Recognition: unknown
Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe
Pith reviewed 2026-05-07 16:57 UTC · model grok-4.3
The pith
Uni-OPD fixes two core limits in on-policy distillation so a single student model can reliably absorb capabilities from expert LLMs and MLLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
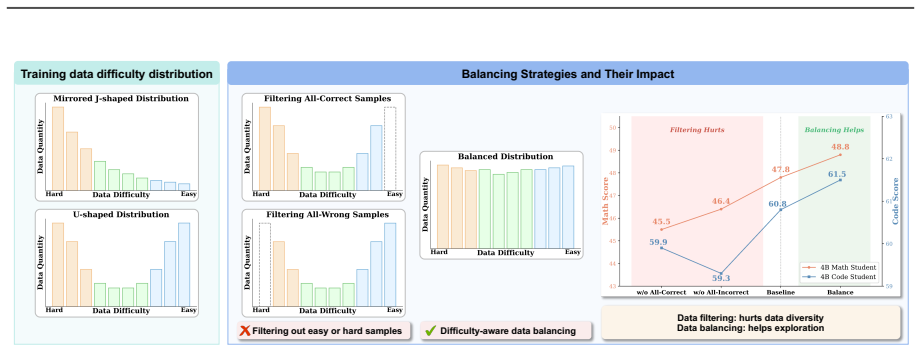
On-policy distillation improves when viewed through two lenses: from the student, data balancing strategies increase exploration of informative self-generated states; from the teacher, outcome-guided margin calibration ensures token-level guidance remains order-consistent with the final reward. Together these steps form Uni-OPD, a framework shown to work across LLMs and MLLMs in single-teacher, multi-teacher, strong-to-weak, and cross-modal distillation tasks.
What carries the argument
Dual-perspective optimization strategy that pairs student-side data balancing with teacher-side outcome-guided margin calibration.
If this is right
- Single-teacher and multi-teacher distillation both become more effective across language and multimodal models.
- Strong-to-weak distillation gains reliability without extra model size.
- Cross-modal distillation between LLMs and MLLMs works under the same unified recipe.
- Practical guidelines emerge for choosing data balance ratios and margin values during training.
Where Pith is reading between the lines
- The same dual-view logic could be tested on non-language sequence tasks such as protein design or code generation where outcome rewards are available.
- Margin calibration might be combined with other reward-modeling techniques to reduce the need for large outcome verifiers.
- If the balancing strategies scale with model size, they could lower the compute cost of distilling many experts into one generalist.
Load-bearing premise
That insufficient state exploration and order-inconsistent teacher supervision are the primary bottlenecks in on-policy distillation and that the specific balancing and calibration fixes will improve results without creating new instabilities.
What would settle it
Applying the two data-balancing steps and margin calibration to a new domain or model family and observing no improvement or a performance drop relative to standard on-policy distillation would show the fixes do not reliably solve the stated bottlenecks.
Figures





read the original abstract
On-policy distillation (OPD) has recently emerged as an effective post-training paradigm for consolidating the capabilities of specialized expert models into a single student model. Despite its empirical success, the conditions under which OPD yields reliable improvement remain poorly understood. In this work, we identify two fundamental bottlenecks that limit effective OPD: insufficient exploration of informative states and unreliable teacher supervision for student rollouts. Building on this insight, we propose Uni-OPD, a unified OPD framework that generalizes across Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs), centered on a dual-perspective optimization strategy. Specifically, from the student's perspective, we adopt two data balancing strategies to promote exploration of informative student-generated states during training. From the teacher's perspective, we show that reliable supervision hinges on whether aggregated token-level guidance remains order-consistent with the outcome reward. To this end, we develop an outcome-guided margin calibration mechanism to restore order consistency between correct and incorrect trajectories. We conduct extensive experiments on 5 domains and 16 benchmarks covering diverse settings, including single-teacher and multi-teacher distillation across LLMs and MLLMs, strong-to-weak distillation, and cross-modal distillation. Our results verify the effectiveness and versatility of Uni-OPD and provide practical insights into reliable OPD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies two fundamental bottlenecks in on-policy distillation (OPD): insufficient exploration of informative states and unreliable teacher supervision for student rollouts. It proposes Uni-OPD, a unified framework generalizing across LLMs and MLLMs via a dual-perspective optimization strategy. From the student perspective, two data balancing strategies promote exploration of informative states; from the teacher perspective, an outcome-guided margin calibration restores order consistency between aggregated token-level guidance and outcome rewards. Extensive experiments are reported across 5 domains and 16 benchmarks in settings including single/multi-teacher distillation, strong-to-weak, and cross-modal distillation, claiming to verify the framework's effectiveness and versatility.
