Mitigating Proxy-to-Wild Domain Gap in Deepfake Speech
Pith reviewed 2026-06-27 20:41 UTC · model grok-4.3
The pith
Transforming deterministic feature statistics into stochastic distributions narrows the proxy-to-wild domain gap in deepfake speech detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Domain-Shift Feature Augmentation narrows the proxy-to-wild domain gap by transforming deterministic feature statistics into stochastic distributions during fine-tuning, and when paired with a post-trained SSL backbone it achieves state-of-the-art performance across diverse CodecFake attacks in both CoSG Eval and CoSG ExtEval.
What carries the argument
Domain-Shift Feature Augmentation (DSFA), a fine-tuning technique that simulates in-the-wild variations by converting deterministic feature statistics to stochastic distributions.
If this is right
- Detectors generalize better to unseen generative models and long-form audio in extended evaluations.
- The combination with post-trained SSL backbones produces state-of-the-art results on both standard and harder test sets.
- The method improves robustness across a wider range of neural audio codec attacks.
Where Pith is reading between the lines
- The same stochastic augmentation idea could be tested on domain gaps in other audio tasks such as speaker verification or music deepfake detection.
- Future experiments might vary the type and amount of stochasticity to find the minimal change that still closes the gap.
Load-bearing premise
That converting deterministic feature statistics into stochastic distributions during fine-tuning accurately represents real-world variations without introducing new artifacts that degrade detection.
What would settle it
A controlled test showing that models using DSFA achieve no improvement or lower accuracy than standard fine-tuning on the CoSG ExtEval set with its 40 unseen models would falsify the claim.
Figures

read the original abstract
Recent neural audio codec-based speech generation (CodecFake) produces highly realistic audio, posing a challenge to existing deepfake countermeasure models. While using codec resynthesized speech (CoRS) as proxy data improves performance, it often suffers from limited generalization. We propose Domain-Shift Feature Augmentation (DSFA), which simulates "in-the-wild" variations by transforming deterministic feature statistics into stochastic distributions during fine-tuning. To evaluate generalization, we further introduce Codec-based Speech Generation Extension Evaluation (CoSG ExtEval) dataset, a more challenging extension of the CoSG Eval (from CodecFake+) dataset, featuring 40 unseen generative models and long-form audio. Experimental results demonstrate that combining a post-trained SSL backbone with DSFA effectively narrows the proxy-to-wild domain gap. This approach achieves state-of-the-art performance across diverse CodecFake attacks in both CoSG Eval and CoSG ExtEval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Domain-Shift Feature Augmentation (DSFA) to narrow the proxy-to-wild domain gap in deepfake speech detection. DSFA transforms deterministic feature statistics from a post-trained SSL backbone into stochastic distributions during fine-tuning to simulate in-the-wild variations. The authors introduce the CoSG ExtEval dataset (an extension of CoSG Eval with 40 unseen generative models and long-form audio) and claim that combining the post-trained SSL backbone with DSFA achieves state-of-the-art performance across diverse CodecFake attacks on both CoSG Eval and CoSG ExtEval.
Significance. If the results are reproducible and the stochastic augmentation is shown to target domain-specific shifts rather than acting as generic regularization, the work would be significant for improving generalization in audio deepfake countermeasures. The new CoSG ExtEval dataset would also serve as a useful community benchmark for evaluating robustness to unseen codec-based attacks and long-form audio.
major comments (2)
- [Abstract] Abstract: the claim of state-of-the-art performance across CoSG Eval and CoSG ExtEval is asserted without any reported baselines, error bars, statistical tests, data-exclusion rules, or quantitative results, making it impossible to verify whether the numbers support the central claim that DSFA narrows the proxy-to-wild gap.
- [Abstract] Abstract (DSFA description): the load-bearing assumption that converting deterministic SSL feature statistics to stochastic distributions during fine-tuning faithfully approximates real domain shifts (e.g., long-form audio artifacts or outputs from the 40 unseen models in CoSG ExtEval) is not accompanied by any distribution-matching analysis or comparison to actual wild data statistics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract below and will make revisions to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of state-of-the-art performance across CoSG Eval and CoSG ExtEval is asserted without any reported baselines, error bars, statistical tests, data-exclusion rules, or quantitative results, making it impossible to verify whether the numbers support the central claim that DSFA narrows the proxy-to-wild gap.
