MemoryVLA++: Temporal Modeling via Memory and Imagination in Vision-Language-Action Models
Pith reviewed 2026-06-27 16:11 UTC · model grok-4.3
The pith
MemoryVLA++ equips VLA models with memory retrieval and future imagination to handle long-horizon robotic tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
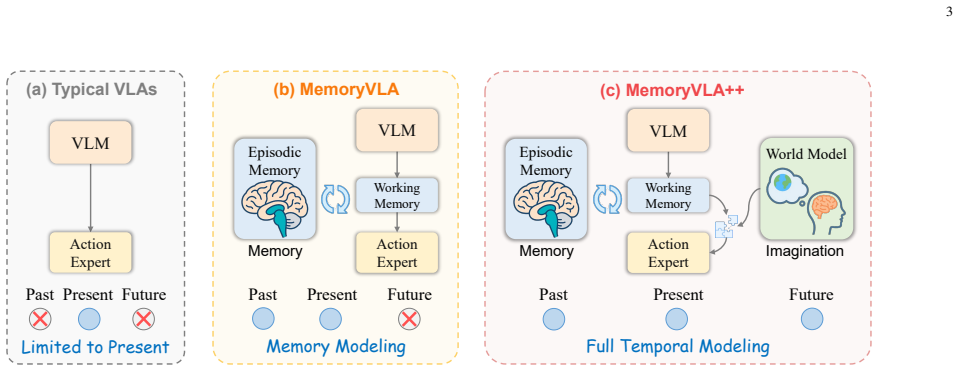
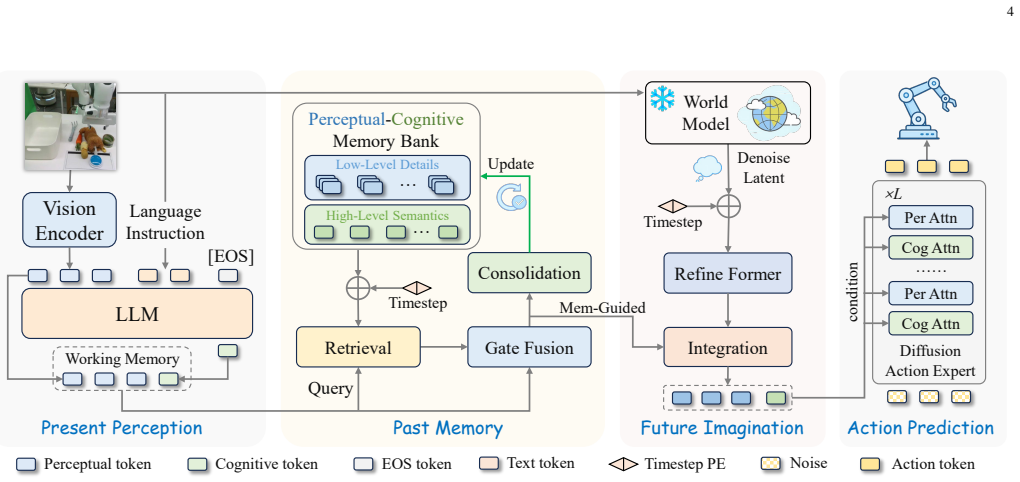
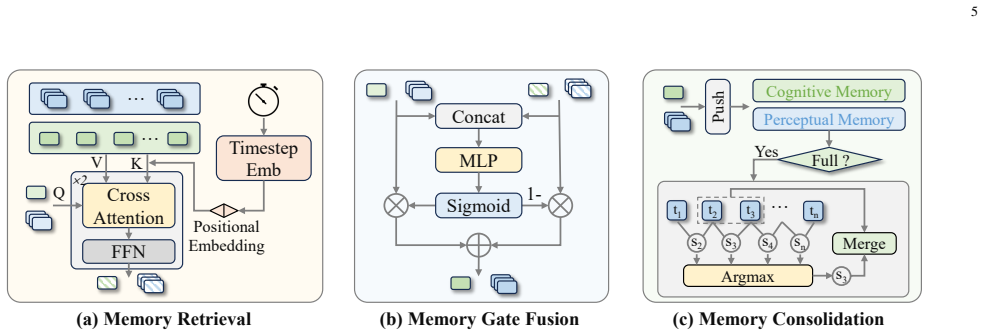
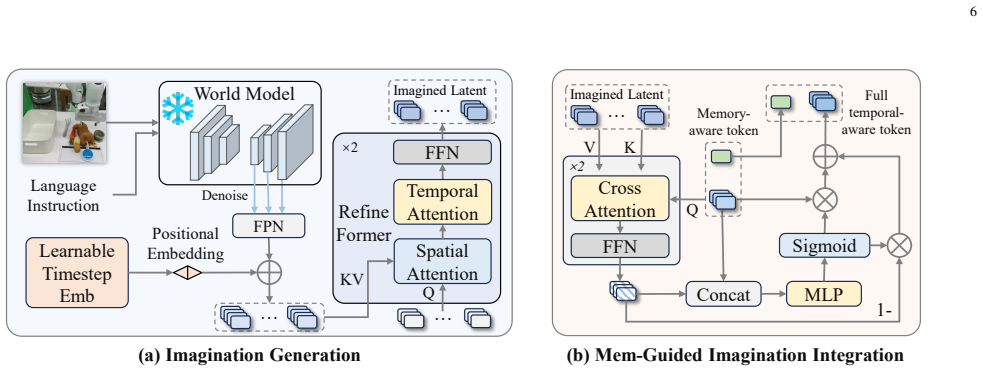
MemoryVLA++ is a full temporal modeling framework for VLA models that encodes the current observation into perceptual and cognitive tokens as working memory, queries a Perceptual-Cognitive Memory Bank to retrieve historical low-level and high-level context, updates the bank through redundancy-aware consolidation, generates imagined future states in a denoising latent space via a world model, integrates those latents under memory guidance to produce temporal-aware tokens, and conditions a diffusion action expert on the resulting tokens to output consistent action sequences.
