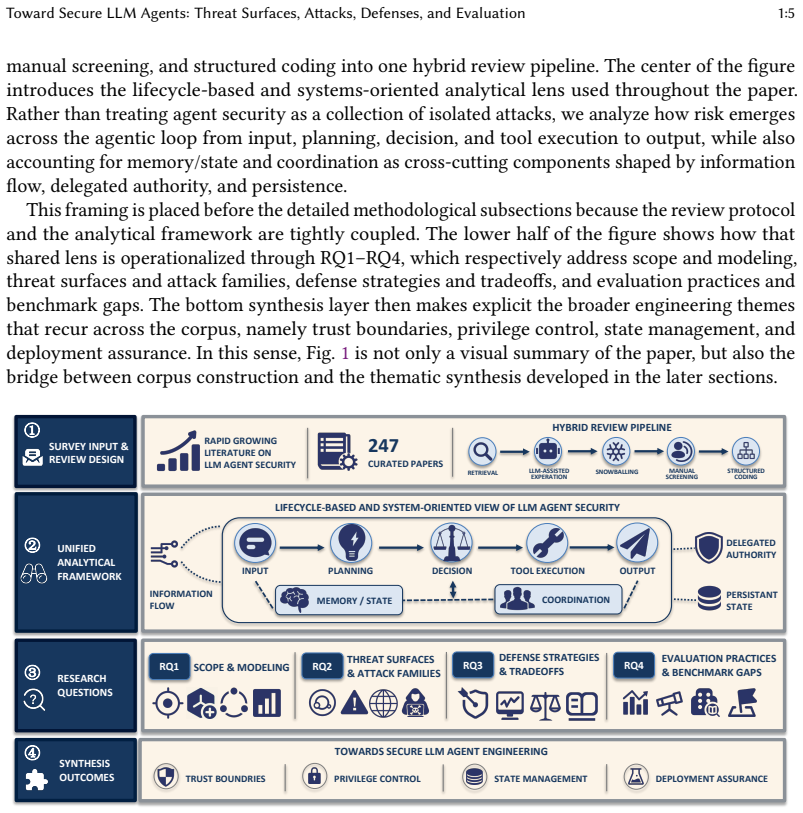
Toward Secure LLM Agents: Threat Surfaces, Attacks, Defenses, and Evaluation
Pith reviewed 2026-06-27 12:53 UTC · model grok-4.3
The pith
Secure LLM agents require explicit trust boundaries, principled privilege control, provenance-aware state management, and evaluation practices aligned with realistic operational settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By synthesizing 247 papers through a lifecycle-based, systems-oriented framework, the authors determine that prompt injection and tool-mediated control-flow hijacking dominate LLM agent threats, with persistent state corruption and multi-agent propagation emerging as key concerns. Defenses offer useful components but lack strong composition, and evaluations often miss long-horizon and deployment realities. This leads to the claim that secure LLM agents depend on explicit trust boundaries, principled privilege control, provenance-aware state management, and aligned evaluation practices.
What carries the argument
The lifecycle-based, systems-oriented framework modeling agent security around the interaction of information flow, delegated authority, and persistent state.
If this is right
- Prompt injection and tool-mediated control-flow hijacking dominate the field of LLM agent attacks.
- Persistent state corruption and multi-agent propagation are becoming central emerging concerns.
- Current defenses provide useful building blocks but remain weakly compositional.
- Existing benchmarks still underrepresent long-horizon, stateful, and deployment-sensitive risks.
Where Pith is reading between the lines
- Adopting provenance tracking in agent memory could stop corrupted data from affecting later decisions in long-running tasks.
- The framework suggests developers should treat tool calls with the same care as external API access in conventional software.
- Evaluation methods might improve by testing agents across multiple sessions that carry state forward.
- These requirements echo least-privilege ideas but must handle the open-ended planning that LLMs perform.
Load-bearing premise
The 247 selected papers sufficiently represent the broader literature on LLM agent security to identify the main threats, defenses, and gaps.
What would settle it
A new survey covering a substantially different collection of papers that finds other attack types dominant or shows that existing defenses compose effectively in practice would undermine the synthesis.