Authors: We agree that the abstract should include concrete quantitative support for the SOTA claim. In the revised version we will add specific performance metrics (EER/AUC on both datasets), explicit baseline comparisons, and references to the error bars and statistical tests already reported in the experimental sections. Data exclusion criteria (if any) will also be summarized. revision: yes
-
Referee: [Abstract] Abstract (DSFA description): the load-bearing assumption that converting deterministic SSL feature statistics to stochastic distributions during fine-tuning faithfully approximates real domain shifts (e.g., long-form audio artifacts or outputs from the 40 unseen models in CoSG ExtEval) is not accompanied by any distribution-matching analysis or comparison to actual wild data statistics.
Authors: The manuscript currently supports the assumption via downstream generalization gains on CoSG ExtEval. We acknowledge that an explicit distribution-matching analysis would strengthen the justification. We will add a short analysis (e.g., feature-statistic comparisons or divergence measures) either in the main text or appendix to directly compare DSFA-augmented statistics against those observed from the unseen models and long-form audio. revision: yes
Circularity Check
No circularity; empirical method and new evaluation dataset are independent
full rationale
The provided abstract and description contain no equations, fitted parameters, or self-citations. DSFA is introduced as a descriptive augmentation technique (transforming deterministic statistics to stochastic distributions) and evaluated on the newly introduced CoSG ExtEval dataset with unseen models. No derivation reduces by construction to its inputs, and the central claim rests on empirical results rather than self-referential definitions or predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Advances in speech generation technologies have greatly im- proved the naturalness and controllability of synthetic speech. While these developments enable a wide range of beneficial applications, they also introduce serious security risks when misused for malicious audio deepfake attacks, such as mis- information dissemination, identity impe...
-
[2]
The Proxy-to-Wild Domain Gap in Deepfake Speech Training CMs on proxy data is a cost-effective alternative to collecting diverse TTS/VC speech [9, 10, 13–15], yet an inher- ent domain gap persists, hindering generalization to “in-the- wild” scenarios. We categorize this gap into three dimensions: (1) Artifact Mismatch:Unseen codecs and generative models i...
Pith/arXiv arXiv 2026
-
[3]
in-the-wild
Proposed Method Our framework (Fig. 1) bridges the proxy-to-wild domain gap by: (1) leveraging a deepfake-tailored post-trained SSL back- bone to establish a versatile representation space, and (2) em- ploying Domain-Shift Feature Augmentation (DSFA) during fine-tuning to simulate unseen domain variations. 3.1. Post-Training Self-Supervised Learning Backb...
