Lung-SRAD: Spectral-Aware Regularized Audio DASS with Dual-Axis Patch-Mix Contrastive Learning for Respiratory Sound Classification
Pith reviewed 2026-06-27 08:14 UTC · model grok-4.3
The pith
State space models augmented with spectral regularization and dual-axis contrastive learning raise respiratory sound classification accuracy to 64.48 percent on the ICBHI benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
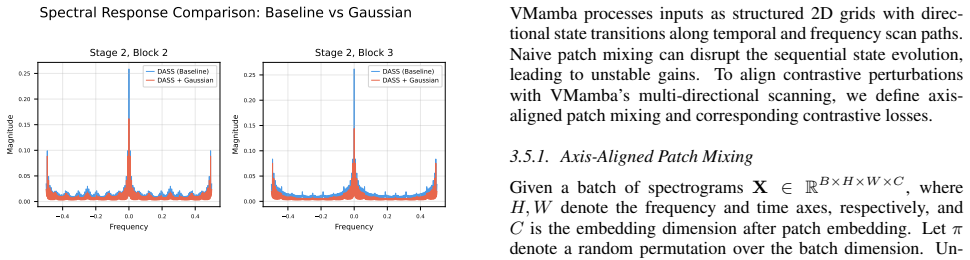
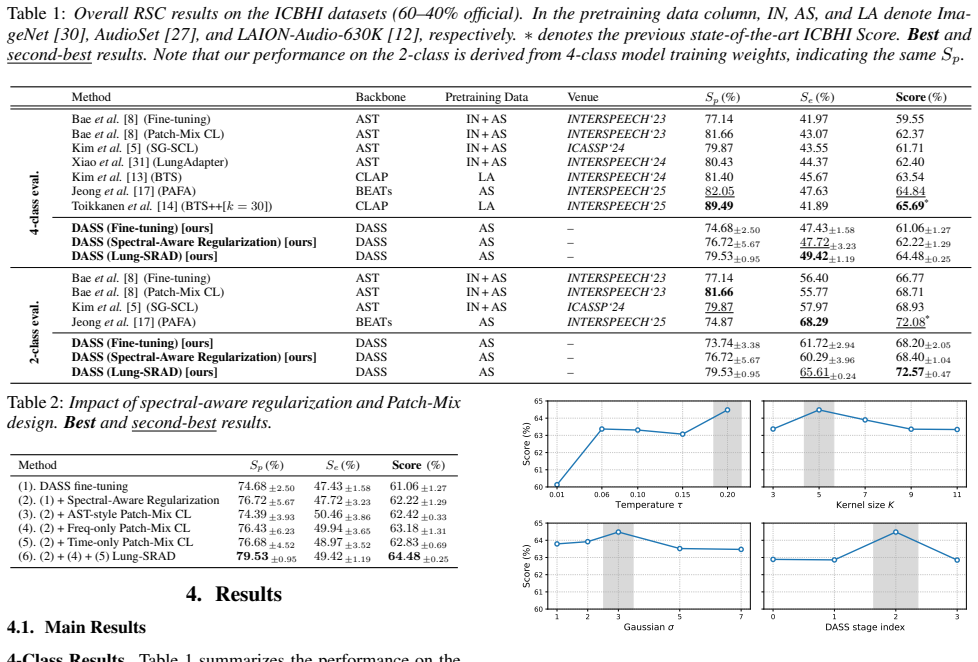
State Space Models exhibit stronger preservation of mid-to-high spatial-frequency components in their intermediate representations than CLS-token self-attention models. Applying spectral-aware layer regularization via Gaussian convolution to selected layers together with Dual-Axis Patch-Mix contrastive learning produces a model that scores 64.48 percent on the ICBHI respiratory-sound benchmark, outperforming the AST baseline by five percentage points.
What carries the argument
Spectral-aware layer regularization that applies Gaussian convolution to selected SSM layers, combined with Dual-Axis Patch-Mix contrastive learning that operates on both time and frequency patch axes.
If this is right
- SSM backbones can replace attention layers in audio tasks where local spectral detail matters more than global context.
- Gaussian convolution regularization can be applied selectively to any SSM layer stack to control frequency response.
- Dual-axis patch-mix contrastive learning provides a training objective that works directly with the patch structure of SSM audio encoders.
- The 5-point gain on ICBHI suggests that frequency-aware regularization may transfer to other sound-classification domains that rely on localized cues.
Where Pith is reading between the lines
- The same spectral-response diagnostic could be run on other sequence models to decide when SSMs are preferable to attention.