Figures



read the original abstract
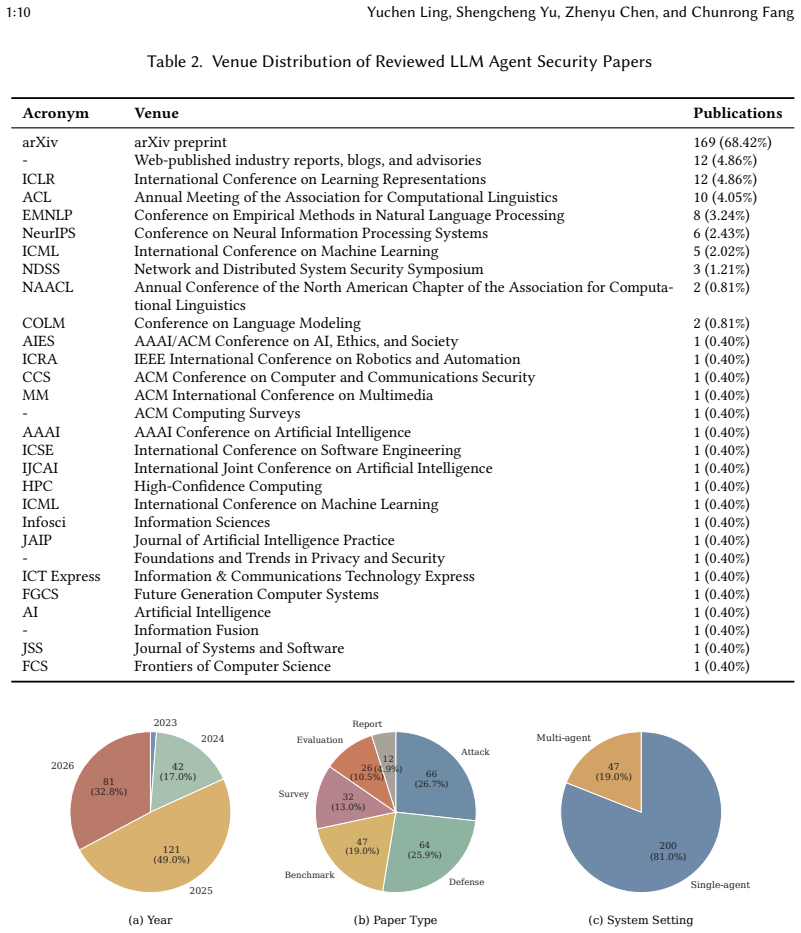
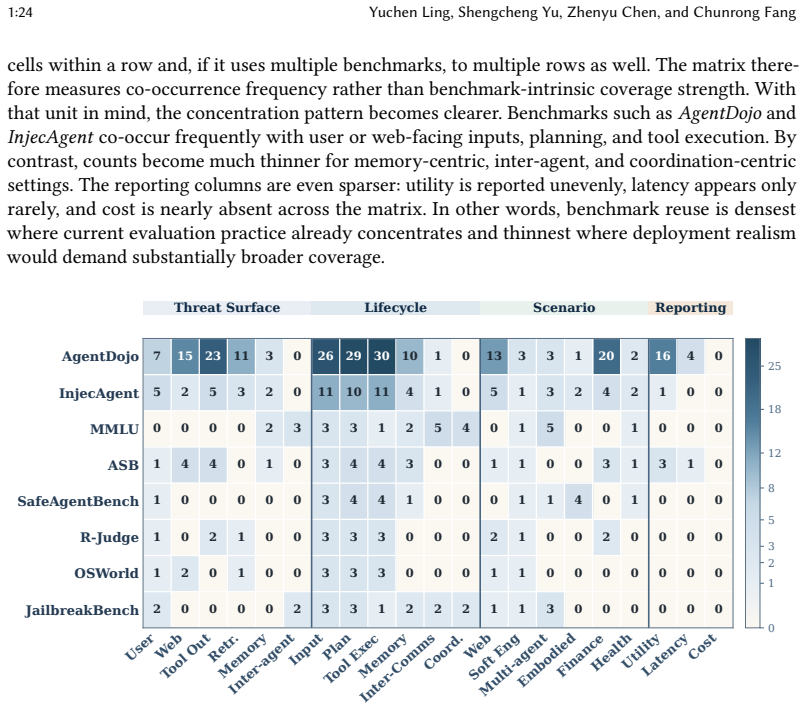
Large language model (LLM) agents are rapidly moving from conversational interfaces to software components that plan, invoke tools, maintain memory, and act on external environments. This transition changes the nature of security risk. In agentic settings, failures are no longer limited to unsafe text generation. Untrusted content may redirect control flow, misuse tool privileges, corrupt persistent state, leak sensitive information, or trigger harmful external actions. At the same time, research on LLM agent security is expanding quickly but remains fragmented across attack families, defense layers, application domains, and evaluation settings. This paper synthesizes 247 papers through a lifecycle-based, systems-oriented framework that models agent security around the interaction of information flow, delegated authority, and persistent state. We organize the literature around four questions: how LLM agent security should be modeled, which threat surfaces and attack families dominate, what defenses have been proposed and with what tradeoffs, and how security claims are evaluated. We find that prompt injection and tool-mediated control-flow hijacking still dominate the field, while persistent state corruption and multi-agent propagation are becoming central emerging concerns. We further find that current defenses provide useful building blocks but remain weakly compositional, and that existing benchmarks still underrepresent long-horizon, stateful, and deployment-sensitive risks. We argue that secure LLM agents require explicit trust boundaries, principled privilege control, provenance-aware state management, and evaluation practices aligned with realistic operational settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a survey synthesizing 247 papers on LLM agent security. It introduces a lifecycle-based, systems-oriented framework organized around information flow, delegated authority, and persistent state. The work addresses four questions: modeling of agent security, dominant threat surfaces and attack families, proposed defenses and tradeoffs, and evaluation practices. Findings include continued dominance of prompt injection and tool-mediated control-flow hijacking, emergence of persistent state corruption and multi-agent propagation risks, weak compositionality of defenses, and underrepresentation of long-horizon/stateful risks in benchmarks. The authors conclude that secure LLM agents require explicit trust boundaries, principled privilege control, provenance-aware state management, and evaluation aligned with realistic operational settings.
