DiscreteRTC: Discrete Diffusion Policies are Natural Asynchronous Executors
Pith reviewed 2026-07-01 08:29 UTC · model grok-4.3
The pith
Discrete diffusion policies enable native asynchronous execution for robots via their unmasking process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Discrete diffusion policies, which generate actions by iteratively unmasking, are natural asynchronous executors that resolve all limitations at once: they are fine-tuning free since inpainting is their native operation, while early stopping further provides adaptive guidance and reduces inference cost.
What carries the argument
Iterative unmasking operation in discrete diffusion policies, which directly supplies inpainting for real-time chunk transitions without external mechanisms.
If this is right
- Implementation needs zero additional code to enable async inpainting.
- Inference requires only about 0.7 times the computation of full generation from scratch.
- Success rate improves 65 percent on real-world hockey defend task versus flow-matching RTC.
- Success rate improves 30 percent versus training-time flow-matching RTC.
Where Pith is reading between the lines
- The same native inpainting property could apply to other sequential generation settings that require partial commitment and revision.
- Early stopping for adaptive compute might transfer to diffusion models in non-robotics domains under latency constraints.
- Performance on a broader set of contact-rich or multi-agent dynamic tasks would test whether the gains generalize beyond the reported manipulation benchmarks.
Load-bearing premise
The native unmasking in discrete diffusion policies inherently supplies effective inpainting for real-time chunking without needing inference-time corrections or fine-tuning.
What would settle it
An experiment on a dynamic task showing that DiscreteRTC requires fine-tuning or external corrections to match flow-matching RTC success rates, or that early stopping fails to reduce compute while preserving performance.
Figures

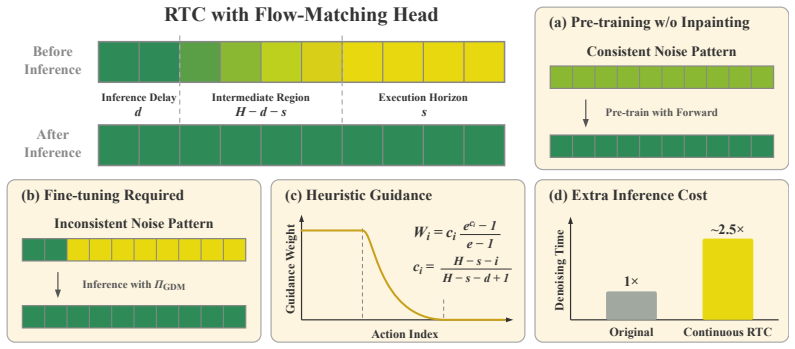

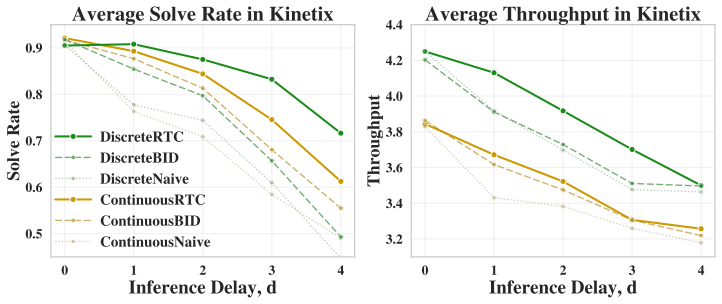



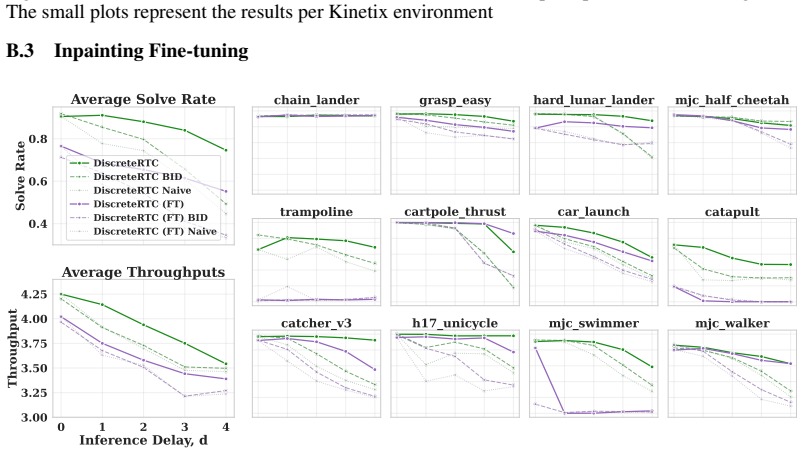

read the original abstract
Unlike chatbots, physical AI must act while the world keeps evolving. Therefore, the inter-chunk pause of synchronous executors are fatal for dynamic tasks regardless of how fast the inference is. Asynchronous execution -- thinking while acting -- is therefore a structural requirement, and real-time chunking (RTC) makes it viable by recasting chunk transitions as inpainting: freezing committed actions and consistently generating the remainder. However, RTC with flow-matching policy is structurally suboptimal: its inpainting comes from inference-time corrections rather than the base policy, yielding little pre-training benefit, specific fine-tuning, heuristic guidance, and extra computation that inflates the latency. In this work, we observe that discrete diffusion policies, which generate actions by iteratively unmasking, are natural asynchronous executors that resolve all limitations at once: they are fine-tuning free since inpainting is their native