-
[4]
CoRS con- tains spoofed samples from 31 neural codecs applied to the VCTK corpus [25]
Experimental Setup We conduct experiments using the CodecFake+ [10] dataset, where CoRS (speech resynthesized by neural audio codecs) is employed for training and CoSG (speech from codec- based generation models) is used for evaluation. CoRS con- tains spoofed samples from 31 neural codecs applied to the VCTK corpus [25]. Following previous work [10], we ...
-
[5]
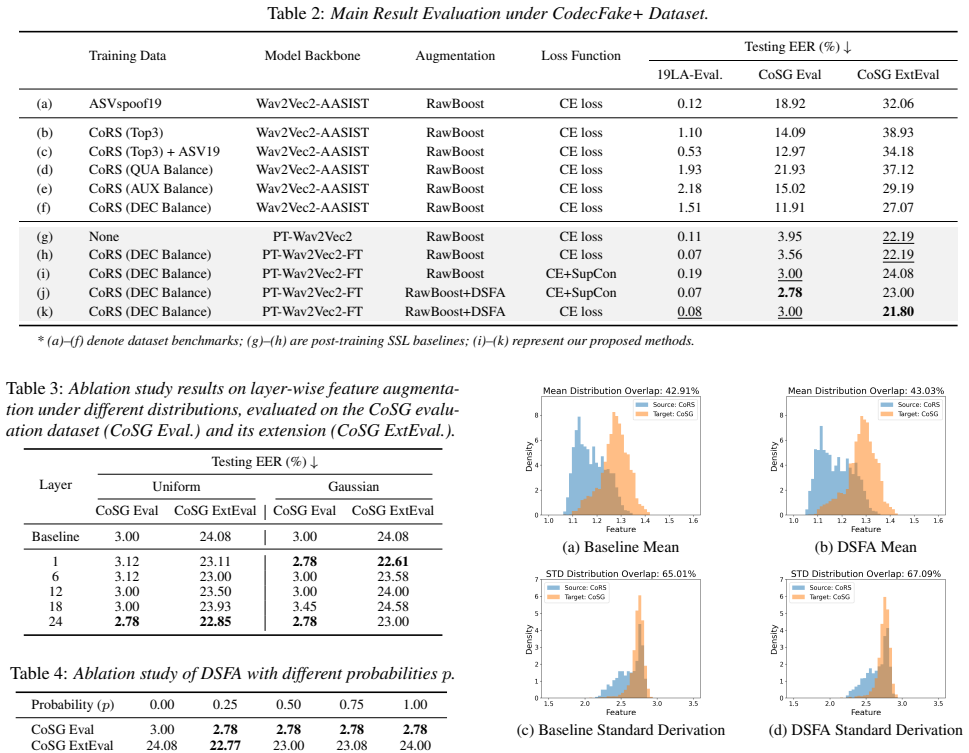
Main Results Table 2 presents the cross-scenario results. Beyond the benchmarks (a)–(f) from CodecFake+ [10] on existing sets (ASVspoof19 LA, CoRS, CoSG Eval), we further evaluate per- formance on our new collected CoSG ExtEval dataset. CoSG ExtEval Baseline Evaluation.Model (a) achieves near-perfect in-domain results but generalizes poorly to CoSG Eval, ...
-
[6]
SSL Layer-wise Analysis.We evaluate DSFA across SSL layers to identify the optimal integration point for robustness and generalizability
Ablation and Quantitative Evaluation To further dissect the mechanisms behind these improvements and optimize feature-level augmentations, we conduct a de- tailed ablation study and quantitative analysis in this section. SSL Layer-wise Analysis.We evaluate DSFA across SSL layers to identify the optimal integration point for robustness and generalizability...
-
[7]
To overcome this, we propose Domain-Shift Feature Augmentation (DSFA), which promotes domain-invariant representations by simulating sta- tistical discrepancies in the latent space
Conclusion This work addresses the proxy-to-wild domain gap in Codec- Fake detection, where models trained on resynthesized data (CoRS) exhibit a distributional bias that impairs their perfor- mance against unseen generative systems. To overcome this, we propose Domain-Shift Feature Augmentation (DSFA), which promotes domain-invariant representations by s...
-
[8]
Acknowledgements This work was supported by the Ministry of Education (MOE) of Taiwan under the project Taiwan Centers of Excellence in Artificial Intelligence, through the NTU Artificial Intelligence Center of Research Excellence (NTU AI-CoRE). We thank the National Center for High-performance Computing (NCHC) of the National Applied Research Laboratorie...
-
[9]
Generative AI Use Disclosure We employed Gemini for grammatical paraphrasing and lan- guage polishing to improve the manuscript’s clarity. The AI tool was utilized solely for technical editing purposes and did not contribute to the conceptualization, data analysis, or pro- duction of any significant scholarly content in this work
-
[10]
ASVspoof 2019: future horizons in spoofed and fake audio detection,
M. Todisco, X. Wang, V . Vestman, M. Sahidullah, H. Delgado, A. Nautsch, J. Yamagishi, N. Evans, T. H. Kinnunen, and K. A. Lee, “ASVspoof 2019: future horizons in spoofed and fake audio detection,” inProc. Interspeech
2019
-
[11]