What carries the argument
The Perceptual-Cognitive Memory Bank together with memory-guided integration of imagined latents from the world model, which together convert static observations into temporally aware tokens for the diffusion action expert.
If this is right
- Performance rises across five simulation benchmarks including Libero, Calvin, and SimplerEnv.
- Gains appear on three categories of real-robot tasks spanning general manipulation, long-horizon temporal dependence, robustness, and generalization.
- The redundancy-aware consolidation step keeps the memory bank from growing without bound while preserving relevant history.
- The conditioned diffusion expert produces action sequences that remain consistent over longer horizons.
Where Pith is reading between the lines
- The same memory-plus-imagination pattern could be tested on non-robotic sequential tasks such as video prediction or autonomous navigation.
- Larger pretrained VLMs might supply higher-quality working-memory tokens and amplify the observed gains.
- The framework supplies a concrete testbed for whether cognitive-science mechanisms translate into measurable control improvements when implemented inside existing VLA architectures.
Load-bearing premise
The particular integration of retrieved memory tokens with imagined latents under memory guidance is what produces the temporal-aware tokens that causally improve the diffusion action expert.
What would settle it
An ablation that removes either the memory-bank retrieval step or the memory-guided imagination step and shows that the reported gains on memory-dependent and imagination-dependent real-robot tasks disappear while other implementation details remain unchanged.
Figures

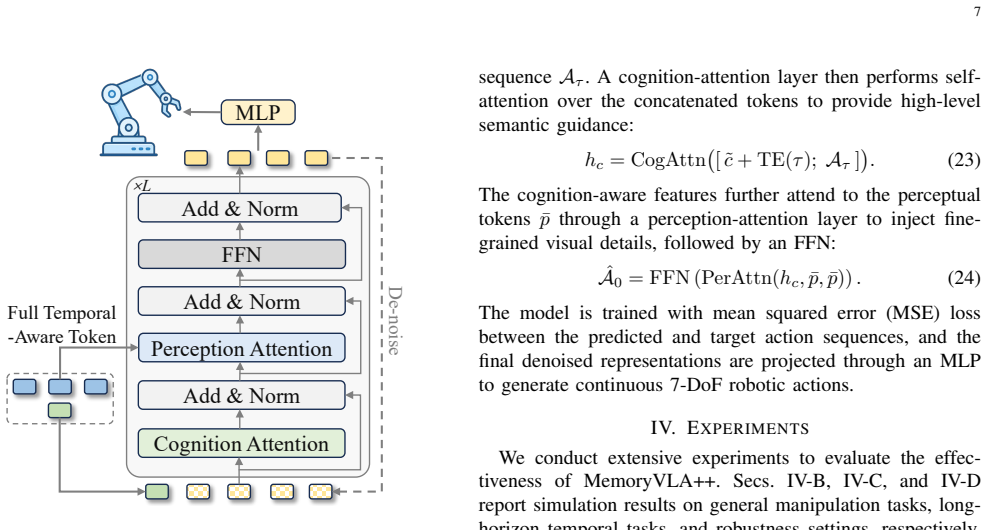
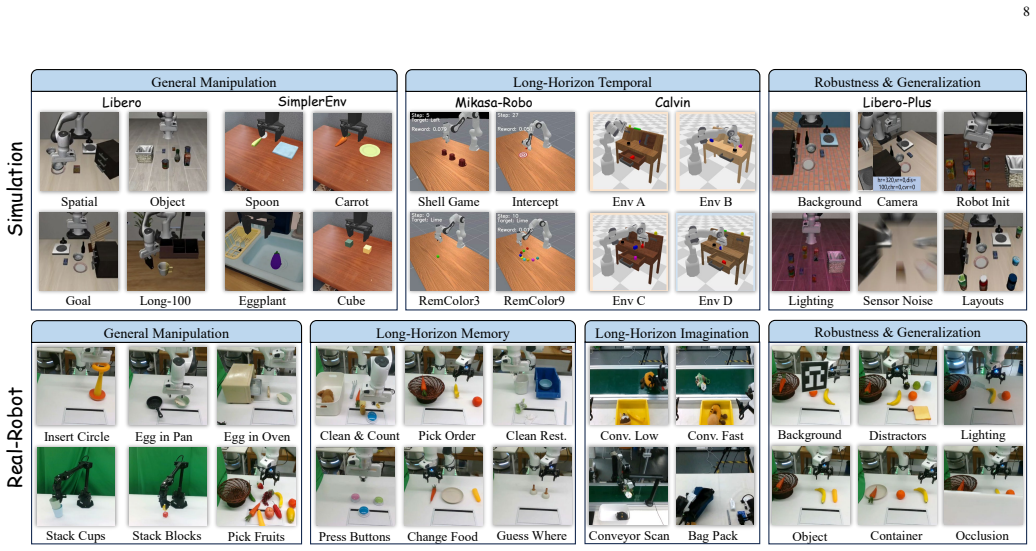

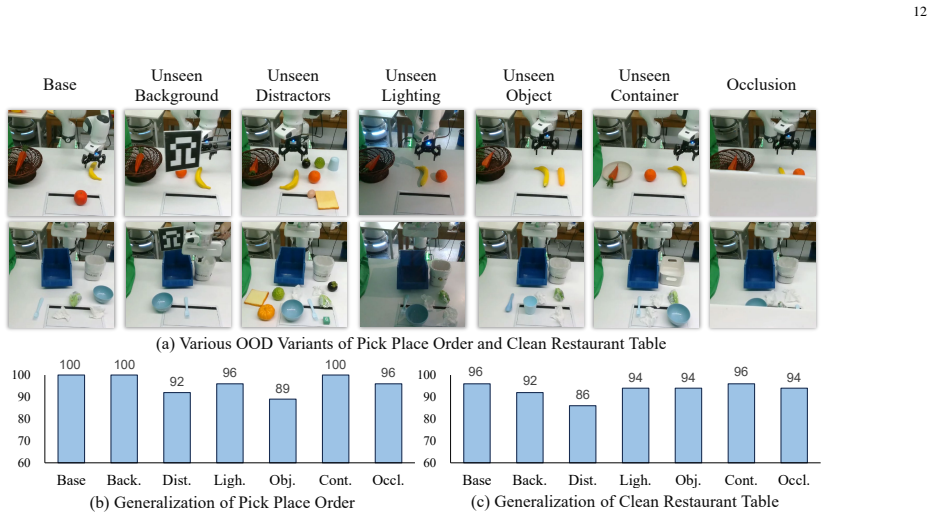

















read the original abstract
Temporal modeling is essential for robotic manipulation, as effective control requires both memory of past interactions and imagination of future states. However, most VLA models rely primarily on the current observation and therefore struggle with long-horizon, temporally dependent tasks. Cognitive science suggests that humans rely on working memory to buffer short-lived context, the hippocampal system to preserve episodic