CodeMind: Evaluating Large Language Models for Code Reasoning
Pith reviewed 2026-05-24 03:51 UTC · model grok-4.3
The pith
Large language models can reason about some dynamic aspects of code, but their abilities drop with complexity and show little connection to bug repair performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
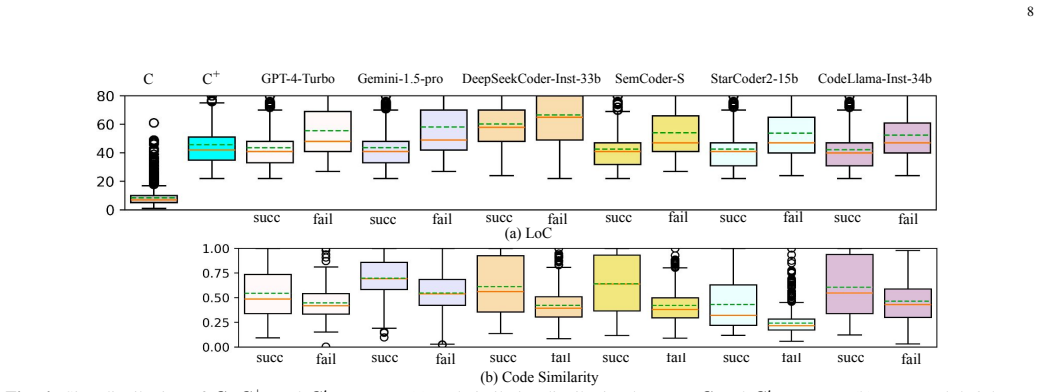
Through CodeMind, LLMs demonstrate varying abilities in Independent Execution Reasoning, Specification Reasoning, and Dynamic Semantics Reasoning depending on size and training strategy. Performance declines for higher complexity code, non-trivial operators, non-primitive types, and API calls. These tasks evaluate models differently, necessitating all for comprehensive assessment, and bug repair performance correlates with reasoning only in advanced frontier models.
What carries the argument
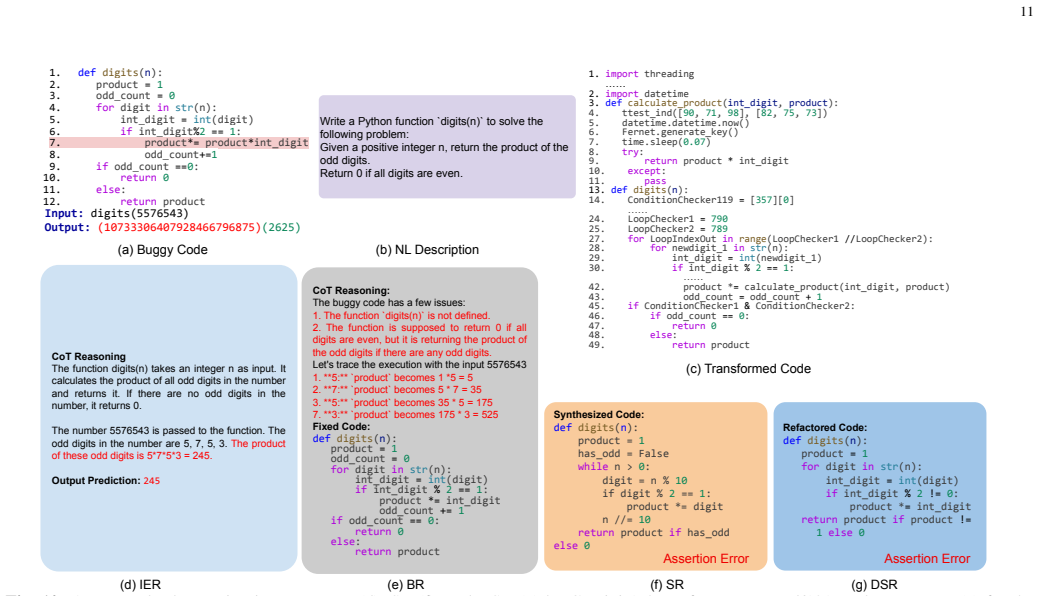
CodeMind framework consisting of three tasks - Independent Execution Reasoning to predict outputs, Specification Reasoning to incorporate test simulation in generation, and Dynamic Semantics Reasoning to understand semantics from input-output pairs - to assess code reasoning beyond generation quality.