ASVspoof 2021: Towards spoofed and deepfake speech detection in the wild,
X. Liu, X. Wanget al., “ASVspoof 2021: Towards spoofed and deepfake speech detection in the wild,”IEEE Transactions on Au- dio, Speech and Language Processing, vol. 31, 2023
2021
-
[12]
ASVspoof 5: Crowdsourced speech data, deepfakes, and adversarial attacks at scale,
X. Wang, H. Delgado, H. Tak, J.-w. Jung, H.-j. Shim, M. Todisco et al., “ASVspoof 5: Crowdsourced speech data, deepfakes, and adversarial attacks at scale,” inProc. ASVspoof Workshop, 2024
2024
-
[13]
ADD 2022: the first audio deep synthesis detection challenge,
J. Yi, R. Fuet al., “ADD 2022: the first audio deep synthesis detection challenge,” inProc. ICASSP, 2022
2022
-
[14]
ADD 2023: Towards audio deepfake detection and anal- ysis in the wild,
J. Yi, C. Y . Zhang, J. Tao, C. Wang, X. Yan, Y . Ren, H. Gu, and J. Zhou, “ADD 2023: Towards audio deepfake detection and anal- ysis in the wild,”arXiv preprint arXiv:2408.04967, 2024
arXiv 2023
-
[15]
Codec-SUPERB: An in-depth analysis of sound codec models,
H. Wu, H.-L. Chung, Y .-C. Lin, Y .-K. Wu, X. Chen, Y .-C. Pai et al., “Codec-SUPERB: An in-depth analysis of sound codec models,” inFindings Assoc. Comput. Linguist., 2024
2024
-
[16]
Codec-SUPERB@ SLT 2024: A lightweight benchmark for neu- ral audio codec models,
H. Wu, X. Chen, Y .-C. Lin, K. Chang, J. Du, K.-H. Luet al., “Codec-SUPERB@ SLT 2024: A lightweight benchmark for neu- ral audio codec models,” inProc. IEEE Spoken Lang. Technol. Workshop, 2024
2024
-
[17]
Towards audio language modeling-an overview,
H. Wu, X. Chen, Y .-C. Lin, K.-w. Chang, H.-L. Chung, A. H. Liu, and H.-y. Lee, “Towards audio language modeling-an overview,” arXiv preprint arXiv:2402.13236, 2024
arXiv 2024
-
[18]
CodecFake: Enhancing anti-spoofing models against deepfake audios from codec-based speech synthesis systems,
H. Wu, Y . Tseng, and H. yi Lee, “CodecFake: Enhancing anti-spoofing models against deepfake audios from codec-based speech synthesis systems,” inProc. Interspeech, 2024
2024
-
[19]
CodecFake+: A large- scale neural audio codec-based deepfake speech dataset,
X. Chen, J. Du, H. Wu, L. Zhang, I. Lin, I. Chiu, W. Ren, Y . Tseng, Y . Tsao, J.-S. R. Jang, and H.-y. Lee, “CodecFake+: A large- scale neural audio codec-based deepfake speech dataset,”arXiv preprint arXiv:2501.08238, 2025
Pith/arXiv arXiv 2025
-
[20]
Towards generalized source tracing for codec-based deepfake speech,
X. Chen, I. Lin, L. Zhang, H. Wu, H.-y. Lee, J.-S. R. Janget al., “Towards generalized source tracing for codec-based deepfake speech,”arXiv preprint arXiv:2506.07294, 2025
arXiv 2025
-
[21]
Codec-based deepfake source tracing via neural audio codec taxonomy,
X. Chen, I. Lin, L. Zhang, J. Du, H. Wu, H.-y. Lee, J.-S. R. Janget al., “Codec-based deepfake source tracing via neural audio codec taxonomy,”arXiv preprint arXiv:2505.12994, 2025
arXiv 2025
-
[22]
Can large-scale vocoded spoofed data improve speech spoofing countermeasure with a self-supervised front end?
