HumanVBench: Probing Human-Centric Video Understanding in MLLMs with Automatically Synthesized Benchmarks
Pith reviewed 2026-05-23 07:02 UTC · model grok-4.3
The pith
HumanVBench reveals that leading multimodal models fall short of humans on subtle emotion perception and speech-visual alignment in videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HumanVBench, built through scalable automated synthesis of annotations and questions, establishes that even top MLLMs exhibit critical deficiencies in human-centric video understanding and remain below human performance levels.
What carries the argument
Two automated pipelines that synthesize high-quality video annotations and multiple-choice questions by leveraging state-of-the-art models and converting their induced errors into plausible distractors.
If this is right
- Progress on HumanVBench would track advances in models' social intelligence from video input.
- The synthesis method provides a template for generating evaluation data in related video understanding domains.
- Architectural or training modifications beyond current scaling will be needed to close the observed gaps.
- Public release of the benchmark enables direct comparison and iterative improvement across research groups.
Where Pith is reading between the lines
- The synthesis approach might extend to creating benchmarks for other fine-grained capabilities like intent inference or social interaction dynamics.
- Persistent gaps could indicate that video models require explicit mechanisms for tracking emotional states over time rather than relying solely on general pretraining.
- Wider use of such targeted benchmarks may shift development priorities toward cross-modal human signal alignment.
Load-bearing premise
The automatically synthesized annotations and multiple-choice questions accurately and unbiasedly probe the intended human-centric capabilities without introducing artifacts from the synthesis models themselves.
What would settle it
Independent human review of a sample of the synthesized questions and annotations that finds systematic bias, ambiguity, or mismatch with the intended capabilities.
Figures















read the original abstract
Evaluating the nuanced human-centric video understanding capabilities of Multimodal Large Language Models (MLLMs) remains a great challenge, as existing benchmarks often overlook the intricacies of emotion, behavior, and cross-modal alignment. We introduce HumanVBench, a comprehensive video benchmark designed to rigorously probe these capabilities across 16 fine-grained tasks. A cornerstone of our work is a novel and scalable benchmark construction methodology, featuring two automated pipelines that synthesize high-quality video annotations and challenging multiple-choice questions with minimal human labor. By leveraging state-of-the-art models for annotation and systematically converting model-induced errors into plausible distractors, our framework provides a generalizable ``machine'' for creating nuanced evaluation suites. Our extensive evaluation of 30 leading MLLMs on HumanVBench reveals critical deficiencies, particularly in perceiving subtle emotions and aligning speech with visual cues, with even top proprietary models falling short of human performance. We open-source HumanVBench and our synthesis pipelines to catalyze the development of more socially intelligent and capable video MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HumanVBench, a benchmark with 16 fine-grained tasks for human-centric video understanding in MLLMs. It proposes two automated pipelines that synthesize video annotations and multiple-choice questions by leveraging SOTA models and converting their errors into distractors, requiring minimal human labor. Extensive evaluation of 30 leading MLLMs reveals critical deficiencies, especially in subtle emotion perception and speech-visual alignment, with even top proprietary models underperforming humans. The benchmark and pipelines are open-sourced.
Significance. If the automated synthesis produces annotations and questions that accurately reflect human ground truth without embedding biases from the synthesis models, the results would usefully identify specific gaps in current MLLMs for nuanced social and cross-modal understanding, providing a scalable template for future benchmarks. The open-sourcing of the pipelines supports reproducibility and community extension.
major comments (2)
- [§3 (Benchmark Construction Methodology)] §3 (Benchmark Construction Methodology): The claim that the synthesized annotations and MCQs provide an unbiased probe of human-centric capabilities rests on an unverified assumption that model-induced errors converted to distractors do not correlate with the failure modes measured in the 30 evaluated MLLMs. No human validation rate, inter-annotator agreement, or accuracy metrics on the final items are reported to confirm fidelity to human ground truth.
- [§4 (Experiments)] §4 (Experiments): The headline finding of critical deficiencies (particularly in subtle emotions and speech-visual alignment) is presented without statistical significance tests, error bars, task definition details, or explicit controls for synthesis artifacts, leaving open whether the gaps versus human performance are robust or partly attributable to the synthesis process itself.
minor comments (1)
- [Abstract] The abstract could clarify the exact human performance baseline and how the 16 tasks map to the reported deficiencies.
