Contrastive Training with LLM-generated Near-Misses for Robust Code-Switching Speech Recognition
Pith reviewed 2026-06-27 22:19 UTC · model grok-4.3
The pith
A contrastive training method using LLM-generated near-misses at code-switch points cuts ASR error rates by over 2%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
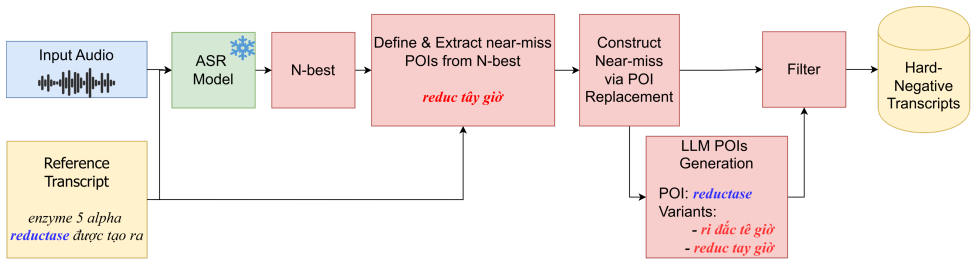
Identifying points of interest for code switches, perturbing them in N-best ASR outputs with an LLM to form near-miss hypotheses, filtering those hypotheses with acoustic, phonemic and textual rules, and then fine-tuning Whisper-small via LoRA with a POI-weighted cross-entropy loss plus a multi-negative contrastive ranking loss produces consistent reductions of more than 2 percent in both general and code-switch-aware error rates on the CS-FLEURS Chinese-English and ViMedCSS Vietnamese-English test sets relative to ordinary LoRA fine-tuning.
What carries the argument
The POI-aware contrastive training framework that detects code-switch points of interest, generates hard negative hypotheses by LLM perturbation of N-best lists, applies acoustic-phonemic-textual filtering, and combines POI-weighted cross-entropy with multi-negative contrastive ranking loss.
If this is right
- Both overall word error rate and code-switch-specific error rate drop by more than 2 percent on the evaluated Chinese-English and Vietnamese-English datasets.
- The gains hold when the method is applied on top of parameter-efficient LoRA adaptation of Whisper-small.
- Training effort is concentrated on the regions where language switches occur rather than spread uniformly across all tokens.
- The generated negatives remain plausible enough to pass acoustic and phonemic checks while still being difficult for the model.
Where Pith is reading between the lines
- The same region-focused negative sampling might help ASR on other sparse events such as proper names or technical terms.
- The pipeline of LLM perturbation plus multi-constraint filtering could be reused to create synthetic hard examples for low-resource language pairs.
- Testing whether the contrastive term still helps when the base model is already much larger than Whisper-small would clarify the method's scaling behavior.
Load-bearing premise
The assumption that POI detection together with LLM perturbation of N-best outputs and subsequent filtering will reliably yield hard but acoustically plausible negative hypotheses that improve learning specifically at code-switch regions.
What would settle it
An ablation that replaces the LLM-generated and filtered near-misses with either random negatives or no contrastive term and measures whether the error-rate gains disappear on the same test sets.
Figures
read the original abstract
Code-switching (CS), the alternation between multiple languages within a single utterance, remains challenging for Automatic Speech Recognition (ASR). To address this issue, we propose a Point-of-Interest (POI)-aware contrastive training framework that improves recognition at CS-critical regions. We first identify CS spans by adopting POI detection method from literature, then construct acoustically plausible near-miss hypotheses by perturbing POIs in ASR N-best outputs and expanding candidates with a large language model. Hard but plausible negatives are retained through filtering with acoustic, phonemic, and textual constraints. Finally, we fine-tune Whisper-small with LoRA using a POI-weighted cross-entropy anchor objective together with a multi-negative contrastive ranking loss. Experiments on CS-FLEURS (cmn-eng) and ViMedCSS (vie-eng) show consistent reductions of over 2% in both general and CS-aware error rates compared to standard LoRA fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Point-of-Interest (POI)-aware contrastive training framework for code-switching speech recognition. It identifies CS spans using POI detection, generates acoustically plausible near-miss hypotheses by perturbing POIs in ASR N-best outputs and using an LLM, filters them with acoustic, phonemic, and textual constraints, and fine-tunes Whisper-small with LoRA using POI-weighted cross-entropy and multi-negative contrastive ranking loss. Experiments on CS-FLEURS (cmn-eng) and ViMedCSS (vie-eng) report consistent reductions of over 2% in general and CS-aware error rates compared to standard LoRA fine-tuning.