Significance. If the results hold with proper isolation of contributions, the work could provide a practical, generalizable recipe for reliable OPD that bridges language and multimodal models. The dual-perspective design (addressing both student exploration and teacher supervision consistency) offers a coherent way to mitigate stated bottlenecks, and the breadth of evaluated settings (cross-modal, multi-teacher) would be a notable strength if supported by controlled evidence.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The manuscript asserts 'extensive experiments on 5 domains and 16 benchmarks' with claims of verifying effectiveness, yet the provided text supplies no quantitative results, baseline comparisons, statistical details, error bars, or ablation evidence. This prevents verification of the central claim that the dual-perspective recipe reliably addresses the two bottlenecks.
- [§4] §4 (Experiments): No systematic ablations or controlled comparisons isolate the causal contribution of the two data balancing strategies versus the outcome-guided margin calibration (or their combination). Without such isolation, performance gains cannot be confidently attributed to the proposed fixes rather than unstated factors such as rollout length, reward sparsity, or hyperparameter choices, undermining the claim that these mechanisms restore order consistency and improve OPD.
- [§3] §3 (Method): The outcome-guided margin calibration is motivated as restoring order consistency with the outcome reward, but the manuscript provides no formal definition, guarantee, or analysis showing that the calibration reliably achieves this across teacher models or modalities without introducing new instabilities in multi-teacher or cross-modal regimes.
minor comments (2)
- [Abstract] The term 'order-consistent' is used repeatedly but lacks an early formal definition or mathematical characterization; adding this in §2 would improve readability.
- [Abstract] Consider including at least one concrete performance delta or table reference in the abstract to convey the scale of improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We appreciate the emphasis on ensuring that experimental claims are fully supported by visible evidence and that the proposed mechanisms are rigorously isolated and analyzed. We address each major comment below and will revise the manuscript accordingly to strengthen clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The manuscript asserts 'extensive experiments on 5 domains and 16 benchmarks' with claims of verifying effectiveness, yet the provided text supplies no quantitative results, baseline comparisons, statistical details, error bars, or ablation evidence. This prevents verification of the central claim that the dual-perspective recipe reliably addresses the two bottlenecks.
Authors: We acknowledge that the experimental results need to be presented more explicitly to support the claims. While §4 describes the evaluation across 5 domains and 16 benchmarks in multiple settings (single/multi-teacher, strong-to-weak, cross-modal), we will revise the manuscript to include complete quantitative tables with all baseline comparisons, performance deltas, error bars, and statistical significance tests. A concise summary of key metrics will also be added to the abstract and introduction for immediate verifiability. revision: yes
-
Referee: [§4] §4 (Experiments): No systematic ablations or controlled comparisons isolate the causal contribution of the two data balancing strategies versus the outcome-guided margin calibration (or their combination). Without such isolation, performance gains cannot be confidently attributed to the proposed fixes rather than unstated factors such as rollout length, reward sparsity, or hyperparameter choices, undermining the claim that these mechanisms restore order consistency and improve OPD.
Authors: We agree that isolating the contributions of each component is necessary to substantiate the dual-perspective design. In the revised version, we will add a new ablation subsection in §4 that evaluates (i) each data balancing strategy in isolation, (ii) the margin calibration alone, and (iii) their combination, while controlling for rollout length, reward sparsity, and hyperparameter settings. These controlled comparisons will directly attribute gains to the proposed mechanisms. revision: yes
-
Referee: [§3] §3 (Method): The outcome-guided margin calibration is motivated as restoring order consistency with the outcome reward, but the manuscript provides no formal definition, guarantee, or analysis showing that the calibration reliably achieves this across teacher models or modalities without introducing new instabilities in multi-teacher or cross-modal regimes.
