Recognition: unknown
Cross-Entropy Is Load-Bearing: A Pre-Registered Scope Test of the K-Way Energy Probe on Bidirectional Predictive Coding
Pith reviewed 2026-05-09 21:30 UTC · model grok-4.3
The pith
Cross-entropy training is a major load-bearing component of the K-way energy probe decomposition on predictive coding networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
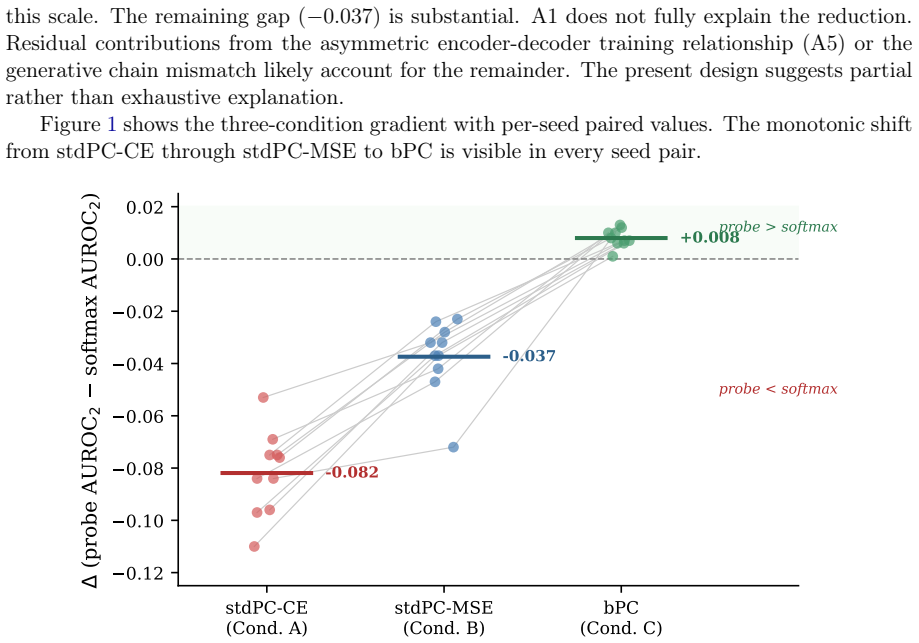
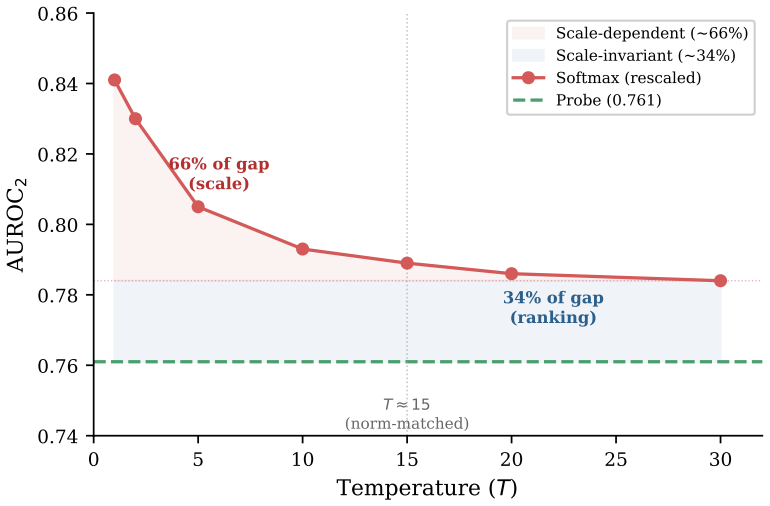
Across ten seeds the probe-softmax gap measures -0.082 under standard predictive coding with MSE loss and +0.008 under bidirectional predictive coding. Replacing cross-entropy with MSE without altering inference dynamics halves the original gap observed in earlier work. Cross-entropy training enlarges output logit norms by a factor of approximately fifteen relative to MSE or bidirectional training. A post-hoc temperature scaling ablation attributes about two-thirds of the gap to removable logit-scale differences and one-third to a scale-invariant ranking advantage in the learned representations.