Significance. If the results hold, this work is significant for advancing robust ASR in code-switching scenarios by focusing training on critical regions with hard negative examples generated via LLM. The approach is practical, building on existing models and prior POI detection methods, and the empirical gains on two datasets suggest it could be useful for improving performance in multilingual speech applications. The falsifiable nature of the claim and direct comparisons to baseline make it a valuable engineering contribution.
minor comments (2)
- The abstract claims 'consistent reductions of over 2%' but does not specify if these are absolute or relative WER reductions, nor does it mention statistical significance or variance across runs; this should be addressed explicitly in the results section for reproducibility.
- The method description references specific filtering steps (acoustic, phonemic, textual) and POI detection from prior literature but provides no concrete thresholds, number of negatives per example, or ablation results on each component; adding these would strengthen the experimental claims without altering the core contribution.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; empirical method with external benchmarks
full rationale
The paper presents an engineering contribution: POI detection from prior literature, LLM perturbation of N-best lists, acoustic/phonemic/textual filtering to create near-miss negatives, and POI-weighted CE plus multi-negative contrastive loss for LoRA fine-tuning of Whisper. The central claim is an empirical >2% WER reduction on CS-FLEURS (cmn-eng) and ViMedCSS (vie-eng) versus standard LoRA. No equations exist that reduce any result to a fitted parameter by construction, no self-citation chain justifies a uniqueness theorem or ansatz, and the method is directly falsifiable via reported dataset comparisons. The derivation chain is self-contained against external data and baselines.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing POI detection method accurately locates code-switch spans in ASR output
- domain assumption LLM-generated perturbations of POI regions produce candidates that remain acoustically plausible after filtering
Reference graph
Works this paper leans on
-
[1]
near-misses
Introduction In Automatic Speech Recognition (ASR),code-switching(CS), the alternation between two or more languages within a single utterance or discourse, presents a unique challenge [1]. The presence of CS terms introduces language confusion and pho- netic ambiguity, which can degrade the accuracy of the ASR de- coder [1]. Empirically, the most severe ...
-
[2]
Contrastive Training with LLM-generated Near-Misses for Robust Code-Switching Speech Recognition
Related Work Code-switching ASR.CS-ASR remains challenging as errors concentrate on embedded-language words/entities and switch- boundary neighborhoods [1, 2]. Many approaches inject lan- guage awareness such as language identification (LID) supervi- sion to reduce confusion at switch points [8, 9, 10, 11]. For CS- arXiv:2606.06985v2 [cs.CL] 22 Jun 2026 F...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
1) that constructs hard-negative transcripts by perturbing only points-of-interest (POIs) while preserving plausibility under the input audio
Near-Miss Data Generation We propose CS-NMG, an acoustic-aware code-switching near- miss generation pipeline (Fig. 1) that constructs hard-negative transcripts by perturbing only points-of-interest (POIs) while preserving plausibility under the input audio. CS-NMG is exe- cuted onceofflineusing a fixed seed ASR checkpoint (param- eters frozen for decoding...
-
[4]
Alignment Training Strategy We fine-tune the ASR model using a maximum-likelihood (CE/WCE) anchor on the reference transcript and a contrastive ranking loss that prefers reference transcripts over acousti- cally plausible POI-local near-misses generated by CS-NMG (Sec. 3). 4.1. Cross-entropy anchor (CE / WCE) Following language-balance training for CS [12...
-
[5]
Experiments 5.1. Setup and Datasets Datasets and Metrics.We evaluate on two code-switching ASR benchmarks: (i) Mandarin–English (cmn-eng) from CS- FLEURS [3] and (ii) Vietnamese–English (vie-eng) from ViMedCSS [4], a domain-specific (medical) benchmark. For CS-FLEURS, we fine-tune on the CS-FLEURS-XTTS train- ing split and evaluate on the human-read CS-FL...