Authors: The calibration is defined in §3.2 as an adjustment of token-level margins conditioned on the outcome reward to enforce order consistency between aggregated guidance and trajectory-level rewards. We provide empirical validation of improved consistency and stability across the evaluated regimes. However, we recognize the value of a formal treatment. We will add a precise mathematical definition together with a proposition characterizing the conditions under which order consistency is restored, plus a brief discussion of stability considerations in multi-teacher and cross-modal cases. revision: yes
Circularity Check
No circularity: empirical proposal without self-referential derivations
full rationale
The paper identifies two bottlenecks in on-policy distillation via empirical observation, then introduces Uni-OPD as a dual-perspective framework consisting of student-side data balancing and teacher-side margin calibration. These are presented as new mechanisms motivated by the bottlenecks, with effectiveness shown through experiments across 16 benchmarks. No equations, parameter-fitting steps, predictions derived from fitted inputs, or self-citations that bear the central load appear in the abstract or described structure. The derivation chain is self-contained as a practical recipe rather than a closed mathematical loop reducing to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reliable teacher supervision requires that aggregated token-level guidance remains order-consistent with the outcome reward
Forward citations
Cited by 3 Pith papers
-
Chronicles-OCR: A Cross-Temporal Perception Benchmark for the Evolutionary Trajectory of Chinese Characters
Chronicles-OCR is the first benchmark with 2,800 images across the complete evolutionary trajectory of Chinese characters, defining four tasks to evaluate VLLMs' cross-temporal visual perception.
-
Beyond GRPO and On-Policy Distillation: An Empirical Sparse-to-Dense Reward Principle for Language-Model Post-Training
Sparse RL on capable teachers followed by dense distillation to students beats direct GRPO on students for verifiable math reasoning.
-
Beyond GRPO and On-Policy Distillation: An Empirical Sparse-to-Dense Reward Principle for Language-Model Post-Training
Sparse RL on a strong teacher followed by dense distillation to the student outperforms direct GRPO on the student for math tasks, with a forward-KL + OPD bridge enabling further gains.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[2]
AIME 2024.https://huggingface.co/datasets/AI-MO/aimo-validation-aime,
AI-MO. AIME 2024.https://huggingface.co/datasets/AI-MO/aimo-validation-aime,
2024
-
[3]
Anthropic
URLhttps://hkunlp.github.io/blog/2025/Polaris. Anthropic. Claude 2, 2023a. URL https://www-files.anthropic.com/production/images/ Model-Card-Claude-2.pdf. Anthropic. Introducing Claude, 2023b. URLhttps://www.anthropic.com/index/introducing-claude. Anthropic. The Claude 3 model family: Opus, Sonnet, Haiku,
2025
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025a. Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-VL technical report.arXiv pr...
work page internal anchor Pith review arXiv
-
[5]
Honeybee: Data recipes for vision-language reasoners.arXiv preprint arXiv:2510.12225,
Hritik Bansal, Devandra Singh Sachan, Kai-Wei Chang, Aditya Grover, Gargi Ghosh, Wen-tau Yih, and Ramakanth Pasunuru. Honeybee: Data recipes for vision-language reasoners.arXiv preprint arXiv:2510.12225,
-
[6]
Walid Bousselham, Hilde Kuehne, and Cordelia Schmid. VOLD: Reasoning transfer from LLMs to vision-language models via on-policy distillation.arXiv preprint arXiv:2510.23497,
-
[7]
Di Cao, Dongjie Fu, Hai Yu, Siqi Zheng, Xu Tan, and Tao Jin. X-OPD: Cross-modal on-policy distillation for capability alignment in speech llms.arXiv preprint arXiv:2603.24596,
-
[8]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review arXiv
-
[9]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, et al. Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456,
work page internal anchor Pith review arXiv
-
[10]
MiniLLM: On-Policy Distillation of Large Language Models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: On-policy distillation of large language models. arXiv preprint arXiv:2306.08543,
work page internal anchor Pith review arXiv
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025a. Yiju Guo, Wenkai Yang, Zexu Sun, Ning Ding, Zhiyuan Liu, and Yankai Lin. Learning to focus: Causal attentio...