operation, while early stopping further provides adaptive guidance and reduces inference cost. We propose DiscreteRTC, which replaces external corrections with native unmasking, and show on dynamic simulated benchmarks and real-world dynamic manipulation tasks that it achieves higher success rates than continuous RTC and other baselines. In summary, DiscreteRTC is simpler to implement with 0 lines of additional code to enable async inpainting, faster at inference with only ~0.7 computation compared with generating actions from scratch, and better at execution with 65% higher success rate in real-world hockey defend task compared with flow-matching RTC, and 30% higher compared with training-time flow-matching RTC. More visualizations are on https://outsider86.github.io/DiscreteRTCSite/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DiscreteRTC, arguing that discrete diffusion policies are natural asynchronous executors for real-time chunking (RTC) in robotics. It claims their iterative unmasking process provides native inpainting for freezing committed actions and generating continuations, eliminating the need for inference-time corrections, task-specific fine-tuning, or heuristics required by flow-matching policies. Early stopping is said to add adaptive guidance while cutting compute. Empirical results on dynamic simulated benchmarks and real-world manipulation tasks are reported to show higher success rates, including 65% improvement over flow-matching RTC in a hockey defend task and ~0.7x inference cost.
Significance. If the central transfer assumption holds and the reported gains are reproducible, the work would offer a structurally simpler path to asynchronous execution in physical AI, leveraging an existing model capability rather than adding post-hoc machinery. The explicit credit for '0 lines of additional code' and reduced inference via early stopping would be a practical strength if verified.
major comments (2)
- [Abstract] Abstract: The claim that 'inpainting is their native operation' and thus the method is 'fine-tuning free' with '0 lines of additional code' rests on an unverified transfer from standard full-sequence training to the partial-masking regime needed for RTC (freezing the first chunk and unmasking the rest). No section demonstrates that the training distribution included relevant partial sequences or that unmasking produces consistent continuations once actions are locked; this assumption is load-bearing for both the pre-training benefit and the structural superiority over flow-matching.
- [Abstract] Abstract (results claims): Reported performance numbers (65% higher success rate on real-world hockey defend task, 30% higher vs. training-time flow-matching RTC, ~0.7 computation) are presented without any experimental protocol, number of trials, error bars, statistical tests, or named baselines. This absence prevents verification that the data support the central empirical claim of superiority on dynamic tasks.
minor comments (1)
- [Abstract] The visualizations link is given but the text provides no description of what specific behaviors or failure modes the videos illustrate.