-
[6]
hard-but-plausible
as the backbone and fine-tune using LoRA, following prior Whisper adaptation work [32, 33]. For LoRA, we set the rank tor= 16, scaling factorα= 32, dropout to0.05, and learning rate to 0.001. We decode with beam search and setN= 10 to construct theN-best list for near-miss generation. Based on development experiments, we fix the number of sampled near- mi...
-
[7]
Conclusion & Future work We introduced a POI-aware contrastive training framework for code-switching ASR that targets errors concentrated on embedded-language spans and switch-boundary neighbor- hoods. Our CS-NMG pipeline generates POI-local near-misses by seeding candidates from the ASRN-best list, expanding POI replacements with a LLM, and selecting har...
-
[8]
Acknowledgments This work was conducted as part of the Cross-College project Robust Vietnamese–English Clinical and Educational Medi- cal Translation(Project ID: VUNI.2324.CC06), a collaborative initiative between the College of Engineering & Computer Sci- ence and the College of Health Sciences at VinUniversity. Tung X. Nguyen, Hieu Minh Truong, Giang So...
-
[9]
These tools were not used to generate any scientific content, experimental results, data anal- yses, or conclusions
Generative AI Use Disclosure The authors used generative AI tools only for minor language editing and to improve readability. These tools were not used to generate any scientific content, experimental results, data anal- yses, or conclusions
-
[10]
Code-Switching in End-to-End Automatic Speech Recog- nition: A Systematic Literature Review,
M. T. Agro, A. A. Kulkarni, K. Kadaoui, Z. Talat, and H. Aldar- maki, “Code-Switching in End-to-End Automatic Speech Recog- nition: A Systematic Literature Review,” inProceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026), S. Piperidis, N. Bel, H. van den Heuvel, N. Ide, S. Krek, and A. Toral, Eds. Palma, Mallorca, Spain: Eu...
2026
-
[11]
Code-Switching Speech Recognition Under the Lens: Model- and Data-Centric Perspectives,
H. Liu, H. Zhang, Q. Zhang, X. Zhang, D. Shi, E. S. Chng, and H. Li, “Code-Switching Speech Recognition Under the Lens: Model- and Data-Centric Perspectives,”IEEE Transactions on Audio, Speech and Language Processing, vol. 34, pp. 1853–1865, 2026
2026
-
[12]
CS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset,
B. Y an, I. Hamed, S. Shimizu, V . S. Lodagala, W . Chen, O. Iakovenko, B. Talafha, A. Hussein, A. Polok, K. Chang, D. Kle- ment, S. Althubaiti, P . Peng, M. Wiesner, T. Solorio, A. Ali, S. Khudanpur, and S. Watanabe, “CS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset,” inInterspeech 2025, 2025, pp. 743–747
2025
-
[13]
ViMed- CSS: A Vietnamese Medical Code-Switching Speech Dataset & Benchmark,
T. X. Nguyen, N. Vo, G. S. Nguyen, D. M. Hoang, C. D. Huynh, I. J. Unanue, M. Piccardi, W . Buntine, and D. D. Le, “ViMed- CSS: A Vietnamese Medical Code-Switching Speech Dataset & Benchmark,” inProceedings of the Fifteenth Language Re- sources and Evaluation Conference (LREC 2026), S. Piperidis, N. Bel, H. van den Heuvel, N. Ide, S. Krek, and A. Toral, E...
