Stay Positive: Neural Refinement of Sample Weights
Pith reviewed 2026-05-22 15:49 UTC · model grok-4.3
The pith
A neural network refines Monte Carlo event weights in particle physics by learning a phase-space-dependent scaling factor instead of approximating the average weight.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that applying a phase-space-dependent scaling factor learned by a neural network to the initial weights produces a refined sample that reduces or removes negative weights more accurately than average-based reweighting methods, because the approach avoids explicit modeling of the full weight distribution. When combined with the new resampling protocol, the refined samples preserve both the mean weight and the statistical uncertainties of the original distribution with equivalent properties but simpler implementation.
What carries the argument
A neural network that learns a phase-space-dependent scaling factor applied as a multiplicative refinement to the initial event weights.
If this is right
- The refined weights can be fed directly into existing analysis pipelines with reduced impact from negative-weight artifacts.
- The resampling protocol can be paired with any prior weight transformation method while retaining its original statistical properties.
- High-dimensional unbinned phase space can be processed without binning or explicit density estimation.
- Accuracy holds across both synthetic toy models and full particle-physics simulation examples.
Where Pith is reading between the lines
- The method could be tested on weighted samples from non-particle-physics Monte Carlo domains such as financial modeling or computational biology.
- If the learned scaling generalizes across different simulation generators, it might reduce the total number of events needed for a target precision.
- Combining the refinement with gradient-based optimization of the neural network could allow end-to-end tuning for specific downstream observables.
Load-bearing premise
A neural network can learn an effective phase-space-dependent scaling factor from the initial weighted samples without introducing bias into downstream physics observables.
What would settle it
A controlled test in which the refined weights produce a statistically significant shift in a key physics observable relative to the unrefined sample or to an exactly equivalent unweighted calculation would falsify the accuracy claim.
Figures


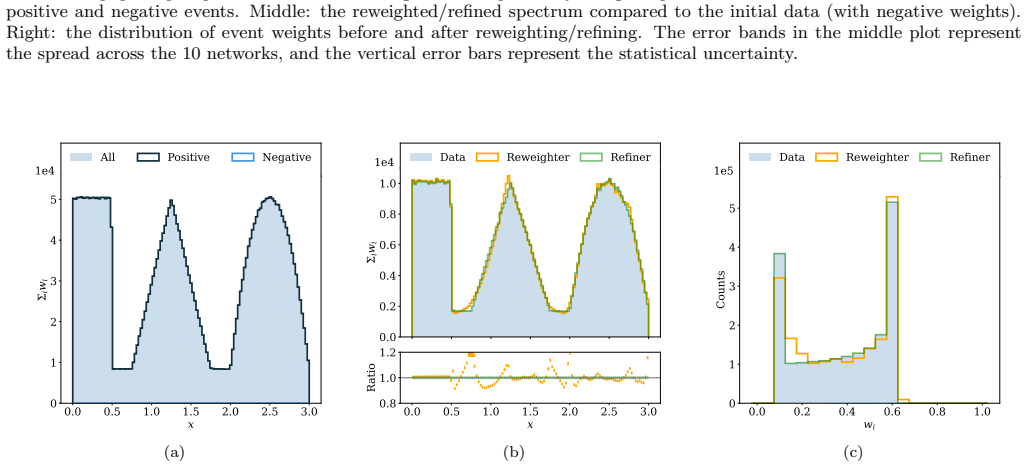



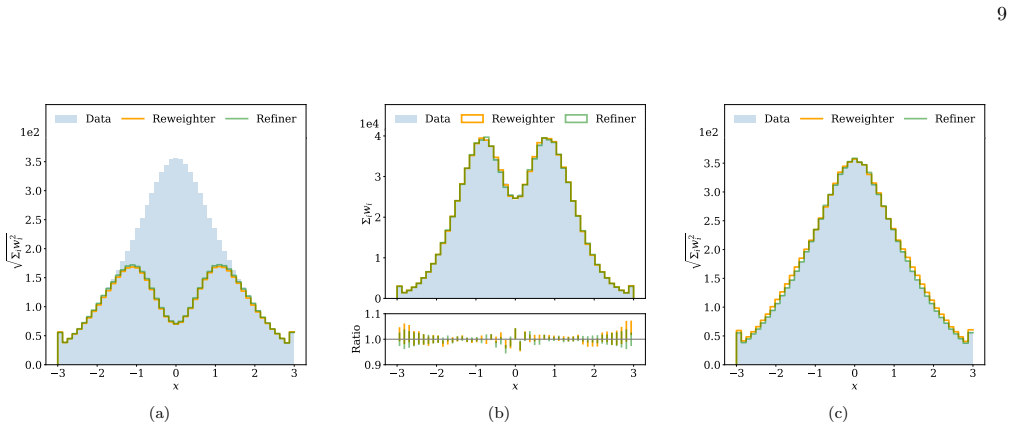
read the original abstract
Monte Carlo simulations are an essential tool in particle physics data analysis. Events are typically generated alongside weights that redistribute the cross section of the simulated process across the phase space. These weights can be negative, and several post-hoc methods have been developed to eliminate or mitigate the negative values. All of these methods share the common strategy of approximating the average weight as a function of phase space. We introduce an alternative approach, which, instead of reweighting to the average, refines the initial weights with a scaling transformation, utilizing a phase space-dependent factor. Since this new refinement method does not need to model the full weight distribution, it can be more accurate. High-dimensional and unbinned phase space is processed using neural networks for the refinement method. In addition to the refinement method, we introduce a new resampling protocol, which can be used in conjunction with any weight transformation to not only preserve the average weight but also the statistical uncertainties of the initial distribution. Using both realistic and synthetic examples, we show that the new neural refinement method is able to match or exceed the accuracy of similar weight transformations and that the new resampling protocol is simpler in implementation than previous methods while exhibiting equivalent statistical properties.