Hybrid privacy-aware semantic search: SVD-truncated document geometry and CKKS-encrypted query reranking under a restricted threat model
Pith reviewed 2026-06-30 09:32 UTC · model grok-4.3
The pith
SVD truncation to a protected subspace plus secret rotation bounds reconstruction error for document embeddings while CKKS encryption hides queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Projecting document embeddings onto an SVD-truncated subspace and rotating them with a secret orthogonal transform confines every possible decoder to that subspace, establishing a strict lower bound on reconstruction error; when paired with CKKS-encrypted queries this yields cryptographic query confidentiality and empirical document obfuscation that maintains retrieval quality on million-document corpora and defeats off-the-shelf inversion.
What carries the argument
The SVD-truncated subspace under secret orthogonal rotation, which enforces a lower bound on any decoder's reconstruction error while still permitting similarity search.
If this is right
- Retrieval quality is preserved or slightly improved on the strongest encoders because truncation acts as a linear denoiser.
- Off-the-shelf inversion attacks collapse to the noise floor under the protected geometry.
- Sub-second end-to-end latency is achieved on a one-million-document corpus.
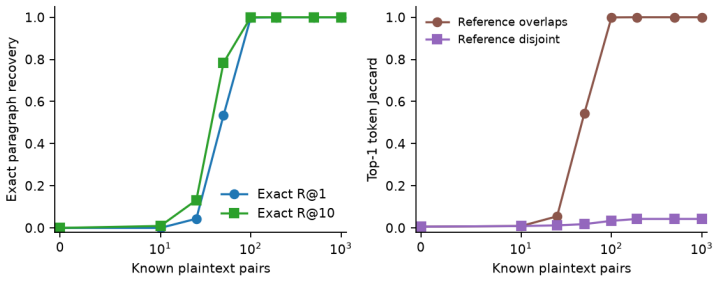
- A known-plaintext attacker needs roughly as many leaked pairs as the retained dimension to recover the rotation.
- The same geometry functions as a privacy-preserving semantic data-loss-prevention detector for LLM firewalls.
Where Pith is reading between the lines
- The observed denoising effect might be isolated and tested on other embedding models or tasks to determine whether truncation alone improves ranking in some regimes.
- The asymmetry between static protected documents and dynamic encrypted queries could be applied to other retrieval or classification settings where one side is fixed.
- Adding modest differential privacy noise to the already-truncated vectors could be measured to see how much extra protection is gained before quality degrades.
- The Procrustes recovery threshold suggests a practical rule of thumb for choosing retained dimension relative to expected leakage volume.
Load-bearing premise
The server is honest-but-curious and no attacker obtains enough known-plaintext pairs to recover the secret rotation via Procrustes analysis.
What would settle it
An inversion attack that recovers readable text from the protected vectors using fewer than the retained-dimension number of known-plaintext pairs, or a measurable drop in retrieval quality after protection on the million-document test set.
Figures















read the original abstract
Dense embeddings power semantic search and retrieval-augmented generation, yet a leaked vector database also leaks the text behind it, because embeddings can be inverted with high fidelity. Fully homomorphic search is sound but far too slow at million-document scale, while privacy noise degrades ranking before it protects. We study a middle path built on an asymmetry: the static document collection is protected geometrically - each vector is SVD-truncated onto a lower-dimensional subspace and rotated by a secret orthogonal transform held only by the data owner - while the dynamic query is protected cryptographically under CKKS, so an honest-but-curious server never sees query values or similarity scores. We prove a tight lower bound on the reconstruction error of any decoder confined to the protected subspace. On a one-million-document corpus with five encoders the protection preserves - and on the strongest encoders slightly improves - retrieval quality, a linear-denoiser effect, at sub-second latency, while an off-the-shelf inversion attack collapses to the noise floor. We also quantify the boundary: a known-plaintext attacker recovers the secret rotation by orthogonal Procrustes from about as many leaked pairs as the retained dimension. The same asymmetric geometry doubles as a privacy-preserving semantic data-loss-prevention primitive for LLM firewalls: a server holding only the protected vectors detects whether a candidate matches a confidential reference corpus at near parity with a plaintext detector, degrading gracefully under text obfuscation. We state the limits plainly: query confidentiality is cryptographic, but document protection rests on SVD truncation and a secret rotation that form an empirical obfuscation layer, not a cryptographic primitive, under a clearly delimited threat model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hybrid privacy-aware semantic search method combining SVD-truncated and rotated document embeddings for geometric protection with CKKS-encrypted queries for cryptographic protection under an honest-but-curious server model. It proves a tight lower bound on reconstruction error for subspace-confined decoders and shows through experiments on a 1M-document corpus with five encoders that retrieval quality is preserved or improved with sub-second latency, while inversion attacks fail. The method is also applied to semantic data-loss prevention.