2026
-
[14]
PIER: A Novel Metric for Evaluating What Matters in Code-Switching,
E. Y . Ugan, N.-Q. Pham, L. B ¨armann, and A. Waibel, “PIER: A Novel Metric for Evaluating What Matters in Code-Switching,” in ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[15]
Direct Preference Optimization: Y our Language Model is Secretly a Reward Model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct Preference Optimization: Y our Language Model is Secretly a Reward Model,” inThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[16]
Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Trans- lation,
H. Xu, A. Sharaf, Y . Chen, W . Tan, L. Shen, B. Van Durme, K. Murray, and Y . J. Kim, “Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Trans- lation,” inProceedings of the 41st International Conference on Machine Learning, ser. ICML ’24. JMLR.org, 2024
2024
-
[17]
On the End- to-End Solution to Mandarin-English Code-Switching Speech Recognition,
Z. Zeng, H. Xu, P . Guo, L. Xie, and E. S. Chng, “On the End- to-End Solution to Mandarin-English Code-Switching Speech Recognition,” inProc. Interspeech, 2019
2019
-
[18]
Joint ASR and Language Identification Using RNN-T: An Efficient Approach to Dynamic Language Switch- ing,
S. Punjabi, H. Arsikere, Z. Raeesy, C. Chandak, N. Bhave, A. Bansal, M. Muller, S. Murillo, A. Rastrow, A. Stolcke, J. Droppo, S. Garimella, R. Maas, M. Hans, A. Mouchtaris, and S. Kunzmann, “Joint ASR and Language Identification Using RNN-T: An Efficient Approach to Dynamic Language Switch- ing,” inICASSP 2021 - 2021 IEEE International Conference on Acou...
2021
-
[19]
Towards Code- Switching ASR for End-to-End CTC Models,
K. Li, J. Li, G. Y e, R. Zhao, and Y . Gong, “Towards Code- Switching ASR for End-to-End CTC Models,” inICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 6076–6080
2019
-
[20]
Text-Derived Language Identity Incorpo- ration for End-to-End Code-Switching Speech Recognition,
Q. Wang and H. Li, “Text-Derived Language Identity Incorpo- ration for End-to-End Code-Switching Speech Recognition,” in Proceedings of the 6th Workshop on Computational Approaches to Linguistic Code-Switching (CALCS), 2023, pp. 33–42
2023
-
[21]
Adapting Lan- guage Balance in Code-Switching Speech,
E. Y . Ugan, N.-Q. Pham, and A. Waibel, “Adapting Lan- guage Balance in Code-Switching Speech,”arXiv preprint arXiv:2510.18724, 2025
-
[22]
Improving Low Resource Code-Switched ASR Using Augmented Code-Switched TTS,
Y . Sharma, B. Abraham, K. Taneja, and P . Jyothi, “Improving Low Resource Code-Switched ASR Using Augmented Code-Switched TTS,” inInterspeech 2020, 2020, pp. 4771–4775
2020
-
[23]
Can we train ASR systems on Code- switch without real code-switch data? Case study for Singapore’s languages,
T. Nguyen and H.-D. Tran, “Can we train ASR systems on Code- switch without real code-switch data? Case study for Singapore’s languages,” inProc. Interspeech, 2025
2025
-
[24]
Cold Fusion: Training Seq2Seq Models Together with Language Models,
A. Sriram, H. Jun, S. Satheesh, and A. Coates, “Cold Fusion: Training Seq2Seq Models Together with Language Models,” in Proc. Interspeech, 2018
2018
-
[25]
Resid- ual Language Model for End-to-end Speech Recognition,
E. Tsunoo, Y . Kashiwagi, C. Narisetty, and S. Watanabe, “Resid- ual Language Model for End-to-end Speech Recognition,” in Proc. Interspeech, 2022
2022
-
[26]
Improved Deep Duel Model for Rescoring N-Best Speech Recognition List Using Backward LSTMLM and Ensemble Encoders,
A. Ogawa, M. Delcroix, S. Karita, and T. Nakatani, “Improved Deep Duel Model for Rescoring N-Best Speech Recognition List Using Backward LSTMLM and Ensemble Encoders,” inProc. In- terspeech, 2019
2019
-
[27]
Progres: Prompted Generative Rescoring on ASR N-Best,
A. D. Tur, A. Moumen, and M. Ravanelli, “Progres: Prompted Generative Rescoring on ASR N-Best,” in2024 IEEE Spoken Language Technology Workshop (SLT), 2024, pp. 600–607
2024
-
[28]
CLEAR: Code-mixed ASR with LLM-driven rescoring,
S. Kumar and M. S. Akhtar, “CLEAR: Code-mixed ASR with LLM-driven rescoring,” inProceedings of the 8th Interna- tional Conference on Natural Language and Speech Processing (ICNLSP-2025). Southern Denmark University, Odense, Den- mark: Association for Computational Linguistics, Aug. 2025
2025
-
[29]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P . Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P . Welinder, P . F. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback,” inAdvances in Neu- ral Information Processing Systems,...