- If the frequency-preservation advantage holds, the method could be tested on speech or music datasets that contain fine-grained local events.
- The regularization strength and choice of which layers receive the Gaussian convolution remain tunable parameters that future work can optimize per dataset.
Load-bearing premise
The stronger preservation of mid-to-high frequencies observed in SSM representations is what enables better detection of localized abnormal patterns in respiratory audio.
What would settle it
An ablation that keeps the SSM backbone but removes the Gaussian spectral regularization and measures whether accuracy falls back to or below the AST level.
Figures

read the original abstract
Recent respiratory sound classification (RSC) studies largely rely on CLS-token driven self-attention architectures such as the Audio Spectrogram Transformer (AST). While effective at modeling global context, recent analyses suggest a low-pass filtering behavior that may reduce sensitivity to localized abnormal patterns. In this work, we investigate State Space Models (SSMs) as an alternative backbone for RSC. Using the Distilled Audio State Space model, we analyze intermediate representations through spectral response curves and observe stronger preservation of mid-to-high spatial-frequency components. Based on these observations, we introduce spectral-aware layer regularization using Gaussian convolution applied to selected layers. We further propose Dual-Axis Patch-Mix contrastive learning tailored to SSM-based audio models for robust representation learning. Experiments on the ICBHI benchmark show that our approach achieves 64.48% score, outperforming the AST baseline by 5%. Code is available at https://github.com/RSC-Toolkit/Lung-SRAD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Lung-SRAD, which replaces the Audio Spectrogram Transformer (AST) backbone with a Distilled Audio State Space Model (DASS) for respiratory sound classification. It observes stronger mid-to-high spatial-frequency preservation in SSM intermediate representations via spectral response curves, introduces spectral-aware Gaussian convolution regularization on selected layers, and adds Dual-Axis Patch-Mix contrastive learning. On the ICBHI benchmark the method reports a 64.48% score, a 5% absolute improvement over the AST baseline.
Significance. If the reported gain is reproducible and the frequency-preservation mechanism is shown to be causal, the work would supply concrete evidence that SSM inductive biases can outperform global self-attention for tasks that require sensitivity to localized high-frequency events in spectrograms. The provision of public code at https://github.com/RSC-Toolkit/Lung-SRAD is a positive factor for reproducibility.
major comments (2)
- [Experimental results] Experimental results section: the central performance claim (64.48% ICBHI score, +5% over AST) is presented without ablation tables that isolate the spectral-aware Gaussian regularization from the Dual-Axis Patch-Mix contrastive objective and the SSM backbone. Because the paper's narrative attributes the gain specifically to mid-to-high frequency retention, the absence of these controls leaves the causal link untested.
- [Spectral analysis] Spectral analysis subsection: the spectral response curves are used to motivate the regularization, yet no quantitative correlation (e.g., layer-wise frequency-retention metric versus per-class accuracy) is reported to link the observed curves directly to the final classification improvement.
minor comments (2)
- [Abstract] The abstract states the ICBHI 'score' without reminding readers that the official metric is (sensitivity + specificity)/2; a parenthetical clarification would improve readability.
- [Results] No error bars or number of random seeds are mentioned for the 64.48% figure; adding these in the results table would strengthen the empirical claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on manuscript arXiv:2606.11922. We address the major comments point by point below and will incorporate the requested analyses to strengthen the causal claims in the revised version.
read point-by-point responses
-
Referee: [Experimental results] Experimental results section: the central performance claim (64.48% ICBHI score, +5% over AST) is presented without ablation tables that isolate the spectral-aware Gaussian regularization from the Dual-Axis Patch-Mix contrastive objective and the SSM backbone. Because the paper's narrative attributes the gain specifically to mid-to-high frequency retention, the absence of these controls leaves the causal link untested.
Authors: We agree that the current version lacks explicit ablations isolating each component. In the revision we will add ablation tables in the Experimental results section that separately disable the spectral-aware Gaussian regularization, the Dual-Axis Patch-Mix contrastive objective, and the DASS backbone while keeping the other elements fixed. These tables will report ICBHI scores for each variant, directly testing the contribution of mid-to-high frequency retention to the reported 64.48% score. revision: yes
-
Referee: [Spectral analysis] Spectral analysis subsection: the spectral response curves are used to motivate the regularization, yet no quantitative correlation (e.g., layer-wise frequency-retention metric versus per-class accuracy) is reported to link the observed curves directly to the final classification improvement.