memory of past experience, and internal models to imagine possible future state evolution. Inspired by these mechanisms, we propose MemoryVLA++, a full temporal modeling framework that equips VLA models with memory and imagination for robotic manipulation. A pretrained VLM encodes the current observation into perceptual and cognitive tokens, forming working memory. These tokens query a Perceptual-Cognitive Memory Bank to retrieve relevant historical context. This bank stores low-level details and high-level semantics from past interactions, and is updated through redundancy-aware consolidation. A world model imagines future states in a denoising latent space, and the imagined latents are integrated under memory guidance to form full temporal-aware tokens. The resulting tokens condition a diffusion action expert to predict temporally consistent action sequences. We conduct extensive experiments on 5 simulation benchmarks and 3 categories of real-robot tasks across 3 robots, covering general manipulation, long-horizon temporal tasks, robustness, and generalization. Our method achieves strong performance across Libero, SimplerEnv, Mikasa-Robo, Calvin, Libero-Plus, and diverse real-robot tasks, validating the effectiveness of full temporal modeling with memory and imagination. For example, on real robots, it achieves +9%, +26%, +28% gains on general, memory-dependent, and imagination-dependent tasks. Project Page: https://shihao1895.github.io/MemoryVLA-PP-Web
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MemoryVLA++, a framework that augments VLA models with cognitively inspired temporal modeling: a VLM produces working-memory tokens from the current observation; these query a Perceptual-Cognitive Memory Bank that stores and consolidates past perceptual and semantic tokens; a world model generates imagined future latents in denoising space; the retrieved memory tokens and imagined latents are fused under memory guidance to produce temporal-aware tokens that condition a diffusion action expert. Experiments are reported on five simulation suites (Libero, SimplerEnv, Mikasa-Robo, Calvin, Libero-Plus) and three categories of real-robot tasks across three platforms, with claimed gains of +9 %, +26 %, and +28 % on general, memory-dependent, and imagination-dependent real-robot tasks.