work page internal anchor Pith review arXiv
-
[12]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review arXiv
-
[13]
Wenjin Hou, Wei Liu, Han Hu, Xiaoxiao Sun, Serena Yeung-Levy, and Hehe Fan. Seeing is believing? a benchmark for multimodal large language models on visual illusions and anomalies.arXiv preprint arXiv:2602.01816,
-
[14]
Reinforcement Learning via Self-Distillation
Jonas H¨ubotter, Frederike L¨ubeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802,
work page internal anchor Pith review arXiv
-
[15]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. GPT-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review arXiv
-
[16]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974,
work page internal anchor Pith review arXiv
-
[17]
Stable On-Policy Distillation through Adaptive Target Reformulation
Ijun Jang, Jewon Yeom, Juan Yeo, Hyunggu Lim, and Taesup Kim. Stable on-policy distillation through adaptive target reformulation.arXiv preprint arXiv:2601.07155,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Entropy-aware on-policy distillation of language models
Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models.arXiv preprint arXiv:2603.07079,
-
[19]
Minsang Kim and Seung Jun Baek. Explain in your own words: Improving reasoning via token-selective dual knowledge distillation.arXiv preprint arXiv:2603.13260,
-
[20]
Jongwoo Ko, Tianyi Chen, Sungnyun Kim, Tianyu Ding, Luming Liang, Ilya Zharkov, and Se-Young Yun. DistiLLM-2: A contrastive approach boosts the distillation of LLMs.arXiv preprint arXiv:2503.07067,
-
[21]
arXiv preprint arXiv:2603.11137 , year =
Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron. Scaling reasoning efficiently via relaxed on-policy distillation.arXiv preprint arXiv:2603.11137,
-
[22]
Efficient knowledge injection in LLMs via self-distillation.arXiv preprint arXiv:2412.14964,
Kalle Kujanp¨a¨a, Pekka Marttinen, Harri Valpola, and Alexander Ilin. Efficient knowledge injection in LLMs via self-distillation.arXiv preprint arXiv:2412.14964,
-
[23]
Jiaze Li, Hao Yin, Haoran Xu, Boshen Xu, Wenhui Tan, Zewen He, Jianzhong Ju, Zhenbo Luo, and Jian Luan. Video-OPD: Efficient post-training of multimodal large language models for temporal video grounding via on-policy distillation.arXiv preprint arXiv:2602.02994, 2026a. Jingyao Li, Senqiao Yang, Sitong Wu, Han Shi, Chuanyang Zheng, Hong Xu, and Jiaya Jia....
work page internal anchor Pith review arXiv
-
[24]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026b. Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring how models mimic ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437, 2024a. Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 2023a. Haotian Liu, Ch...
work page internal anchor Pith review arXiv 2024
-
[26]
Typicalness- aware learning for failure detection.arXiv preprint arXiv:2411.01981, 2024e
Yijun Liu, Jiequan Cui, Zhuotao Tian, Senqiao Yang, Qingdong He, Xiaoling Wang, and Jingyong Su. Typicalness- aware learning for failure detection.arXiv preprint arXiv:2411.01981, 2024e. Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Connectionism,
-
[27]
https://thinkingmachines.ai/blog/ on-policy-distillation/
doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy-distillation. Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022, pp. 2263–2279,
-
[28]
AIME 2025.https://huggingface.co/datasets/opencompass/AIME2025,
OpenCompass. AIME 2025.https://huggingface.co/datasets/opencompass/AIME2025,
2025
-
[29]
Tianyuan Qu, Longxiang Tang, Bohao Peng, Senqiao Yang, Bei Yu, and Jiaya Jia. Does your vision-language model get lost in the long video sampling dilemma?arXiv preprint arXiv:2503.12496,
-
[30]
Yuxiao Qu, Amrith Setlur, Virginia Smith, Ruslan Salakhutdinov, and Aviral Kumar. POPE: Learning to reason on hard problems via privileged on-policy exploration.arXiv preprint arXiv:2601.18779,
-
[31]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Tong Shao, Zhuotao Tian, Hang Zhao, and Jingyong Su. Explore the potential of CLIP for training-free open vocabulary semantic segmentation. InEuropean Conference on Computer Vision, 2024a. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathema...
work page internal anchor Pith review arXiv
-
[32]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron- lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053,
work page internal anchor Pith review arXiv 1909
-
[33]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626,
work page internal anchor Pith review arXiv
-
[34]
Alex Stein, Furong Huang, and Tom Goldstein. GATES: Self-distillation under privileged context with consensus gating.arXiv preprint arXiv:2602.20574,
-
[35]
CommonsenseQA: A question answering challenge targeting commonsense knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers),
2019
-
[36]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530,
work page internal anchor Pith review arXiv
-
[37]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276,
work page internal anchor Pith review arXiv
-
[38]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review arXiv
-
[39]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset.Advances in Neural Information Processing Systems, 37:95095–95169, 2024a. Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin...