2022
-
[30]
Minimum Word Error Rate Training for Attention-Based Sequence-to-Sequence Models,
R. Prabhavalkar, T. N. Sainath, Y . Wu, P . Nguyen, Z. Chen, C.-C. Chiu, and A. Kannan, “Minimum Word Error Rate Training for Attention-Based Sequence-to-Sequence Models,” in2018 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), 2018, pp. 4839–4843
2018
-
[31]
Efficient Minimum Word Error Rate Training of RNN-Transducer for End-to-End Speech Recogni- tion,
J. Guo, G. Tiwari, J. Droppo, M. V . Segbroeck, C.-W . Huang, A. Stolcke, and R. Maas, “Efficient Minimum Word Error Rate Training of RNN-Transducer for End-to-End Speech Recogni- tion,” inInterspeech 2020, 2020, pp. 2807–2811
2020
-
[32]
Binary codes capable of correcting deletions, insertions, and reversals,
V . I. Levenshtein, “Binary codes capable of correcting deletions, insertions, and reversals,”Soviet physics. Doklady, vol. 10, pp. 707–710, 1965. [Online]. Available: https://api.semanticscholar. org/CorpusID:60827152
1965
-
[33]
Joint-sequence models for grapheme-to- phoneme conversion,
M. Bisani and H. Ney, “Joint-sequence models for grapheme-to- phoneme conversion,”Speech Communication, vol. 50, no. 5, pp. 434–451, 2008. [Online]. Available: https://www.sciencedirect. com/science/article/pii/S0167639308000046
2008
-
[34]
Representation Learning with Contrastive Predictive Coding
A. van den Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018. [Online]. Available: https://arxiv.org/ abs/1807.03748
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
Noise-contrastive estimation: A new estimation principle for unnormalized statistical models,
M. Gutmann and A. Hyv ¨arinen, “Noise-contrastive estimation: A new estimation principle for unnormalized statistical models,” in Proceedings of the Thirteenth International Conference on Arti- ficial Intelligence and Statistics (AISTATS), ser. Proceedings of Machine Learning Research, vol. 9, 2010, pp. 297–304. [Online]. Available: https://proceedings.ml...
2010
-
[36]
Gemini Team, Google, “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,” 2025. [Online]. Available: https://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
mozillazg/python-pinyin: v0.55.0,
H. Huanget al., “mozillazg/python-pinyin: v0.55.0,” 2025. [Online]. Available: https://zenodo.org/records/3520670/latest
-
[38]
g2pe: English grapheme-to-phoneme con- version,
K. Park and J. Kim, “g2pe: English grapheme-to-phoneme con- version,” https://github.com/Kyubyong/g2p, 2019
2019
-
[39]
underthesea: Vietnamese nlp toolkit,
undertheseanlp contributors, “underthesea: Vietnamese nlp toolkit,” https://github.com/undertheseanlp/underthesea, 2017
2017
-
[40]
Robust Speech Recognition via Large-Scale Weak Supervision,
A. Radford, J. W . Kim, T. Xu, G. Brockman, C. Mcleavey, and I. Sutskever, “Robust Speech Recognition via Large-Scale Weak Supervision,” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, Eds., vol. 202. PMLR, 23–...
2023
-
[41]
LoRA- Whisper: Parameter-Efficient and Extensible Multilingual ASR,
Z. Song, J. Zhuo, Y . Y ang, Z. Ma, S. Zhang, and X. Chen, “LoRA- Whisper: Parameter-Efficient and Extensible Multilingual ASR,” inInterspeech 2024, 2024, pp. 3934–3938
2024
-
[42]
Towards Rehearsal-Free Multilingual ASR: A LoRA-based Case Study on Whisper ,
T. Xu, K. Huang, P . Guo, Y . Zhou, L. Huang, H. Xue, and L. Xie, “Towards Rehearsal-Free Multilingual ASR: A LoRA-based Case Study on Whisper ,” inInterspeech 2024, 2024, pp. 2534–2538
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.