Simulated Author's Rebuttal
Thank you for the referee's constructive feedback on our manuscript. We address each major comment point-by-point below, with honest acknowledgment of current limitations and plans for revision where needed.
read point-by-point responses
-
Referee: [§3 (Benchmark Construction Methodology)] §3 (Benchmark Construction Methodology): The claim that the synthesized annotations and MCQs provide an unbiased probe of human-centric capabilities rests on an unverified assumption that model-induced errors converted to distractors do not correlate with the failure modes measured in the 30 evaluated MLLMs. No human validation rate, inter-annotator agreement, or accuracy metrics on the final items are reported to confirm fidelity to human ground truth.
Authors: We thank the referee for this observation. Our benchmark construction deliberately uses minimal human labor and converts errors from SOTA models into distractors to create challenging, scalable items that target capabilities beyond current models. However, the manuscript does not report human validation rates, inter-annotator agreement, or accuracy metrics on the synthesized items. To address the concern about potential correlation with evaluated model failure modes and to confirm fidelity to human ground truth, we will perform a targeted human validation study on a subset of annotations and MCQs and report the resulting metrics in the revised manuscript. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments): The headline finding of critical deficiencies (particularly in subtle emotions and speech-visual alignment) is presented without statistical significance tests, error bars, task definition details, or explicit controls for synthesis artifacts, leaving open whether the gaps versus human performance are robust or partly attributable to the synthesis process itself.
Authors: We agree that the current presentation of results in §4 would be strengthened by additional statistical rigor and controls. In the revision we will add error bars to all performance figures, include statistical significance tests comparing model and human performance, expand task definition details in the main text, and provide an explicit analysis of potential synthesis artifacts (including any available controls or ablations). These additions will help demonstrate that the reported gaps are robust. revision: yes
Circularity Check
Empirical benchmark construction with no self-referential derivation
full rationale
The paper introduces HumanVBench via two automated synthesis pipelines for annotations and MCQs, then reports direct empirical evaluations of 30 MLLMs against human performance. No equations, fitted parameters, or mathematical derivations appear in the provided text. The central claims are observational comparisons on the constructed benchmark; they do not reduce by construction to the synthesis method itself or to any self-citation chain. The synthesis pipelines are described as a methodological contribution rather than a derived result that loops back to the evaluation outcomes. This is a standard empirical benchmark paper whose claims rest on external model outputs and human baselines, not on internal definitional or fitting circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 16 fine-grained tasks comprehensively cover the nuances of emotion, behavior, and cross-modal alignment in human-centric video understanding.
- domain assumption Model-induced errors can be systematically converted into plausible distractors that maintain test validity.
Forward citations
Cited by 2 Pith papers
-
FineBench: Benchmarking and Enhancing Vision-Language Models for Fine-grained Human Activity Understanding
FineBench is a new dense VQA benchmark for fine-grained human activity understanding in long videos, revealing weaknesses in open VLMs and showing that FineAgent improves them via localization and description modules.
-
FineBench: Benchmarking and Enhancing Vision-Language Models for Fine-grained Human Activity Understanding
FineBench is a new dense VQA benchmark for fine-grained human activity in long videos that exposes weaknesses in open VLMs and demonstrates gains from the proposed FineAgent modular framework.
Reference graph
Works this paper leans on
-
[1]
Keyu An, Qian Chen, Chong Deng, Zhihao Du, Changfeng Gao, Zhifu Gao, Yue Gu, Ting He, Hangrui Hu, Kai Hu, Shengpeng Ji, Yabin Li, Zerui Li, Heng Lu, Haoneng Luo, Xiang Lv, Bin Ma, Ziyang Ma, Chongjia Ni, Changhe Song, Jiaqi Shi, Xian Shi, Hao Wang, Wen Wang, Yuxuan Wang, Zhangyu Xiao, Zhijie Yan, Yexin Yang, Bin Zhang, Qinglin Zhang, Shiliang Zhang, Nan Z...