Authors: We acknowledge the absence of a quantitative link. In the revised Spectral analysis subsection we will define a layer-wise frequency-retention metric from the spectral response curves and compute its Pearson correlation with per-class accuracy gains. The resulting correlation coefficients and scatter plots will be reported to provide direct evidence connecting the observed frequency preservation to classification performance. revision: yes
Circularity Check
No circularity: empirical result from full model training on benchmark
full rationale
The paper's central result is an empirical ICBHI score of 64.48% obtained by training the proposed model (SSM backbone + spectral-aware Gaussian regularization + Dual-Axis Patch-Mix contrastive loss). No equations, fitted parameters, or self-citations are shown that would make this score equivalent to its inputs by construction. The spectral observations motivate the regularization design but do not define the final metric; the performance number remains an independent experimental outcome.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption State-space models preserve mid-to-high frequency content better than self-attention transformers when processing audio spectrograms.
Reference graph
Works this paper leans on
-
[1]
Introduction Abnormal lung sounds likecracklesandwheezesare key in- dicators of respiratory disorders such as pneumonia, COPD, and asthma, which account for nearly four million deaths annu- ally [1]. Crackles are associated with diseases affecting the lung parenchyma and manifest as discontinuous acoustic events [2], whereas wheezes are characterized by c...
-
[2]
Preliminaries 2.1. Dataset Description We use the ICBHI [22] dataset, comprising 5.5 hours of record- ings and 6,898 breathing cycles with four lung sounds:Normal, Crackle, WheezeandCrackle + Wheeze (Both). We follow the official 60% train and 40% test sets split, with no patient overlap between them, resulting in 4,142 cycles and 2,756 cycles. 2.2. Train...
Pith/arXiv arXiv 2026
-
[3]
Methodology We introduceLung-SRAD(Spectral-Aware Regularized Audio DASS for Lung Sounds) to address architectural limitations and spectral biases for RSC, with theoretical motivation and empir- ical validation for each design choice. 3.1. State Space Models (SSMs) SSMs.SSMs map an input sequencex(t)∈R D to an output y(t)through a latent stateh(t)∈R N : h′...
-
[4]
Main Results 4-Class Results.Table 1 summarizes the performance on the ICBHI benchmark under the official 60–40 patient indepen- dent split
Results 4.1. Main Results 4-Class Results.Table 1 summarizes the performance on the ICBHI benchmark under the official 60–40 patient indepen- dent split. With simple fine-tuning from AudioSet-distilled DASS initialization, the model achieves 61.06% Score. Apply- ing spectral-aware regularization with Gaussian convolution on selected intermediate layers im...
-
[5]
We observed that the DASS architecture preserves mid-to-high spatial-frequency components important for capturing local- ized abnormal respiratory events
Conclusion In this work, we explored SSM as a backbone for RSC. We observed that the DASS architecture preserves mid-to-high spatial-frequency components important for capturing local- ized abnormal respiratory events. Based on this observation, we introduced spectral-aware regularization using Gaussian smoothing on selected intermediate layers, along wit...
-
[6]
RS-2025-16066662)
Acknowledgement This research was supported by the Regional Innovation System & Education(RISE) program through the Jeonbuk RISE Center, funded by the Ministry of Education(MOE) and the Jeonbuk State, Republic of Korea(2026-RISE-13-WKU), and by the Na- tional Research Foundation of Korea(NRF) grant funded by the Korea government(MSIT) (grant no. RS-2025-16066662)
2026
-
[7]
The authors have verified all technical content and maintain full account- ability for the work
Generative AI Use Disclosure Generative AI (ChatGPT) was used solely for grammar correc- tion and linguistic polishing of this manuscript. The authors have verified all technical content and maintain full account- ability for the work
-
[8]
Assessing the impact of new technologies on man- aging chronic respiratory diseases,
O. Gra ˜na-Castro, E. Izquierdo, A. Pi ˜nas-Mesa, E. Menasalvas, and T. Chivato-P´erez, “Assessing the impact of new technologies on man- aging chronic respiratory diseases,”Journal of Clinical Medicine, vol. 13, no. 22, p. 6913, 2024