Significance. If the corpus selection is systematic and representative, the survey offers a useful organizing taxonomy for a rapidly expanding but fragmented area. It could help focus research on compositional defenses and more realistic benchmarks, particularly by distinguishing text-generation risks from agentic control and state issues. The framework itself provides a concrete lens for future work on trust boundaries and provenance.
major comments (2)
- [Abstract and Introduction] Abstract and Introduction: The synthesis of 247 papers is presented as the basis for identifying dominant threats (prompt injection, tool hijacking) and evaluation gaps, yet no search methodology, inclusion/exclusion criteria, database sources, or categorization protocol is described. This is load-bearing because the claims about what 'dominates' and what is 'emerging' cannot be verified for coverage bias across domains or multi-agent settings without these details.
- [Findings sections on defenses and evaluation] Findings on defenses and evaluation (the four-question organization): The assertion that 'current defenses provide useful building blocks but remain weakly compositional' and that 'existing benchmarks still underrepresent long-horizon, stateful risks' rests on the reviewed corpus; without an explicit mapping or protocol showing how papers were classified into these categories, the trade-off and gap conclusions cannot be assessed for completeness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for methodological transparency. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and Introduction] Abstract and Introduction: The synthesis of 247 papers is presented as the basis for identifying dominant threats (prompt injection, tool hijacking) and evaluation gaps, yet no search methodology, inclusion/exclusion criteria, database sources, or categorization protocol is described. This is load-bearing because the claims about what 'dominates' and what is 'emerging' cannot be verified for coverage bias across domains or multi-agent settings without these details.
Authors: We agree that the search methodology, inclusion/exclusion criteria, database sources, and categorization protocol must be described to support the claims about dominant and emerging threats. The provided manuscript text does not include these details in the abstract or introduction. In the revised version we will insert a dedicated 'Survey Methodology' subsection that specifies the databases (arXiv, Google Scholar, major security and AI conferences), search strings, date range, inclusion criteria (papers on LLM agents involving planning, tools, memory, or external actions with security implications), exclusion criteria (non-agent LLM safety papers), and the multi-author categorization protocol used to assign works to the four organizing questions. This addition will allow readers to evaluate potential coverage bias. revision: yes
-
Referee: [Findings sections on defenses and evaluation] Findings on defenses and evaluation (the four-question organization): The assertion that 'current defenses provide useful building blocks but remain weakly compositional' and that 'existing benchmarks still underrepresent long-horizon, stateful risks' rests on the reviewed corpus; without an explicit mapping or protocol showing how papers were classified into these categories, the trade-off and gap conclusions cannot be assessed for completeness.
Authors: We concur that the conclusions on weak compositionality of defenses and underrepresentation of long-horizon risks require an explicit classification protocol and mapping. The current manuscript states the findings but does not provide a detailed mapping or protocol description. We will revise by adding an appendix that summarizes the distribution of the 247 papers across categories (with representative examples) and a description of the classification process (independent review of abstracts and key sections by multiple authors, with consensus resolution). This will make the evidentiary basis for the trade-off and gap claims verifiable. revision: yes
Circularity Check
No circularity: survey synthesis rests on external literature
full rationale
This is a survey paper that organizes and synthesizes 247 external papers under a lifecycle framework. No mathematical derivations, fitted parameters, equations, or ansatzes appear. Central claims about required security properties (trust boundaries, privilege control, provenance-aware state) are presented as conclusions drawn from the reviewed literature rather than self-defined or forced by internal construction. Self-citations, if present, are not load-bearing for the synthesis itself. The enumerated circularity patterns (self-definitional, fitted-input prediction, uniqueness imported from authors, etc.) do not apply. Representativeness of the corpus is a methodological validity question outside the circularity criteria.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Agents That Know Too Much: A Data-Centric Survey of Privacy in LLM Agents
A data-centric survey finds that only information-flow control covers compositional and cross-session leakage in LLM agents and that no single benchmark tests an agent across all its data surfaces under one policy.
Reference graph
Works this paper leans on
-
[1]
Sahar Abdelnabi, Aideen Fay, Ahmed Salem, Egor Zverev, Kai-Chieh Liao, Chi-Huang Liu, Chun-Chih Kuo, Jannis Weigend, Danyael Manlangit, Alex Apostolov, Haris Umair, João Donato, Masayuki Kawakita, Athar Mahboob, Tran Huu Bach, Tsun-Han Chiang, Myeongjin Cho, Hajin Choi, Byeonghyeon Kim, Hyeonjin Lee, Benjamin Pannell, Conor McCauley, Mark Russinovich, And...