If this is right
- LLMs require evaluation on all three reasoning tasks for complete assessment of their code capabilities.
- Code with higher complexity or certain operators will see reduced LLM performance in reasoning.
- Bug repair by LLMs does not rely on code reasoning abilities except in the most advanced models.
- Existing generation-focused evaluations miss important aspects of code understanding that CodeMind captures.
Where Pith is reading between the lines
- Training strategies could be adjusted to improve LLMs' ability to simulate code execution for more reliable outputs.
- Code reasoning might be a separate skill from generation that future models need to develop explicitly.
- This approach could apply to evaluating reasoning in other domains like mathematical proofs or scientific simulations.
Load-bearing premise
The three tasks in CodeMind together give a complete and non-overlapping picture of code reasoning abilities.
What would settle it
Finding a model that performs well on bug repair but fails the reasoning tasks, or an advanced model where reasoning and repair are not linked.
Figures








read the original abstract
Large Language Models (LLMs) have been widely used to automate programming tasks. Their capabilities have been evaluated by assessing the quality of generated code through tests or proofs. The extent to which they can reason about code is a critical question revealing important insights about their true capabilities. This paper introduces CodeMind, a framework designed to gauge the code reasoning abilities of LLMs through the following explicit and implicit code reasoning tasks: Independent Execution Reasoning (IER), Specification Reasoning (SR) and Dynamic Semantics Reasoning (DSR). The first evaluates the abilities of LLMs to simulate the execution of given inputs to a code and predict the output (IER). The second assesses the abilities of LLMs to incorporate the simulation of test data in the specification into code generation (SR). Finally, CodeMind evaluates LLMs' abilities to understand overall code semantics only given a specific input/output (DSR). Our extensive evaluation of ten LLMs across four widely used benchmarks using CodeMind shows that LLMs, depending on their size and training strategy, can reason about some dynamic aspects of code. However, their performance drops for code with higher complexity, non-trivial logical and arithmetic operators, non-primitive types, and API calls. We show that these reasoning tasks evaluate LLMs differently, and a comprehensive evaluation of code reasoning requires them all. Finally, we show that the performance of LLMs in bug repair is not correlated with any of the code reasoning tasks, and except for advanced frontier models, other LLMs do not incorporate code reasoning when performing bug repair.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CodeMind, a framework with three tasks—Independent Execution Reasoning (IER), Specification Reasoning (SR), and Dynamic Semantics Reasoning (DSR)—to evaluate LLMs' code reasoning abilities. It reports results from evaluating ten LLMs across four benchmarks, claiming that LLMs can reason about some dynamic code aspects depending on size and training strategy, but performance drops with higher complexity, non-trivial operators, non-primitive types, and API calls; that the three tasks evaluate models differently and all are required for comprehensive assessment; and that bug repair performance is uncorrelated with the reasoning tasks except for advanced frontier models.
Significance. If the empirical findings hold after addressing methodological details, the work offers a useful distinction between generation-focused and reasoning-focused evaluations of code LLMs. The reported differential behavior across tasks and the lack of correlation with bug repair (outside frontier models) could inform future benchmark design, provided the tasks are shown to be non-redundant.
major comments (2)
- [Abstract / Task Definitions] The central claim that 'a comprehensive evaluation of code reasoning requires them all' (Abstract) is load-bearing but rests on the observation of differential task performance without an explicit analysis of coverage, redundancy, or completeness; e.g., no argument is given that IER/SR/DSR together exhaust the space of dynamic code reasoning or that omitting any one materially changes conclusions.
