Superposition Yields Robust Neural Scaling
Pith reviewed 2026-05-22 14:33 UTC · model grok-4.3
The pith
Strong superposition in neural networks makes loss scale inversely with model dimension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
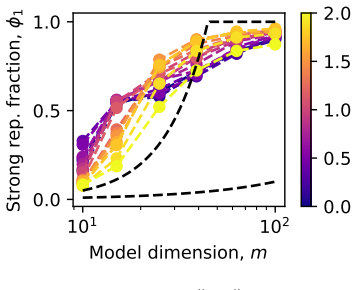
The central discovery is that under strong superposition the loss generically scales inversely with model dimension across a broad class of frequency distributions due to geometric overlaps between representation vectors. This holds in contrast to the weak superposition case which requires specific distributions.
What carries the argument
geometric overlaps between representation vectors in the strong superposition regime
If this is right
- Loss scales inversely with model dimension under strong superposition for many frequency distributions.
- Power-law loss scaling requires power-law feature frequencies only when superposition is weak.
- Large language models operate in the strong superposition regime with corresponding scaling behavior.
- The robustness of scaling laws comes from this geometric mechanism.
Where Pith is reading between the lines
- If superposition strength changes with model size, scaling laws could deviate from current observations.
- Similar superposition effects might explain scaling in other machine learning tasks beyond language modeling.
- Designing models to maintain strong superposition could extend the benefits of scaling.
Load-bearing premise
A simplified neural model controlled for superposition degree accurately reproduces the loss scaling dynamics of real large language models.
What would settle it
Observing that loss does not scale inversely with dimension in a large language model confirmed to operate under strong superposition would challenge the claim.
Figures





















read the original abstract
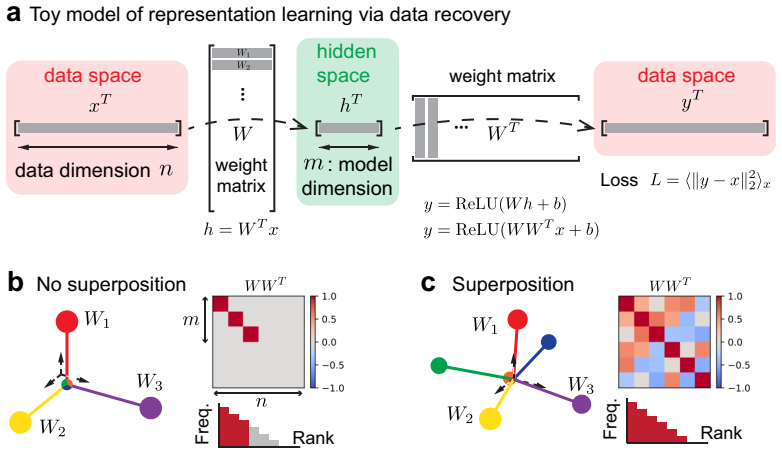
The success of today's large language models (LLMs) depends on the observation that larger models perform better. However, the origin of this neural scaling law, that loss decreases as a power law with model size, remains unclear. We propose that representation superposition, meaning that LLMs represent more features than they have dimensions, can be a key contributor to loss and cause neural scaling. Based on Anthropic's toy model, we use weight decay to control the degree of superposition, allowing us to systematically study how loss scales with model size. When superposition is weak, the loss follows a power law only if data feature frequencies are power-law distributed. In contrast, under strong superposition, the loss generically scales inversely with model dimension across a broad class of frequency distributions, due to geometric overlaps between representation vectors. We confirmed that open-sourced LLMs operate in the strong superposition regime and have loss scaling inversely with model dimension, and that the Chinchilla scaling laws are also consistent with this behavior. Our results identify representation superposition as a central driver of neural scaling laws, providing insights into questions like when neural scaling laws can be improved and when they will break down.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that representation superposition in LLMs is a central driver of neural scaling laws. Using Anthropic's toy model with weight decay to control the degree of superposition, the authors show that weak superposition yields power-law scaling only for power-law feature frequencies, while strong superposition produces generic inverse (1/d) loss scaling with model dimension across broad frequency distributions due to geometric overlaps between representation vectors. They report consistency checks showing open-source LLMs operate in the strong regime with 1/d scaling and that Chinchilla laws align with this behavior.
