Recognition: unknown
DMGD: Train-Free Dataset Distillation with Semantic-Distribution Matching in Diffusion Models
Pith reviewed 2026-05-07 17:35 UTC · model grok-4.3
The pith
A training-free diffusion method creates small synthetic datasets that outperform fine-tuned distillation approaches on ImageNet subsets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
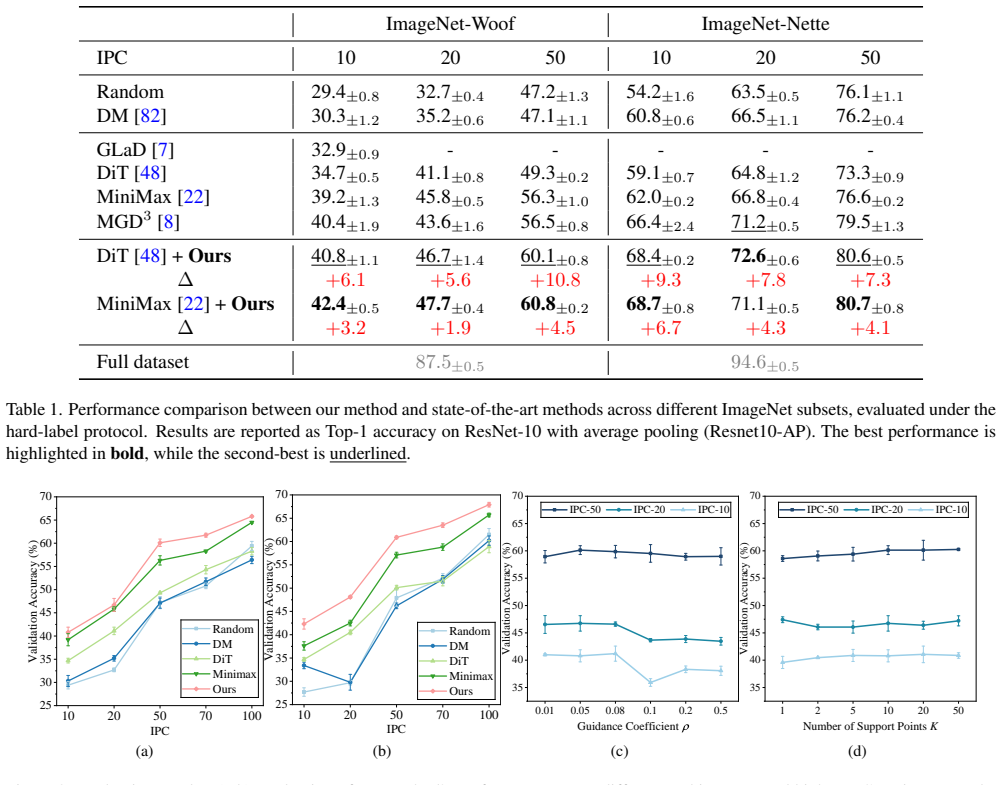
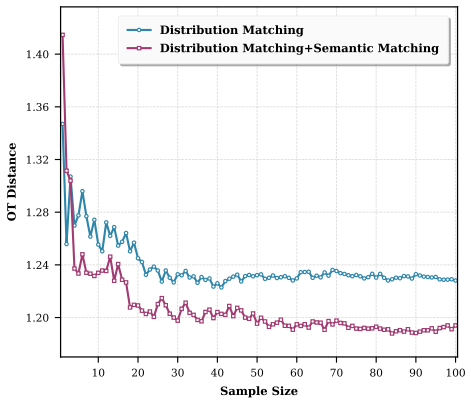
The authors establish the DMGD framework for training-free dataset distillation. Semantic Matching occurs via conditional likelihood optimization that eliminates auxiliary classifiers. A dynamic guidance mechanism improves sample diversity while preserving alignment. An optimal transport based Distribution Matching step further aligns the synthetic data with the target distribution structure. Two efficiency strategies, Distribution Approximate Matching and Greedy Progressive Matching, allow the full process to run with low overhead. Experiments show the resulting synthetic sets improve downstream accuracy over prior methods that require fine-tuning.
