Recognition: unknown
Distilling Self-Consistency into Verbal Confidence: A Pre-Registered Negative Result and Post-Hoc Rescue on Gemma 3 4B
Pith reviewed 2026-05-08 03:48 UTC · model grok-4.3
The pith
Self-consistency signals from repeated samples can be distilled into single-pass verbal statements that discriminate correct answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Confidence-conditioned supervised fine-tuning using self-consistency-derived targets compresses multi-sample agreement information into a single verbal confidence statement that discriminates correct from incorrect answers with AUROC 0.774 on held-out data, outperforming logit entropy baselines, while shuffled targets yield no improvement.
What carries the argument
Confidence-conditioned supervised fine-tuning that treats self-consistency agreement across samples as the source of training targets for verbal confidence outputs.
If this is right
- A single verbal confidence statement can serve as a practical binary predictor of answer correctness that exceeds logit-entropy baselines.
- Training on correct targets also improves accuracy on related tasks while regularizing output format validity.
- Label entropy must be preserved in the targets; filtering to high-consistency items causes collapse and removes the benefit.
- The benefit disappears under shuffled targets, confirming that the consistency signal itself drives the result.
Where Pith is reading between the lines
- The same target-construction approach could be applied to distill other internal signals such as token-level uncertainty into verbal form.
- The format-regularization side effect suggests verbal training may improve overall output reliability beyond calibration alone.
- Extension to continuous rather than binary confidence targets would test whether the method supports graded rather than thresholded readout.
Load-bearing premise
The observed gains in verbal discrimination are produced by the specific self-consistency content of the training targets rather than by incidental effects of fine-tuning or output-format changes.
What would settle it
Repeating the identical training run but replacing the self-consistency targets with randomly shuffled versions and observing no rise in discrimination performance above the un-tuned baseline.
Figures


read the original abstract
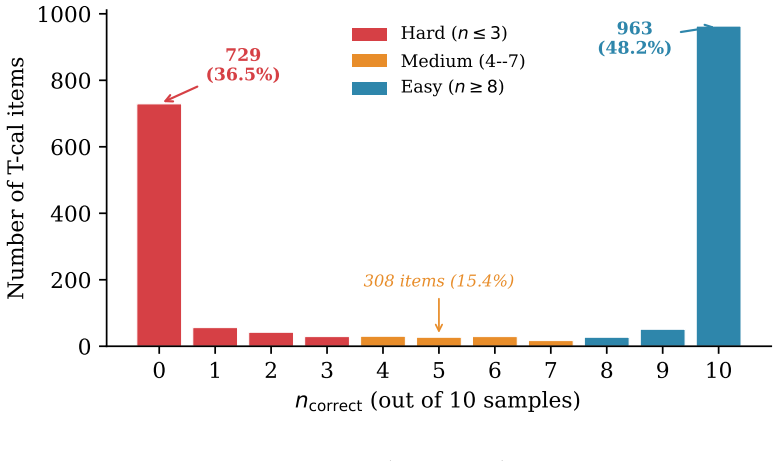
Small instruct-tuned LLMs produce degenerate verbal confidence under minimal elicitation: ceiling rates above 95%, near-chance Type-2 AUROC, and Invalid validity profiles. We test whether confidence-conditioned supervised fine-tuning (CSFT) with self-consistency-derived targets can close the gap between internal information and verbal readout. A pre-registered Phase 0 protocol on Gemma 3 4B-it with a modal filter restricting training to items with correct modal answers produced a negative result: AUROC2 dropped from 0.554 to 0.509 due to label-entropy collapse in the training targets. An exploratory rescue removed the filter, training on all 2,000 calibration items. This produced a binary verbal correctness discriminator with AUROC2 = 0.774 on held-out TriviaQA, compressing a 10-sample self-consistency signal (AUROC2 = 0.999) into a single-pass readout exceeding logit entropy (0.701). The shuffled-target control showed no improvement (0.501). On MMLU, accuracy improved from 54.2% to 77.4% with the shuffled model at baseline (56.1%), supporting a target-dependent interpretation. The result is exploratory, binary rather than continuously calibrated, and observed at a single scale. It identifies two design lessons: confidence training requires label entropy, and correct targets regularise output format.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a pre-registered negative result for confidence-conditioned supervised fine-tuning (CSFT) on Gemma 3 4B-it using self-consistency-derived targets restricted by a modal filter, which caused label-entropy collapse and dropped Type-2 AUROC2 from 0.554 to 0.509. An exploratory post-hoc rescue removes the filter and trains on all 2,000 calibration items, yielding AUROC2 = 0.774 on held-out TriviaQA (exceeding logit entropy at 0.701), with a shuffled-target control at 0.501. MMLU accuracy rises from 54.2% to 77.4% (shuffled baseline 56.1%). The work draws design lessons on requiring label entropy for confidence training and correct targets regularizing output format.