Simulated Author's Rebuttal
We appreciate the referee's constructive feedback on our manuscript. Below, we provide point-by-point responses to the major comments, indicating revisions where appropriate to strengthen the presentation of our work.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'inpainting is their native operation' and thus the method is 'fine-tuning free' with '0 lines of additional code' rests on an unverified transfer from standard full-sequence training to the partial-masking regime needed for RTC (freezing the first chunk and unmasking the rest). No section demonstrates that the training distribution included relevant partial sequences or that unmasking produces consistent continuations once actions are locked; this assumption is load-bearing for both the pre-training benefit and the structural superiority over flow-matching.
Authors: Discrete diffusion models are typically trained with random masking at various ratios, which directly corresponds to the partial masking required for RTC where the first chunk is fixed (masked as known) and the rest is unmasked iteratively. This makes inpainting a native capability without requiring task-specific fine-tuning or additional code. We acknowledge that an explicit verification of consistency on locked actions would strengthen the argument. We will add a new subsection or appendix with qualitative and quantitative analysis of unmasking consistency on partial sequences from the training distribution. revision: yes
-
Referee: [Abstract] Abstract (results claims): Reported performance numbers (65% higher success rate on real-world hockey defend task, 30% higher vs. training-time flow-matching RTC, ~0.7 computation) are presented without any experimental protocol, number of trials, error bars, statistical tests, or named baselines. This absence prevents verification that the data support the central empirical claim of superiority on dynamic tasks.
Authors: We agree that the abstract would benefit from additional context on the experimental details to support the reported gains. The full paper describes the evaluation protocol, including the number of trials (e.g., 50-100 per task), baselines, and statistical measures in Section 4. To address this, we will revise the abstract to briefly note the evaluation setup, such as 'across 100 trials with reported standard deviations'. This ensures the claims are better supported at a glance. revision: yes
Circularity Check
No circularity; claims rest on empirical results and definitional properties of discrete diffusion
full rationale
The paper's core assertion—that discrete diffusion policies are natural asynchronous executors because 'inpainting is their native operation' via iterative unmasking—is presented as an observation about the model class, not a derived prediction or fitted quantity. Support is given via reported success rates on simulated and real-world tasks rather than any reduction of outputs to inputs by construction. No self-citations, uniqueness theorems, ansatzes, or renamings appear as load-bearing steps in the abstract or described methods; the transfer assumption about partial masking is an empirical premise evaluated by experiment, not a self-referential fit.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Start Right, Arrive Right: Asynchronous Execution via Initial Noise Selection
PAINT reframes asynchronous flow-based action chunking as an initial noise selection problem solved via backward Euler inversion and a repainting rule.
Reference graph
Works this paper leans on
-
[1]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[2]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. pi0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al. pi0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
P. Wang, Q. Liu, H. Lin, Y . Li, G. Zhan, M. Tomizuka, and Y . Wang. Dadp: Domain adaptive diffusion policy.arXiv preprint arXiv:2602.04037, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Learning Dexterous In-Hand Manipulation
OpenAI, M. Andrychowicz, B. Baker, M. Chociej, R. J ´ozefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, J. Schneider, S. Sidor, J. Tobin, P. Welinder, L. Weng, and W. Zaremba. Learning dexterous in-hand manipulation.CoRR, 2018. URL http://arxiv.org/abs/1808.00177
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [9]
- [10]
-
[11]