What carries the argument
The DMGD framework, which performs semantic matching through conditional likelihood optimization, dynamic guidance for diversity, and optimal transport distribution matching together with approximate and progressive efficiency strategies.
If this is right
- Synthetic datasets produced without fine-tuning can yield higher downstream classification accuracy than those from methods that include fine-tuning stages.
- Optimal transport distribution matching preserves structural properties of the original large dataset in the much smaller synthetic version.
- Dynamic guidance during diffusion sampling can maintain semantic correctness while increasing the variety of generated samples.
- Approximate and progressive matching strategies allow distribution alignment to occur with only modest extra computation.
Where Pith is reading between the lines
- The same dual-matching idea could be tested on other generative backbones such as GANs or flow models to see if training-free distillation generalizes beyond diffusion.
- If the matching mechanisms hold, similar techniques might reduce the data requirements for training large vision models in resource-constrained settings.
- The approach suggests that diffusion models already encode enough dataset statistics to support distillation once the right guidance signals are supplied.
- Extending the method to video or multimodal datasets would test whether the semantic and distribution matching components remain effective outside static images.
Load-bearing premise
Semantic matching via conditional likelihood optimization combined with optimal transport distribution matching and dynamic guidance can produce high-quality diverse synthetic data that supports strong downstream model performance without fine-tuning or auxiliary classifiers.
What would settle it
Generate the synthetic dataset on ImageNet-1K using the described DMGD procedure, train a standard classifier on it, and check whether accuracy exceeds the reported SOTA fine-tuned baselines by roughly 2.4 percent.
Figures







read the original abstract
Dataset distillation enables efficient training by distilling the information of large-scale datasets into significantly smaller synthetic datasets. Diffusion based paradigms have emerged in recent years, offering novel perspectives for dataset distillation. However, they typically necessitate additional fine-tuning stages, and effective guidance mechanisms remain underexplored. To address these limitations, we rethink diffusion based dataset distillation and propose a Dual Matching Guided Diffusion (DMGD) framework, centered on efficient training-free guidance. We first establish Semantic Matching via conditional likelihood optimization, eliminating the need for auxiliary classifiers. Furthermore, we propose a dynamic guidance mechanism that enhances the diversity of synthetic data while maintaining semantic alignment. Simultaneously, we introduce an optimal transport (OT) based Distribution Matching approach to further align with the target distribution structure. To ensure efficiency, we develop two enhanced strategies for diffusion based framework: Distribution Approximate Matching and Greedy Progressive Matching. These strategies enable effective distribution matching guidance with minimal computational overhead. Experimental results on ImageNet-Woof, ImageNet-Nette, and ImageNet-1K demonstrate that our training-free approach achieves significant improvements, outperforming state-of-the-art (SOTA) methods requiring additional fine-tuning by average accuracy gains of 2.1%, 5.4%, and 2.4%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DMGD, a training-free dataset distillation framework for diffusion models. It introduces semantic matching through conditional likelihood optimization (no auxiliary classifier), a dynamic guidance mechanism to improve diversity while preserving alignment, and an OT-based distribution matching step. Two efficiency strategies (Distribution Approximate Matching and Greedy Progressive Matching) are added to keep overhead low. Experiments on ImageNet-Woof, ImageNet-Nette, and ImageNet-1K report average accuracy gains of 2.1%, 5.4%, and 2.4% over fine-tuned SOTA baselines.
Significance. If the empirical claims hold, the result would be significant: it removes the fine-tuning stage and auxiliary-classifier requirement that have been standard in recent diffusion-based distillation work, while still delivering measurable downstream gains. The combination of likelihood-based semantic guidance with OT distribution alignment and the two lightweight matching approximations constitutes a coherent, self-contained pipeline that could simplify large-scale synthetic-data generation.
major comments (2)
- [§4] §4 (Method), the conditional-likelihood formulation for semantic matching: the paper states that this step eliminates auxiliary classifiers, yet the precise objective (e.g., the form of the likelihood term and how it is optimized inside the diffusion sampling loop) is not written as an equation or algorithm; without it, it is impossible to confirm that the procedure is truly classifier-free and does not implicitly rely on pre-trained embeddings that function equivalently.