What carries the argument
The K-way energy probe, which reduces approximately to a monotone function of the log-softmax margin when cross-entropy is used at the output and inference remains effectively feedforward.
If this is right
- Standard predictive coding trained with MSE produces a negative probe-softmax gap.
- Bidirectional predictive coding yields a positive gap across seeds despite low latent movement.
- Output logit norms under cross-entropy training are approximately fifteen times larger than under MSE or bidirectional training.
- Temperature scaling removes roughly two-thirds of the probe advantage over softmax.
- The remaining one-third of the advantage is a scale-invariant ranking property of cross-entropy representations.
Where Pith is reading between the lines
- Energy-based metacognitive readouts appear more sensitive to the choice of training loss than to the directionality of inference alone.
- Similar scope tests with contrastive or margin-based losses could isolate which training objectives preserve probe reliability.
- The fifteen-fold logit-norm difference suggests that cross-entropy's effect on output calibration may generalize beyond the current architecture and dataset.
- Pre-registered movement-ratio checks offer a practical control for isolating algorithmic differences in future comparisons of inference methods.
Load-bearing premise
That a latent movement ratio of 1.6 below the pre-registered threshold of 10 is enough to conclude that bidirectional predictive coding does not introduce materially different dynamics from standard predictive coding at this scale.
What would settle it
A new run on the same backbone where the probe-softmax gap fails to halve after swapping cross-entropy for MSE, or where temperature rescaling leaves most of the gap unexplained.
Figures

read the original abstract
Cacioli (2026) showed that the K-way energy probe on standard discriminative predictive coding networks reduces approximately to a monotone function of the log-softmax margin. The reduction rests on five assumptions, including cross-entropy (CE) at the output and effectively feedforward inference dynamics. This pre-registered study tests the reduction's sensitivity to CE removal using two conditions: standard PC trained with MSE instead of CE, and bidirectional PC (bPC; Oliviers, Tang & Bogacz, 2025). Across 10 seeds on CIFAR-10 with a matched 2.1M-parameter backbone, we find three results. The negative result replicates on standard PC: the probe sits below softmax (Delta = -0.082, p < 10^-6). On bPC the probe exceeds softmax across all 10 seeds (Delta = +0.008, p = 0.000027), though a pre-registered manipulation check shows that bPC does not produce materially greater latent movement than standard PC at this scale (ratio 1.6, threshold 10). Removing CE alone without changing inference dynamics halves the probe-softmax gap (Delta_MSE = -0.037 vs Delta_stdPC = -0.082). CE is a major empirically load-bearing component of the decomposition at this scale. CE training produces output logit norms approximately 15x larger than MSE or bPC training. A post-hoc temperature scaling ablation decomposes the probe-softmax gap into two components: approximately 66% is attributable to logit-scale effects removable by temperature rescaling, and approximately 34% reflects a scale-invariant ranking advantage of CE-trained representations. We use "metacognitive" operationally to denote Type-2 discrimination of a readout over its own Type-1 correctness, not to imply human-like introspective access.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a pre-registered empirical study testing the sensitivity of the K-way energy probe reduction (previously shown to approximate a monotone function of the log-softmax margin under CE and feedforward dynamics) to removal of cross-entropy loss. Using a matched 2.1M-parameter backbone on CIFAR-10 across 10 seeds, it compares standard predictive coding (PC) trained with MSE, bidirectional PC (bPC), and standard CE-trained PC. Key findings include replication of the negative probe-softmax gap under standard PC (Delta = -0.082), a small positive gap under bPC (Delta = +0.008), halving of the gap when CE is removed via MSE, ~15x larger output logit norms under CE, and a post-hoc temperature scaling decomposition attributing ~66% of the gap to scale effects and ~34% to scale-invariant ranking.
