Recognition: no theorem link
Offline Preference Optimization for Rectified Flow with Noise-Tracked Pairs
Pith reviewed 2026-05-12 02:05 UTC · model grok-4.3
The pith
Keeping the exact prior noise sample for each winner and loser image tightens the preference objective for rectified flow generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Augmenting each preference triplet into a sextuple that includes the paired prior noises, then estimating intermediate states via linear noise-image interpolation under the straight-line property of rectified flow, produces a tighter surrogate for the preference optimization objective; an adaptive regularizer that depends on the winner-loser reward gap and training progress further improves stability and sample efficiency.
What carries the argument
Prior Noise-Aware Preference Optimization (PNAPO), which augments data to (prompt, winner image, loser image, winner prior noise, loser prior noise) sextuples and substitutes noise-image linear interpolation for independent noising when constructing the DPO-style loss.
If this is right
- Trajectory estimation variance drops because the interpolation is constrained to the model's actual generation path rather than an independent forward process.
- The dynamic regularizer reduces the need for manual hyperparameter tuning by automatically weakening the penalty when the reward gap is large or training is early.
- The method works entirely offline on existing preference datasets once the prior noises are added, without requiring online sampling or model changes at inference time.
- Training compute decreases substantially because fewer gradient steps are needed to reach the same or better preference scores.
Where Pith is reading between the lines
- Preference data pipelines for flow-based generators should routinely record and store the initial noise sample alongside each image to enable this form of alignment.
- The same noise-tracking idea could be tested on other straight-trajectory generative models to see whether the compute savings generalize beyond rectified flow.
- If the straight-line assumption proves robust, future alignment work might shift from full-trajectory simulation to simple interpolation, lowering the barrier for smaller research groups.
Load-bearing premise
That storing the exact prior noise for every image in a preference dataset remains practical at scale and that straight-line interpolation between noise and image introduces no systematic bias into the preference signal.
What would settle it
A controlled experiment on the same preference pairs showing that replacing the recorded prior noises with freshly sampled independent noises produces equal or higher final preference metrics and equal or lower compute cost would falsify the claimed advantage.
Figures







read the original abstract
Existing preference datasets for text-to-image models typically store only the final winner/loser images. This representation is insufficient for rectified flow (RF) models, whose generation is naturally indexed by a specific prior noise sample and follows a nearly straight denoising trajectory. In contrast, prior DPO-style alignment for diffusion models commonly estimates trajectories using an independent forward noising process, which can be mismatched to the true reverse dynamics and introduces unnecessary variance. We propose Prior Noise-Aware Preference Optimization (PNAPO), an off-policy alignment framework specialized for rectified flow. PNAPO augments preference data by retaining the paired prior noises used to generate each winner/loser image, turning the standard (prompt, winner, loser) triplet into a sextuple. Leveraging the straight-line property of RF, we estimate intermediate states via noise-image interpolation, which constrains the trajectory estimation space and yields a tighter surrogate objective for preference optimization. In addition, we introduce a dynamic regularization strategy that adapts the DPO regularization based on (i) the reward gap between winner and loser and (ii) training progress, improving stability and sample efficiency. Experiments on state-of-the-art RF T2I backbones show that PNAPO consistently improves preference metrics while substantially reducing training compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Prior Noise-Aware Preference Optimization (PNAPO) for offline alignment of rectified flow (RF) text-to-image models. It augments standard preference triplets with the paired prior noise samples used to generate each winner and loser image, then leverages the (nearly) straight-line property of RF trajectories to interpolate intermediate states and form a tighter surrogate for the preference loss. A dynamic regularization term is added that adapts the DPO-style penalty using the observed reward gap and training progress. The authors claim that this yields consistent gains on preference metrics while substantially lowering training compute relative to prior diffusion-style DPO on state-of-the-art RF backbones.
Significance. If the interpolation is shown to be unbiased and the reported gains are supported by proper baselines and ablations, the work would offer a practical, RF-specific improvement to offline preference optimization. Retaining and reusing the original prior noises directly addresses a known mismatch between independent noising and the true reverse dynamics of RF models, which could translate into more sample-efficient alignment for a class of generators that is currently dominant in text-to-image research.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the central claim that noise-image interpolation produces a 'tighter surrogate' rests on the assumption that RF trajectories are sufficiently linear for the interpolated points to lie on the true denoising path. The abstract itself qualifies the trajectories as only 'nearly straight,' yet no error analysis, trajectory deviation measurements, or ablation comparing interpolated versus actual intermediate states is referenced. This assumption is load-bearing for both the correctness of the preference loss and the claimed compute reduction versus independent-noising DPO.