X. Wang and J. Yamagishi, “Can large-scale vocoded spoofed data improve speech spoofing countermeasure with a self-supervised front end?” inICASSP 2024 - 2024 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 10 311–10 315
2024
-
[23]
Spoofed training data for speech spoofing countermeasure can be efficiently created using neural vocoders,
——, “Spoofed training data for speech spoofing countermeasure can be efficiently created using neural vocoders,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[24]
Improv- ing copy-synthesis anti-spoofing training method with rhythm and speaker perturbation,
J. Lu, Y . Zhang, Z. Li, Z. Shang, W. Wang, and P. Zhang, “Improv- ing copy-synthesis anti-spoofing training method with rhythm and speaker perturbation,” inInterspeech, vol. 2024, 2024, pp. 512– 516
2024
-
[25]
Codec-Based Deepfake Source Tracing via Neural Audio Codec Taxonomy,
X. Chen, I.-M. Lin, L. Zhang, J. Du, H. Wu, H. yi Lee, and J.-S. R. Jang, “Codec-Based Deepfake Source Tracing via Neural Audio Codec Taxonomy,” inInterspeech 2025, 2025, pp. 1538–1542
2025
-
[26]
The impact of silence on speech anti-spoofing,
Y . Zhang, Z. Li, J. Lu, H. Hua, W. Wang, and P. Zhang, “The impact of silence on speech anti-spoofing,”IEEE/ACM Transac- tions on Audio, Speech, and Language Processing, vol. 31, pp. 3374–3389, 2023
2023
-
[27]
Post-training for deepfake speech detection,
W. Ge, X. Wang, X. Liu, and J. Yamagishi, “Post-training for deepfake speech detection,”arXiv preprint arXiv:2506.21090, 2025
arXiv 2025
-
[28]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inProc. NeurIPS, vol. 33, 2020
2020
-
[29]
Automatic speaker verification spoofing and deepfake detection using wav2vec 2.0 and data augmentation,
H. Tak, M. Todisco, X. Wang, J.-w. Jung, J. Yamagishi, and N. Evans, “Automatic speaker verification spoofing and deepfake detection using wav2vec 2.0 and data augmentation,” inProc. Odyssey Speaker Lang. Recognit. Workshop, 2022
2022
-
[30]
Closed-form factorization of latent seman- tics in gans,
Y . Shen and B. Zhou, “Closed-form factorization of latent seman- tics in gans,” inProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, 2021, pp. 1532–1540
2021
-
[31]
Im- plicit semantic data augmentation for deep networks,
Y . Wang, X. Pan, S. Song, H. Zhang, G. Huang, and C. Wu, “Im- plicit semantic data augmentation for deep networks,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[32]
Arbitrary style transfer in real-time with adaptive instance normalization,
X. Huang and S. Belongie, “Arbitrary style transfer in real-time with adaptive instance normalization,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 1501– 1510
2017
-
[33]
Supervised contrastive learning,
P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y . Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, “Supervised contrastive learning,”Advances in neural information processing systems, vol. 33, pp. 18 661–18 673, 2020
2020
-
[34]
Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (ver- sion 0.92),
J. Yamagishi, C. Veaux, K. MacDonaldet al., “Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (ver- sion 0.92),”Univ. of Edinburgh, The Centre for Speech Technol- ogy Research (CSTR), 2019
2019
-
[35]
Raw- boost: A raw data boosting and augmentation method applied to automatic speaker verification anti-spoofing,
H. Tak, M. Kamble, J. Patino, M. Todisco, and N. Evans, “Raw- boost: A raw data boosting and augmentation method applied to automatic speaker verification anti-spoofing,” inProc. ICASSP, 2022
2022
-
[36]
Lens-df: Deepfake detection and temporal localization for long-form noisy speech,
X. Liu, W. Ge, X. Wang, and J. Yamagishi, “Lens-df: Deepfake detection and temporal localization for long-form noisy speech,” Osaka, Japan, 2025
2025
-
[37]
Singfake: Singing voice deepfake detection,
Y . Zang, Y . Zhang, M. Heydari, and Z. Duan, “Singfake: Singing voice deepfake detection,” inICASSP 2024-2024 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 12 156–12 160
2024
-
[38]
Singing voice graph modeling for singfake detection,
X. Chen, H. Wu, J.-S. R. Jang, and H. yi Lee, “Singing voice graph modeling for singfake detection,” inInterspeech 2024, 2024
2024
-
[39]
How does instrumental music help singfake detection?
X. Chen, C.-Y . Hu, I.-M. Lin, Y .-C. Lin, I.-H. Chiu, Y . Zhang, S.- F. Huang, Y .-H. Yang, H. Wu, H. yi Lee, and J.-S. R. Jang, “How does instrumental music help singfake detection?” 2025
2025
-
[40]
SpeechFake: A large-scale multilingual speech deepfake dataset incorporating cutting-edge generation methods,
W. Huang, Y . Gu, Z. Wang, H. Zhu, and Y . Qian, “SpeechFake: A large-scale multilingual speech deepfake dataset incorporating cutting-edge generation methods,” inProceedings of the 63rd An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vienna, Austria: Association for Com- putational Linguistics, Jul. 2025, pp. 9985–9998
2025
-
[41]
Uncertainty modeling for out-of-distribution generalization,
X. Li, Y . Dai, Y . Ge, J. Liu, Y . Shan, and L. DUAN, “Uncertainty modeling for out-of-distribution generalization,” inInternational Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=6HN7LHyzGgC
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.