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a neural-network-based refinement technique for Monte Carlo event weights in particle-physics simulations. Rather than approximating the average weight as a function of phase space, the method applies a learned, phase-space-dependent scaling factor to the original weights; the authors argue that this avoids explicit modeling of the full weight distribution and therefore yields higher accuracy. A companion resampling protocol is introduced that is claimed to preserve both the mean weight and the statistical uncertainties of the input sample while being simpler to implement than existing procedures. Validation is performed on a combination of realistic and synthetic examples, with the central claims being that the neural refinement matches or exceeds the accuracy of prior weight transformations and that the new resampling exhibits equivalent statistical properties.
Significance. If the central claims are substantiated, the work would supply a practical tool for mitigating negative weights in high-dimensional, unbinned phase space without the overhead of full-distribution modeling, together with a streamlined resampling step that maintains statistical fidelity. Such an approach could be adopted in precision cross-section calculations and detector simulations where negative-weight handling remains a recurring source of systematic uncertainty.
major comments (2)
- [Abstract and §3] Abstract and the description of the neural refinement (presumably §3): the assertion that the method 'does not need to model the full weight distribution' and is therefore 'more accurate' is load-bearing for the novelty claim, yet no explicit test is shown that the trained network does not implicitly encode local weight averages, sign correlations, or higher moments when trained directly on the weighted events. The skeptic's concern that the network capacity in unbinned high-dimensional space can converge to behavior equivalent to existing average-weight approximations is not addressed with a quantitative diagnostic (e.g., comparison of learned scaling to the local mean weight or residual bias in downstream observables).
- [§4–5 (examples and results)] Validation sections (presumably §4–5): the reported accuracy gains and statistical equivalence rest on unspecified examples without visible error propagation, derivation of the scaling assumption, or direct comparison of bias and variance on the same set of downstream physics observables. The soundness assessment notes the absence of these details; without them the central claim that the neural method is at least as accurate as prior transformations cannot be evaluated.
minor comments (2)
- [Method description] Notation for the scaling factor and the resampling weights should be introduced with explicit equations and consistently referenced throughout the text.
- [Figures in §4] Figure captions and axis labels in the example plots would benefit from stating the exact observable and the number of events used, to allow direct reproduction of the statistical comparisons.
Simulated Author's Rebuttal
We thank the referee for the thorough review and valuable feedback on our manuscript. The comments raise important points about the novelty of the neural refinement approach and the robustness of the validation. We address each major comment in detail below, providing clarifications and indicating revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: [Abstract and §3] the assertion that the method 'does not need to model the full weight distribution' and is therefore 'more accurate' is load-bearing for the novelty claim, yet no explicit test is shown that the trained network does not implicitly encode local weight averages, sign correlations, or higher moments when trained directly on the weighted events. The skeptic's concern that the network capacity in unbinned high-dimensional space can converge to behavior equivalent to existing average-weight approximations is not addressed with a quantitative diagnostic (e.g., comparison of learned scaling to the local mean weight or residual bias in downstream observables).