Significance. If the reported gains are shown to arise specifically from the memory-guided integration step rather than from unablated implementation choices, the work would supply a concrete, cognitively motivated mechanism for long-horizon consistency in VLA policies and could influence subsequent architectures that must handle episodic memory and forward simulation.
major comments (1)
- [Abstract / Experiments] Abstract and Experiments section: the central performance claims (+9/26/28 % real-robot gains) are presented without any description of the experimental protocol, baseline implementations, number of trials, statistical tests, or ablation variants that isolate the contribution of the memory-guided token integration. Because the weakest link identified in the stress-test is precisely the causal attribution of gains to this integration step, the absence of controlled ablations renders the primary empirical support for the framework load-bearing and currently unverifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in our experimental reporting. We agree that the current presentation of results in the abstract and experiments section lacks sufficient detail on protocols, baselines, and ablations, which is necessary to substantiate the causal role of the memory-guided integration. We will revise accordingly.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central performance claims (+9/26/28 % real-robot gains) are presented without any description of the experimental protocol, baseline implementations, number of trials, statistical tests, or ablation variants that isolate the contribution of the memory-guided token integration. Because the weakest link identified in the stress-test is precisely the causal attribution of gains to this integration step, the absence of controlled ablations renders the primary empirical support for the framework load-bearing and currently unverifiable.
Authors: We acknowledge this limitation in the current manuscript. The experiments section describes the benchmarks and overall setup but does not provide the requested granularity. In the revision we will: (1) update the abstract to briefly state the evaluation protocol, number of trials per task category, and statistical testing procedure; (2) expand the experiments section with explicit descriptions of baseline implementations (including how each baseline was reproduced or re-implemented), exact trial counts, and the statistical tests used to report significance; (3) add controlled ablation variants that disable or replace only the memory-guided token integration step while keeping all other components fixed, thereby isolating its contribution to the reported gains on memory-dependent and imagination-dependent tasks. These changes will make the empirical claims verifiable and directly address the concern about causal attribution. revision: yes
Circularity Check
No circularity; framework description is self-contained with no equations or reductions
full rationale
The paper presents an architectural framework for temporal modeling in VLA models, drawing inspiration from cognitive science mechanisms (working memory, episodic memory, internal models) and describing components such as a Perceptual-Cognitive Memory Bank, redundancy-aware consolidation, a world model in denoising latent space, and integration under memory guidance to condition a diffusion action expert. No equations, fitted parameters, predictions derived from inputs, self-citations, or ansatzes are referenced in the provided text. Performance claims are empirical results on benchmarks and real-robot tasks rather than any derivation that reduces outputs to inputs by construction. This is a standard non-circular empirical proposal.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
DIM-WAM: World-Action Modeling with Diverse Historical Event Memory
DiM-WAM is a memory-augmented world-action model that integrates multi-scale historical events and global task progress to improve long-horizon robot manipulation performance.
Reference graph
Works this paper leans on
-
[1]
Openvla: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuonget al., “Openvla: An open-source vision-language-action model,” inConference on Robot Learning. PMLR, 2025, pp. 2679–2713
2025
-
[2]
pi-0: A vision-language- action flow model for general robot control,
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “pi-0: A vision-language- action flow model for general robot control,” inProceedings of Robotics: Science and Systems, 2025
2025
-
[3]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhanget al., “Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation,” arXiv preprint arXiv:2411.19650, 2024
Pith/arXiv arXiv 2024
-
[4]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x- embodiment collaboration 0,
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jainet al., “Open x-embodiment: Robotic learning datasets and rt-x models: Open x- embodiment collaboration 0,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 6892–6903