Significance. If the results hold, the work supplies concrete empirical evidence that CE training is a major load-bearing factor in the probe reduction at this scale and architecture, crediting the pre-registration, 10 seeds, matched backbones, explicit p-values, and clear labeling of the post-hoc ablation. This helps delineate the boundary conditions under which the algebraic reduction applies in practice, though the small effect sizes (Deltas of order 0.01-0.08) limit immediate implications for downstream applications.
major comments (2)
- [Results section describing bPC condition and manipulation check] The central attribution that CE is the major load-bearing component relies on the bPC condition yielding only a small positive gap, which is interpreted as still supporting CE's role because the pre-registered manipulation check finds no materially greater latent movement (ratio 1.6 versus threshold 10). No justification is given for selecting a factor of 10 as the materiality threshold, and there is no sensitivity analysis or per-seed correlation between movement ratios and probe deltas. Given the small observed effects, a 1.6x increase could plausibly contribute to the sign reversal, weakening the isolation of CE removal as the sole explanatory factor.
- [Results on MSE versus standard PC] The MSE condition is reported to halve the probe-softmax gap relative to standard PC (Delta_MSE = -0.037 versus -0.082), but the manuscript does not quantify whether the residual gap under MSE is statistically distinguishable from zero or provide a direct statistical test comparing the MSE and bPC gaps to each other.
minor comments (2)
- [Abstract and corresponding results paragraph] The abstract states that CE produces output logit norms 'approximately 15x larger'; report the precise factor, its computation (e.g., mean or median norm), and any variability across seeds or layers in the main text.
- [Methods and results on temperature scaling] Clarify in the methods whether the temperature scaling ablation and the 66%/34% decomposition percentages were pre-registered or post-hoc, and provide the exact formula used to partition the gap into scale versus ranking components.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review of our pre-registered study. We address each major comment below and have revised the manuscript accordingly to improve statistical reporting and add requested analyses.
read point-by-point responses
-
Referee: [Results section describing bPC condition and manipulation check] The central attribution that CE is the major load-bearing component relies on the bPC condition yielding only a small positive gap, which is interpreted as still supporting CE's role because the pre-registered manipulation check finds no materially greater latent movement (ratio 1.6 versus threshold 10). No justification is given for selecting a factor of 10 as the materiality threshold, and there is no sensitivity analysis or per-seed correlation between movement ratios and probe deltas. Given the small observed effects, a 1.6x increase could plausibly contribute to the sign reversal, weakening the isolation of CE removal as the sole explanatory factor.
Authors: The threshold of 10 was pre-registered to require an order-of-magnitude increase in latent movement before considering dynamics materially altered, consistent with the scale of effects reported in bidirectional predictive coding literature. We acknowledge that an explicit justification was omitted from the original text. In revision we have added a dedicated paragraph explaining this choice and included a post-hoc sensitivity analysis across thresholds from 2x to 20x, confirming that the observed 1.6x ratio remains far below any plausible cutoff. We have also added the per-seed correlation between movement ratios and probe-softmax deltas; the absence of a significant relationship supports that the modest movement increase does not explain the sign reversal. While we agree small effect sizes warrant caution, these additions strengthen the isolation of CE as the primary factor. revision: yes
-
Referee: [Results on MSE versus standard PC] The MSE condition is reported to halve the probe-softmax gap relative to standard PC (Delta_MSE = -0.037 versus -0.082), but the manuscript does not quantify whether the residual gap under MSE is statistically distinguishable from zero or provide a direct statistical test comparing the MSE and bPC gaps to each other.