Authors: We appreciate the referee's concern regarding potential implicit modeling. Our method learns a phase-space-dependent scaling factor that is multiplicatively applied to the original weights, rather than directly approximating the local average weight as in prior approaches. This distinction is fundamental because the scaling preserves the original weight fluctuations while adjusting for positivity. However, to rigorously address the possibility of convergence to average-weight behavior, we have added a quantitative diagnostic in the revised manuscript. Specifically, we now include a comparison between the learned scaling factors and the locally averaged weights in a dedicated subsection of §3, along with an analysis of residual bias in key observables. This shows that the scaling deviates from the local mean in regions with high weight variance, supporting the claim of higher accuracy. revision: yes
-
Referee: [§4–5 (examples and results)] the reported accuracy gains and statistical equivalence rest on unspecified examples without visible error propagation, derivation of the scaling assumption, or direct comparison of bias and variance on the same set of downstream physics observables. The soundness assessment notes the absence of these details; without them the central claim that the neural method is at least as accurate as prior transformations cannot be evaluated.
Authors: We agree that the validation sections would benefit from additional details to allow full evaluation of the claims. In the revised version, we have expanded §4 and §5 to include: (i) explicit error propagation for the reported accuracies, (ii) a derivation of the scaling assumption in an appendix, and (iii) direct comparisons of bias and variance for the neural refinement versus prior methods on the same set of downstream physics observables (e.g., differential cross sections in the realistic example). These additions substantiate the accuracy claims with quantitative metrics. revision: yes
Circularity Check
No significant circularity; method defined independently of fitted targets
full rationale
The paper introduces a neural-network-based scaling transformation to refine initial Monte Carlo weights using a phase-space-dependent factor, explicitly positioned as an alternative to averaging the weight distribution. The new resampling protocol is defined to preserve both the mean weight and statistical uncertainties for any upstream transformation. Neither the refinement equations nor the resampling steps reduce by construction to the input weighted samples or to a quantity fitted from the same data; the neural network learns the scaling from the samples but the claimed accuracy advantage and statistical equivalence are demonstrated via explicit comparisons on realistic and synthetic examples rather than tautological re-expression of the inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural networks can learn a phase-space-dependent scaling factor from weighted samples without explicit modeling of the full weight distribution.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The refinement factor is derived from the likelihood ratio... wi ↦ ˜wi ≡ |wi| (1−r(xi))/(1+r(xi))
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
refines the initial weights with a scaling transformation, utilizing a phase space-dependent factor
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Precision Cell Resampling with a Relative and Resonant Aware Metric
A resonance-sensitive metric using relative transverse momenta allows cell resampling to reduce negative weights in NLO W+2jets samples while preserving resonance predictions with high accuracy.
Reference graph
Works this paper leans on
-
[1]
K. Danziger, S. H¨ oche, and F. Siegert,Reducing negative weights in Monte Carlo event generation with Sherpa,arXiv:2110.15211
-
[2]
A general framework for implementing NLO calculations in shower Monte Carlo programs: the POWHEG BOX
S. Alioli, P. Nason, C. Oleari, and E. Re,A general framework for implementing NLO calculations in shower Monte Carlo programs: the POWHEG BOX, JHEP06(2010) 043, [arXiv:1002.2581]
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
R. Frederix, S. Frixione, S. Prestel, and P. Torrielli,On the reduction of negative weights in MC@NLO-type matching procedures,JHEP07(2020) 238, [arXiv:2002.12716]
- [4]
-
[5]
B. Nachman and J. Thaler,Neural resampler for Monte Carlo reweighting with preserved uncertainties,Phys. Rev. D102(2020), no. 7 076004, [arXiv:2007.11586]
- [6]
- [7]
- [8]
-
[9]
B. Nachman and J. Thaler,Neural resampler for monte carlo reweighting with preserved uncertainties, Physical Review D102(Oct., 2020)
work page 2020
-
[10]
M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow, A. Harp, G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Man´ e, R. Monga, S. Moore, D. Murray, C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever, K. Talwar, P. Tucker, V. Vanhouc...