- [§5] §5 (Experiments), Tables 1–3: the reported accuracy improvements (2.1–5.4 %) are given as point estimates without error bars, number of random seeds, or statistical significance tests. Because the central claim is that DMGD outperforms fine-tuned SOTA, the absence of these controls makes it impossible to judge whether the gains are robust or could be explained by variance in the downstream training.
minor comments (3)
- [Abstract, §3.2] The abstract and §3.2 mention “dynamic guidance” but never define the schedule or the hyper-parameter that trades off diversity versus alignment; a short equation or pseudocode would clarify the mechanism.
- [§4.3] Notation for the OT cost matrix and the approximate matching strategies is introduced without a reference to the specific OT solver or the approximation error bound; adding one sentence and a citation would improve reproducibility.
- [Figure 2] Figure 2 (qualitative samples) lacks a side-by-side comparison with the strongest baseline at the same IPC; this would help readers visually assess the claimed diversity improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. The comments help improve the clarity of the method and the robustness of the empirical claims. We address each major comment below and commit to the corresponding revisions.
read point-by-point responses
-
Referee: [§4] §4 (Method), the conditional-likelihood formulation for semantic matching: the paper states that this step eliminates auxiliary classifiers, yet the precise objective (e.g., the form of the likelihood term and how it is optimized inside the diffusion sampling loop) is not written as an equation or algorithm; without it, it is impossible to confirm that the procedure is truly classifier-free and does not implicitly rely on pre-trained embeddings that function equivalently.
Authors: We appreciate the referee's observation. Section 4 describes semantic matching through conditional likelihood optimization to remove the need for auxiliary classifiers, but we agree that an explicit equation and algorithmic presentation are required for full verification and reproducibility. In the revised manuscript we will introduce a dedicated equation for the likelihood objective and add pseudocode (as a new algorithm) that details its optimization inside the diffusion sampling loop, explicitly showing that the procedure remains classifier-free and operates directly on the diffusion model's conditional likelihood without relying on equivalent pre-trained embeddings. revision: yes
-
Referee: [§5] §5 (Experiments), Tables 1–3: the reported accuracy improvements (2.1–5.4 %) are given as point estimates without error bars, number of random seeds, or statistical significance tests. Because the central claim is that DMGD outperforms fine-tuned SOTA, the absence of these controls makes it impossible to judge whether the gains are robust or could be explained by variance in the downstream training.
Authors: The referee correctly notes that the current tables report only point estimates. While the experiments followed fixed protocols, variability across random seeds and formal significance testing were not included. We will rerun the evaluations on ImageNet-Woof, ImageNet-Nette, and ImageNet-1K using at least five random seeds, update Tables 1–3 to display mean accuracy together with standard deviations, and add paired statistical significance tests against the fine-tuned baselines. These additions will appear in the revised manuscript and will strengthen the evidence for the reported gains. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces a DMGD framework for training-free dataset distillation via semantic matching through conditional likelihood optimization, dynamic guidance for diversity, and OT-based distribution matching, plus two efficiency strategies (Distribution Approximate Matching and Greedy Progressive Matching). No equations, derivations, or first-principles results are presented that reduce any claim to its own inputs by construction. The central performance claims rest on empirical results for ImageNet subsets rather than fitted parameters renamed as predictions or self-citation chains. The method is self-contained, with no load-bearing self-citations or ansatzes smuggled in; external benchmarks and reported accuracy gains provide independent support.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Conditional likelihood optimization can achieve semantic matching without auxiliary classifiers