2024
-
[5]
Rt-1: Robotics transformer for real-world control at scale,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “Rt-1: Robotics transformer for real-world control at scale,”Robotics: Science and Systems XIX, 2023
2023
-
[6]
Droid: A large-scale in-the-wild robot manipulation dataset,
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karam- cheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Elliset al., “Droid: A large-scale in-the-wild robot manipulation dataset,”arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[7]
Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems,
Q. Bu, J. Cai, L. Chen, X. Cui, Y . Ding, S. Feng, X. He, X. Huang et al., “Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025. 16
2025
-
[8]
Prismatic vlms: Investigating the design space of visually- conditioned language models,
S. Karamcheti, S. Nair, A. Balakrishna, P. Liang, T. Kollar, and D. Sadigh, “Prismatic vlms: Investigating the design space of visually- conditioned language models,” inForty-first International Conference on Machine Learning, 2024
2024
-
[9]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huanget al., “Qwen technical report,”arXiv preprint arXiv:2309.16609, 2023
Pith/arXiv arXiv 2023
-
[10]
Ttf- vla: Temporal token fusion via pixel-attention integration for vision- language-action models,
C. Liu, J. Zhang, C. Li, Z. Zhou, S. Wu, S. Huang, and H. Duan, “Ttf- vla: Temporal token fusion via pixel-attention integration for vision- language-action models,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 22, 2026, pp. 18 452–18 459
2026
-
[11]
Contextvla: Vision-language-action model with amortized multi-frame context,
H. Jang, S. Yu, H. Kwon, H. Jeon, Y . Seo, and J. Shin, “Contextvla: Vision-language-action model with amortized multi-frame context,” arXiv preprint arXiv:2510.04246, 2025
arXiv 2025
-
[12]
Lola: Long horizon latent action learning for general robot manipulation,
X. Wang, X. Gao, J. Fu, Z. Li, D. Fortier, G. Mullins, A. Kolobov, and B. Guo, “Lola: Long horizon latent action learning for general robot manipulation,”arXiv preprint arXiv:2512.20166, 2025
arXiv 2025
-
[13]
Foreact: Steering your vla with efficient visual foresight planning,
Z. Zhang, S. Yang, Q. Hu, L. J. Huang, J. Hou, Y . Sun, Y . Lu, and S. Han, “Foreact: Steering your vla with efficient visual foresight planning,”arXiv preprint arXiv:2602.12322, 2026
arXiv 2026
-
[14]
Scaling world model for hierarchical manipulation policies,
Q. Long, Y . Wang, J. Song, J. Zhang, P. Li, W. Wang, Y . Wang, H. Li, S. Xie, G. Yaoet al., “Scaling world model for hierarchical manipulation policies,”arXiv preprint arXiv:2602.10983, 2026
arXiv 2026
-
[15]
Learning universal policies via text-guided video generation,
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schu- urmans, and P. Abbeel, “Learning universal policies via text-guided video generation,”Advances in neural information processing systems, vol. 36, pp. 9156–9172, 2023
2023
-
[16]
Zero-shot robotic manipulation with pre-trained image- editing diffusion models,
K. Black, M. Nakamoto, P. Atreya, H. Walke, C. Finn, A. Kumar, and S. Levine, “Zero-shot robotic manipulation with pre-trained image- editing diffusion models,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 33 431–33 452
2024
-
[17]
Working memory (vol. 8),
A. D. Baddeley and G. J. Hitch, “Working memory (vol. 8),”New York: GA Bower (ed), Recent advances in learning and motivation, 1974
1974
-
[18]
Episodic and semantic memory,
E. Tulvinget al., “Episodic and semantic memory,”Organization of memory, vol. 1, no. 381-403, p. 1, 1972
1972
-
[19]
Fuzzy-trace theory: An interim synthesis,
V . F. Reyna and C. J. Brainerd, “Fuzzy-trace theory: An interim synthesis,”Learning and individual Differences, vol. 7, no. 1, pp. 1–75, 1995
1995
-
[20]
K. J. W. Craik,The nature of explanation. CUP Archive, 1967, vol. 445
1967
-
[21]
The emulation theory of representation: Motor control, imagery, and perception,
R. Grush, “The emulation theory of representation: Motor control, imagery, and perception,”Behavioral and brain sciences, vol. 27, no. 3, pp. 377–396, 2004
2004
-
[22]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learning,” Advances in Neural Information Processing Systems, vol. 36, pp. 44 776–44 791, 2023
2023
-
[23]
Evaluating real-world robot manipulation policies in simulation,
X. Li, K. Hsu, J. Gu, O. Mees, K. Pertsch, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kirmaniet al., “Evaluating real-world robot manipulation policies in simulation,” inConference on Robot Learning. PMLR, 2025, pp. 3705–3728
2025
-
[24]
Memory, benchmark & robots: A benchmark for solving complex tasks with reinforcement learning,
E. Cherepanov, N. Kachaev, A. K. Kovalev, and A. I. Panov, “Memory, benchmark & robots: A benchmark for solving complex tasks with reinforcement learning,”arXiv preprint arXiv:2502.10550, 2025