- [Results / Bug Repair Correlation] The non-correlation result between bug repair and the three reasoning tasks (Abstract) is presented as a key finding, yet the manuscript provides no details on the correlation metric, statistical controls for model size/training, or the exact bug-repair benchmark used; this undermines assessment of whether the exception for frontier models is robust.
minor comments (2)
- [Abstract] The four benchmarks are described only as 'widely used' in the Abstract; naming them and justifying their selection would improve reproducibility.
- [Introduction / Task Overview] The distinction between 'explicit and implicit' reasoning tasks is introduced but not mapped clearly onto IER/SR/DSR; a short clarifying sentence or table would help.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and note planned revisions to improve clarity and transparency.
read point-by-point responses
-
Referee: [Abstract / Task Definitions] The central claim that 'a comprehensive evaluation of code reasoning requires them all' (Abstract) is load-bearing but rests on the observation of differential task performance without an explicit analysis of coverage, redundancy, or completeness; e.g., no argument is given that IER/SR/DSR together exhaust the space of dynamic code reasoning or that omitting any one materially changes conclusions.
Authors: The claim rests on the empirical observation that the three tasks produce distinct performance profiles across the ten models, indicating they probe different facets of dynamic reasoning: IER measures direct simulation of execution traces, SR measures the ability to embed such simulation within a generation process, and DSR measures inference of semantics solely from I/O pairs. While we do not claim the three tasks form an exhaustive partition of all possible dynamic reasoning, the results demonstrate that each supplies information not recoverable from the others. In revision we will add an explicit subsection discussing pairwise correlations among task scores and the incremental value of each task when the others are already present. revision: yes
-
Referee: [Results / Bug Repair Correlation] The non-correlation result between bug repair and the three reasoning tasks (Abstract) is presented as a key finding, yet the manuscript provides no details on the correlation metric, statistical controls for model size/training, or the exact bug-repair benchmark used; this undermines assessment of whether the exception for frontier models is robust.
Authors: We agree that the correlation analysis requires fuller documentation. The bug-repair evaluation was performed on Defects4J. We report Pearson correlation coefficients together with partial correlations that control for model parameter count; we also present stratified results for models below and above 10B parameters. In the revision we will insert the exact metric definitions, the correlation tables with p-values, and the benchmark citation into both the Methods and Results sections. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces three empirical evaluation tasks (IER, SR, DSR) and reports direct experimental results across LLMs and benchmarks. There are no mathematical derivations, equations, fitted parameters presented as predictions, or self-citation chains that reduce any central claim to its own inputs by construction. All findings rest on external model evaluations against standard benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 6 Pith papers
-
Evaluating LLMs Code Reasoning Under Real-World Context
R2Eval is a new benchmark with 135 real-world code reasoning problems from Python projects that preserves complex data structures for more realistic LLM evaluation.
-
Evaluating Code Reasoning Abilities of Large Language Models Under Real-World Settings
A new dataset and nine-metric majority-vote procedure show that existing code-reasoning benchmarks are dominated by lower-complexity problems that do not reflect real-world code.
-
Assessing Coherency and Consistency of Code Execution Reasoning by Large Language Models
LLMs achieve 81% coherent execution simulation on HumanEval but show mostly random or weak consistency across tests, with frontier models relying on natural language shortcuts instead of true program analysis.
-
PrismaDV: Automated Task-Aware Data Unit Test Generation
PrismaDV generates task-aware data unit tests by jointly analyzing downstream code and dataset profiles, outperforming task-agnostic baselines on new benchmarks spanning 60 tasks, with SIFTA enabling automatic prompt ...
-
Can We Predict Before Executing Machine Learning Agents?