- domain assumption Optimal transport effectively aligns synthetic and target data distributions for distillation
Forward citations
Cited by 1 Pith paper
-
Offline Preference Optimization for Rectified Flow with Noise-Tracked Pairs
PNAPO augments preference data with prior noise pairs and uses straight-line interpolation to create a tighter surrogate objective for offline alignment of rectified flow models.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[2]
Geometric dataset distances via optimal transport.Advances in Neural Infor- mation Processing Systems, 33:21428–21439, 2020
David Alvarez-Melis and Nicolo Fusi. Geometric dataset distances via optimal transport.Advances in Neural Infor- mation Processing Systems, 33:21428–21439, 2020. 8, 9
2020
-
[3]
Wasserstein generative adversarial networks
Martin Arjovsky et al. Wasserstein generative adversarial networks. InInternational conference on machine learning, pages 214–223. PMLR, 2017. 2, 4
2017
-
[4]
Learning probability measures with respect to optimal transport metrics.Advances in neural in- formation processing systems, 25, 2012
Guillermo Canas et al. Learning probability measures with respect to optimal transport metrics.Advances in neural in- formation processing systems, 25, 2012. 1, 5, 6
2012
-
[5]
Hengyuan Cao, Yutong Feng, Biao Gong, Yijing Tian, Yun- hong Lu, Chuang Liu, and Bin Wang. Dimension-reduction attack! video generative models are experts on controllable image synthesis.arXiv preprint arXiv:2505.23325, 2025. 1
-
[6]
Dataset distillation by matching training trajectories
George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A Efros, and Jun-Yan Zhu. Dataset distillation by matching training trajectories. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4750–4759, 2022. 1, 2
2022
-
[7]
Generalizing dataset distillation via deep generative prior
George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A Efros, and Jun-Yan Zhu. Generalizing dataset distillation via deep generative prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3739–3748, 2023. 2, 5, 6, 7, 11
2023
-
[8]
Jeffrey A Chan-Santiago, Praveen Tirupattur, Gaurav Kumar Nayak, Gaowen Liu, and Mubarak Shah. Mgd 3: Mode- guided dataset distillation using diffusion models.arXiv preprint arXiv:2505.18963, 2025. 1, 2, 6, 7, 8, 4, 9, 10, 11
-
[9]
Rapverse: Coherent vocals and whole- body motion generation from text
Jiaben Chen, Xin Yan, Yihang Chen, Siyuan Cen, Zixin Wang, Qinwei Ma, Haoyu Zhen, Kaizhi Qian, Lie Lu, and Chuang Gan. Rapverse: Coherent vocals and whole- body motion generation from text. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10097–10107, 2025. 14
2025
-
[10]
Influence-guided diffusion for dataset distillation
Mingyang Chen, Jiawei Du, Bo Huang, Yi Wang, Xiaobo Zhang, and Wei Wang. Influence-guided diffusion for dataset distillation. InThe Thirteenth International Conference on Learning Representations, 2025. 2, 4
2025
-
[11]
Optimal transport for domain adaptation.IEEE transactions on pattern analysis and machine intelligence, 39(9):1853–1865, 2016
Nicolas Courty, R ´emi Flamary, Devis Tuia, and Alain Rako- tomamonjy. Optimal transport for domain adaptation.IEEE transactions on pattern analysis and machine intelligence, 39(9):1853–1865, 2016. 3
2016
-
[12]
Diffusion models in vision: A survey
Florinel-Alin Croitoru, Vlad Hondru, Radu Tudor Ionescu, and Mubarak Shah. Diffusion models in vision: A survey. IEEE transactions on pattern analysis and machine intelli- gence, 45(9):10850–10869, 2023. 2
2023
-
[13]
Scaling up dataset distillation to imagenet-1k with constant memory
Justin Cui, Ruochen Wang, Si Si, and Cho-Jui Hsieh. Scaling up dataset distillation to imagenet-1k with constant memory. InInternational Conference on Machine Learning, pages 6565–6590. PMLR, 2023. 2