- [Experiments] Experiments section: the abstract asserts that PNAPO 'consistently improves preference metrics while substantially reducing training compute,' but the provided text supplies no quantitative numbers, baseline comparisons, or ablation results. Without these, it is impossible to judge effect sizes, the relative contribution of the interpolation versus the dynamic regularizer, or whether the compute savings are robust across model scales.
minor comments (2)
- [§3.1] The transition from the conventional (prompt, winner, loser) triplet to the proposed sextuple is described in prose but would benefit from an explicit equation or table defining the augmented data structure and the interpolation formula.
- [§3.3] Notation for the dynamic regularization schedule (reward-gap and progress terms) is introduced without a clear equation reference; adding a numbered equation would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to clarify our contributions to offline preference optimization for rectified flow models. We address each major comment point-by-point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the central claim that noise-image interpolation produces a 'tighter surrogate' rests on the assumption that RF trajectories are sufficiently linear for the interpolated points to lie on the true denoising path. The abstract itself qualifies the trajectories as only 'nearly straight,' yet no error analysis, trajectory deviation measurements, or ablation comparing interpolated versus actual intermediate states is referenced. This assumption is load-bearing for both the correctness of the preference loss and the claimed compute reduction versus independent-noising DPO.
Authors: We appreciate the referee highlighting the importance of rigorously justifying the linearity assumption underlying our interpolation approach. Rectified flow trajectories are known to follow (nearly) straight paths in expectation, a property central to the RF formulation and leveraged in prior RF literature to enable efficient sampling. Our noise-tracked interpolation exploits this to constrain the trajectory space and reduce variance relative to independent noising. We agree, however, that an explicit error analysis would make the 'tighter surrogate' claim more robust. In the revised manuscript we will add a dedicated subsection (in §3 or the appendix) that quantifies trajectory deviation by comparing linearly interpolated states against actual intermediate outputs from the RF model on a held-out set of samples. We will also include an ablation that measures the effect of this approximation on the preference loss and overall alignment performance. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts that PNAPO 'consistently improves preference metrics while substantially reducing training compute,' but the provided text supplies no quantitative numbers, baseline comparisons, or ablation results. Without these, it is impossible to judge effect sizes, the relative contribution of the interpolation versus the dynamic regularizer, or whether the compute savings are robust across model scales.
Authors: We acknowledge that the experimental results need to be presented with greater clarity and detail to allow proper evaluation of effect sizes and component contributions. The full manuscript contains an experiments section (§4) reporting results on state-of-the-art RF text-to-image backbones, but we agree these should be expanded for accessibility. In the revision we will augment §4 with explicit quantitative tables showing preference metric improvements (e.g., win rates), direct baseline comparisons against diffusion-style DPO and other offline methods, ablations isolating the noise-aware interpolation and dynamic regularizer, and compute measurements (training FLOPs and wall-clock time) across multiple model scales. These additions will make the claimed gains and efficiency benefits fully transparent. revision: yes
Circularity Check
No significant circularity; derivation relies on external RF properties and observable quantities
full rationale
The paper augments preference data with retained prior noises (an implementation choice) and derives the surrogate objective by interpolating along the line connecting noise to image, explicitly leveraging the known straight-line property of rectified flows as stated in the abstract. This interpolation is not self-definitional because the linearity assumption originates from prior RF literature rather than being fitted or defined within the present objective. The dynamic regularization term adapts explicitly to the observable reward gap between winner/loser and to training progress, both of which are external to the loss itself and not obtained by fitting the target quantity. No equation reduces a prediction to a fitted parameter by construction, no uniqueness theorem is imported via self-citation, and no ansatz is smuggled through prior work by the same authors. The central claim therefore remains independent of its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rectified flow models follow nearly straight denoising trajectories from prior noise to image.