-
[2]
Sahar Abdelnabi, Amr Gomaa, Eugene Bagdasarian, Per Ola Kristensson, and Reza Shokri. 2025. Firewalls to Secure Dynamic LLM Agentic Networks. arXiv:2502.01822 [cs.CR] doi:10.48550/arXiv.2502.01822
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.01822 2025
-
[3]
Alsharif Abuadbba, Nazatul Sultan, Surya Nepal, and Sanjay Jha. 2026. Human Society-Inspired Approaches to Agentic AI Security: The 4C Framework. arXiv:2602.01942 [cs.CR] doi:10.48550/arXiv.2602.01942
-
[4]
Tanzim Ahad, Ismail Hossain, Md Jahangir Alam, Sai Puppala, Yoonpyo Lee, Syed Bahauddin Alam, and Sajedul Talukder. 2026. Semantic Intent Fragmentation: A Single-Shot Compositional Attack on Multi-Agent AI Pipelines. arXiv:2604.08608 [cs.CR] doi:10.48550/arXiv.2604.08608
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.08608 2026
-
[5]
Hengyu An, Minxi Li, Jinghuai Zhang, Naen Xu, Chunyi Zhou, Changjiang Li, Xiaogang Xu, Tianyu Du, and Shouling Ji. 2026. ACIArena: Toward Unified Evaluation for Agent Cascading Injection. arXiv:2604.07775 [cs.AI] doi:10.48550/arXiv.2604.07775
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.07775 2026
-
[6]
Hengyu An, Jinghuai Zhang, Tianyu Du, Chunyi Zhou, Qingming Li, Tao Lin, and Shouling Ji. 2025. IPIGuard: A Novel Tool Dependency Graph-Based Defense Against Indirect Prompt Injection in LLM Agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 1023–1039. doi:10.18653/V...
-
[7]
Zico Kolter, Matt Fredrikson, Yarin Gal, and Xander Davies
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, J. Zico Kolter, Matt Fredrikson, Yarin Gal, and Xander Davies. 2025. AgentHarm: A Bench- mark for Measuring Harmfulness of LLM Agents. InInternational Conference on Learning Representations (ICLR). OpenReview.net
2025
-
[8]
Anthropic. 2024. Developing a computer use model. Retrieved May 20, 2026 from https://www.anthropic.com/news/ developing-computer-use Research report
2024
-
[9]
Anthropic. 2025. Claude Sonnet 4 and Opus 4 System Card. Retrieved May 20, 2026 from https://www-cdn.anthropic. com/07b2a3f9902ee19fe39a36ca638e5ae987bc64dd.pdf System card
2025
-
[10]
Nirmit Arora, Sathvik Joel, Ishan Kavathekar, Palak, Rohan Gandhi, Yash Pandya, Tanuja Ganu, Aditya Kanade, and Akshay Nambi. 2025. Exposing Weak Links in Multi-Agent Systems under Adversarial Prompting. arXiv:2511.10949 [cs.MA] doi:10.48550/arXiv.2511.10949
-
[11]
Sadia Asif and Mohammad Mohammadi Amiri. 2026. Information-Theoretic Privacy Control for Sequential Multi- Agent LLM Systems. arXiv:2603.05520 [cs.MA] doi:10.48550/arXiv.2603.05520 ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article 1. Publication date: January 2026. 1:30 Yuchen Ling, Shengcheng Yu, Zhenyu Chen, and Chunrong Fang
-
[12]
Eugene Bagdasarian, Ren Yi, Sahra Ghalebikesabi, Peter Kairouz, Marco Gruteser, Sewoong Oh, Borja Balle, and Daniel Ramage. 2024. AirGapAgent: Protecting Privacy-Conscious Conversational Agents. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security. ACM, 3868–3882. doi:10.1145/3658644.3690350
-
[13]
Sunil Kumar Jang Bahadur and Gopala Dhar. 2025. Securing Generative AI Agentic Workflows: Risks, Mitigation, and a Proposed Firewall Architecture. arXiv:2506.17266 [cs.CR] doi:10.48550/arXiv.2506.17266
-
[14]
Julia Bazinska, Max Mathys, Francesco Casucci, Mateo Rojas-Carulla, Xander Davies, Alexandra Souly, and Niklas Pfis- ter. 2025. Breaking Agent Backbones: Evaluating the Security of Backbone LLMs in AI Agents. arXiv:2510.22620 [cs.CR] doi:10.48550/arXiv.2510.22620
-
[15]
Roy Betser, Shamik Bose, Amit Giloni, Chiara Picardi, Sindhu Padakandla, and Roman Vainshtein. 2026. AgenTRIM: Tool Risk Mitigation for Agentic AI. arXiv:2601.12449 [cs.CR] doi:10.48550/arXiv.2601.12449
-
[16]