2023
-
[14]
Optical: Leveraging optimal transport for con- tribution allocation in dataset distillation
Xiao Cui, Yulei Qin, Wengang Zhou, Hongsheng Li, and Houqiang Li. Optical: Leveraging optimal transport for con- tribution allocation in dataset distillation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15245–15254, 2025. 2
2025
-
[15]
Xiao Cui, Yulei Qin, Wengang Zhou, Hongsheng Li, and Houqiang Li. Optimizing distributional geometry align- ment with optimal transport for generative dataset distilla- tion.arXiv preprint arXiv:2512.00308, 2025. 2
-
[16]
Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information pro- cessing systems, 26, 2013
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information pro- cessing systems, 26, 2013. 3, 5
2013
-
[17]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 6
2009
-
[18]
Sequential subset matching for dataset distillation.Advances in Neural Infor- mation Processing Systems, 36:67487–67504, 2023
Jiawei Du, Qin Shi, and Joey Tianyi Zhou. Sequential subset matching for dataset distillation.Advances in Neural Infor- mation Processing Systems, 36:67487–67504, 2023. 2
2023
-
[19]
Inter- polating between optimal transport and mmd using sinkhorn divergences
Jean Feydy, Thibault S ´ejourn´e, Franc ¸ois-Xavier Vialard, Shun-ichi Amari, Alain Trouv ´e, and Gabriel Peyr ´e. Inter- polating between optimal transport and mmd using sinkhorn divergences. InThe 22nd international conference on arti- ficial intelligence and statistics, pages 2681–2690. PMLR,
-
[20]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014. 2
2014
-
[21]
Optimum quantization and its applications
Peter M Gruber. Optimum quantization and its applications. Advances in Mathematics, 186(2):456–497, 2004. 5
2004
-
[22]
Efficient dataset distillation via minimax diffusion
Jianyang Gu, Saeed Vahidian, Vyacheslav Kungurtsev, Hao- nan Wang, Wei Jiang, Yang You, and Yiran Chen. Efficient dataset distillation via minimax diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15793–15803, 2024. 1, 2, 6, 7, 8, 4, 9, 10, 11
2024
-
[23]
arXiv preprint arXiv:2310.05773 , year=
Ziyao Guo, Kai Wang, George Cazenavette, Hui Li, Kaipeng Zhang, and Yang You. Towards lossless dataset distillation via difficulty-aligned trajectory matching.arXiv preprint arXiv:2310.05773, 2023. 2
-
[24]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 9
2016
-
[25]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 2, 4
work page internal anchor Pith review arXiv 2022
-
[26]
Denoising diffusion probabilistic mod- els.Advances in neural information processing systems, 33: 6840–6851, 2020
Jonathan Ho et al. Denoising diffusion probabilistic mod- els.Advances in neural information processing systems, 33: 6840–6851, 2020. 2, 3, 1
2020
-
[27]
Imagenette: A smaller subset of 10 easily classified classes from imagenet, 2019
Jeremy Howard. Imagenette: A smaller subset of 10 easily classified classes from imagenet, 2019. 9
2019
-
[28]
Dataset condensation via efficient synthetic- data parameterization
Jang-Hyun Kim, Jinuk Kim, Seong Joon Oh, Sangdoo Yun, Hwanjun Song, Joonhyun Jeong, Jung-Woo Ha, and Hyun Oh Song. Dataset condensation via efficient synthetic- data parameterization. InInternational Conference on Ma- chine Learning, pages 11102–11118. PMLR, 2022. 2, 9, 10, 11
2022
-
[29]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding varia- tional bayes.arXiv preprint arXiv:1312.6114, 2013. 3, 1
work page internal anchor Pith review arXiv 2013
-
[30]
Okan Koc ¸, Alexander Soen, Chao-Kai Chiang, and Masashi Sugiyama. Domain adaptation and entanglement: an opti- mal transport perspective.arXiv preprint arXiv:2503.08155,
-
[31]
Dataset distillation from first principles: Integrating core in- formation extraction and purposeful learning, 2024
Vyacheslav Kungurtsev, Yuanfang Peng, Jianyang Gu, Saeed Vahidian, Anthony Quinn, Fadwa Idlahcen, and Yiran Chen. Dataset distillation from first principles: Integrating core in- formation extraction and purposeful learning, 2024. 1
2024
-
[32]