work page internal anchor Pith review arXiv
-
[40]
Yecheng Wu, Song Han, and Hai Cai. Lightning opd: Efficient post-training for large reasoning models with offline on-policy distillation.arXiv preprint arXiv:2604.13010,
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
MiMo-V2-Flash Technical Report
Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, et al. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780,
work page internal anchor Pith review arXiv
-
[42]
Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang. Logicvista: Multimodal llm logical reasoning benchmark in visual contexts.arXiv preprint arXiv:2407.04973,
-
[43]
Ovd: On-policy verbal distillation.arXiv preprint arXiv:2601.21968, 2026
Jing Xiong, Hui Shen, Shansan Gong, Yuxin Cheng, Jianghan Shen, Chaofan Tao, Haochen Tan, Haoli Bai, Lifeng Shang, and Ngai Wong. OVD: On-policy verbal distillation.arXiv preprint arXiv:2601.21968,
-
[44]
RedStar: Does Scaling Long- CoT Data Unlock Better Slow-Reasoning Systems?
Haotian Xu, Xing Wu, Weinong Wang, Zhongzhi Li, Da Zheng, Boyuan Chen, Yi Hu, Shijia Kang, Jiaming Ji, Yingying Zhang, et al. Redstar: does scaling long-cot data unlock better slow-reasoning systems?arXiv preprint arXiv:2501.11284, 2025a. Weiye Xu, Jiahao Wang, Weiyun Wang, Zhe Chen, Wengang Zhou, Aijun Yang, Lewei Lu, Houqiang Li, Xiaohua Wang, Xizhou Zh...
-
[45]
PACED: Distillation and On-Policy Self-Distillation at the Frontier of Student Competence
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, and Zhipeng Wang. PACED: Distillation at the frontier of student competence.arXiv preprint arXiv:2603.11178,
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024a. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint...
work page internal anchor Pith review arXiv
-
[47]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled RLVR.arXiv preprint arXiv:2604.03128, 2026a. Senqiao Yang, Jiaming Liu, Ray Zhang, Mingjie Pan, Zoey Guo, Xiaoqi Li, Zehui Chen, Peng Gao, Yandong Guo, and Shanghang Zhang. LiDAR-LLM: Exploring the potential of large ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models. arXiv preprint arXiv:2602.12275,
work page internal anchor Pith review arXiv
-
[49]
GLM-5: from Vibe Coding to Agentic Engineering
URLhttps://aclanthology.org/P19-1472. Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. GLM-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763,
work page internal anchor Pith review arXiv
-
[50]
Dongxu Zhang, Zhichao Yang, Sepehr Janghorbani, Jun Han, Andrew Ressler II, Qian Qian, Gregory D Lyng, Sanjit Singh Batra, and Robert E Tillman. Fast and effective on-policy distillation from reasoning prefixes.arXiv preprint arXiv:2602.15260, 2026a. Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang,...
-
[51]
Lyra: An efficient and speech-centric framework for omni-cognition.arXiv preprint arXiv:2412.09501,
Zhisheng Zhong, Chengyao Wang, Yuqi Liu, Senqiao Yang, Longxiang Tang, Yuechen Zhang, Jingyao Li, Tianyuan Qu, Yanwei Li, Yukang Chen, et al. Lyra: An efficient and speech-centric framework for omni-cognition.arXiv preprint arXiv:2412.09501,
-
[52]
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. LIMA: Less is more for alignment.Advances in Neural Information Processing Systems, 36: 55006–55021, 2023a. Guorui Zhou, Honghui Bao, Jiaming Huang, Jiaxin Deng, Jinghao Zhang, Junda She, Kuo Cai, Lejian Ren, Lu Ren, Qiang Luo, et a...
-
[53]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023b. Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. MiniGPT-4: Enhancing vision-language understanding with advanced large language mo...
work page internal anchor Pith review arXiv
-
[54]
Chengke Zou, Xingang Guo, Rui Yang, Junyu Zhang, Bin Hu, and Huan Zhang. Dynamath: A dynamic vi- sual benchmark for evaluating mathematical reasoning robustness of vision language models.arXiv preprint arXiv:2411.00836,
-
[55]
The decoding configuration is kept fixed throughout this offline phase: we use temperature =1.0 , top-p=0.95 , top-k=50 , and a maximum response length of 16,384 tokens
under the same prompt template that will later be used at training time, so that the estimated difficulty reflects the actual input format the student will see. The decoding configuration is kept fixed throughout this offline phase: we use temperature =1.0 , top-p=0.95 , top-k=50 , and a maximum response length of 16,384 tokens. For each instance, we then...