Luca Beurer-Kellner, Beat Buesser, Ana-Maria Cretu, Edoardo Debenedetti, Daniel Dobos, Daniel Fabian, Marc Fischer, David Froelicher, Kathrin Grosse, Daniel Naeff, Ezinwanne Ozoani, Andrew Paverd, Florian Tramèr, and Václav Volhejn. 2025. Design Patterns for Securing LLM Agents against Prompt Injections. arXiv:2506.08837 [cs.LG] doi:10.48550/arXiv.2506.08837
-
[17]
Rohini Bhosale, Pankaj Chandre, Sushma Mehetre, Swati Powar, Shubhra Mathur, and Arun Ghandat. 2026. The Dark Side of Autonomous Intelligence: a survey on data leakage and privacy failures in agentic AI.Frontiers in Computer Science8 (2026), 1802727. doi:10.3389/fcomp.2026.1802727
-
[18]
Léo Boisvert, Mihir Bansal, Chandra Kiran Reddy Evuru, Gabriel Huang, Abhay Puri, Avinandan Bose, Maryam Fazel, Quentin Cappart, Jason Stanley, Alexandre Lacoste, Alexandre Drouin, and Krishnamurthy Dvijotham. 2025. DoomArena: A framework for Testing AI Agents Against Evolving Security Threats. arXiv:2504.14064 [cs.CR] doi:10.48550/arXiv.2504.14064
-
[19]
Christoph Bühler, Matteo Biagiola, Luca Di Grazia, and Guido Salvaneschi. 2025. AgentBound: Securing Execution Boundaries of AI Agents. arXiv:2510.21236 [cs.CR] doi:10.48550/arXiv.2510.21236
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.21236 2025
-
[20]
Tri Cao, Bennett Lim, Yue Liu, Yuan Sui, Yuexin Li, Shumin Deng, Lin Lu, Nay Oo, Shuicheng Yan, and Bryan Hooi. 2025. VPI-Bench: Visual Prompt Injection Attacks for Computer-Use Agents. arXiv:2506.02456 [cs.AI] doi:10.48550/arXiv.2506.02456
-
[21]
Victor Castro-Maldonado, Marco A. Aceves-Fernández, Luis R. García-Noguez, and Jesús C. Pedraza-Ortega. 2026. Semantic Firewalls with Online Ensemble Learning for Secure Agentic RAG Systems in Financial Chatbots.AI7, 3 (2026), 80. doi:10.3390/ai7030080
-
[22]
Hwan Chang, Yonghyun Jun, and Hwanhee Lee. 2025. ChatInject: Abusing Chat Templates for Prompt Injection in LLM Agents. arXiv:2509.22830 [cs.CL] doi:10.48550/arXiv.2509.22830
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.22830 2025
-
[23]
Fengchao Chen, Tingmin Wu, Van Nguyen, and Carsten Rudolph. 2026. Too Helpful to Be Safe: User-Mediated Attacks on Planning and Web-Use Agents. arXiv:2601.10758 [cs.CR] doi:10.48550/arXiv.2601.10758
-
[24]
Jizhou Chen and Samuel Lee Cong. 2025. AgentGuard: Repurposing Agentic Orchestrator for Safety Evaluation of Tool Orchestration. arXiv:2502.09809 [cs.CR] doi:10.48550/arXiv.2502.09809
-
[25]
Ruolin Chen, Yinqian Sun, Jihang Wang, Mingyang Lv, Qian Zhang, and Yi Zeng. 2025. SafeMind: Benchmarking and Mitigating Safety Risks in Embodied LLM Agents. arXiv:2509.25885 [cs.AI] doi:10.48550/arXiv.2509.25885
-
[26]
Yurun Chen, Xueyu Hu, Keting Yin, Juncheng Li, and Shengyu Zhang. 2025. Evaluating the Robustness of Multimodal Agents Against Active Environmental Injection Attacks. arXiv:2502.13053 [cs.CL] doi:10.48550/arXiv.2502.13053
-
[27]
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. 2024. AgentPoison: Red-teaming LLM Agents via Poisoning Memory or Knowledge Bases. InAdvances in Neural Information Processing Systems. doi:10.52202/079017- 4136
-
[28]
Pengzhou Cheng, Zheng Wu, Zongru Wu, Tianjie Ju, Aston Zhang, Zhuosheng Zhang, and Gongshen Liu. 2025. OS-Kairos: Adaptive Interaction for MLLM-Powered GUI Agents. InFindings of the Association for Computational Linguistics: ACL 2025. Association for Computational Linguistics, 6701–6725. doi:10.18653/v1/2025.findings-acl.348
-
[29]
Sahana Chennabasappa, Cyrus Nikolaidis, Daniel Song, David Molnar, Stephanie Ding, Shengye Wan, Spencer Whitman, Lauren Deason, Nicholas Doucette, Abraham Montilla, Alekhya Gampa, Beto de Paola, Dominik Gabi, James Crnkovich, Jean-Christophe Testud, Kat He, Rashnil Chaturvedi, Wu Zhou, and Joshua Saxe. 2025. LlamaFirewall: An open source guardrail system ...