arXiv 2025
-
[25]
Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks,
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard, “Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks,”IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 7327–7334, 2022
2022
-
[26]
Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation,
H. Shi, B. Xie, Y . Liu, L. Sun, F. Liu, T. Wang, E. Zhou, H. Fan, X. Zhang, and G. Huang, “Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation,”arXiv preprint arXiv:2508.19236, 2025
Pith/arXiv arXiv 2025
-
[27]
Dexbotic: Open-source vision-language-action toolbox,
B. Xie, E. Zhou, F. Jia, H. Shi, H. Fan, H. Zhang, H. Li, J. Sun, J. Bin, J. Huanget al., “Dexbotic: Open-source vision-language-action toolbox,”arXiv preprint arXiv:2510.23511, 2025
arXiv 2025
-
[28]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”Transactions on Machine Learning Research Journal, 2024
2024
-
[29]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 11 975–11 986
2023
-
[30]
Denseg: Alleviating vision-language feature sparsity in multi-view 3d visual grounding,
H. Zheng, H. Shi, Y . X. Chng, R. Huang, Z. Ni, T. Tan, Q. Peng, Y . Weng, Z. Shi, and G. Huang, “Denseg: Alleviating vision-language feature sparsity in multi-view 3d visual grounding,” inAutonomous Grand Challenge CVPR 2024 Workshop, vol. 2, 2024, p. 6
2024
-
[31]
Densegrounding: Improving dense language-vision semantics for ego-centric 3d visual grounding,
H. Zheng, H. Shi, Q. Peng, Y . X. Chng, R. Huang, Y . Weng, zhongchao shi, and G. Huang, “Densegrounding: Improving dense language-vision semantics for ego-centric 3d visual grounding,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[32]
Grounding beyond detection: Enhancing contextual understanding in embodied 3d grounding,
Y . Zhang, D. Wu, H. Shi, Y . Liu, T. Wang, H. Fan, and X. Dong, “Grounding beyond detection: Enhancing contextual understanding in embodied 3d grounding,”arXiv preprint arXiv:2506.05199, 2025
Pith/arXiv arXiv 2025
-
[33]
Emulating human-like adaptive vision for efficient and flexible machine visual perception,
Y . Wang, Y . Yue, Y . Yue, H. Wang, H. Jiang, Y . Han, Z. Ni, Y . Pu, M. Shi, R. Luet al., “Emulating human-like adaptive vision for efficient and flexible machine visual perception,”Nature Machine Intelligence, pp. 1–19, 2025
2025
-
[34]
Glance and focus networks for dynamic visual recognition,
G. Huang, Y . Wang, K. Lv, H. Jiang, W. Huang, P. Qi, and S. Song, “Glance and focus networks for dynamic visual recognition,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 4, pp. 4605–4621, 2022
2022
-
[35]
Uni-adafocus: Spatial-temporal dynamic computation for video recog- nition,
Y . Wang, H. Zhang, Y . Yue, S. Song, C. Deng, J. Feng, and G. Huang, “Uni-adafocus: Spatial-temporal dynamic computation for video recog- nition,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 47, no. 3, pp. 1782–1799, 2024
2024
-
[36]
Diffusion policy: Visuomotor policy learning via ac- tion diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via ac- tion diffusion,”The International Journal of Robotics Research, p. 02783649241273668, 2023
2023
-
[37]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,”Robotics: Science and Systems XIX, 2023
2023
-
[38]
Rvt: Robotic view transformer for 3d object manipulation,
A. Goyal, J. Xu, Y . Guo, V . Blukis, Y .-W. Chao, and D. Fox, “Rvt: Robotic view transformer for 3d object manipulation,” inConference on Robot Learning. PMLR, 2023, pp. 694–710
2023
-
[39]
Spatialactor: Exploring disentangled spatial representations for robust robotic manipulation,
H. Shi, B. Xie, Y . Liu, Y . Yue, T. Wang, H. Fan, X. Zhang, and G. Huang, “Spatialactor: Exploring disentangled spatial representations for robust robotic manipulation,” inProceedings of the AAAI Confer- ence on Artificial Intelligence, vol. 40, no. 11, 2026, pp. 8969–8977
2026
-
[40]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[41]
Llama 2: Open foundation and fine-tuned chat models,
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[42]
HybridVLA: Collaborative diffusion and autoregression in a unified vision-language-action model,
J. Liu, H. Chen, Z. Liu, P. An, R. Zhang, C. Gu, X. Li, Z. Guo, S. Chen, M. Liu, C. Hou, M. Zhao, K. alex Zhou, P.-A. Heng, and S. Zhang, “HybridVLA: Collaborative diffusion and autoregression in a unified vision-language-action model,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[43]
Deer-vla: Dynamic inference of multimodal large language models for efficient robot execution,
Y . Yue, Y . Wang, B. Kang, Y . Han, S. Wang, S. Song, J. Feng, and G. Huang, “Deer-vla: Dynamic inference of multimodal large language models for efficient robot execution,”Advances in Neural Information Processing Systems, vol. 37, pp. 56 619–56 643, 2024
2024
-
[44]
Geovla: Empowering 3d representations in vision-language-action models,