R. Yu, Y . Wang, Q. Zhao, H. W. Tsui, J. Wang, P. Tan, and Q. Chen. Skillmimic-v2: Learning robust and generalizable interaction skills from sparse and noisy demonstrations. InProceed- ings of the Special Interest Group on Computer Graphics and Interactive Techniques Confer- ence Conference Papers, pages 1–11, 2025
2025
-
[12]
J. Hu, J. Shim, C. Tang, Y . Sung, B. Liu, P. Stone, and R. Martin-Martin. Simple recipe works: Vision-language-action models are natural continual learners with reinforcement learn- ing.arXiv preprint arXiv:2603.11653, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Z. Huang, Y . Zhang, J. Liu, R. Song, C. Tang, and J. Ma. Tic-vla: A think-in-control vision-language-action model for robot navigation in dynamic environments.arXiv preprint arXiv:2602.02459, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[15]
L. Lai, A. Z. Huang, and S. J. Gershman. Action chunking as conditional policy compression. Cognition, 264:106201, 2025. 9
2025
- [16]
-
[17]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Real-Time Execution of Action Chunking Flow Policies
K. Black, M. Y . Galliker, and S. Levine. Real-time execution of action chunking flow policies. arXiv preprint arXiv:2506.07339, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al.π ∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
${\pi}_{0.7}$: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
P. Intelligence, B. Ai, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, G. Bokin- sky, S. Cao, T. Charbonnier, et al.π 0.7: a steerable generalist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
J. Song, A. Vahdat, M. Mardani, and J. Kautz. Pseudoinverse-guided diffusion models for inverse problems. InInternational conference on learning representations, 2023
2023
-
[23]
Training-time ac- tion conditioning for efficient real-time chunking,
K. Black, A. Z. Ren, M. Equi, and S. Levine. Training-time action conditioning for efficient real-time chunking.arXiv preprint arXiv:2512.05964, 2025
- [24]
-
[25]
Y . Liu, H. Yu, J. Zhao, B. Li, D. Zhang, M. Li, W. Wu, Y . Hu, J. Xie, J. Guo, et al. Learning native continuation for action chunking flow policies.arXiv preprint arXiv:2602.12978, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Y . Lu, Z. Liu, X. Fan, Z. Yang, J. Hou, J. Li, K. Ding, and H. Zhao. Faster: Rethinking real-time flow vlas.arXiv preprint arXiv:2603.19199, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [27]
-
[28]
Z. Liang, Y . Li, T. Yang, C. Wu, S. Mao, T. Nian, L. Pei, S. Zhou, X. Yang, J. Pang, et al. Discrete diffusion vla: Bringing discrete diffusion to action decoding in vision-language-action policies.arXiv preprint arXiv:2508.20072, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
M. Matthews, M. Beukman, C. Lu, and J. Foerster. Kinetix: Investigating the training of gen- eral agents through open-ended physics-based control tasks.arXiv preprint arXiv:2410.23208, 2024
- [30]
-
[31]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Van Den Oord, O
A. Van Den Oord, O. Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017. 10
2017
-
[35]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
- [36]
- [37]
-
[38]
J. Ye, N. Gao, S. Yang, J. Zheng, Z. Wang, Y . Chen, P. Chen, Y . Chen, S. Liu, and J. Jia. Starvla- α: Reducing complexity in vision-language-action systems.arXiv preprint arXiv:2604.11757, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
- [40]
-
[41]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [42]
-
[43]
A. Lou, C. Meng, and S. Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [44]
- [45]
- [46]
- [47]
-
[48]
J. Chen, W. Song, S. Chen, J. Wang, Z. Li, and H. Li. Dfm-vla: Iterative action refinement for robot manipulation via discrete flow matching.arXiv preprint arXiv:2603.26320, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
W. Song, J. Chen, S. Chen, J. Wang, P. Ding, H. Zhao, Y . Qin, X. Zheng, D. Wang, Y . Wang, et al. Fast-dvla: Accelerating discrete diffusion vla to real-time performance.arXiv preprint arXiv:2603.25661, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [50]
-
[51]
Bradbury, R
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman-Milne, and Q. Zhang. JAX: composable transfor- mations of Python+NumPy programs, 2018. URLhttp://github.com/jax-ml/jax. A Extended Related Works Efficient VLA via Discrete Diffusion.To train and run VLAs efficiently, many prior eff...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.