Significance. This approach addresses the practical need for scalable privacy in semantic search without the overhead of full homomorphic encryption. The mathematical lower bound and the clear delimitation of the threat model strengthen the contribution. The observed linear-denoiser effect and the boundary quantification for known-plaintext attacks are valuable. The work has potential significance for privacy-preserving RAG systems if the empirical results are robust.
minor comments (2)
- [Abstract] The abstract refers to 'five encoders' without naming them; including the specific models would improve clarity and reproducibility.
- [Empirical Evaluation] Details on the exact truncation dimensions used and any post-hoc experimental choices should be provided to allow full verification of the retrieval quality claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and positive review. The recommendation for minor revision is appreciated, and we note the absence of specific major comments requiring point-by-point rebuttal. We will incorporate minor clarifications and improvements in the revised version to enhance readability and address any implicit suggestions from the summary.
Circularity Check
No significant circularity
full rationale
The paper's central claims consist of an explicitly stated proof of a lower bound on reconstruction error for decoders confined to the protected subspace, together with separate empirical measurements of retrieval quality on a one-million-document corpus. These elements are presented as distinct: the proof applies under the delimited honest-but-curious threat model with secret orthogonal transform, while the retrieval numbers are reported as experimental outcomes that do not reduce to any fitted parameter defined by the same experiment. The manuscript explicitly labels document-side protection as empirical obfuscation rather than a cryptographic primitive and states the Procrustes recovery boundary as a separate quantification. No equation, self-citation chain, or ansatz reduces the claimed results to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The server is honest-but-curious and does not collude to obtain the secret rotation.
- domain assumption The data owner alone controls and keeps secret the orthogonal transform applied after SVD truncation.
Forward citations
Cited by 2 Pith papers
-
SHARD: cell-keyed residual splitting for alignment-resistant private dense retrieval
SHARD shards private embedding residuals into cell-local keyed groups to raise the anchor requirement for alignment attacks by a factor of C while preserving full-dimensional nDCG@10 via encrypted reranking.
-
SHARD: cell-keyed residual splitting for alignment-resistant private dense retrieval
SHARD introduces cell-keyed residual splitting that turns dense retrieval embeddings into revocable, renewable, unlinkable templates resistant to alignment attacks while preserving exact utility under CKKS reranking.