Reference graph
Works this paper leans on
-
[1]
Training Diffusion Models with Reinforcement Learning
Black, K., Janner, M., Du, Y ., Kostrikov, I., and Levine, S. Training diffusion models with reinforcement learning. arXiv preprint arXiv:2305.13301,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Preference-based alignment of discrete diffusion mod- els.arXiv preprint arXiv:2503.08295,
Borso, U., Paglieri, D., Wells, J., and Rockt ¨aschel, T. Preference-based alignment of discrete diffusion mod- els.arXiv preprint arXiv:2503.08295,
-
[3]
Cao, H., Feng, Y ., Gong, B., Tian, Y ., Lu, Y ., Liu, C., and Wang, B. Dimension-reduction attack! video generative models are experts on controllable image synthesis.arXiv preprint arXiv:2505.23325, 2025a. Cao, H., Lu, Y ., Wang, Q., Li, T., Xu, X., and Zhang, M. Adversarial self flow matching: Few-steps image generation with straight flows, 2025b. URL ...
- [4]
-
[5]
Croitoru, F.-A., Hondru, V ., Ionescu, R. T., Sebe, N., and Shah, M. Curriculum direct preference optimization for diffusion and consistency models.arXiv preprint arXiv:2405.13637,
-
[6]
Personalized preference fine-tuning of diffusion models
13 Submission and Formatting Instructions for ICML 2026 Dang, M., Singh, A., Zhou, L., Ermon, S., and Song, J. Personalized preference fine-tuning of diffusion models. arXiv preprint arXiv:2501.06655,
-
[7]
Dong, H., Xiong, W., Goyal, D., Zhang, Y ., Chow, W., Pan, R., Diao, S., Zhang, J., Shum, K., and Zhang, T. Raft: Re- ward ranked finetuning for generative foundation model alignment.arXiv preprint arXiv:2304.06767,
-
[8]
Dunlop, C., Zheng, M., Venkatesh, K., and Yanardag, P. Per- sonalized image editing in text-to-image diffusion models via collaborative direct preference optimization.arXiv preprint arXiv:2511.05616,
-
[9]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Muller, J., Saini, H., Levi, Y ., Lorenz, D., Sauer, A., Boesel, F., Podell, D., Dockhorn, T., English, Z., Lacey, K., Good- win, A., Marek, Y ., and Rombach, R. Scaling rectified flow transformers for high-resolution image synthesis. ArXiv, abs/2403.03206,
work page internal anchor Pith review arXiv
-
[10]
KTO: Model Alignment as Prospect Theoretic Optimization
Ethayarajh, K., Xu, W., Muennighoff, N., Jurafsky, D., and Kiela, D. Kto: Model alignment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306,
work page internal anchor Pith review arXiv
-
[11]
Fu, M., Wang, G.-H., Cao, L., Chen, Q.-G., Xu, Z., Luo, W., and Zhang, K. Chats: Combining human-aligned optimization and test-time sampling for text-to-image generation.arXiv preprint arXiv:2502.12579,
-
[12]
Gadre, S. Y ., Ilharco, G., Fang, A., Hayase, J., Smyrnis, G., Nguyen, T., Marten, R., Wortsman, M., Ghosh, D., Zhang, J., Orgad, E., Entezari, R., Daras, G., Pratt, S., Ramanujan, V ., Bitton, Y ., Marathe, K., Mussmann, S., Vencu, R., Cherti, M., Krishna, R., Koh, P. W., Saukh, O., Ratner, A. J., Song, S., Hajishirzi, H., Farhadi, A., Beaumont, R., Oh, ...
-
[13]
Hong, J., Lee, N., and Thorne, J. Orpo: Monolithic pref- erence optimization without reference model.arXiv preprint arXiv:2403.07691, 2024a. Hong, J., Paul, S., Lee, N., Rasul, K., Thorne, J., and Jeong, J. Margin-aware preference optimization for aligning diffusion models without reference. InFirst Workshop on Scalable Optimization for Efficient and Adap...
-
[14]
Hu, Z., Zhang, F., Chen, L., Kuang, K., Li, J., Gao, K., Xiao, J., Wang, X., and Zhu, W. Towards better alignment: Training diffusion models with reinforcement learning against sparse rewards.arXiv preprint arXiv:2503.11240, 2025a. Hu, Z., Zhang, F., and Kuang, K. D-fusion: Direct prefer- ence optimization for aligning diffusion models with visu- ally con...