work page 2024
-
[2]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural infor- mation processing systems, 33:12449–12460, 2020. 5
work page 2020
-
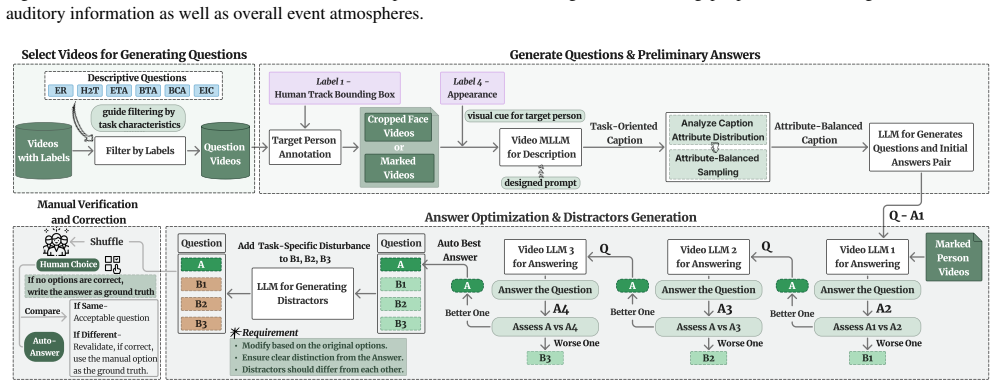
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Auroracap: Efficient, performant video detailed captioning and a new benchmark
Wenhao Chai, Enxin Song, Yilun Du, Chenlin Meng, Vashisht Madhavan, Omer Bar-Tal, Jenq-Neng Hwang, Sain- ing Xie, and Christopher D Manning. Auroracap: Efficient, performant video detailed captioning and a new benchmark. arXiv preprint arXiv:2410.03051, 2024. 3
-
[6]
Data-juicer: A one-stop data pro- cessing system for large language models
Daoyuan Chen, Yilun Huang, Zhijian Ma, Hesen Chen, Xuchen Pan, Ce Ge, Dawei Gao, Yuexiang Xie, Zhaoyang Liu, Jinyang Gao, et al. Data-juicer: A one-stop data pro- cessing system for large language models. In Companion of the 2024 International Conference on Management of Data, pages 120–134, 2024. 2, 4
work page 2024
-
[7]
Data-juicer 2.0: Cloud-scale adap- tive data processing for foundation models, 2024
Daoyuan Chen, Yilun Huang, Xuchen Pan, Nana Jiang, Haibin Wang, Ce Ge, Yushuo Chen, Wenhao Zhang, Zhi- jian Ma, Yilei Zhang, Jun Huang, Wei Lin, Yaliang Li, Bolin Ding, and Jingren Zhou. Data-juicer 2.0: Cloud-scale adap- tive data processing for foundation models, 2024. 5
work page 2024
-
[8]
Multi-modal data processing for foundation models: Practical guidances and use cases
Daoyuan Chen, Yaliang Li, and Bolin Ding. Multi-modal data processing for foundation models: Practical guidances and use cases. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, page 6414–6415, 2024. 2
work page 2024
-
[9]
Data-juicer sand- box: A comprehensive suite for multimodal data-model co- development
Daoyuan Chen, Haibin Wang, Yilun Huang, Ce Ge, Yaliang Li, Bolin Ding, and Jingren Zhou. Data-juicer sand- box: A comprehensive suite for multimodal data-model co- development. arXiv preprint arXiv:2407.11784, 2024. 4
-
[10]
Are we on the right way for evaluating large vision-language models? CoRR, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models? CoRR, 2024. 6
work page 2024
-
[11]
Sharegpt4video: Improving video understanding and generation with better captions
Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Bin Lin, Zhenyu Tang, et al. Sharegpt4video: Improving video understand- ing and generation with better captions. arXiv preprint arXiv:2406.04325, 2024. 2, 6, 5
-
[12]
Activitynet 2019 Task 3: Exploring Contexts for Dense Captioning Events in Videos
Shizhe Chen, Yuqing Song, Yida Zhao, Qin Jin, Zhaoyang Zeng, Bei Liu, Jianlong Fu, and Alexander Hauptmann. Ac- tivitynet 2019 task 3: Exploring contexts for dense caption- ing events in videos.arXiv preprint arXiv:1907.05092, 2019. 3
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[13]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks, 2024
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks, 2024. 3
work page 2024
-
[14]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. In Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 6
work page 2024
-
[15]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, Lixin Gu, Xuehui Wang, Qingyun Li, Yimin Ren, Zixuan Chen, Jiapeng Luo, Jiahao Wang, Tan Jiang, Bo Wang, Conghui He, Botian Shi, Xingcheng Zhang, Han Lv, Yi Wang, Wenqi Shao, Pei Chu, Zhongying Tu, Tong He, Zhiyong Wu, Huipeng Deng, J...