LLMs primed with verified data reports predict agent solution quality at 61.5% accuracy, powering a Predict-then-Verify agent that converges 6x faster than execution-only baselines.
-
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
LiveCodeBench collects 400 recent contest problems to create a contamination-free benchmark evaluating LLMs on code generation and related capabilities like self-repair and execution.
Reference graph
Works this paper leans on
-
[1]
X. Du, M. Liu, K. Wang, H. Wang, J. Liu, Y . Chen, J. Feng, C. Sha, X. Peng, and Y . Lou, “Classeval: A manually-crafted benchmark for evaluating llms on class-level code generation,” arXiv preprint arXiv:2308.01861, 2023
-
[2]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “Swe-bench: Can language models resolve real-world github issues?” arXiv preprint arXiv:2310.06770 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Understanding the effectiveness of large language models in code translation,
R. Pan, A. R. Ibrahimzada, R. Krishna, D. Sankar, L. P. Wassi, M. Merler, B. Sobolev, R. Pavuluri, S. Sinha, and R. Jabbarvand, “Understanding the effectiveness of large language models in code translation,” arXiv preprint arXiv:2308.03109 , 2023
-
[4]
Beyond accuracy: Evaluating self-consistency of code large language models with identitychain,
M. J. Min, Y . Ding, L. Buratti, S. Pujar, G. Kaiser, S. Jana, and B. Ray, “Beyond accuracy: Evaluating self-consistency of code large language models with identitychain,” arXiv preprint arXiv:2310.14053 , 2023
-
[5]
Rect: A recursive transformer architecture for generalizable mathematical reasoning
R. Deshpande, J. Chen, and I. Lee, “Rect: A recursive transformer architecture for generalizable mathematical reasoning.” in NeSy, 2021, pp. 165–175
work page 2021
-
[6]
Z. Wu, L. Qiu, A. Ross, E. Aky ¨urek, B. Chen, B. Wang, N. Kim, J. An- dreas, and Y . Kim, “Reasoning or reciting? exploring the capabilities and limitations of language models through counterfactual tasks,” arXiv preprint arXiv:2307.02477, 2023
-
[7]
A. V . Miceli-Barone, F. Barez, I. Konstas, and S. B. Cohen, “The larger they are, the harder they fail: Language models do not recognize identifier swaps in python,” arXiv preprint arXiv:2305.15507 , 2023
-
[8]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
S. Bubeck, V . Chandrasekaran, R. Eldan, J. Gehrke, E. Horvitz, E. Ka- mar, P. Lee, Y . T. Lee, Y . Li, S. Lundberg et al. , “Sparks of artificial general intelligence: Early experiments with gpt-4,” arXiv preprint arXiv:2303.12712, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Mathcoder: Seamless code integration in llms for enhanced mathematical reasoning,
K. Wang, H. Ren, A. Zhou, Z. Lu, S. Luo, W. Shi, R. Zhang, L. Song, M. Zhan, and H. Li, “Mathcoder: Seamless code integration in llms for enhanced mathematical reasoning,” arXiv preprint arXiv:2310.03731 , 2023
-
[10]
Mathprompter: Mathematical rea- soning using large language models,
S. Imani, L. Du, and H. Shrivastava, “Mathprompter: Mathematical rea- soning using large language models,” arXiv preprint arXiv:2303.05398, 2023
-
[11]
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct
H. Luo, Q. Sun, C. Xu, P. Zhao, J. Lou, C. Tao, X. Geng, Q. Lin, S. Chen, and D. Zhang, “Wizardmath: Empowering mathematical rea- soning for large language models via reinforced evol-instruct,” arXiv preprint arXiv:2308.09583, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Do lvlms understand charts? analyzing and correcting factual errors in chart captioning,
K.-H. Huang, M. Zhou, H. P. Chan, Y . R. Fung, Z. Wang, L. Zhang, S.-F. Chang, and H. Ji, “Do lvlms understand charts? analyzing and correcting factual errors in chart captioning,” arXiv preprint arXiv:2312.10160 , 2023
-
[13]
K. Valmeekam, A. Olmo, S. Sreedharan, and S. Kambhampati, “Large language models still can’t plan (a benchmark for llms on planning and reasoning about change),” arXiv preprint arXiv:2206.10498 , 2022
-
[14]
CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution
A. Gu, B. Rozi `ere, H. Leather, A. Solar-Lezama, G. Synnaeve, and S. I. Wang, “Cruxeval: A benchmark for code reasoning, understanding and execution,” arXiv preprint arXiv:2401.03065 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Reasoning runtime behavior of a program with llm: How far are we?