-
[15]
Huang, Q., Chan, L., Liu, J., He, W., Jiang, H., Song, M., and Song, J. Patchdpo: Patch-level dpo for finetuning- free personalized image generation.arXiv preprint arXiv:2412.03177,
-
[16]
14 Submission and Formatting Instructions for ICML 2026 is Better-Together, D. Open image prefer- ences v1. https://huggingface.co/ datasets/data-is-better-together/ open-image-preferences-v1,
work page 2026
-
[17]
Diffusion tree sampling: Scalable inference-time alignment of diffusion models, 2025
Jain, V ., Sareen, K., Pedramfar, M., and Ravanbakhsh, S. Diffusion tree sampling: Scalable inference- time alignment of diffusion models.arXiv preprint arXiv:2506.20701,
-
[18]
Elucidating the Design Space of Diffusion-Based Generative Models
Karras, T., Aittala, M., Aila, T., and Laine, S. Elucidating the design space of diffusion-based generative models. ArXiv, abs/2206.00364,
work page internal anchor Pith review arXiv
-
[19]
Karthik, S., Coskun, H., Akata, Z., Tulyakov, S., Ren, J., and Kag, A. Scalable ranked preference optimization for text- to-image generation.arXiv preprint arXiv:2410.18013,
-
[20]
Lee, J.-Y ., Cha, B., Kim, J., and Ye, J. C. Aligning text to image in diffusion models is easier than you think.arXiv preprint arXiv:2503.08250, 2025a. Lee, K., Liu, H., Ryu, M., Watkins, O., Du, Y ., Boutilier, C., Abbeel, P., Ghavamzadeh, M., and Gu, S. S. Aligning text- to-image models using human feedback.arXiv preprint arXiv:2302.12192,
-
[21]
Calibrated multi- preference optimization for aligning diffusion models
Lee, K., Li, X., Wang, Q., He, J., Ke, J., Yang, M.-H., Essa, I., Shin, J., Yang, F., and Li, Y . Calibrated multi- preference optimization for aligning diffusion models. arXiv preprint arXiv:2502.02588, 2025b. Li, J., Cui, Y ., Huang, T., Ma, Y ., Fan, C., Yang, M., and Zhong, Z. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv prep...
-
[22]
Aligning diffusion models by optimizing human utility
Li, S., Kallidromitis, K., Gokul, A., Kato, Y ., and Kozuka, K. Aligning diffusion models by optimizing human utility. arXiv preprint arXiv:2404.04465,
-
[23]
Liang, Y ., He, J., Li, G., Li, P., Klimovskiy, A., Carolan, N., Sun, J., Pont-Tuset, J., Young, S., Yang, F., et al. Rich human feedback for text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 19401–19411, 2024a. Liang, Z., Yuan, Y ., Gu, S., Chen, B., Hang, T., Li, J., and Zheng, L. Step-aw...
-
[24]
Towards un- derstanding camera motions in any video.arXiv preprint arXiv:2504.15376,
Lin, Z., Cen, S., Jiang, D., Karhade, J., Wang, H., Mitra, C., Ling, T., Huang, Y ., Liu, S., Chen, M., et al. Towards un- derstanding camera motions in any video.arXiv preprint arXiv:2504.15376,
-
[25]
Lin, Z., Mitra, C., Cen, S., Li, I., Huang, Y ., Ling, Y . T. T., Wang, H., Pi, I., Zhu, S., Rao, R., et al. Building a precise video language with human-ai oversight.arXiv preprint arXiv:2604.21718,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Flow Matching for Generative Modeling
Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Flow-GRPO: Training Flow Matching Models via Online RL
Liu, J., Liu, G., Liang, J., Li, Y ., Liu, J., Wang, X., Wan, P., Zhang, D., and Ouyang, W. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025a. Liu, J., Liu, G., Liang, J., Yuan, Z., Liu, X., Zheng, M., Wu, X., Wang, Q., Qin, W., Xia, M., et al. Improving video generation with human feedback.arXiv preprint arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Lu, R., Shao, Z., Ding, Y ., Chen, R., Wu, D., Su, H., Yang, T., Zhang, F., Wang, J., Shi, Y ., et al. Discovery of the reward function for embodied reinforcement learning agents.Nature Communications, 16(1):11064, 2025a. Lu, Y ., Wang, Q., Cao, H., Wang, X., Xu, X., and Zhang, M. Inpo: Inversion preference optimization with reparametrized ddim for effici...