work page 2025
-
[16]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476, 2024. 3, 7, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Mmbench-video: A long-form multi-shot benchmark for holistic video under- standing
Xinyu Fang, Kangrui Mao, Haodong Duan, Xiangyu Zhao, Yining Li, Dahua Lin, and Kai Chen. Mmbench-video: A long-form multi-shot benchmark for holistic video under- standing. arXiv preprint arXiv:2406.14515, 2024. 2, 3
-
[18]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Rongrong Ji, and Xing Sun. Video-mme: The first- ever comprehensive evaluation benchmark of multi-modal llms in video analysis, 2024. 2, 3, 1
work page 2024
-
[19]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15180–15190, 2023. 3, 7
work page 2023
-
[20]
Onellm: One framework to align all modalities with language
Jiaming Han, Kaixiong Gong, Yiyuan Zhang, Jiaqi Wang, Kaipeng Zhang, Dahua Lin, Yu Qiao, Peng Gao, and Xi- 9 angyu Yue. Onellm: One framework to align all modalities with language. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26584– 26595, 2024. 3, 7
work page 2024
-
[21]
CogVLM2: Visual Language Models for Image and Video Understanding
Wenyi Hong, Weihan Wang, Ming Ding, Wenmeng Yu, Qingsong Lv, Yan Wang, Yean Cheng, Shiyu Huang, Jun- hui Ji, Zhao Xue, et al. Cogvlm2: Visual language mod- els for image and video understanding. arXiv preprint arXiv:2408.16500, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 3
work page 2024
-
[23]
Img-diff: Contrastive data syn- thesis for multimodal large language models
Qirui Jiao, Daoyuan Chen, Yilun Huang, Bolin Ding, Yaliang Li, and Ying Shen. Img-diff: Contrastive data syn- thesis for multimodal large language models. 2025. 3
work page 2025
-
[24]
Qirui Jiao, Daoyuan Chen, Yilun Huang, Yaliang Li, and Ying Shen. From training-free to adaptive: Empirical in- sights into mllms’ understanding of detection information. CVPR, 2025. 2, 1
work page 2025
-
[25]
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation em- powers large language models with image and video under- standing, 2024. 6
work page 2024
-
[26]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yix- iao Ge, and Ying Shan. Seed-bench: Benchmarking mul- timodal llms with generative comprehension. arXiv preprint arXiv:2307.16125, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Mimic-it: Multi-modal in-context instruction tuning, 2023
Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Mimic-it: Multi-modal in-context instruction tuning, 2023. 6
work page 2023
-
[28]
Llava-onevision: Easy visual task transfer, 2024
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer, 2024. 6, 8
work page 2024
-
[29]
VideoChat: Chat-Centric Video Understanding
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355, 2023. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Mvbench: A comprehensive multi- modal video understanding benchmark, 2024
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. Mvbench: A comprehensive multi- modal video understanding benchmark, 2024. 3
work page 2024
-
[31]
Herm: Benchmarking and enhancing multimodal llms for human- centric understanding
Keliang Li, Zaifei Yang, Jiahe Zhao, Hongze Shen, Ruibing Hou, Hong Chang, Shiguang Shan, and Xilin Chen. Herm: Benchmarking and enhancing multimodal llms for human- centric understanding. arXiv preprint arXiv:2410.06777 ,
-
[32]
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, and Jiaya Jia. Mini-gemini: Mining the potential of multi-modality vision language models. arXiv preprint arXiv:2403.18814,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
A light weight model for active speaker detection
Junhua Liao, Haihan Duan, Kanghui Feng, Wanbing Zhao, Yanbing Yang, and Liangyin Chen. A light weight model for active speaker detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22932–22941, 2023. 5
work page 2023
-
[34]
Video-LLaV A: Learning united visual repre- sentation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-LLaV A: Learning united visual repre- sentation by alignment before projection. In Proceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 5971–5984, Miami, Florida, USA,
work page 2024
-
[35]
Association for Computational Linguistics. 2, 3, 8
-
[36]
Vila: On pre-training for vi- sual language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Moham- mad Shoeybi, and Song Han. Vila: On pre-training for vi- sual language models. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 26689–26699, 2024. 6
work page 2024
-
[37]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024. 2
work page 2024
-
[38]
Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024. 3
work page 2024
-
[39]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36, 2024. 2
work page 2024
-
[40]
Video-chatgpt: Towards detailed video understanding via large vision and language models, 2024
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fa- had Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models, 2024. 2, 3
work page 2024
-
[41]
Egoschema: A diagnostic benchmark for very long- form video language understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long- form video language understanding. Advances in Neural In- formation Processing Systems, 36:46212–46244, 2023. 3