A comprehensive survey of dataset distillation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(1):17–32, 2023
Shiye Lei and Dacheng Tao. A comprehensive survey of dataset distillation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(1):17–32, 2023. 1
2023
-
[33]
Towards un- derstanding camera motions in any video.arXiv preprint arXiv:2504.15376,
Zhiqiu Lin, Siyuan Cen, Daniel Jiang, Jay Karhade, Hewei Wang, Chancharik Mitra, Tiffany Ling, Yuhan Huang, Sifan Liu, Mingyu Chen, et al. Towards understanding camera mo- tions in any video.arXiv preprint arXiv:2504.15376, 2025. 1
-
[34]
Dataset distillation by automatic training trajecto- ries
Dai Liu, Jindong Gu, Hu Cao, Carsten Trinitis, and Martin Schulz. Dataset distillation by automatic training trajecto- ries. InEuropean Conference on Computer Vision, pages 334–351. Springer, 2024. 2
2024
-
[35]
Dataset distillation via the wasserstein metric.arXiv preprint arXiv:2311.18531,
Haoyang Liu, Yijiang Li, Tiancheng Xing, Vibhu Dalal, Luwei Li, Jingrui He, and Haohan Wang. Dataset distillation via the wasserstein metric.arXiv preprint arXiv:2311.18531,
-
[36]
Dataset distillation via factorization.Ad- vances in neural information processing systems, 35:1100– 1113, 2022
Songhua Liu, Kai Wang, Xingyi Yang, Jingwen Ye, and Xinchao Wang. Dataset distillation via factorization.Ad- vances in neural information processing systems, 35:1100– 1113, 2022. 2
2022
-
[37]
Dream: Efficient dataset distillation by rep- resentative matching
Yanqing Liu, Jianyang Gu, Kai Wang, Zheng Zhu, Wei Jiang, and Yang You. Dream: Efficient dataset distillation by rep- resentative matching. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 17314– 17324, 2023. 6, 2
2023
-
[38]
Discovery of the reward function for embod- ied reinforcement learning agents.Nature Communications, 16(1):11064, 2025
Renzhi Lu, Zonghe Shao, Yuemin Ding, Ruijuan Chen, Don- grui Wu, Housheng Su, Tao Yang, Fumin Zhang, Jun Wang, Yang Shi, et al. Discovery of the reward function for embod- ied reinforcement learning agents.Nature Communications, 16(1):11064, 2025. 14
2025
-
[39]
Inpo: Inversion preference optimization with reparametrized ddim for efficient diffusion model alignment
Yunhong Lu, Qichao Wang, Hengyuan Cao, Xierui Wang, Xiaoyin Xu, and Min Zhang. Inpo: Inversion preference optimization with reparametrized ddim for efficient diffusion model alignment. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28629–28639, 2025. 1
2025
-
[40]
Yunhong Lu, Qichao Wang, Hengyuan Cao, Xiaoyin Xu, and Min Zhang. Smoothed preference optimization via renoise inversion for aligning diffusion models with varied human preferences.arXiv preprint arXiv:2506.02698, 2025. 1
-
[41]
Yunhong Lu, Yanhong Zeng, Haobo Li, Hao Ouyang, Qi- uyu Wang, Ka Leong Cheng, Jiapeng Zhu, Hengyuan Cao, Zhipeng Zhang, Xing Zhu, et al. Reward forcing: Ef- ficient streaming video generation with rewarded distribu- tion matching distillation.arXiv preprint arXiv:2512.04678,
-
[42]
Visualizing data using t-sne.Journal of machine learning research, 9 (Nov):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9 (Nov):2579–2605, 2008. 9
2008
-
[43]
Recent advances in optimal transport for machine learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Eduardo Fernandes Montesuma et al. Recent advances in optimal transport for machine learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 3
2024
-
[44]
Unlocking dataset distillation with diffusion models.arXiv preprint arXiv:2403.03881,
Brian B Moser, Federico Raue, Sebastian Palacio, Stanislav Frolov, and Andreas Dengel. Unlocking dataset distillation with diffusion models.arXiv preprint arXiv:2403.03881,
-
[45]
Reliable fidelity and diversity metrics for generative models
Muhammad Ferjad Naeem, Seong Joon Oh, Youngjung Uh, Yunjey Choi, and Jaejun Yoo. Reliable fidelity and diversity metrics for generative models. InInternational conference on machine learning, pages 7176–7185. PMLR, 2020. 8, 9
2020
-
[46]
fast-pytorch-kmeans, 2020
Sehban Omer. fast-pytorch-kmeans, 2020. 8
2020
-
[47]
On aliased resizing and surprising subtleties in gan evaluation
Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. On aliased resizing and surprising subtleties in gan evaluation. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 11410–11420, 2022. 9
2022
-
[48]
Scalable diffusion models with trans- formers
William Peebles et al. Scalable diffusion models with trans- formers. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 4195–4205, 2023. 6, 7, 8, 9, 11
2023
-
[49]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 3, 1
2022
-
[50]
Seyedmorteza Sadat, Jakob Buhmann, Derek Bradley, Otmar Hilliges, and Romann M Weber. Cads: Unleashing the di- versity of diffusion models through condition-annealed sam- pling.arXiv preprint arXiv:2310.17347, 2023. 4, 5
-
[51]
Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural in- formation processing systems, 35:25278–25294, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural in- formation processing systems, 35:25278–25294, 2022. 1
2022
-
[52]
Generalized large-scale data condensa- tion via various backbone and statistical matching
Shitong Shao, Zeyuan Yin, Muxin Zhou, Xindong Zhang, and Zhiqiang Shen. Generalized large-scale data condensa- tion via various backbone and statistical matching. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16709–16718, 2024. 6, 8, 2, 4
2024
-
[53]
A novel data-driven lstm-saf model for power systems transient stability assessment.IEEE Transac- tions on Industrial Informatics, 20(7):9083–9097, 2024
Zonghe Shao, Qichao Wang, Yuzhe Cao, Defu Cai, Yang You, and Renzhi Lu. A novel data-driven lstm-saf model for power systems transient stability assessment.IEEE Transac- tions on Industrial Informatics, 20(7):9083–9097, 2024. 14
2024
-
[54]
Delt: A simple diversity-driven earlylate training for dataset distillation
Zhiqiang Shen, Ammar Sherif, Zeyuan Yin, and Shitong Shao. Delt: A simple diversity-driven earlylate training for dataset distillation. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 4797–4806,
-
[55]
Ot-clip: Understanding and general- izing clip via optimal transport
Liangliang Shi et al. Ot-clip: Understanding and general- izing clip via optimal transport. InForty-first International Conference on Machine Learning, 2024. 6
2024
-
[56]
Distilling dataset into neural field.arXiv preprint arXiv:2503.04835, 2025
Donghyeok Shin, HeeSun Bae, Gyuwon Sim, Wanmo Kang, and Il-Chul Moon. Distilling dataset into neural field.arXiv preprint arXiv:2503.04835, 2025. 2
-
[57]
Loss-curvature matching for dataset selection and condensation
Seungjae Shin, Heesun Bae, Donghyeok Shin, Weonyoung Joo, and Il-Chul Moon. Loss-curvature matching for dataset selection and condensation. InInternational Conference on Artificial Intelligence and Statistics, pages 8606–8628. PMLR, 2023. 2
2023
-
[58]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014. 9
work page internal anchor Pith review arXiv 2014
-
[59]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 1, 2
work page internal anchor Pith review arXiv 2010
-
[60]
Dˆ4: Dataset distillation via disentangled diffusion model
Duo Su, Junjie Hou, Weizhi Gao, Yingjie Tian, and Bowen Tang. Dˆ4: Dataset distillation via disentangled diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5809–5818, 2024. 2, 6, 8, 4, 9
2024
-
[61]
On the diversity and realism of distilled dataset: An efficient dataset distilla- tion paradigm
Peng Sun, Bei Shi, Daiwei Yu, and Tao Lin. On the diversity and realism of distilled dataset: An efficient dataset distilla- tion paradigm. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9390– 9399, 2024. 6, 8, 2, 4, 9
2024
-
[62]
Discriminative adversarial domain adaptation
Hui Tang and Kui Jia. Discriminative adversarial domain adaptation. InProceedings of the AAAI conference on artifi- cial intelligence, pages 5940–5947, 2020. 3
2020
-
[63]
Minority-focused text-to- image generation via prompt optimization
Soobin Um and Jong Chul Ye. Minority-focused text-to- image generation via prompt optimization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 20926–20936, 2025. 2, 4
2025
-
[64]
Springer, 2008
C ´edric Villani et al.Optimal transport: old and new. Springer, 2008. 3
2008
-
[65]
Dim: Distilling dataset into genera- tive model, 2023