-
[29]
Step-video-t2v tech- nical report: The practice, challenges, and future of video foundation model
Ma, G., Huang, H., Yan, K., Chen, L., Duan, N., Yin, S., Wan, C., Ming, R., Song, X., Chen, X., et al. Step- video-t2v technical report: The practice, challenges, and future of video foundation model.arXiv preprint arXiv:2502.10248,
-
[30]
Miao, Z., Yang, Z., Lin, K., Wang, Z., Liu, Z., Wang, L., and Qiu, Q. Tuning timestep-distilled diffusion model using pairwise sample optimization.arXiv preprint arXiv:2410.03190,
-
[31]
Na, B., Park, M., Sim, G., Shin, D., Bae, H., Kang, M., Kwon, S. J., Kang, W., and Moon, I.-C. Diffusion adap- tive text embedding for text-to-image diffusion models. arXiv preprint arXiv:2510.23974,
-
[32]
Na, S., Kim, Y ., and Lee, H. Boost your human image gen- eration model via direct preference optimization.arXiv preprint arXiv:2405.20216,
-
[33]
Peebles, W. S. and Xie, S. Scalable diffusion models with transformers.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 4172–4182,
work page 2023
-
[34]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Muller, J., Penna, J., and Rombach, R. Sdxl: Im- proving latent diffusion models for high-resolution image synthesis.ArXiv, abs/2307.01952,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Ren, J., Zhang, Y ., Liu, D., Zhang, X., and Tian, Q. Re- fining alignment framework for diffusion models with intermediate-step preference ranking.arXiv preprint arXiv:2502.01667,
-
[36]
S., Shu, Z., Zhang, J., Jung, H., Gerig, G., and Zhang, H
Ren, M., Xiong, W., Yoon, J. S., Shu, Z., Zhang, J., Jung, H., Gerig, G., and Zhang, H. Relightful harmonization: Lighting-aware portrait background replacement.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6452–6462,
work page 2024
-
[37]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with la- tent diffusion models.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10674–10685,
work page 2022
-
[38]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Shi, D., Wang, Y ., Li, H., and Chu, X. Prioritize denois- ing steps on diffusion model preference alignment via explicit denoised distribution estimation.arXiv preprint arXiv:2411.14871,
-
[40]
Denoising Diffusion Implicit Models
Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[41]
16 Submission and Formatting Instructions for ICML 2026 Tee, J. T. J., Yoon, H. S., Syarubany, A. H. M., Yoon, E., and Yoo, C. D. A gradient guidance perspective on stepwise preference optimization for diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. Wallace, B., Dang, M., Rafailov, R., Zhou, L., Lou, A., Pu...
work page 2026
-
[42]
Wang, F.-Y ., Shui, Y ., Piao, J., Sun, K., and Li, H. Diffusion- npo: Negative preference optimization for better pref- erence aligned generation of diffusion models.arXiv preprint arXiv:2505.11245, 2025a. Wang, F.-Y ., Sun, K., Teng, Y ., Liu, X., Song, J., and Li, H. Self-npo: Negative preference optimization of diffusion models by simply learning from...
-
[43]
URL https:// arxiv.org/abs/2605.03877. Wang, Z. J., Montoya, E., Munechika, D., Yang, H., Hoover, B., and Chau, D. H. Diffusiondb: A large-scale prompt gallery dataset for text-to-image generative models.arXiv preprint arXiv:2210.14896,
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Human preference score: Better aligning text-to-image models with human preference
Wu, X., Sun, K., Zhu, F., Zhao, R., and Li, H. Human preference score: Better aligning text-to-image models with human preference. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2096– 2105,
work page 2096
-
[45]
DanceGRPO: Unleashing GRPO on Visual Generation
Xue, Z., Wu, J., Gao, Y ., Kong, F., Zhu, L., Chen, M., Liu, Z., Liu, W., Guo, Q., Huang, W., et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818,
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Using human feedback to fine-tune diffusion models without any reward model
Yang, K., Tao, J., Lyu, J., Ge, C., Chen, J., Shen, W., Zhu, X., and Li, X. Using human feedback to fine-tune diffusion models without any reward model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8941–8951, 2024a. Yang, S., Chen, T., and Zhou, M. A dense reward view on aligning text-to-image diffusion with pre...
-
[47]
Rrhf: Rank responses to align language models with human feedback without tears
Yuan, Z., Yuan, H., Tan, C., Wang, W., Huang, S., and Huang, F. Rrhf: Rank responses to align language mod- els with human feedback without tears.arXiv preprint arXiv:2304.05302,
-
[48]
Learning multi-dimensional human prefer- ence for text-to-image generation
Zhang, S., Wang, B., Wu, J., Li, Y ., Gao, T., Zhang, D., and Wang, Z. Learning multi-dimensional human prefer- ence for text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8018–8027, 2024a. Zhang, T., Da, C., Ding, K., Yang, H., Jin, K., Li, Y ., Gao, T., Zhang, D., Xiang, S., and Pan, C. Dif...