Significance. If the result holds, the work supplies a mechanistic account of why loss improves with scale, separating regimes by superposition strength and identifying geometric vector overlaps as the source of robust 1/d scaling. The use of weight decay as a controllable knob and the reported consistency with real models and Chinchilla laws are concrete strengths that would make the explanation falsifiable and useful for predicting when scaling improves or saturates.
major comments (2)
- Abstract and main text: the claim that open-sourced LLMs are in the strong superposition regime and exhibit loss scaling inversely with model dimension is presented without the measurement protocol, exact frequency distributions tested, or quantitative error analysis. This verification step is load-bearing for the extrapolation from the toy model to real LLMs.
- The derivation of generic 1/d scaling under strong superposition is obtained inside the Anthropic toy model via geometric overlaps; it is unclear whether the inverse scaling survives when the model is extended to include layered attention or data-driven feature emergence, which could alter overlap statistics or introduce additional loss terms.
minor comments (2)
- Define the quantitative threshold separating weak from strong superposition and show how weight-decay strength maps onto it.
- Specify the precise class of frequency distributions for which the 1/d result is proven and note any counter-examples.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract and main text: the claim that open-sourced LLMs are in the strong superposition regime and exhibit loss scaling inversely with model dimension is presented without the measurement protocol, exact frequency distributions tested, or quantitative error analysis. This verification step is load-bearing for the extrapolation from the toy model to real LLMs.
Authors: We agree that the verification details are essential for supporting the extrapolation. In the revised manuscript we will add an expanded methods subsection that fully specifies the measurement protocol used to classify open-source LLMs as operating in the strong-superposition regime, lists the exact frequency distributions against which scaling was checked, and reports quantitative error analysis including bootstrap confidence intervals on the fitted scaling exponents. These additions will make the empirical consistency checks transparent and reproducible. revision: yes
-
Referee: The derivation of generic 1/d scaling under strong superposition is obtained inside the Anthropic toy model via geometric overlaps; it is unclear whether the inverse scaling survives when the model is extended to include layered attention or data-driven feature emergence, which could alter overlap statistics or introduce additional loss terms.
Authors: The 1/d scaling arises from the geometry of vector overlaps once the number of represented features exceeds the ambient dimension; this mechanism is independent of the specific architecture that produces the representations. We will insert a new discussion paragraph that explains why additional loss terms from attention or emergent features are not expected to eliminate the leading 1/d term in the strong-superposition limit, while acknowledging that a full end-to-end simulation of layered transformers lies beyond the present scope. We therefore treat the toy-model derivation as a mechanistic foundation rather than a complete proof for every architecture. revision: partial
Circularity Check
No significant circularity: inverse scaling derived mathematically from toy-model geometry
full rationale
The central derivation proceeds from the Anthropic toy model equations under strong superposition, where loss scaling as 1/d emerges directly from geometric overlaps between representation vectors across a broad class of frequency distributions. Weight decay serves only as a regime selector, not as a fitted parameter that sets the scaling exponent. No step reduces by construction to a self-definition, a renamed fit, or a load-bearing self-citation; the result is obtained by explicit calculation inside the model rather than by re-expressing its inputs. Empirical checks on open LLMs are presented as external corroboration, not as the source of the scaling form.
Axiom & Free-Parameter Ledger
free parameters (1)
- weight decay strength
axioms (1)
- domain assumption The Anthropic toy model with weight decay reproduces essential superposition and loss behavior of real LLMs.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
under strong superposition, the loss generically scales inversely with model dimension ... due to geometric overlaps between representation vectors
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
vectors Wi tend to be isotropic ... squared overlaps scaling like 1/m
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 8 Pith papers
-
GIANTS: Generative Insight Anticipation from Scientific Literature
GIANTS-4B, trained with RL on a new 17k-example benchmark of parent-to-child paper insights, achieves 34% relative improvement over gemini-3-pro in LM-judge similarity and is rated higher-impact by a citation predictor.
-
Linear-Readout Floors and Threshold Recovery in Computation in Superposition
Linear readouts incur an Omega(d^{-1/2}) crosstalk floor that caps the Hanni template at d^{3/2} capacity, while threshold recovery succeeds at quadratic loads for s = O(d/log d) sparsity, resolving the apparent contr...