Significance. If the post-hoc result proves robust, the work would show that self-consistency signals can be compressed into single-pass verbal correctness discriminators for small instruct-tuned LLMs, addressing their typical degenerate verbal confidence. Transparent reporting of the pre-registered negative outcome and the shuffled-target control are methodological strengths that support credibility. The finding remains limited by its exploratory status, single-model scale, and binary (rather than calibrated) nature.
major comments (3)
- [Phase 0 protocol and exploratory rescue] Exploratory rescue analysis: The modal filter was removed only after the pre-registered Phase 0 protocol produced a negative result (AUROC2 = 0.509 due to entropy collapse). Although the shuffled-target control on the unfiltered set yields AUROC2 = 0.501, this does not isolate whether the reported gain to 0.774 arises from the self-consistency targets themselves or from incidental effects of training on the full unfiltered 2,000-item dataset.
- [MMLU evaluation] MMLU accuracy results: The large accuracy lift from 54.2% to 77.4% (shuffled control 56.1%) indicates that CSFT alters the model's answer-generation behavior in addition to verbal confidence. This raises the possibility that the AUROC2 improvement is partly driven by better factual performance rather than pure distillation of the self-consistency signal, which the single shuffled control does not fully disentangle.
- [Results] Statistical reporting: No error bars, standard deviations across runs, or multiple random seeds are shown for the key AUROC2 figures (0.774, 0.701, 0.501). Without these, it is difficult to determine whether the observed differences exceed what would be expected from sampling variability at a single model scale.
minor comments (3)
- [Abstract] The abstract and introduction should more explicitly flag which analyses were pre-registered versus exploratory to prevent misreading of the protocol changes.
- [Notation and methods] Define AUROC2 explicitly on first use and clarify how the binary correctness discriminator is constructed from the verbal outputs.
- [Experimental setup] Add dataset sizes for the held-out TriviaQA split and any hyperparameter details to a table or appendix for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below, with revisions where appropriate to clarify limitations and strengthen the presentation of our exploratory findings.
read point-by-point responses
-
Referee: Exploratory rescue analysis: The modal filter was removed only after the pre-registered Phase 0 protocol produced a negative result (AUROC2 = 0.509 due to entropy collapse). Although the shuffled-target control on the unfiltered set yields AUROC2 = 0.501, this does not isolate whether the reported gain to 0.774 arises from the self-consistency targets themselves or from incidental effects of training on the full unfiltered 2,000-item dataset.
Authors: We agree that the post-hoc removal of the modal filter renders the rescue exploratory and that the shuffled control on the unfiltered dataset does not fully isolate the contribution of the self-consistency targets from incidental effects of training on all 2,000 items. The pre-registered negative result with the filter underscores the necessity of label entropy for effective confidence training, as already noted in the manuscript. We will revise the discussion to more explicitly acknowledge this limitation and to suggest that future controlled experiments (e.g., additional random-label baselines on the unfiltered set) would further strengthen causal claims. The current shuffled baseline at 0.501 provides supporting evidence for a target-dependent effect, but we will emphasize caution in interpretation. revision: partial
-
Referee: MMLU accuracy results: The large accuracy lift from 54.2% to 77.4% (shuffled control 56.1%) indicates that CSFT alters the model's answer-generation behavior in addition to verbal confidence. This raises the possibility that the AUROC2 improvement is partly driven by better factual performance rather than pure distillation of the self-consistency signal, which the single shuffled control does not fully disentangle.
Authors: The MMLU accuracy increase demonstrates that CSFT influences answer-generation behavior beyond verbal confidence alone. We concur that this raises the possibility of partial confounding between factual gains and the observed AUROC2 improvement on TriviaQA. The shuffled-target control at baseline AUROC2 supports a target-specific contribution, yet does not fully disentangle the factors. We will add a dedicated paragraph in the results and limitations sections to discuss this interplay and to list it explicitly as a design limitation of the current study. Further experiments isolating factual versus confidence effects would be valuable but lie outside the scope of this work. revision: partial
-
Referee: Statistical reporting: No error bars, standard deviations across runs, or multiple random seeds are shown for the key AUROC2 figures (0.774, 0.701, 0.501). Without these, it is difficult to determine whether the observed differences exceed what would be expected from sampling variability at a single model scale.
