper describes a hybrid retrieval approach combining codebase matching and history-based retrieval, followed by merging and reranking, then reports experimental results on SWE-Bench. No equations, derivations, fitted parameters presented as predictions, or self-citations appear as load-bearing steps in the provided abstract or description. The central claims rest on external benchmark outcomes rather than reducing to internal definitions or prior self-work by construction. This is a standard empirical systems paper with no detectable circularity patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
RepoMirage: Probing Repository Context Reasoning in Code Agents with Perturbations
RepoMirage uses semantics-preserving perturbations on SWE-Bench to show code agents lack repository context reasoning, with performance falling sharply on extended structure tasks, and introduces RepoAnchor as a struc...
Reference graph
Works this paper leans on
-
[1]
Jacob Austin et al. 2021. Program synthesis with large language models. arXiv preprint arXiv:2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Tegawend \' e F. Bissyand \' e , David Lo, Lingxiao Jiang, Laurent R \' e veill \` e re, Jacques Klein, and Yves Le Traon. 2013. https://doi.org/10.1109/ISSRE.2013.6698918 Got issues? who cares about it? A large scale investigation of issue trackers from github . In IEEE 24th International Symposium on Software Reliability Engineering, ISSRE 2013, Pasaden...
-
[3]
Mark Chen et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [4]
-
[5]
Django Software Foundation. 2024. \#30255 (docutils reports an error rendering view docstring when the first line is not empty). https://code.djangoproject.com/ticket/30255
work page 2024
-
[6]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez et al. 2023. Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F. Liu et al. 2023. Lost in the middle: How language models use long contexts. arXiv preprint arXiv:2307.03172
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Nils Reimers. 2021. all-mpnet-base-v2. https://huggingface.co/sentence-transformers/all-mpnet-base-v2
work page 2021
-
[9]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing
work page 2019
-
[10]
Stephen Robertson, Hugo Zaragoza, et al. 2009. The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends in Information Retrieval , 3(4):333--389
work page 2009
-
[11]
Gerard Salton and Chris Buckley. 1988. Term-weighting approaches in automatic text retrieval. Information Processing & Management, 24(5):513--523
work page 1988
-
[12]
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. 2020. Mpnet: Masked and permuted pre-training for language understanding. In Advances in Neural Information Processing Systems
work page 2020
-
[13]
Wei Tao et al. 2024. Magis: Llm-based multi-agent framework for github issue resolution. In Advances in Neural Information Processing Systems, volume 37, pages 51963--51993
work page 2024
-
[14]
Yunlong Zhang, Junqiang Chen, Xiang Liu, Zhengzi Wu, and Qing Wang. 2024. Trae: Trajectory-based automated program repair. In Proceedings of the 46th International Conference on Software Engineering, pages 1--13. ACM
work page 2024
-
[15]
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[16]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.