2024
-
[9]
Automated analysis of crackles in patients with interstitial pulmonary fibrosis,
B. Flietstra, N. Markuzon, A. Vyshedskiy, and R. Murphy, “Automated analysis of crackles in patients with interstitial pulmonary fibrosis,” Pulmonary medicine, vol. 2011, no. 1, p. 590506, 2011
2011
-
[10]
Fundamentals of lung auscultation,
A. Bohadana, G. Izbicki, and S. S. Kraman, “Fundamentals of lung auscultation,”New England Journal of Medicine, vol. 370, no. 8, pp. 744–751, 2014
2014
-
[11]
Anomaly detection from multivariate time- series with sparse representation,
N. Takeishi and T. Yairi, “Anomaly detection from multivariate time- series with sparse representation,” in2014 ieee international confer- ence on systems, man, and cybernetics (smc). IEEE, 2014, pp. 2651– 2656
2014
-
[12]
Stethoscope- guided supervised contrastive learning for cross-domain adaptation on respiratory sound classification,
J.-W. Kim, S. Bae, W.-Y . Cho, B. Lee, and H.-Y . Jung, “Stethoscope- guided supervised contrastive learning for cross-domain adaptation on respiratory sound classification,” inICASSP 2024-2024 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 1431–1435
2024
-
[13]
Adaptive metadata-guided super- vised contrastive learning for domain adaptation on respiratory sound classification,
J.-W. Kim, M. Toikkanen, A. Jalali, M. Kim, H.-J. Han, H. Kim, W. Shin, H.-Y . Jung, and K. Kim, “Adaptive metadata-guided super- vised contrastive learning for domain adaptation on respiratory sound classification,”IEEE Journal of Biomedical and Health Informatics, 2025
2025
-
[14]
Ast: Audio spectrogram trans- former,
Y . Gong, Y .-A. Chung, and J. Glass, “Ast: Audio spectrogram trans- former,” inProc. Interspeech 2021, 2021, pp. 571–575
2021
-
[15]
Patch-mix contrastive learning with audio spectrogram transformer on respiratory sound classification,
S. Bae, J.-W. Kim, W.-Y . Cho, H. Baek, S. Son, B. Lee, C. Ha, K. Tae, S. Kim, and S.-Y . Yun, “Patch-mix contrastive learning with audio spectrogram transformer on respiratory sound classification,” inProc. Interspeech 2023, 2023, pp. 5436–5440
2023
-
[16]
Adver- sarial fine-tuning using generated respiratory sound to address class imbalance,
J.-W. Kim, C. Yoon, M. Toikkanen, S. Bae, and H.-Y . Jung, “Adver- sarial fine-tuning using generated respiratory sound to address class imbalance,”arXiv preprint arXiv:2311.06480, 2023
arXiv 2023
-
[17]
Repaug- ment: Input-agnostic representation-level augmentation for respiratory sound classification,
J.-W. Kim, M. Toikkanen, S. Bae, M. Kim, and H.-Y . Jung, “Repaug- ment: Input-agnostic representation-level augmentation for respiratory sound classification,” in2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 2024, pp. 1–6
2024
-
[18]
Tri-mtl: A triple multitask learning approach for respiratory disease diagnosis,
J.-W. Kim, S. Lee, M. Toikkanen, D. Hwang, and K. Kim, “Tri-mtl: A triple multitask learning approach for respiratory disease diagnosis,” in 2025 47th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 2025, pp. 1–6
2025
-
[19]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dub- nov, “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[20]
Bts: Bridging text and sound modalities for metadata-aided respira- tory sound classification,
J.-W. Kim, M. Toikkanen, Y . Choi, S.-E. Moon, and H.-Y . Jung, “Bts: Bridging text and sound modalities for metadata-aided respira- tory sound classification,” inProc. Interspeech 2024, 2024, pp. 1690– 1694
2024
-
[21]
Improving respiratory sound classifi- cation with architecture-agnostic knowledge distillation from ensem- bles,
M. Toikkanen and J.-W. Kim, “Improving respiratory sound classifi- cation with architecture-agnostic knowledge distillation from ensem- bles,” inProc. Interspeech 2025, 2025, pp. 1023–1027
2025
-
[22]
Empow- ering multimodal respiratory sound classification with counterfactual adversarial debiasing for out-of-distribution robustness,
H. Koo, M. Toikkanen, Y . T. Kim, S. Y . Kim, and J.-W. Kim, “Empow- ering multimodal respiratory sound classification with counterfactual adversarial debiasing for out-of-distribution robustness,” inICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2026, pp. 14 967–14 971
2026
-
[23]
Beats: audio pre-training with acoustic tokeniz- ers,