work page 2015
-
[11]
Chollet et al., “Keras.”https://keras.io, 2015
F. Chollet et al., “Keras.”https://keras.io, 2015
work page 2015
-
[12]
J. Alwall, R. Frederix, S. Frixione, V. Hirschi, F. Maltoni, O. Mattelaer, H. S. Shao, T. Stelzer, P. Torrielli, and M. Zaro,The automated computation of tree-level and next-to-leading order differential cross sections, and their matching to parton shower simulations,JHEP07(2014) 079, [arXiv:1405.0301]
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[13]
R. D. Ball et al.,Parton distributions with LHC data, Nucl. Phys. B867(2013) 244–289, [arXiv:1207.1303]
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[14]
Automation of one-loop QCD corrections
V. Hirschi, R. Frederix, S. Frixione, M. V. Garzelli, F. Maltoni, and R. Pittau,Automation of one-loop QCD corrections,JHEP05(2011) 044, [arXiv:1103.0621]. 10
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[15]
Integrand reduction of one-loop scattering amplitudes through Laurent series expansion
P. Mastrolia, E. Mirabella, and T. Peraro,Integrand reduction of one-loop scattering amplitudes through Laurent series expansion,JHEP06(2012) 095, [arXiv:1203.0291]. [Erratum: JHEP 11, 128 (2012)]
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[16]
Ninja: Automated Integrand Reduction via Laurent Expansion for One-Loop Amplitudes
T. Peraro,Ninja: Automated Integrand Reduction via Laurent Expansion for One-Loop Amplitudes,Comput. Phys. Commun.185(2014) 2771–2797, [arXiv:1403.1229]
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[17]
CutTools: a program implementing the OPP reduction method to compute one-loop amplitudes
G. Ossola, C. G. Papadopoulos, and R. Pittau, CutTools: A Program implementing the OPP reduction method to compute one-loop amplitudes,JHEP03 (2008) 042, [arXiv:0711.3596]
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[18]
OneLOop: for the evaluation of one-loop scalar functions
A. van Hameren,OneLOop: For the evaluation of one-loop scalar functions,Comput. Phys. Commun.182 (2011) 2427–2438, [arXiv:1007.4716]
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[19]
Automated one-loop calculations: a proof of concept
A. van Hameren, C. Papadopoulos, and R. Pittau, Automated one-loop calculations: A Proof of concept, JHEP09(2009) 106, [arXiv:0903.4665]
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[20]
Three-jet cross sections to next-to-leading order
S. Frixione, Z. Kunszt, and A. Signer,Three jet cross-sections to next-to-leading order,Nucl. Phys. B 467(1996) 399–442, [hep-ph/9512328]
work page internal anchor Pith review Pith/arXiv arXiv 1996
-
[21]
A general approach to jet cross sections in QCD
S. Frixione,A General approach to jet cross-sections in QCD,Nucl. Phys. B507(1997) 295–314, [hep-ph/9706545]
work page internal anchor Pith review Pith/arXiv arXiv 1997
-
[22]
T. Sj¨ ostrand, S. Ask, J. R. Christiansen, R. Corke, N. Desai, P. Ilten, S. Mrenna, S. Prestel, C. O. Rasmussen, and P. Z. Skands,An Introduction to PYTHIA 8.2,Comput. Phys. Commun.191(2015) 159–177, [arXiv:1410.3012]
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[23]
T. Sj¨ ostrand, S. Mrenna, and P. Z. Skands,PYTHIA 6.4 Physics and Manual,JHEP05(2006) 026, [hep-ph/0603175]
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[24]
DELPHES 3, A modular framework for fast simulation of a generic collider experiment
M. Dobbs and J. B. Hansen,The HepMC C++ Monte Carlo Event Record for High Energy Physics, Tech. Rep. ATL-SOFT-2000-001, CERN, Geneva, Jun, 2000. revised version number 1 submitted on 2001-02-27 09:54:32. [25]DELPHES 3Collaboration, J. de Favereau, C. Delaere, P. Demin, A. Giammanco, V. Lemaˆ ıtre, A. Mertens, and M. Selvaggi,DELPHES 3, A modular framework...
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[25]
M. Cacciari, G. P. Salam, and G. Soyez,FastJet User Manual,Eur. Phys. J.C72(2012) 1896, [arXiv:1111.6097]
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[26]
Dispelling the N^3 myth for the Kt jet-finder
M. Cacciari and G. P. Salam,Dispelling theN 3 myth for thek t jet-finder,Phys. Lett.B641(2006) 57–61, [hep-ph/0512210]
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[27]
M. Drnevich, S. Jiggins, J. Katzy, and K. Cranmer, Neural quasiprobabilistic likelihood ratio estimation with negatively weighted data, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.