Reference graph
Works this paper leans on
-
[1]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks,” inProc. EMNLP, 2019, pp. 3982–3992
2019
-
[2]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
L. Wang, N. Yang, X. Huang, et al., “Text Embeddings by Weakly-Supervised Contrastive Pre- training,”arXiv:2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Large Dual Encoders Are Generalizable Retrievers,
J. Ni et al., “Large Dual Encoders Are Generalizable Retrievers,” inProc. EMNLP, 2022, pp. 9844–9855
2022
-
[4]
J. Chen, S. Xiao, P. Zhang, K. Luo, D. Lian, and Z. Liu, “BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation,” arXiv:2402.03216, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Dense Passage Retrieval for Open-Domain Question Answering,
V. Karpukhin et al., “Dense Passage Retrieval for Open-Domain Question Answering,” inProc. EMNLP, 2020, pp. 6769–6781
2020
-
[6]
ColBERT: Efficient and Effective Passage Search via Contextualised Late Interaction over BERT,
O. Khattab and M. Zaharia, “ColBERT: Efficient and Effective Passage Search via Contextualised Late Interaction over BERT,” inProc. ACM SIGIR, 2020, pp. 39–48
2020
-
[7]
Text Embeddings Reveal (Almost) As Much As Text,
J. X. Morris, V. Kuleshov, V. Shmatikov, and A. M. Rush, “Text Embeddings Reveal (Almost) As Much As Text,” inProc. EMNLP, 2023
2023
-
[8]
Sentence Embedding Leaks More Information than You Expect: Generative Embedding Inversion Attack to Recover the Whole Sentence,
H. Li, M. Xu, and Y. Song, “Sentence Embedding Leaks More Information than You Expect: Generative Embedding Inversion Attack to Recover the Whole Sentence,” inFindings of ACL, 2023, pp. 14022–14040
2023
-
[9]
Transferable Embedding Inversion Attack: Uncovering Privacy Risks in Text Embeddings without Model Queries,
Y.-H. Huang, Y. Tsai, H. Hsiao, H.-Y. Lin, and S.-D. Lin, “Transferable Embedding Inversion Attack: Uncovering Privacy Risks in Text Embeddings without Model Queries,” inProc. ACL (Long), 2024, pp. 4193–4205. 26
2024
-
[10]
ALGEN: Few-shot Inversion Attacks on Textual Embeddings via Cross-Model Alignment and Generation,
Y. Chen, Q. Xu, and J. Bjerva, “ALGEN: Few-shot Inversion Attacks on Textual Embeddings via Cross-Model Alignment and Generation,” inProc. ACL (Long), 2025, pp. 24330–24348. arXiv:2502.11308
-
[11]
Universal Zero-shot Embedding Inversion,
C. Zhang, J. X. Morris, and V. Shmatikov, “Universal Zero-shot Embedding Inversion,” arXiv:2504.00147, 2025
-
[12]
Harnessing the Universal Geometry of Embed- dings,
R. Jha, C. Zhang, V. Shmatikov, and J. X. Morris, “Harnessing the Universal Geometry of Embeddings (vec2vec),”arXiv:2505.12540, 2025
-
[13]
Zero2Text: Zero-Training Cross-Domain Inversion Attacks on Textual Embeddings,
D. Kim, D. Kang, K. Lee, H. Baek, and B. B. Kang, “Zero2Text: Zero-Training Cross-Domain Inversion Attacks on Textual Embeddings,”arXiv:2602.01757, 2026
-
[14]
The Good and the Bad: Exploring Privacy Issues in Retrieval-Augmented Generation (RAG),
S. Zeng et al., “The Good and the Bad: Exploring Privacy Issues in Retrieval-Augmented Generation (RAG),” inFindings of ACL, 2024, pp. 4505–4524
2024
-
[15]
Information Leakage in Embedding Models,
C. Song and A. Raghunathan, “Information Leakage in Embedding Models,” inProc. ACM CCS, 2020, pp. 377–390
2020
-
[16]
Membership Inference Attacks Against Machine Learning Models,
R. Shokri et al., “Membership Inference Attacks Against Machine Learning Models,” inProc. IEEE S&P, 2017, pp. 3–18
2017
-
[17]
Extracting Training Data from Large Language Models,
N. Carlini et al., “Extracting Training Data from Large Language Models,” inProc. USENIX Security, 2021, pp. 2633–2650
2021
-
[18]
Differential Privacy,
C. Dwork, “Differential Privacy,” inProc. ICALP, 2006, pp. 1–12
2006
-
[19]
Deep Learning with Differential Privacy,