2025
-
[56]
Present the code in ‘‘‘python Your code ‘‘‘ at the end
Training Prompt Template Math Reasoning <|im start|>user {question} Please reason step by step, and put your final answer within\boxed{}.<|im end|> <|im start|>assistant Code Reasoning <|im start|>user {question} Write Python code to solve the problem. Present the code in ‘‘‘python Your code ‘‘‘ at the end. You need to think first then write the Python co...
2048
-
[57]
training sets. 6https://huggingface.co/datasets/OpenMMReasoner/OpenMMReasoner-RL-74K 7 0 10 20 30 40 50 Optimization Step 30 40 50 60 70 80Response Correct Ratio (%) 0 10 20 30 40 50 Optimization Step 0.28 0.30 0.32 0.34 0.36 0.38 0.40 0.42Entropy 0 10 20 30 40 50 Optimization Step 2000 4000 6000 8000 10000 12000Average Response Length OPD Uni-OPD Figure ...
2000
-
[58]
per prompt in the worst case (typicallyG≤16in our setup). In contrast, the dominant per-iteration cost of OPD comes from two stages whose complexity scales linearly with the total number of rollout tokens Ttok = ∑BG i=1 |τi| and cubically with the hidden size d: (i) sampling BG on-policy rollouts from the student, and (ii) running a teacher prefill pass o...
2024
-
[59]
For math reasoning benchmarks, we sample N=32 solutions per problem, while for code generation benchmarks, we sample N=4 solutions per problem
We use the vLLM inference engine to perform sampling. For math reasoning benchmarks, we sample N=32 solutions per problem, while for code generation benchmarks, we sample N=4 solutions per problem. For evaluation, we adopt Math-Verify10 as a rule- based verifier for math reasoning tasks. For code generation, we use the EvalPlus11 and LiveCodeBench12 frame...
2024
-
[60]
following recent studies (Peng et al., 2026; Meng et al., 2024). Specifically, we report results on MMLU (Hendrycks et al., 2020), ARC (Clark et al., 2018), HellaSwag (Zellers et al., 2019), TruthfulQA (Lin et al., 2022), Winogrande (Levesque et al., 2012), GSM8K (Cobbe et al., 2021), Common- senseQA (Talmor et al., 2019), and IFEval (Zhou et al., 2023b)....
2026
-
[61]
Recently, some works have also combined RLVR with OPD, such as Self-Distilled RLVR (Yang et al., 2026a) and OpenClaw-RL (Wang et al., 2026)
for sequence-level stable optimization. Recently, some works have also combined RLVR with OPD, such as Self-Distilled RLVR (Yang et al., 2026a) and OpenClaw-RL (Wang et al., 2026). In our work, we use GRPO to obtain stronger domain-specific teachers and use the corresponding reward models as global guidance for return calibration in OPD. 13 E.3 On-Policy ...
2026
-
[62]
Recent studies further broaden this paradigm from multiple perspectives
and GKD (Agarwal et al., 2024), establishes the basic paradigm of using teacher feedback on student-generated trajectories under a reverse KL objective. Recent studies further broaden this paradigm from multiple perspectives. In self-distillation methods, OPSD (Zhao et al., 2026b) uses privileged information; SDFT (Shenfeld et al.,
2024
-
[63]
find all such functions,
further extends OPD to speech through cross-modal alignment. In contrast, our work focuses on developing a unified OPD framework with an open recipe for both LLMs and MLLMs. F Case Studies We provide qualitative case studies ofUni-OPD, standard OPD, and the Student model across both LLM and MLLM benchmarks, covering textual math reasoning, code generation...
1996
-
[64]
In 1996, Coal is shown as 35% of total output
So:\n\nNuclear output in 2006 = 2 × 70 TWh = 140 TWh.\n\nThus, the correct answer is:\n\n<answer>A</answer> Uni-OPD: To solve this, we first need to find the output for Coal in 1996 from the chart. In 1996, Coal is shown as 35% of total output. Since total output in 1996 was 200 TWh, Coal output in 1996 is:\n\n35% of 200 TWh = 0.35 × 200 = 70 TWh.\n\nThe ...
2006
-
[65]
\\boxed{}\
So:\n\nNuclear in 2006 = 2 × 70 TWh = 140 TWh.\n\nLooking at the options, (A) 140TWh matches this value.\n\n<answer>A</answer> logicvista Figure F.4:Example output of LogicVista.All three models correctly answer this multi-step arithmetic reasoning question. OPD andUni-OPDboth reason concisely, withUni-OPDbeing slightly more token-efficient. 38.png Questi...
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.