-
[30]
Manuel Costa, Boris Köpf, Aashish Kolluri, Andrew Paverd, Mark Russinovich, Ahmed Salem, Shruti Tople, Lukas Wutschitz, and Santiago Zanella-Béguelin. 2025. Securing AI Agents with Information-Flow Control. arXiv:2505.23643 [cs.CR] doi:10.48550/arXiv.2505.23643
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.23643 2025
-
[31]
Pedro M. P. Curvo. 2025. The Traitors: Deception and Trust in Multi-Agent Language Model Simulations. arXiv:2505.12923 [cs.AI] doi:10.48550/arXiv.2505.12923
-
[32]
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tramèr. 2025. Defeating Prompt Injections by Design. arXiv:2503.18813 [cs.CR] doi:10.48550/arXiv.2503.18813 ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article 1. Publication date: January 2026. Tow...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.18813 2025
-
[33]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents. InAdvances in Neural Information Processing Systems. doi:10.52202/079017-2636
-
[34]
Xinhao Deng, Yixiang Zhang, Jiaqing Wu, Jiaqi Bai, Sibo Yi, Zhuoheng Zou, Yue Xiao, Rennai Qiu, Jianan Ma, Jialuo Chen, Xiaohu Du, Xiaofang Yang, Shiwen Cui, Changhua Meng, Weiqiang Wang, Jiaxing Song, Ke Xu, and Qi Li. 2026. Taming OpenClaw: Security Analysis and Mitigation of Autonomous LLM Agent Threats. arXiv:2603.11619 [cs.CR] doi:10.48550/arXiv.2603.11619
-
[35]
Zehang Deng, Yongjian Guo, Changzhou Han, Wanlun Ma, Junwu Xiong, Sheng Wen, and Yang Xiang. 2025. AI Agents Under Threat: A Survey of Key Security Challenges and Future Pathways.Comput. Surveys57, 7 (2025), 1–36. doi:10.1145/3716628
-
[36]
Shen Dong, Shaochen Xu, Pengfei He, Yige Li, Jiliang Tang, Tianming Liu, Hui Liu, and Zhen Xiang. 2025. Memory Injection Attacks on LLM Agents via Query-Only Interaction. InAdvances in Neural Information Processing Systems
2025
-
[37]
Zenghao Duan, Yuxin Tian, Zhiyi Yin, Liang Pang, Jingcheng Deng, Zihao Wei, Shicheng Xu, Yuyao Ge, and Xueqi Cheng. 2026. SkillAttack: Automated Red Teaming of Agent Skills through Attack Path Refinement. arXiv:2604.04989 [cs.CR] doi:10.48550/arXiv.2604.04989
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.04989 2026
-
[38]
Mateusz Dziemian, Maxwell Lin, Xiaohan Fu, Micha Nowak, Nick Winter, Eliot Krzysztof Jones, Andy Zou, Lama Ahmad, Kamalika Chaudhuri, Sahana Chennabasappa, Xander Davies, Lauren Deason, Benjamin L. Edelman, Tanner Emek, Ivan Evtimov, Jim Gust, Maia Hamin, Kat He, Klaudia Krawiecka, Riccardo Patana, Neil Perry, Troy Peterson, Xiangyu Qi, Javier Rando, Zifa...
-
[40]
Richard Fang, Rohan Bindu, Akul Gupta, and Daniel Kang. 2024. LLM Agents can Autonomously Exploit One-day Vulnerabilities. arXiv:2404.08144 [cs.CR] doi:10.48550/arXiv.2404.08144
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.08144 2024
-
[41]
Richard Fang, Rohan Bindu, Akul Gupta, Qiusi Zhan, and Daniel Kang. 2024. LLM Agents can Autonomously Hack Websites. arXiv:2402.06664 [cs.CR] doi:10.48550/arXiv.2402.06664
-
[42]
Yunhao Feng, Yifan Ding, Yingshui Tan, Boren Zheng, Yanming Guo, Xiaolong Li, Kun Zhai, Yishan Li, and Wenke Huang. 2026. SkillTrojan: Backdoor Attacks on Skill-Based Agent Systems. arXiv:2604.06811 [cs.CR] doi:10.48550/ arXiv.2604.06811
Pith/arXiv arXiv 2026
-
[43]
Mohamed Amine Ferrag, Norbert Tihanyi, Djallel Hamouda, Leandros Maglaras, Abderrahmane Lakas, and Merouane Debbah. 2026. From prompt injections to protocol exploits: Threats in LLM-powered AI agents workflows.ICT Express12, 2 (2026), 353–383. doi:10.1016/J.ICTE.2025.12.001
-
[44]
Hanna Foerster, Robert Mullins, Tom Blanchard, Nicolas Papernot, Kristina Nikolic, Florian Tramèr, Ilia Shumailov, Cheng Zhang, and Yiren Zhao. 2026. CaMeLs Can Use Computers Too: System-level Security for Computer Use Agents. arXiv:2601.09923 [cs.AI] doi:10.48550/arXiv.2601.09923
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.09923 2026
-
[45]
Gupta, Taylor Berg-Kirkpatrick, and Earlence Fernandes
Xiaohan Fu, Shuheng Li, Zihan Wang, Yihao Liu, Rajesh K. Gupta, Taylor Berg-Kirkpatrick, and Earlence Fernandes
-
[46]
Rethinking VLMs and LLMs for Image Classification.arXiv e-prints, art
Imprompter: Tricking LLM Agents into Improper Tool Use. arXiv:2410.14923 [cs.CR] doi:10.48550/arXiv.2410. 14923
-
[47]