J. Chen, Z. Pan, X. Hu, Z. Li, G. Li, and X. Xia, “Reasoning runtime behavior of a program with llm: How far are we?” in 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE) . IEEE Computer Society, 2024, pp. 140–152
work page 2025
-
[16]
Evaluating large language models trained on code,
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
work page 2021
-
[17]
Evaluating large language models in class-level code generation,
X. Du, M. Liu, K. Wang, H. Wang, J. Liu, Y . Chen, J. Feng, C. Sha, X. Peng, and Y . Lou, “Evaluating large language models in class-level code generation,” in Proceedings of the IEEE/ACM 46th International Conference on Software Engineering , 2024, pp. 1–13
work page 2024
-
[18]
Avatar: A parallel corpus for java-python program translation,
W. U. Ahmad, M. G. R. Tushar, S. Chakraborty, and K.-W. Chang, “Avatar: A parallel corpus for java-python program translation,” arXiv preprint arXiv:2108.11590, 2021
-
[19]
OpenAI, “Gpt-4 technical report,” https://arxiv.org/abs/2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, Y . Wu, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth et al., “Gemini: a family of highly capable multimodal models,” arXiv preprint arXiv:2312.11805 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Code Llama: Open Foundation Models for Code
B. Roziere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, T. Remez, J. Rapin et al., “Code llama: Open foundation models for code,” arXiv preprint arXiv:2308.12950 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
X. Bi, D. Chen, G. Chen, S. Chen, D. Dai, C. Deng, H. Ding, K. Dong, Q. Du, Z. Fu et al. , “Deepseek llm: Scaling open-source language models with longtermism,” arXiv preprint arXiv:2401.02954 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Semcoder: Training code language models with comprehensive semantics,
Y . Ding, J. Peng, M. J. Min, G. Kaiser, J. Yang, and B. Ray, “Semcoder: Training code language models with comprehensive semantics,” arXiv preprint arXiv:2406.01006, 2024
-
[24]
StarCoder 2 and The Stack v2: The Next Generation
A. Lozhkov, R. Li, L. B. Allal, F. Cassano, J. Lamy-Poirier, N. Tazi, A. Tang, D. Pykhtar, J. Liu, Y . Wei et al. , “Starcoder 2 and the stack v2: The next generation,” arXiv preprint arXiv:2402.19173 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
“Huggingface model hub,” https://huggingface.co/docs/hub/en/models-t he-hub, 2024
work page 2024
-
[26]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language mod- els are few-shot learners,” Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
work page 1901
-
[27]
Compositional exemplars for in-context learning,
J. Ye, Z. Wu, J. Feng, T. Yu, and L. Kong, “Compositional exemplars for in-context learning,” in International Conference on Machine Learning . PMLR, 2023, pp. 39 818–39 833
work page 2023
-
[28]
A Survey on In-context Learning
Q. Dong, L. Li, D. Dai, C. Zheng, Z. Wu, B. Chang, X. Sun, J. Xu, and Z. Sui, “A survey on in-context learning,” arXiv preprint arXiv:2301.00234, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou et al. , “Chain-of-thought prompting elicits reasoning in large language models,” Advances in Neural Information Processing Systems , vol. 35, pp. 24 824–24 837, 2022
work page 2022
-
[30]
Tree of thoughts: Deliberate problem solving with large language models,
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,” Advances in Neural Information Processing Systems , vol. 36, 2024
work page 2024
-
[31]
Graph of thoughts: Solving elaborate problems with large language models,