M. Abadi et al., “Deep Learning with Differential Privacy,” inProc. ACM CCS, 2016, pp. 308–318
2016
-
[20]
Differentially Private Representation for NLP,
L. Lyu, X. He, and Y. Li, “Differentially Private Representation for NLP,” inFindings of EMNLP, 2020, pp. 2355–2365
2020
-
[21]
Privacy via the Johnson-Lindenstrauss Transform,
K. Kenthapadi, A. Korolova, I. Mironov, and N. Mishra, “Privacy via the Johnson-Lindenstrauss Transform,”J. Privacy and Confidentiality, vol. 5, no. 1, 2013
2013
-
[22]
Random Projection-Based Multiplicative Data Perturbation for Privacy Preserving Distributed Data Mining,
K. Liu, H. Kargupta, and J. Ryan, “Random Projection-Based Multiplicative Data Perturbation for Privacy Preserving Distributed Data Mining,”IEEE TKDE, vol. 18, no. 1, 2006, pp. 92–106
2006
-
[23]
Homomorphic Encryption for Arithmetic of Approximate Numbers,
J. H. Cheon, A. Kim, M. Kim, and Y. Song, “Homomorphic Encryption for Arithmetic of Approximate Numbers,” inAdvances in Cryptology—ASIACRYPT 2017, LNCS 10624, pp. 409–437
2017
-
[24]
Bootstrapping for Approximate Homomorphic Encryption,
J. H. Cheon, K. Han, A. Kim et al., “Bootstrapping for Approximate Homomorphic Encryption,” in Advances in Cryptology—EUROCRYPT 2018, LNCS 10820, pp. 360–384
2018
-
[25]
Homomorphic Encryption Security Standard,
M. Albrecht et al., “Homomorphic Encryption Security Standard,” HomomorphicEncryption.org, 2018
2018
-
[26]
On the Concrete Hardness of Learning with Errors,
M. R. Albrecht, R. Player, and S. Scott, “On the Concrete Hardness of Learning with Errors,”Journal of Mathematical Cryptology, vol. 9, no. 3, 2015, pp. 169–203 (lattice-estimator methodology)
2015
-
[27]
A Generalized Solution of the Orthogonal Procrustes Problem,
P. H. Schönemann, “A Generalized Solution of the Orthogonal Procrustes Problem,”Psychometrika, vol. 31, no. 1, 1966, pp. 1–10
1966
-
[28]
OpenFHE: Open-Source Fully Homomorphic Encryption Library,
A. Al Badawi et al., “OpenFHE: Open-Source Fully Homomorphic Encryption Library,” inProc. WAHC ’22, 2022, pp. 53–63
2022
-
[29]
EVA: An Encrypted Vector Arithmetic Language and Compiler for Efficient Homomorphic Computation,
R. Dathathri et al., “EVA: An Encrypted Vector Arithmetic Language and Compiler for Efficient Homomorphic Computation,” inProc. ACM PLDI, 2020, pp. 546–561
2020
-
[30]
CHET: An Optimizing Compiler for Fully-Homomorphic Neural-Network Inferencing,
R. Dathathri et al., “CHET: An Optimizing Compiler for Fully-Homomorphic Neural-Network Inferencing,” inProc. ACM PLDI, 2019, pp. 142–156
2019
-
[31]
Over 100x Faster Bootstrapping in Fully Homomorphic Encryption through Memory-centric Optimisation with GPUs,
W. Jung, S. Kim, J. H. Ahn et al., “Over 100x Faster Bootstrapping in Fully Homomorphic Encryption through Memory-centric Optimisation with GPUs,”IACR TCHES, vol. 2021, no. 4, pp. 114–148. 27
2021
-
[32]
Intel HEXL: Accelerating Homomorphic Encryption with Intel AVX512-IFMA52,
F. Boemer et al., “Intel HEXL: Accelerating Homomorphic Encryption with Intel AVX512-IFMA52,” inProc. WAHC ’21, 2021, pp. 57–62
2021
-
[33]
CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy,
R. Gilad-Bachrach et al., “CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy,” inProc. ICML, 2016, vol. 48, pp. 201–210
2016
-
[34]
Private Web Search with Tiptoe,
A. Henzinger, E. Dauterman, H. Corrigan-Gibbs, and N. Zeldovich, “Private Web Search with Tiptoe,” inProc. ACM SOSP, 2023
2023
-
[35]
PIR with Compressed Queries and Amortised Query Processing,
S. Angel, H. Chen, K. Laine, and S. Setty, “PIR with Compressed Queries and Amortised Query Processing,” inProc. IEEE S&P, 2018, pp. 962–979
2018
-
[36]
One Server for the Price of Two: Simple and Fast Single-Server Private Information Retrieval (SimplePIR),