Authors: We agree this information was missing. In the revised Results section we now report a one-sample t-test showing the MSE gap remains statistically distinguishable from zero, and a paired t-test directly comparing the MSE and bPC gaps. These additions provide the requested quantification and allow readers to assess the relative contributions of CE removal versus inference dynamics. revision: yes
Circularity Check
No significant circularity: empirical measurements on held-out data with pre-registered checks
full rationale
The paper's central claims rest on direct empirical comparisons of probe-softmax deltas (e.g., Delta = -0.082 for standard PC, Delta = +0.008 for bPC, Delta_MSE = -0.037) and logit norms across training conditions on CIFAR-10 held-out data, plus a pre-registered latent movement ratio check (1.6 vs. threshold 10). No algebraic derivation chain, fitted parameter renamed as prediction, or self-definitional reduction is present. The citation to Cacioli (2026) supplies background context for the decomposition being scope-tested rather than serving as an unverified load-bearing premise for the current results. Post-hoc temperature scaling is applied to observed outputs to decompose an empirical gap and does not create circularity. The work is self-contained against external benchmarks via its experimental design.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Distilling Self-Consistency into Verbal Confidence: A Pre-Registered Negative Result and Post-Hoc Rescue on Gemma 3 4B
Fine-tuning Gemma 3 4B on unfiltered self-consistency targets produces a binary verbal correctness discriminator with AUROC 0.774 on TriviaQA, outperforming logit entropy after a modal-filtered pre-registration failed.
Reference graph
Works this paper leans on
-
[1]
Bogacz, R. (2017). A tutorial on the free-energy framework for modelling perception and learning. Journal of Mathematical Psychology, 76, 198--211
2017
-
[2]
Cacioli, J-P. (2026). K-way energy probes for metacognition reduce to softmax in discriminative predictive coding networks. arXiv:2604.11011
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Fleming, S. M. and Lau, H. C. (2014). How to measure metacognition. Frontiers in Human Neuroscience, 8, 443
2014
-
[4]
and Raftery, A
Gneiting, T. and Raftery, A. E. (2007). Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association, 102(477), 359--378
2007
- [5]
-
[6]
Guo, C., Pleiss, G., Sun, Y., and Weinberger, K. Q. (2017). On calibration of modern neural networks. Proceedings of the 34th International Conference on Machine Learning (ICML), 1321--1330
2017
- [7]
-
[8]
and Lau, H
Maniscalco, B. and Lau, H. (2012). A signal detection theoretic approach for estimating metacognitive sensitivity. Consciousness and Cognition, 21(1), 422--430
2012
-
[9]
Millidge, B., Tschantz, A., and Buckley, C. L. (2022). Predictive coding approximates backprop along arbitrary computation graphs. Neural Computation, 34(6), 1329--1368
2022
- [10]
-
[11]
Pepe, M. S. (2003). The Statistical Evaluation of Medical Tests for Classification and Prediction. Oxford University Press
2003
-
[12]
Pinchetti, L., Chang, T., Salvatori, T., Shi, Y., Singh, R. A., Buckley, C. L., and Lukasiewicz, T. (2024). Benchmarking predictive coding networks: made simple. arXiv:2407.01163
-
[13]
Rao, R. P. N. and Ballard, D. H. (1999). Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nature Neuroscience, 2(1), 79--87
1999
-
[14]
Song, Y., Millidge, B., Salvatori, T., Lukasiewicz, T., Xu, Z., and Bogacz, R. (2024). Inferring neural activity before plasticity as a foundation for learning beyond backpropagation. Nature Neuroscience, 27, 348--358
2024
-
[15]
Wei, H., Xie, R., Cheng, H., Feng, L., An, B., and Li, Y. (2022). Mitigating neural network overconfidence with logit normalization. Proceedings of the 39th International Conference on Machine Learning (ICML), 23631--23644
2022
-
[16]
Whittington, J. C. R. and Bogacz, R. (2017). An approximation of the error backpropagation algorithm in a predictive coding network with local Hebbian synaptic plasticity. Neural Computation, 29(5), 1229--1262
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.