Yuchuan Fu, Xiaohan Yuan, and Dongxia Wang. 2025. RAS-Eval: A Comprehensive Benchmark for Security Evaluation of LLM Agents in Real-World Environments. arXiv:2506.15253 [cs.CR] doi:10.48550/arXiv.2506.15253
-
[48]
Yuyou Gan, Yong Yang, Zhe Ma, Ping He, Rui Zeng, Yiming Wang, Qingming Li, Chunyi Zhou, Songze Li, Ting Wang, Yunjun Gao, Yingcai Wu, and Shouling Ji. 2024. Navigating the Risks: A Survey of Security, Privacy, and Ethics Threats in LLM-Based Agents. arXiv:2411.09523 [cs.AI] doi:10.48550/arXiv.2411.09523
-
[49]
Yiang Gao and Shanshan Wu. 2025. A Four-Layer Security Governance Framework for LLM-Based AI Agents.Journal of Artificial Intelligence Practice8, 4 (2025), 49–55. doi:10.23977/jaip.2025.080406
-
[50]
Tarek Gasmi, Ramzi Guesmi, Jihene Bennaceur, and Ines Belhadj. 2026. Bridging AI and software security: A comparative vulnerability assessment of LLM agent deployment paradigms.Information Sciences740 (2026), 123231. doi:10.1016/J.INS.2026.123231
-
[51]
Tongcheng Geng, Yubin Qu, and W. Eric Wong. 2026. A white-box prompt injection attack on embodied AI agents driven by large language models.Journal of Systems and Software235 (2026), 112782. doi:10.1016/J.JSS.2026.112782
-
[52]
GitHub. 2026. openclaw Arbitrary Malicious Code Execution Vulnerability. Retrieved May 20, 2026 from https: //github.com/openclaw/openclaw/security/advisories/GHSA-m3mh-3mpg-37hw Security advisory
2026
-
[53]
Guangyu Gong and Zizhuang Deng. 2026. PlanGuard: Defending Agents against Indirect Prompt Injection via Planning-based Consistency Verification. arXiv:2604.10134 [cs.CR] doi:10.48550/arXiv.2604.10134 ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article 1. Publication date: January 2026. 1:32 Yuchen Ling, Shengcheng Yu, Zhenyu Chen, and Chunrong Fang
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.10134 2026
-
[54]
Google DeepMind. 2025. Gemini 2.5 Computer Use. Retrieved May 20, 2026 from https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-2-5-Computer-Use-Model-Card.pdf Model card
2025
-
[55]
Google DeepMind. 2026. Gemini Robotics-ER 1.6. Retrieved May 20, 2026 from https://deepmind.google/models/ model-cards/gemini-robotics-er-1-6/ Model card
2026
-
[56]
Feng He, Tianqing Zhu, Dayong Ye, Bo Liu, Wanlei Zhou, and Philip S. Yu. 2026. The Emerged Security and Privacy of LLM Agent: A Survey with Case Studies.Comput. Surveys58, 6 (2026), 1–36. doi:10.1145/3773080
-
[57]
Ping He, Changjiang Li, Binbin Zhao, Tianyu Du, and Shouling Ji. 2025. Automatic Red Teaming LLM-based Agents with Model Context Protocol Tools. arXiv:2509.21011 [cs.CR] doi:10.48550/arXiv.2509.21011
-
[58]
Pengfei He, Yuping Lin, Shen Dong, Han Xu, Yue Xing, and Hui Liu. 2025. Red-Teaming LLM Multi-Agent Systems via Communication Attacks. InFindings of the Association for Computational Linguistics: ACL 2025. Association for Computational Linguistics, 6726–6747. doi:10.18653/v1/2025.findings-acl.349
-
[59]
Yifeng He, Ethan Wang, Yuyang Rong, Zifei Cheng, and Hao Chen. 2025. Security of AI Agents. In2025 IEEE/ACM International Workshop on Responsible AI Engineering (RAIE). IEEE, 45–52. doi:10.1109/RAIE66699.2025.00013
-
[60]
Yu He, Haozhe Zhu, Yiming Li, Shuo Shao, Hongwei Yao, Zhihao Liu, and Zhan Qin. 2026. AttriGuard: Defeating Indirect Prompt Injection in LLM Agents via Causal Attribution of Tool Invocations. arXiv:2603.10749 [cs.CR] doi:10.48550/arXiv.2603.10749
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.10749 2026
-
[61]
Manuel Herrador and Johann Rehberger. 2026. SpAIware: Uncovering a novel artificial intelligence attack vector through persistent memory in LLM applications and agents.Future Generation Computer Systems174 (2026), 107994. doi:10.1016/J.FUTURE.2025.107994
-
[62]
Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kiciman. 2024. Defending Against Indirect Prompt Injection Attacks With Spotlighting. InProceedings of the Conference on Applied Machine Learning in Information Security. CEUR-WS.org, 48–62
2024
-
[63]
Omer Hofman, Jonathan Brokman, Oren Rachmil, Shamik Bose, Vikas Pahuja, Toshiya Shimizu, Trisha Starostina, Kelly Marchisio, Seraphina Goldfarb-Tarrant, and Roman Vainshtein. 2026. MAPS: A Multilingual Benchmark for Agent Performance and Security. InFindings of the Association for Computational Linguistics: EACL 2026. Association for Computational Linguis...