L. Sun, B. Xie, Y . Liu, H. Shi, T. Wang, and J. Cao, “Geovla: Empowering 3d representations in vision-language-action models,” arXiv preprint arXiv:2508.09071, 2025
arXiv 2025
-
[45]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[46]
Gr00t n1: An open foundation model for generalist humanoid robots,
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huanget al., “Gr00t n1: An open foundation model for generalist humanoid robots,”arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[47]
Exploring object- centric temporal modeling for efficient multi-view 3d object detection,
S. Wang, Y . Liu, T. Wang, Y . Li, and X. Zhang, “Exploring object- centric temporal modeling for efficient multi-view 3d object detection,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 3621–3631
2023
-
[48]
Open compound domain adaptation with object style compensation for semantic segmentation,
T. Feng, H. Shi, X. Liu, W. Feng, L. Wan, Y . Zhou, and D. Lin, “Open compound domain adaptation with object style compensation for semantic segmentation,”Advances in Neural Information Processing Systems, vol. 36, pp. 63 136–63 149, 2023
2023
-
[49]
Octo: An open-source generalist robot policy,
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y . Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine, “Octo: An open-source generalist robot policy,” inProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[50]
What matters in building vision–language– action models for generalist robots,
X. Li, P. Li, L. Qian, M. Liu, D. Wang, J. Liu, B. Kang, X. Ma, X. Wang, D. Guoet al., “What matters in building vision–language– action models for generalist robots,”Nature Machine Intelligence, pp. 1–15, 2026. 17
2026
-
[51]
Interleave-vla: Enhancing robot manipulation with interleaved image-text instructions,
C. Fan, X. Jia, Y . Sun, Y . Wang, J. Wei, Z. Gong, X. Zhao, M. Tomizuka, X. Yang, J. Yanet al., “Interleave-vla: Enhancing robot manipulation with interleaved image-text instructions,” in1st Workshop on Safely Leveraging Vision-Language Foundation Models in Robotics: Challenges and Opportunities, 2025
2025
-
[52]
Cronusvla: Transferring latent motion across time for multi-frame prediction in manipulation,
H. Li, S. Yang, Y . Chen, Y . Tian, X. Yang, X. Chen, H. Wang, T. Wang, F. Zhao, D. Linet al., “Cronusvla: Transferring latent motion across time for multi-frame prediction in manipulation,”arXiv preprint arXiv:2506.19816, 2025
arXiv 2025
-
[53]
4d-vla: Spatiotemporal vision- language-action pretraining with cross-scene calibration,
J. Zhang, Y . Chen, Y . Xu, Z. Huang, Y . Zhou, Y .-J. Yuan, X. Cai, G. Huang, X. Quan, H. Xuet al., “4d-vla: Spatiotemporal vision- language-action pretraining with cross-scene calibration,”Advances in Neural Information Processing Systems, vol. 38, pp. 33 914–33 937, 2026
2026
-
[54]
HAMLET: Switch your vision-language-action model into a history- aware policy,
M. Koo, D. Choi, T. Kim, K. Lee, C. Kim, Y . Seo, and J. Shin, “HAMLET: Switch your vision-language-action model into a history- aware policy,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[55]
Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation,
H. Fang, M. Grotz, W. Pumacay, Y . R. Wang, D. Fox, R. Krishna, and J. Duan, “Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 15 925–15 942
2025
-
[56]
Hif-vla: Hindsight, insight and foresight through motion representation for vision-language-action models,
M. Lin, P. Ding, S. Wang, Z. Zhuang, Y . Liu, X. Tong, W. Song, S. Lyu, S. Huang, and D. Wang, “Hif-vla: Hindsight, insight and foresight through motion representation for vision-language-action models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 20 732–20 742
2026
-
[57]
Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies,
R. Zheng, Y . Liang, S. Huang, J. Gao, H. Daum ´e III, A. Kolobov, F. Huang, and J. Yang, “Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies,” inInterna- tional Conference on Learning Representations, vol. 2025, 2025, pp. 54 277–54 296
2025
-
[58]
Learning long-context diffusion policies via past-token prediction,
M. T. Villasevil, A. Tang, Y . Liu, and C. Finn, “Learning long-context diffusion policies via past-token prediction,” in9th Annual Conference on Robot Learning, 2025
2025
-
[59]
Memer: Scaling up memory for robot control via experience retrieval,
A. Sridhar, J. Pan, S. Sharma, and C. Finn, “Memer: Scaling up memory for robot control via experience retrieval,”arXiv preprint arXiv:2510.20328, 2025
arXiv 2025
-
[60]
Rmbench: Memory-dependent robotic ma- nipulation benchmark with insights into policy design,
T. Chen, Y . Wang, M. Li, Y . Qin, H. Shi, Z. Li, Y . Hu, Y . Zhang, K. Wang, Y . Chenet al., “Rmbench: Memory-dependent robotic ma- nipulation benchmark with insights into policy design,”arXiv preprint arXiv:2603.01229, 2026
arXiv 2026
-
[61]
Mem: Multi-scale embodied memory for vision language action models,