Authors: We acknowledge that the absence of error bars or multi-seed statistics limits assessment of variability. Given the computational expense of fine-tuning and the post-hoc exploratory character of the rescue, only single runs were performed for each condition. We will revise the results section to include an explicit statement of this limitation, noting that the magnitude of the observed differences (particularly 0.774 versus 0.501) is suggestive but that multiple random seeds would be required for rigorous statistical comparison. This caveat will be added as a methodological note. revision: yes
Circularity Check
No significant circularity; empirical result with explicit controls
full rationale
The paper reports an empirical pre-registered experiment on Gemma 3 4B that produced a negative result under the modal filter, followed by an exploratory rescue that removed the filter and measured AUROC on held-out TriviaQA. The central performance claim (AUROC2 = 0.774) is evaluated against a shuffled-target control (0.501) and logit entropy baseline (0.701), with no equations, fitted parameters, or self-citations that reduce the reported improvement to a quantity defined inside the paper by construction. The derivation chain consists of standard supervised fine-tuning plus external self-consistency targets and held-out evaluation, remaining self-contained against the provided controls.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Self-consistency across 10 samples provides a reliable proxy label for correctness
- domain assumption Supervised fine-tuning on these targets transfers multi-sample information into single-pass verbal confidence
Reference graph
Works this paper leans on
-
[1]
Cacioli, J.-P. (2026a). Model scale is dissociable from metacognitive monitoring quality: An atlas of Type-2 sensitivity across seven frontier LLMs. Preprint
-
[2]
Cacioli, J.-P. (2026b). Quantisation reshapes the metacognitive geometry of language models. arXiv:2604.08976
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Cacioli, J.-P. (2026c). Verbal confidence saturation in 3--9B open-weight instruction-tuned LLMs: A pre-registered psychometric validity screen. arXiv:2604.22215
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Cacioli, J.-P. (2026d). Cross-entropy is load-bearing: A pre-registered scope test of the K-way energy probe on bidirectional predictive coding. arXiv:2604.21286
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Fleming, S. M. & Lau, H. C. (2014). How to measure metacognition. Frontiers in Human Neuroscience, 8, 443
2014
-
[6]
Gemma Team. (2025). Gemma 3 technical report. arXiv:2503.19786
work page internal anchor Pith review arXiv 2025
-
[7]
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., & Steinhardt, J. (2021). Measuring massive multitask language understanding. ICLR 2021
2021
-
[8]
S., & Zettlemoyer, L
Joshi, M., Choi, E., Weld, D. S., & Zettlemoyer, L. (2017). TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. ACL 2017
2017
- [9]
- [10]
-
[11]
& Lau, H
Maniscalco, B. & Lau, H. (2012). A signal detection theoretic approach for estimating metacognitive sensitivity from confidence ratings. Consciousness and Cognition, 21(1), 422--430
2012
- [12]
-
[13]
Nelson, T. O. & Narens, L. (1990). Metamemory: A theoretical framework and new findings. In G. H. Bower (Ed.), The Psychology of Learning and Motivation (Vol. 26, pp. 125--173). Academic Press
1990
-
[14]
ADVICE: Answer-Dependent Verbalized Confidence Estimation
Seo, K. J., Lim, S., & Kim, T. (2026). ADVICE: Answer-dependent verbalized confidence estimation. arXiv:2510.10913
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Taubenfeld, A., Sheffer, T., Ofek, E., et al. (2025). Confidence improves self-consistency in large language models. Findings of ACL 2025
2025
-
[16]
Tian, K., Mitchell, E., Zhou, A., Sharma, A., Rafailov, R., Yao, H., Finn, C., & Manning, C. D. (2023). Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. EMNLP 2023
2023
-
[17]
& Stengel-Eskin, E
Wang, Z. & Stengel-Eskin, E. (2026). Calibrating verbalized confidence with self-generated distractors. ICLR 2026
2026
-
[18]
Xiong, M., Hu, Z., Lu, X., Li, Y., Fu, J., He, J., & Hooi, B. (2024). Can LLMs express their uncertainty? An empirical evaluation of confidence elicitation in LLMs. ICLR 2024
2024
- [19]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.