M. Besta, N. Blach, A. Kubicek, R. Gerstenberger, M. Podstawski, L. Gianinazzi, J. Gajda, T. Lehmann, H. Niewiadomski, P. Nyczyk et al. , “Graph of thoughts: Solving elaborate problems with large language models,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 16, 2024, pp. 17 682–17 690
work page 2024
-
[32]
Reflex- ion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflex- ion: Language agents with verbal reinforcement learning,” Advances in Neural Information Processing Systems , vol. 36, pp. 8634–8652, 2023
work page 2023
-
[33]
Cyclomatic complexity density and software maintenance productivity,
G. K. Gill and C. F. Kemerer, “Cyclomatic complexity density and software maintenance productivity,” IEEE transactions on software engineering, vol. 17, no. 12, pp. 1284–1288, 1991
work page 1991
-
[34]
Lost in the middle: How language models use long contexts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,” Transactions of the Association for Computational Linguistics , vol. 12, pp. 157–173, 2024
work page 2024
-
[35]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
N. Jain, K. Han, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica, “Livecodebench: Holistic and contamination free evaluation of large language models for code,” arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
CodeMind, “Artifact website,” https://github.com/Intelligent-CAT-Lab /CodeMind, 2024
work page 2024
-
[37]
A tool for in-depth analysis of code execution reasoning of large language models,
C. Liu and R. Jabbarvand, “A tool for in-depth analysis of code execution reasoning of large language models,” arXiv preprint arXiv:2501.18482 , 2025
-
[38]
Exerscope: Code reasoning analysis tool,
“Exerscope: Code reasoning analysis tool,” https://github.com/Intellige nt-CAT-Lab/ExeRScope, 2025
work page 2025
-
[39]
The proof and measurement of association between two things
C. Spearman, “The proof and measurement of association between two things.” 1961
work page 1961
-
[40]
Octopack: Instruction tuning code large language models,
N. Muennighoff, Q. Liu, A. Zebaze, Q. Zheng, B. Hui, T. Y . Zhuo, S. Singh, X. Tang, L. V on Werra, and S. Longpre, “Octopack: Instruction tuning code large language models,” arXiv preprint arXiv:2308.07124 , 2023
-
[41]
Large language models as code executors: An exploratory study,
C. Lyu, L. Yan, R. Xing, W. Li, Y . Samih, T. Ji, and L. Wang, “Large language models as code executors: An exploratory study,”arXiv preprint arXiv:2410.06667, 2024
-
[42]
Coconut: Structural code understanding does not fall out of a tree,
C. Beger and S. Dutta, “Coconut: Structural code understanding does not fall out of a tree,” arXiv preprint arXiv:2501.16456 , 2025
-
[43]
Code simulation as a proxy for high-order tasks in large language models,
E. La Malfa, C. Weinhuber, O. Torre, F. Lin, X. A. Huang, S. Marro, A. Cohn, N. Shadbolt, and M. Wooldridge, “Code simulation as a proxy for high-order tasks in large language models,” arXiv preprint arXiv:2502.03568, 2025. 14
-
[44]
Next: Teaching large language models to reason about code execution,
A. Ni, M. Allamanis, A. Cohan, Y . Deng, K. Shi, C. Sutton, and P. Yin, “Next: Teaching large language models to reason about code execution,” arXiv preprint arXiv:2404.14662 , 2024
-
[45]
Llm is like a box of chocolates: the non-determinism of chatgpt in code generation,
S. Ouyang, J. M. Zhang, M. Harman, and M. Wang, “Llm is like a box of chocolates: the non-determinism of chatgpt in code generation,” arXiv preprint arXiv:2308.02828 , 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.