M. Torne, K. Pertsch, H. Walke, K. Vedder, S. Nair, B. Ichter, A. Z. Ren, H. Wang, J. Tang, K. Stachowiczet al., “Mem: Multi-scale embodied memory for vision language action models,”arXiv preprint arXiv:2603.03596, 2026
arXiv 2026
-
[62]
Stable video diffusion: Scaling latent video diffusion models to large datasets,
A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y . Levi, Z. English, V . V oleti, A. Lettset al., “Stable video diffusion: Scaling latent video diffusion models to large datasets,”arXiv preprint arXiv:2311.15127, 2023
Pith/arXiv arXiv 2023
-
[63]
Wan: Open and advanced large-scale video generative models,
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yanget al., “Wan: Open and advanced large-scale video generative models,”arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[64]
World simulation with video foundation models for physical ai,
A. Ali, J. Bai, M. Bala, Y . Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y .-W. Chaoet al., “World simulation with video foundation models for physical ai,”arXiv preprint arXiv:2511.00062, 2025
Pith/arXiv arXiv 2025
-
[65]
pi-0.7: a steer- able generalist robotic foundation model with emergent capabilities,
P. Intelligence, B. Ai, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, G. Bokinsky, S. Cao, T. Charbonnieret al., “pi-0.7: a steer- able generalist robotic foundation model with emergent capabilities,” arXiv preprint arXiv:2604.15483, 2026
Pith/arXiv arXiv 2026
-
[66]
Video prediction policy: A generalist robot policy with predictive visual representations,
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen, “Video prediction policy: A generalist robot policy with predictive visual representations,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 24 328–24 346
2025
-
[67]
mimic-video: Video-action models for generalizable robot control beyond vlas,
J. Pai, L. Achenbach, V . Montesinos, B. Forrai, O. Mees, and E. Nava, “mimic-video: Video-action models for generalizable robot control beyond vlas,”arXiv preprint arXiv:2512.15692, 2025
Pith/arXiv arXiv 2025
-
[68]
Predictive inverse dynamics models are scalable learners for robotic manipulation,
Y . Tian, S. Yang, J. Zeng, P. Wang, D. Lin, H. Dong, and J. Pang, “Predictive inverse dynamics models are scalable learners for robotic manipulation,” inInternational Conference on Learning Representa- tions, vol. 2025, 2025, pp. 92 033–92 052
2025
-
[69]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7132–7141
2018
-
[70]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125
2017
-
[71]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4195–4205
2023
-
[72]
Denoising diffusion implicit mod- els,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit mod- els,” inInternational Conference on Learning Representations, 2020
2020
-
[73]
Bridgedata v2: A dataset for robot learning at scale,
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen- Estruch, A. W. He, V . Myers, M. J. Kim, M. Duet al., “Bridgedata v2: A dataset for robot learning at scale,” inConference on Robot Learning. PMLR, 2023, pp. 1723–1736
2023
-
[74]
Libero-plus: In-depth robustness analysis of vision- language-action models,
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Feiet al., “Libero-plus: In-depth robustness analysis of vision- language-action models,”arXiv preprint arXiv:2510.13626, 2025
Pith/arXiv arXiv 2025
-
[75]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” inNeurIPS 2021 Workshop on Deep Generative Models and Downstream Appli- cations, 2021
2021
-
[76]
Multimodal diffusion transformer: Learning versatile behavior from multimodal goals,
M. Reuss, ¨O. E. Ya ˘gmurlu, F. Wenzel, and R. Lioutikov, “Multimodal diffusion transformer: Learning versatile behavior from multimodal goals,” inRobotics: Science and Systems, 2024
2024
-
[77]
Universal actions for enhanced embodied foundation models,
J. Zheng, J. Li, D. Liu, Y . Zheng, Z. Wang, Z. Ou, Y . Liu, J. Liu, Y .-Q. Zhang, and X. Zhan, “Universal actions for enhanced embodied foundation models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22 508–22 519
2025
-
[78]
Mail: Improving im- itation learning with selective state space models,
X. Jia, Q. Wang, A. Donat, B. Xing, G. Li, H. Zhou, O. Celik, D. Blessing, R. Lioutikov, and G. Neumann, “Mail: Improving im- itation learning with selective state space models,” in8th Annual Conference on Robot Learning, 2024
2024
-
[79]
Spatialvla: Exploring spatial representations for visual-language-action model,
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wanget al., “Spatialvla: Exploring spatial representations for visual-language-action model,” inProceedings of Robotics: Science and Systems, 2025
2025
-
[80]
Worldvla: Towards autoregressive action world model,
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wanget al., “Worldvla: Towards autoregressive action world model,”arXiv preprint arXiv:2506.21539, 2025
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.