S. Chen, Y . Wu, C. Wang, S. Liu, D. Tompkins, Z. Chen, W. Che, X. Yu, and F. Wei, “Beats: audio pre-training with acoustic tokeniz- ers,” inProceedings of the 40th International Conference on Machine Learning, 2023, pp. 5178–5193
2023
-
[24]
Patient-aware feature alignment for robust lung sound classification: Cohesion-separation and global alignment losses,
S. G. Jeong and S. E. Kim, “Patient-aware feature alignment for robust lung sound classification: Cohesion-separation and global alignment losses,” inProc. Interspeech 2025, 2025, pp. 1018–1022
2025
-
[25]
Masked modeling duo: Towards a universal audio pre-training frame- work,
D. Niizumi, D. Takeuchi, Y . Ohishi, N. Harada, and K. Kashino, “Masked modeling duo: Towards a universal audio pre-training frame- work,”IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 32, pp. 2391–2406, 2024
2024
-
[26]
Anti-oversmoothing in deep vision transformers via the fourier domain analysis: From theory to practice,
P. Wang, W. Zheng, T. Chen, and Z. Wang, “Anti-oversmoothing in deep vision transformers via the fourier domain analysis: From theory to practice,” inInternational Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/ forum?id=O476oWmiNNp
2022
-
[27]
Attention sinks: A’catch, tag, release’mechanism for embeddings,
S. Zhang, M. Khan, and V . Papyan, “Attention sinks: A’catch, tag, release’mechanism for embeddings,”Advances in Neural Information Processing Systems, vol. 38, pp. 83 140–83 181, 2026
2026
-
[28]
Dass: Distilled audio state space models are stronger and more duration-scalable learners,
S. Bhati, Y . Gong, L. Karlinsky, H. Kuehne, R. Feris, and J. Glass, “Dass: Distilled audio state space models are stronger and more duration-scalable learners,” in2024 IEEE Spoken Language Technol- ogy Workshop (SLT). IEEE, 2024, pp. 1015–1022
2024
-
[29]
A respiratory sound database for the development of automated classification,
B. M. Rocha, D. Filos, L. Mendes, I. V ogiatzis, E. Perantoni, E. Kaimakamis, P. Natsiavas, A. Oliveira, C. J ´acome, A. Marques et al., “A respiratory sound database for the development of automated classification,” inInternational conference on biomedical and health informatics. Springer, 2017, pp. 33–37
2017
-
[30]
Specaugment: A simple data augmentation method for automatic speech recognition,
D. S. Park, W. Chan, Y . Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V . Le, “Specaugment: A simple data augmentation method for automatic speech recognition,” inProc. Interspeech 2019, 2019, pp. 2613–2617
2019
-
[31]
Adam: A method for stochastic optimiza- tion,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimiza- tion,”arXiv preprint arXiv:1412.6980, 2014
Pith/arXiv arXiv 2014
-
[32]
Mamba: Linear-time sequence modeling with se- lective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with se- lective state spaces,”arXiv preprint arXiv:2312.00752, 2023
Pith/arXiv arXiv 2023
-
[33]
Vmamba: Visual state space model,
Y . Liu, Y . Tian, Y . Zhao, H. Yu, L. Xie, Y . Wang, Q. Ye, J. Jiao, and Y . Liu, “Vmamba: Visual state space model,”Advances in neural in- formation processing systems, vol. 37, pp. 103 031–103 063, 2024
2024
-
[34]
Audio set: An ontology and human-labeled dataset for audio events,
J. F. Gemmeke, D. P. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2017, pp. 776–780
2017
-
[35]
Hts-at: A hierarchical token-semantic audio transformer for sound classification and detection,
K. Chen, X. Du, B. Zhu, Z. Ma, T. Berg-Kirkpatrick, and S. Dub- nov, “Hts-at: A hierarchical token-semantic audio transformer for sound classification and detection,” inICASSP 2022-2022 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 646–650
2022
-
[36]
Efficient streaming language models with attention sinks,
G. Xiao, Y . Tian, B. Chen, S. Han, and M. Lewis, “Efficient streaming language models with attention sinks,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 21 875–21 895
2024
-
[37]
Ima- genet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Ima- genet: A large-scale hierarchical image database,” in2009 IEEE con- ference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
2009
-
[38]
Lungadapter: Efficient adapt- ing audio spectrogram transformer for lung sound classification,
L. Xiao, L. Fang, Y . Yang, and W. Tu, “Lungadapter: Efficient adapt- ing audio spectrogram transformer for lung sound classification,” in Proc. Interspeech 2024, 2024, pp. 4738–4742
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.