-
[64]
Capture the Flags: Family-Based Evaluation of Agentic LLMs via Semantics-Preserving Transformations
Shahin Honarvar, Amber Gorzynski, James Lee-Jones, Harry Coppock, Marek Rei, Joseph Ryan, and Alastair F. Don- aldson. 2026. Capture the Flags: Family-Based Evaluation of Agentic LLMs via Semantics-Preserving Transformations. arXiv:2602.05523 [cs.SE] doi:10.48550/arXiv.2602.05523
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.05523 2026
-
[65]
Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. 2025. Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions. arXiv:2503.23278 [cs.CR] doi:10.48550/arXiv.2503.23278
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.23278 2025
-
[66]
Yuepeng Hu, Yuqi Jia, Mengyuan Li, Dawn Song, and Neil Gong. 2026. MalTool: Malicious Tool Attacks on LLM Agents. arXiv:2602.12194 [cs.CR] doi:10.48550/arXiv.2602.12194
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.12194 2026
-
[67]
Charoes Huang, Xin Huang, and Amin Milani Fard. 2026. Are AI-assisted Development Tools Immune to Prompt Injection? arXiv:2603.21642 [cs.CR] doi:10.48550/arXiv.2603.21642
-
[68]
Kung-Hsiang Huang, Akshara Prabhakar, Onkar Thorat, Divyansh Agarwal, Prafulla Kumar Choubey, Yixin Mao, Silvio Savarese, Caiming Xiong, and Chien-Sheng Wu. 2026. CRMArena-Pro: Holistic Assessment of LLM Agents Across Diverse Business Scenarios and Interactions.Transactions on Machine Learning Research2026 (2026)
2026
-
[69]
Umar Iqbal, Tadayoshi Kohno, and Franziska Roesner. 2024. LLM Platform Security: Applying a Systematic Evaluation Framework to OpenAI’s ChatGPT Plugins.Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society7 (2024), 611–623. doi:10.1609/AIES.V7I1.31664
-
[70]
Jafar Isbarov and Murat Kantarcioglu. 2026. Bypassing AI Control Protocols via Agent-as-a-Proxy Attacks. arXiv:2602.05066 [cs.CR] doi:10.48550/arXiv.2602.05066
-
[71]
Dennis Jacob, Emad Alghamdi, Zhanhao Hu, Basel Alomair, and David A. Wagner. 2025. Preventing Prompt Injection with Type-Directed Privilege Separation. arXiv:2509.25926 [cs.CR] doi:10.48550/arXiv.2509.25926
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.25926 2025
-
[72]
Jha, Harold Triedman, Justin Wagle, and Vitaly Shmatikov
Rishi D. Jha, Harold Triedman, Justin Wagle, and Vitaly Shmatikov. 2025. Breaking and Fixing Defenses Against Control-Flow Hijacking in Multi-Agent Systems. arXiv:2510.17276 [cs.LG] doi:10.48550/arXiv.2510.17276
-
[73]
Zimo Ji, Daoyuan Wu, Wenyuan Jiang, Pingchuan Ma, Zongjie Li, Yudong Gao, Shuai Wang, and Yingjiu Li
-
[74]
arXiv:2601.11893 [cs.CR] doi:10.48550/arXiv.2601.11893
Taming Various Privilege Escalation in LLM-Based Agent Systems: A Mandatory Access Control Frame- work. arXiv:2601.11893 [cs.CR] doi:10.48550/arXiv.2601.11893
-
[75]
Feiran Jia, Tong Wu, Xin Qin, and Anna Cinzia Squicciarini. 2025. The Task Shield: Enforcing Task Alignment to Defend Against Indirect Prompt Injection in LLM Agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 29680–29697. doi:10.18653/v1/202...
-
[76]
Xiaojun Jia, Jie Liao, Simeng Qin, Jindong Gu, Wenqi Ren, Xiaochun Cao, Yang Liu, and Philip Torr. 2026. SkillJect: Effectively Automating Skill-Based Prompt Injection for Skill-Enabled Agents. arXiv:2602.14211 [cs.CR] doi:10.48550/ arXiv.2602.14211 ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article 1. Publication date: January 2026. Toward Secure L...
Pith/arXiv arXiv 2026
-
[77]
Tanqiu Jiang, Yuhui Wang, Jiacheng Liang, and Ting Wang. 2026. AgentLAB: Benchmarking LLM Agents against Long-Horizon Attacks. arXiv:2602.16901 [cs.AI] doi:10.48550/arXiv.2602.16901
-
[78]
Xiaochong Jiang, Shiqi Yang, Wenting Yang, Yichen Liu, and Cheng Ji. 2026. SOK: A Taxonomy of Attack Vectors and Defense Strategies for Agentic Supply Chain Runtime. arXiv:2602.19555 [cs.CR] doi:10.48550/arXiv.2602.19555
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.19555 2026
-
[79]
Yanna Jiang, Delong Li, Haiyu Deng, Baihe Ma, Xu Wang, Qin Wang, and Guangsheng Yu. 2026. SoK: Agentic Skills - Beyond Tool Use in LLM Agents. arXiv:2602.20867 [cs.CR] doi:10.48550/arXiv.2602.20867
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.20867 2026
-
[80]
Ruochen Jiao, Shaoyuan Xie, Justin Yue, Takami Sato, Lixu Wang, Yixuan Wang, Qi Alfred Chen, and Qi Zhu. 2025. Can We Trust Embodied Agents? Exploring Backdoor Attacks against Embodied LLM-Based Decision-Making Systems. InInternational Conference on Learning Representations (ICLR). OpenReview.net
2025
-
[82]
Daniel Jones, Giorgio Severi, Martin Pouliot, Gary Lopez, Joris de Gruyter, Santiago Zanella-Béguelin, Justin Song, Blake Bullwinkel, Pamela Cortez, and Amanda J. Minnich. 2025. A Systematization of Security Vulnerabilities in Computer Use Agents. arXiv:2507.05445 [cs.CR] doi:10.48550/arXiv.2507.05445
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.