A. Henzinger, M. M. Hong, H. Corrigan-Gibbs, S. Meiklejohn, and V. Vaikuntanathan, “One Server for the Price of Two: Simple and Fast Single-Server Private Information Retrieval (SimplePIR),” in Proc. USENIX Security, 2023
2023
-
[37]
OnionPIR: Response Efficient Single-Server PIR,
M. H. Mughees, H. Chen, and L. Ren, “OnionPIR: Response Efficient Single-Server PIR,” inProc. ACM CCS, 2021, pp. 2292–2306
2021
-
[38]
Finding Structure with Randomness: Probabilistic Algorithms for Constructing Approximate Matrix Decompositions,
N. Halko, P.-G. Martinsson, and J. A. Tropp, “Finding Structure with Randomness: Probabilistic Algorithms for Constructing Approximate Matrix Decompositions,”SIAM Review, vol. 53, no. 2, 2011, pp. 217–288
2011
-
[39]
Product Quantisation for Nearest Neighbor Search,
H. Jegou, M. Douze, and C. Schmid, “Product Quantisation for Nearest Neighbor Search,”IEEE TPAMI, vol. 33, no. 1, 2011, pp. 117–128
2011
-
[40]
Efficient and Robust Approximate Nearest Neighbour Search Using Hierarchical Navigable Small World Graphs,
Y. A. Malkov and D. A. Yashunin, “Efficient and Robust Approximate Nearest Neighbour Search Using Hierarchical Navigable Small World Graphs,”IEEE TPAMI, vol. 42, no. 4, 2020, pp. 824–836
2020
-
[41]
Milvus: A Purpose-Built Vector Data Management System,
J. Wang, X. Yi, R. Guo et al., “Milvus: A Purpose-Built Vector Data Management System,” inProc. ACM SIGMOD, 2021, pp. 2614–2627
2021
-
[42]
The Approximation of One Matrix by Another of Lower Rank,
C. Eckart and G. Young, “The Approximation of One Matrix by Another of Lower Rank,”Psychome- trika, vol. 1, no. 3, 1936, pp. 211–218
1936
-
[43]
Extensions of Lipschitz Mappings into a Hilbert Space,
W. B. Johnson and J. Lindenstrauss, “Extensions of Lipschitz Mappings into a Hilbert Space,” Contemporary Mathematics, vol. 26, 1984, pp. 189–206
1984
-
[44]
BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models,
N. Thakur, N. Reimers, A. Rücklé, A. Srivastava, and I. Gurevych, “BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models,” inProc. NeurIPS Datasets and Benchmarks Track, 2021
2021
-
[45]
BLEU: a Method for Automatic Evaluation of Machine Translation,
K. Papineni et al., “BLEU: a Method for Automatic Evaluation of Machine Translation,” inProc. ACL, 2002, pp. 311–318
2002
-
[46]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,
P. Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” inProc. NeurIPS, 2020
2020
-
[47]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection,
A. Asai et al., “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection,” in Proc. ICLR, 2024
2024
-
[48]
Corrective Retrieval Augmented Generation
S.-Q. Yan et al., “Corrective Retrieval Augmented Generation,”arXiv:2401.15884, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Retrieval-Augmented Generation for Large Language Models: A Survey
Y. Gao et al., “Retrieval-Augmented Generation for Large Language Models: A Survey,” arXiv:2312.10997, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
S. M. Kurilenko, “Hybrid Method for Privacy-Preserving Semantic Search Based on Homomorphic Encryption and Random Projections,”Vestnik Komp’yuternykh i Informatsionnykh Tekhnologiy, no. 3, 2026, pp. 44–49. doi:10.14489/vkit.2026.03.pp.044-049
-
[51]
LlamaFirewall: An open source guardrail system for building secure AI agents
Meta AI, “LlamaFirewall: An Open-Source Guardrail System for Building Secure AI Agents,” arXiv:2505.03574, 2025. 28
-
[52]
Presidio: Context-aware, pluggable and customizable data protection and de-identification SDK,
Microsoft, “Presidio: Context-aware, pluggable and customizable data protection and de-identification SDK,”https://github.com/microsoft/presidio, 2024
2024
-
[53]
AI Adoption and Risk Report,
Cyberhaven, “AI Adoption and Risk Report,” industry report, 2025. 29
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.