-
Are LLM Uncertainty and Correctness Encoded by the Same Features? A Functional Dissociation via Sparse Autoencoders
Uncertainty and correctness in LLMs are encoded by distinct feature populations, with suppression of confounded features improving accuracy and reducing entropy.
-
Predictable Confabulations: Factual Recall by LLMs Scales with Model Size and Topic Frequency
Factual recall quality in LLMs follows a sigmoid scaling law in the log-linear combination of model parameter count and topic frequency in training data, explaining 60% of variance across models and up to 94% within families.
-
Hypothesis generation and updating in large language models
LLMs exhibit Bayesian-like hypothesis updating with strong-sampling bias and an evaluation-generation gap but generalize poorly outside observed data.
-
Spectral Lens: Activation and Gradient Spectra as Diagnostics of LLM Optimization
Spectral analysis of activations and gradients provides new diagnostics that link batch size to representation geometry, early covariance tails to token efficiency, and spectral shifts to learning dynamics in decoder-...
-
Asymmetric Scaling Laws from Sparse Features
A sparse-activation model predicts double-descent loss with distinct under- and over-parameterized scaling exponents set by sparsity, plus a compute-optimal frontier favoring dataset growth.
-
Unveiling Memorization-Generalization Coexistence: A Case Study on Arithmetic Tasks with Label Noise
Experiments on modular arithmetic with heavy label noise show that over-parameterized networks form a distributed internal generalization structure that can be extracted via frequency methods to achieve high accuracy ...
Reference graph
Works this paper leans on
-
[1]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[2]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[3]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Scaling Laws for Autoregressive Generative Modeling
Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Heewoo Jun, Tom B Brown, Prafulla Dhariwal, Scott Gray, et al. Scaling laws for autoregressive generative modeling.arXiv preprint arXiv:2010.14701, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[5]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
How good is google bard’s visual understanding? an empirical study on open challenges
Haotong Qin, Ge-Peng Ji, Salman Khan, Deng-Ping Fan, Fahad Shahbaz Khan, and Luc Van Gool. How good is google bard’s visual understanding? an empirical study on open challenges. arXiv preprint arXiv:2307.15016, 2023. https://arxiv.org/abs/2307.15016
-
[7]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quan- titative reasoning problems with language models.Advances in neural information processing systems, 35:3843–3857, 2022
work page 2022
-
[8]
Galactica: A Large Language Model for Science
Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. Galactica: A large language model for science.arXiv preprint arXiv:2211.09085, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Wolfram|alpha as the computation engine for gpt models, 2023
Stephen Wolfram. Wolfram|alpha as the computation engine for gpt models, 2023. https://www.wolfram.com/wolfram-alpha-openai-plugin
work page 2023
-
[10]
Solving olympiad geometry without human demonstrations.Nature, 625(7995):476–482, 2024
Trieu H Trinh, Yuhuai Wu, Quoc V Le, He He, and Thang Luong. Solving olympiad geometry without human demonstrations.Nature, 625(7995):476–482, 2024
work page 2024
-
[11]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Github copilot: Your ai pair programmer, 2022
GitHub. Github copilot: Your ai pair programmer, 2022. https://github.com/features/copilot
work page 2022
-
[13]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher.arXiv preprint arXiv:2112.11446, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Scaling laws from the data manifold dimension.Journal of Machine Learning Research, 23(9):1–34, 2022
Utkarsh Sharma and Jared Kaplan. Scaling laws from the data manifold dimension.Journal of Machine Learning Research, 23(9):1–34, 2022. 11
work page 2022
-
[15]
Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, and Utkarsh Sharma. Explaining neural scaling laws.Proceedings of the National Academy of Sciences, 121(27):e2311878121, 2024
work page 2024
-
[16]
Spectrum dependent learning curves in kernel regression and wide neural networks