Kai Wang, Jianyang Gu, Daquan Zhou, Zheng Zhu, Wei Jiang, and Yang You. Dim: Distilling dataset into genera- tive model, 2023. 2
2023
-
[66]
Dataset dis- tillation with neural characteristic function: A minmax per- spective
Shaobo Wang, Yicun Yang, Zhiyuan Liu, Chenghao Sun, Xuming Hu, Conghui He, and Linfeng Zhang. Dataset dis- tillation with neural characteristic function: A minmax per- spective. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 25570–25580, 2025. 2
2025
-
[67]
Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba, and Alexei A. Efros. Dataset distillation, 2020. 1
2020
-
[68]
Transferable attention for domain adapta- tion
Ximei Wang, Liang Li, Weirui Ye, Mingsheng Long, and Jianmin Wang. Transferable attention for domain adapta- tion. InProceedings of the AAAI conference on artificial intelligence, pages 5345–5352, 2019. 3
2019
-
[69]
Herding dynamical weights to learn
Max Welling. Herding dynamical weights to learn. InPro- ceedings of the 26th annual international conference on ma- chine learning, pages 1121–1128, 2009. 10
2009
-
[70]
Lingao Xiao and Yang He. Are large-scale soft labels nec- essary for large-scale dataset distillation?arXiv preprint arXiv:2410.15919, 2024. 2, 4
-
[71]
Difffit: Un- locking transferability of large diffusion models via sim- ple parameter-efficient fine-tuning
Enze Xie, Lewei Yao, Han Shi, Zhili Liu, Daquan Zhou, Zhaoqiang Liu, Jiawei Li, and Zhenguo Li. Difffit: Un- locking transferability of large diffusion models via sim- ple parameter-efficient fine-tuning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4230–4239, 2023. 2
2023
-
[72]
Towards adversarially robust dataset distillation by curvature regularization
Eric Xue, Yijiang Li, Haoyang Liu, Peiran Wang, Yifan Shen, and Haohan Wang. Towards adversarially robust dataset distillation by curvature regularization. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 9041–9049, 2025. 2
2025
-
[73]
What is dataset distillation learning?, 2024
William Yang, Ye Zhu, Zhiwei Deng, and Olga Russakovsky. What is dataset distillation learning?, 2024. 1
2024
-
[74]
Tfg: Unified training-free guidance for diffusion mod- els.Advances in Neural Information Processing Systems, 37: 22370–22417, 2024
Haotian Ye, Haowei Lin, Jiaqi Han, Minkai Xu, Sheng Liu, Yitao Liang, Jianzhu Ma, James Y Zou, and Stefano Er- mon. Tfg: Unified training-free guidance for diffusion mod- els.Advances in Neural Information Processing Systems, 37: 22370–22417, 2024. 8
2024
-
[75]
Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective
Zeyuan Yin et al. Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective. Advances in Neural Information Processing Systems, 36: 73582–73603, 2023. 1, 4, 6, 8, 2
2023
-
[76]
Freedom: Training-free energy-guided condi- tional diffusion model
Jiwen Yu, Yinhuai Wang, Chen Zhao, Bernard Ghanem, and Jian Zhang. Freedom: Training-free energy-guided condi- tional diffusion model. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 23174– 23184, 2023. 3, 4, 5, 1, 6, 8, 12
2023
-
[77]
Dataset condensation via generative model, 2023
David Junhao Zhang, Heng Wang, Chuhui Xue, Rui Yan, Wenqing Zhang, Song Bai, and Mike Zheng Shou. Dataset condensation via generative model, 2023. 2
2023
-
[78]
Gsdd: generative space dataset distillation for image super-resolution
Haiyu Zhang, Shaolin Su, Yu Zhu, Jinqiu Sun, and Yanning Zhang. Gsdd: generative space dataset distillation for image super-resolution. InProceedings of the AAAI Conference on Artificial Intelligence, pages 7069–7077, 2024. 2
2024
-
[79]
Junyi Zhang, Yiming Wang, Yunhong Lu, Qichao Wang, Wenzhe Qian, Xiaoyin Xu, David Gu, and Min Zhang. Spherical geometry diffusion: Generating high-quality 3d face geometry via sphere-anchored representations.arXiv preprint arXiv:2601.13371, 2026. 1
-
[80]
Dataset condensation with differ- entiable siamese augmentation
Bo Zhao and Hakan Bilen. Dataset condensation with differ- entiable siamese augmentation. InInternational Conference on Machine Learning, pages 12674–12685. PMLR, 2021. 2
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.