work page 2023
- [42]
-
[43]
Per- ception test: A diagnostic benchmark for multimodal video models
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Re- casens, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Mateusz Malinowski, Yi Yang, Carl Doersch, et al. Per- ception test: A diagnostic benchmark for multimodal video models. Advances in Neural Information Processing Sys- tems, 36, 2024. 2, 3
work page 2024
- [44]
-
[45]
Zhen Qin, Daoyuan Chen, Wenhao Zhang, Liuyi Yao, Yilun Huang, Bolin Ding, Yaliang Li, and Shuiguang Deng. The synergy between data and multi-modal large language mod- els: A survey from co-development perspective. arXiv preprint arXiv:2407.08583, 2024. 2
-
[46]
Moviechat+: Question-aware sparse memory for long video question answering
Enxin Song, Wenhao Chai, Tian Ye, Jenq-Neng Hwang, Xi Li, and Gaoang Wang. Moviechat+: Question-aware sparse memory for long video question answering. arXiv preprint arXiv:2404.17176, 2024. 3
-
[47]
Humanbench: Towards general human-centric perception with projector as- sisted pretraining, 2023
Shixiang Tang, Cheng Chen, Qingsong Xie, Meilin Chen, Yizhou Wang, Yuanzheng Ci, Lei Bai, Feng Zhu, Haiyang Yang, Li Yi, Rui Zhao, and Wanli Ouyang. Humanbench: Towards general human-centric perception with projector as- sisted pretraining, 2023. 3
work page 2023
-
[48]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a 10 family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023. 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
CogVLM: Visual Expert for Pretrained Language Models
Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al. Cogvlm: Visual expert for pretrained language models. arXiv preprint arXiv:2311.03079, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Visionllm: Large language model is also an open- ended decoder for vision-centric tasks
Wenhai Wang, Zhe Chen, Xiaokang Chen, Jiannan Wu, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, et al. Visionllm: Large language model is also an open- ended decoder for vision-centric tasks. Advances in Neural Information Processing Systems, 36, 2024. 2
work page 2024
-
[52]
Funqa: Towards surprising video comprehension
Binzhu Xie, Sicheng Zhang, Zitang Zhou, Bo Li, Yuanhan Zhang, Jack Hessel, Jingkang Yang, and Ziwei Liu. Funqa: Towards surprising video comprehension. InEuropean Con- ference on Computer Vision , pages 39–57. Springer, 2025. 2
work page 2025
-
[53]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296, 2016. 3
work page 2016
-
[54]
PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, and Jiashi Feng. Pllava: Parameter-free llava extension from images to videos for video dense captioning. arXiv preprint arXiv:2404.16994, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jian- wei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, M...
work page 2024
-
[56]
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Activitynet-qa: A dataset for understanding complex web videos via question answering
Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yuet- ing Zhuang, and Dacheng Tao. Activitynet-qa: A dataset for understanding complex web videos via question answering. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 9127–9134, 2019. 3
work page 2019
-
[58]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multi- modal foundation models for image and video understand- ing. arXiv preprint arXiv:2501.13106, 2025. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Video-llama: An instruction-tuned audio-visual language model for video un- derstanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding. In Proceedings of the 2023 Conference on Em- pirical Methods in Natural Language Processing: System Demonstrations, pages 543–553, 2023. 3, 7, 8
work page 2023
-
[60]
S3fd: Single shot scale-invariant face detector
Shifeng Zhang, Xiangyu Zhu, Zhen Lei, Hailin Shi, Xiaobo Wang, and Stan Z Li. S3fd: Single shot scale-invariant face detector. In Proceedings of the IEEE international confer- ence on computer vision, pages 192–201, 2017. 5
work page 2017
-
[61]
Beyond llava-hd: Diving into high-resolution large multimodal models, 2024
Yi-Fan Zhang, Qingsong Wen, Chaoyou Fu, Xue Wang, Zhang Zhang, Liang Wang, and Rong Jin. Beyond llava-hd: Diving into high-resolution large multimodal models, 2024. 8
work page 2024
-
[62]
Chatbridge: Bridging modalities with large language model as a language catalyst
Zijia Zhao, Longteng Guo, Tongtian Yue, Sihan Chen, Shuai Shao, Xinxin Zhu, Zehuan Yuan, and Jing Liu. Chatbridge: Bridging modalities with large language model as a language catalyst. arXiv preprint arXiv:2305.16103, 2023. 3, 7
-
[63]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023. 2 11 HUMAN VBENCH : Exploring Human-Centric Video Understanding Capabilities of MLLMs with Synthetic Benchmark Data Supplementary Material
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
Overview In the appendix, we first We provide more benchmark statis- tics in Section 7, then the modality ablation experiments in VideoLLaMA2 in Section 8, followed by additional evalu- ation details in Section 9, followed by the detailed defini- tion and examples for the 16 tasks of H UMAN VBENCH in Section 10. Then, we present implementation specifics o...