Blake Bordelon, Abdulkadir Canatar, and Cengiz Pehlevan. Spectrum dependent learning curves in kernel regression and wide neural networks. InInternational Conference on Machine Learning, pages 1024–1034. PMLR, 2020
work page 2020
-
[17]
Blake Bordelon, Alexander Atanasov, and Cengiz Pehlevan. How feature learning can improve neural scaling laws.Journal of Statistical Mechanics: Theory and Experiment, 2025(8):084002, 2025
work page 2025
-
[18]
arXiv preprint arXiv:2210.16859 , year=
Alexander Maloney, Daniel A Roberts, and James Sully. A solvable model of neural scaling laws.arXiv preprint arXiv:2210.16859, 2022
-
[19]
Learning curve theory.arXiv preprint arXiv:2102.04074, 2021
Marcus Hutter. Learning curve theory.arXiv preprint arXiv:2102.04074, 2021
-
[20]
Eric Michaud, Ziming Liu, Uzay Girit, and Max Tegmark. The quantization model of neural scaling.Advances in Neural Information Processing Systems, 36:28699–28722, 2023
work page 2023
-
[21]
Ziming Liu, Yizhou Liu, Eric J Michaud, Jeff Gore, and Max Tegmark. Physics of skill learning. arXiv preprint arXiv:2501.12391, 2025
-
[22]
Scaling Laws and Interpretability of Learning from Repeated Data
Danny Hernandez, Tom Brown, Tom Conerly, Nova DasSarma, Dawn Drain, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Tom Henighan, Tristan Hume, et al. Scaling laws and interpretability of learning from repeated data.arXiv preprint arXiv:2205.10487, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Neural scaling laws rooted in the data distribution.arXiv preprint arXiv:2412.07942, 2024
Ari Brill. Neural scaling laws rooted in the data distribution.arXiv preprint arXiv:2412.07942, 2024
-
[24]
Stefano Spigler, Mario Geiger, and Matthieu Wyart. Asymptotic learning curves of kernel methods: empirical data versus teacher–student paradigm.Journal of Statistical Mechanics: Theory and Experiment, 2020(12):124001, 2020
work page 2020
-
[25]
A resource model for neural scaling law
Jinyeop Song, Ziming Liu, Max Tegmark, and Jeff Gore. A resource model for neural scaling law.arXiv preprint arXiv:2402.05164, 2024
-
[26]
Sanjeev Arora, Yuanzhi Li, Yingyu Liang, Tengyu Ma, and Andrej Risteski. Linear algebraic structure of word senses, with applications to polysemy.Transactions of the Association for Computational Linguistics, 6:483–495, 2018
work page 2018
-
[27]
Toy models of superposition.Transformer Circuits Thread, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition.Transformer Circuits Thread, 2022
work page 2022
-
[28]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Lloyd Welch. Lower bounds on the maximum cross correlation of signals (corresp.).IEEE Transactions on Information Theory, 20(3):397–399, 2003
work page 2003
-
[30]
Springer Science & Business Media, 2012
Peter G Casazza and Gitta Kutyniok.Finite frames: Theory and applications. Springer Science & Business Media, 2012
work page 2012
-
[31]
Thomas Strohmer and Robert W Heath Jr. Grassmannian frames with applications to coding and communication.Applied and computational harmonic analysis, 14(3):257–275, 2003
work page 2003
-
[32]
Steiner equiangular tight frames
Matthew Fickus, Dustin G Mixon, and Janet C Tremain. Steiner equiangular tight frames. Linear algebra and its applications, 436(5):1014–1027, 2012
work page 2012
-
[33]
Joseph M Renes, Robin Blume-Kohout, A J Scott, and Carlton M Caves. Symmetric informa- tionally complete quantum measurements.Journal of Mathematical Physics, 45(6):2171–2180, 2004. 12
work page 2004
-
[34]
Yizhou Liu and John B. DeBrota. Relating measurement disturbance, information, and orthogo- nality.Phys. Rev. A, 104:052216, Nov 2021
work page 2021
-
[35]
Quantifying unsharpness of measurements via uncertainty.Phys
Yizhou Liu and Shunlong Luo. Quantifying unsharpness of measurements via uncertainty.Phys. Rev. A, 104:052227, Nov 2021
work page 2021
-
[36]
Yizhou Liu, Shunlong Luo, and Yuan Sun. Total, classical and quantum uncertainties generated by channels.Theoretical and Mathematical Physics, 213(2):1613–1631, 2022
work page 2022
-
[37]
Vardan Papyan, XY Han, and David L Donoho. Prevalence of neural collapse during the terminal phase of deep learning training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020
work page 2020
-
[38]
arXiv preprint arXiv:2206.04041 , year=
Vignesh Kothapalli. Neural collapse: A review on modelling principles and generalization. arXiv preprint arXiv:2206.04041, 2022
-
[39]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