-
[49]
Large-scale reinforcement learning for diffusion models
Zhang, Y ., Tzeng, E., Du, Y ., and Kislyuk, D. Large-scale reinforcement learning for diffusion models. InEuro- pean Conference on Computer Vision, pp. 1–17. Springer, 2024b. Zheng, K., Chen, Y ., Chen, H., He, G., Liu, M.-Y ., Zhu, J., and Zhang, Q. Direct discriminative optimization: Your likelihood-based visual generative model is secretly a gan discr...
-
[50]
17 Submission and Formatting Instructions for ICML 2026 A. Background A.1. More Related Works Conditional Generative Models.Diffusion models belong to a family of generative approaches that create data through an iterative denoising process. These models learn to reverse a predefined forward process that gradually adds noise to data. By capitalizing on ne...
work page 2026
-
[51]
as its core algorithm, which necessitates simultaneous operation of multiple model components - including the active policy, reference model, value function estimator, and reward predictor. However, PPO’s computational intensity and complex optimization landscape frequently pose implementation challenges. To mitigate these issues, researchers have develop...
work page 2023
-
[52]
enhances LLM training through comparative reward information. These advancements collectively represent significant progress in developing more efficient and theoretically grounded alignment techniques. Further Preference Optimization of Diffusion Models.The application of preference alignment techniques extends well beyond text-to-image diffusion models ...
work page 2024
-
[53]
remains a nascent research area. Promising future directions (Cao et al., 2025a;b; Lin et al., 2026; 2025; Lu et al., 2025a; Wang et al.,
work page 2026
-
[54]
18 Submission and Formatting Instructions for ICML 2026 B
may involve transferring alignment methodologies from large language models to generative visual systems (Borso et al., 2025; Lee et al., 2025a; Zheng et al., 2025; Lu et al., 2025d), as well as expanding these techniques to novel sensory modalities including auditory and haptic domains (Huang et al., 2024; Shi et al., 2024). 18 Submission and Formatting ...
work page 2025
-
[55]
19 Submission and Formatting Instructions for ICML 2026 C. Details of the Primary Derivation In this section, we present a detailed derivation of our proposed method. Following Diffusion-DPO, we define the reward on the whole chain: r(x0,c) =E pθ(x1:T |x0,c)[r(x0:T ,c)].(25) We begin with the objective function of RLHF: max pθ Ex0∼pθ(x0|c)[r(x0,c)]/β−D KL...
work page 2026
-
[56]
Exw 1:T−1 ∼pc θ (xw 1:T−1 |xw 0 ,xw T ) xl 1:T−1 ∼pc θ (xl 1:T−1 |xl 0,xl T ) log pc θ(xw 0:T ) pc ref (xw 0:T ) −log pc θ(xl 0:T ) pc ref (xl 0:T ) .(31) Given x∗ T , pc θ(x∗ 1:T−1 |x∗ 0,x ∗ T ) becomes tractable if we estimate it using pc θ(x∗ 1:T−1 |x∗ T ), though this approach is evidently resource-intensive. Leveraging the inherent straightness o...
work page 2026
-
[57]
Exw t−1,t∼q(xw t−1,t|xw 0 ,xw T ) xl t−1,t∼q(xl t−1,t|xl 0,xl T ) log pc θ(xw t−1|xw t ) pc ref (xw t−1|xw t ) −log pc θ(xl t−1|xl t) pc ref (xl t−1|xl t) =−E D logσ βTE tExw T ∼pθ (xw T |xw 0 ),xl T ∼pθ (xl T |xl 0)Exw t ∼q(xw t |xw 0 ,xw T ),xl t∼q(xl t|xl 0,xl T ) Exw t ∼q(xw t−1|xw 0 ,xw t ,xw T ),xl t−1∼q(xl t−1|xl 0,xl t,xl T ) log pc θ(xw t−1|x...