-
[65]
More Statistics of HUMAN VBENCH HUMAN VBENCH focuses on short video understanding, specifically videos with a duration of 10 seconds or less. It includes a total of 2116 question instances, with the spe- cific number for each task indicated in 1. The total video duration amounts to 4.7 hours and demonstrates a variety of people, scenes, and video shooting...
-
[66]
Modality Ablation in VideoLLaMA2 Despite audio-visual MLLMs processing audio data, they perform at random-guess levels on A VSM and ASD tasks, underperforming relative to many vision-only models that rely solely on lip movement analysis. This raises the ques- tion: does the poor performance stem from limitations in visual analysis (e.g., lacking lip-readi...
-
[67]
Model Evaluation Implementation Prompt. In order to facilitate the statistical model to answer the results, following common practices used in MLLM evaluations [18, 24], we adopt the following prompt to guide the MLLM to output option letters: “ Select the best answer to the following multiple-choice question based on the video. Respond with only the lett...
-
[68]
Definitions and Examples for Each Task 10.1. Emotion Perception Emotion Recognition aims to judge the overall emotional state of the person highlighted by a red bounding box in the video. An example is shown in Figure 7. 1 Models Input Modal Human Emotion Perception Person Recognition Human Behavior Analysis Speech-Visual Alignment ER ETA AR EIC Avg T2H H...
-
[69]
Annotations Details and Examples in Human-Centric Annotation Pipeline For the in-the-wild videos collected from Pexels, we first apply splitting and filtering operations. Specifically, we begin by utilizing the video resolution filter, video aesthetics filter, and video nsfw filter operators to select videos that meet the following criteria: a resolution ...
-
[70]
A face bounding box is added to a human track if its overlap rate exceeds 50%
as the face detector. A face bounding box is added to a human track if its overlap rate exceeds 50%. After ob- taining the face track, we identify the corresponding body bounding box for each face bounding box in the same frame to generate a second bounding box track for the individual, referred to as the body track. The matching criterion se- lects the c...
-
[71]
for appearance description and simple actions. In the video facial description mapper, we use the face bounding box track to crop the video, creating face- focused reconstructed videos for emotion description using VideoLLaMA2.1 [16]. The choice of VideoLLaMA2.1 is based on a comparative analysis of multiple models, which revealed that VideoLLaMA2.1 is of...
-
[72]
LLM for Generating Distractors
Complete Construction Details of All Tasks We will first explain the details of six descriptive ques- tions generated using the Distractor-Included QA Genera- tion Pipeline, followed by the construction details of the re- maining tasks. 12.1. Construction Details of 6 Descriptive Human- Centric Questions For these six tasks, the video-MLLM used to obtain ...
-
[73]
are added to help to guide the model’s attention to the individual. The prompt for obtaining the task-oriented cap- tion is designed as follows: Please focus on the person highlighted by the red bound- ing box ( 〈Human Appearance〉) and tell me if the actions of the person changed over time and what actions does the person take in order? Respond according ...
-
[74]
Based on the marked video, appearance cues of the target individual (i.e., Label-4) are added to help the model focus on the person. The prompt for obtaining the task-oriented caption is designed as follows: Please accurately describe the person highlighted by a red box(〈appearance〉), your answer can be based on appear- ance, location, and actions, so tha...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.