work page 2019
-
[41]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
-
[42]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR, 2023
work page 2023
-
[43]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[44]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[45]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
work page 2020
-
[46]
Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. InProceedings of the IEEE international conference on computer vision, pages 19–27, 2015
work page 2015
-
[47]
Tamay Besiroglu, Ege Erdil, Matthew Barnett, and Josh You. Chinchilla scaling: A replication attempt.arXiv preprint arXiv:2404.10102, 2024
-
[48]
Deep Learning Scaling is Predictable, Empirically
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically.arXiv preprint arXiv:1712.00409, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
Compressed sensing.IEEE Transactions on Information Theory, 52(4):1289– 1306, 2006
David L Donoho. Compressed sensing.IEEE Transactions on Information Theory, 52(4):1289– 1306, 2006
work page 2006
-
[50]
Emmanuel J Candès, Justin Romberg, and Terence Tao. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information.IEEE Transactions on Information Theory, 52(2):489–509, 2006. 13
work page 2006
-
[51]
Compressive sensing.IEEE Signal Processing Magazine, 24(4):118–121, 2007
Richard G Baraniuk. Compressive sensing.IEEE Signal Processing Magazine, 24(4):118–121, 2007
work page 2007
-
[52]
Surya Ganguli and Haim Sompolinsky. Compressed sensing, sparsity, and dimensionality in neuronal information processing and data analysis.Annual review of neuroscience, 35(1):485– 508, 2012
work page 2012
-
[53]
Madhu S Advani and Surya Ganguli. Statistical mechanics of optimal convex inference in high dimensions.Physical Review X, 6(3):031034, 2016
work page 2016
-
[54]
Bruno A Olshausen and David J Field. Emergence of simple-cell receptive field properties by learning a sparse code for natural images.Nature, 381(6583):607–609, 1996
work page 1996
-
[55]
Sparseness and expansion in sensory representations
Behtash Babadi and Haim Sompolinsky. Sparseness and expansion in sensory representations. Neuron, 83(5):1213–1226, 2014
work page 2014
-
[56]
arXiv preprint arXiv:2408.05451 , year=
Kaarel Hänni, Jake Mendel, Dmitry Vaintrob, and Lawrence Chan. Mathematical models of computation in superposition.arXiv preprint arXiv:2408.05451, 2024
-
[57]
arXiv preprint arXiv:2409.15318 , year =
Micah Adler and Nir Shavit. On the complexity of neural computation in superposition.arXiv preprint arXiv:2409.15318, 2024
-
[58]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute opti- mally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
-
[59]
The depth-to-width interplay in self-attention, 2021
Yoav Levine, Noam Wies, Or Sharir, Hofit Bata, and Amnon Shashua. The depth-to-width interplay in self-attention.arXiv preprint arXiv:2006.12467, 2020
-
[60]
ngpt: Normalized transformer with rep- resentation learning on the hypersphere
Ilya Loshchilov, Cheng-Ping Hsieh, Simeng Sun, and Boris Ginsburg. ngpt: Normalized transformer with representation learning on the hypersphere.arXiv preprint arXiv:2410.01131, 2024
-
[61]
arXiv preprint arXiv:2501.12243 , year=
Yizhou Liu, Ziming Liu, and Jeff Gore. Focus: First order concentrated updating scheme.arXiv preprint arXiv:2501.12243, 2025
-
[62]
Mechanistic Interpretability for AI Safety -- A Review
Leonard Bereska and Efstratios Gavves. Mechanistic interpretability for ai safety–a review. arXiv preprint arXiv:2404.14082, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. NeurIPS Paper Checklist 1.Claims Question: Do the main claims made in the abstract and introduction accuratel...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
work page 2025
-
[65]
Text samples were streamed directly from the datasets
-
[66]
Text was tokenized without adding special tokens (e.g., EOS)
-
[67]
Token frequencies were counted and accumulated until the target token count (1 million tokens) was reached
-
[68]
Token frequencies were saved as JSON files for subsequent detailed analyses. Token frequency data was systematically stored for each tokenizer and dataset combination, enabling comparative analyses of token distributions. The data files provide foundational insights into tokenizer efficiency and coverage across diverse textual domains. 25 Figure 7: Row no...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.