work page 2026
-
[58]
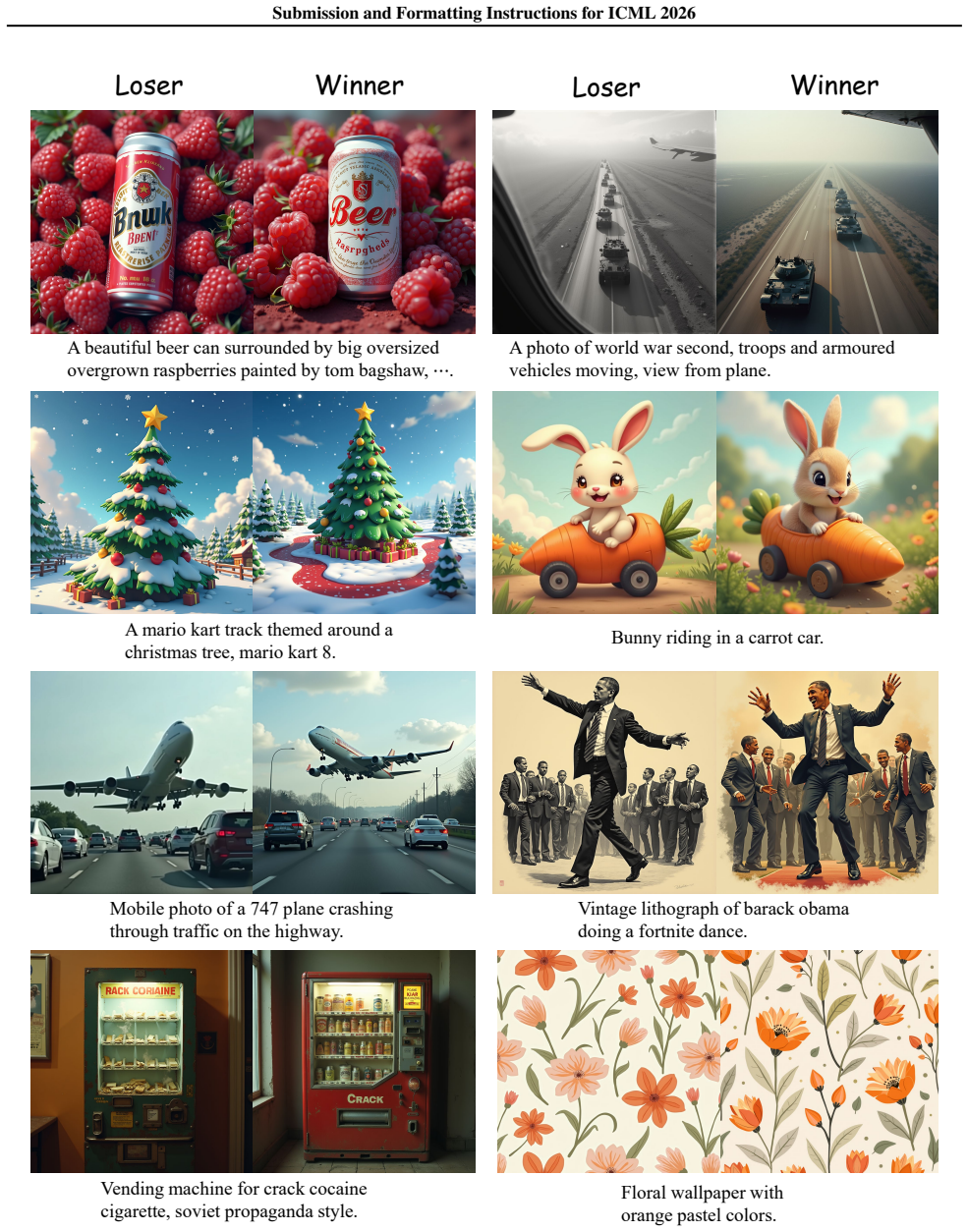
E.2. Off-Policy Data Construction We present a subset of samples generated by FLUX as Figure 6 and Figure 7, with comparative assessments conducted using HPSv2.1 (Human Preference Score v2.1) as the evaluation metric. These visualizations demonstrate both the quality improvements achieved through rectification and the effectiveness of HPSv2.1 in discrimin...
work page 2026
-
[59]
Mobile photo of a 747 plane crashing through traffic on the highway. Vintage lithograph of barack obama doing a fortnite dance. Vending machine for crack cocaine cigarette, soviet propaganda style. Floral wallpaper with orange pastel colors. Figure 6.Preference Dataset samples generated by FLUX. Both the quality improvements achieved through rectification...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.