A Common Pool of Privacy Problems: Legal and Technical Lessons from a Large-Scale Web-Scraped Machine Learning Dataset
Pith reviewed 2026-05-19 08:15 UTC · model grok-4.3
The pith
Web-scraped datasets for AI training contain significant personally identifiable information despite sanitization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
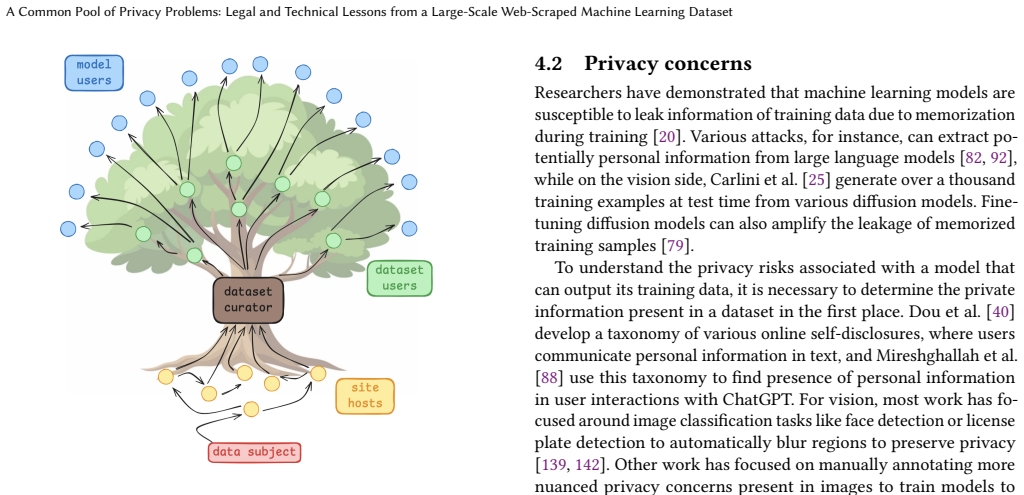
An audit of one popular web-scraped machine learning dataset finds significant personally identifiable information persisting after sanitization. This supplies concrete evidence that large-scale web-scraped corpora may contain legally defined personal data, which can then propagate into models trained on them. The empirical results inform an analysis of risks under privacy and data protection laws and support the argument that frameworks treating internet content as freely available for AI training should be reoriented to impose meaningful limits on indiscriminate scraping.
What carries the argument
The combination of a targeted privacy audit of a real-world sanitized dataset with legal analysis of how personal data in training sets interacts with existing privacy statutes.
If this is right
- Models trained on such data can embed and later disclose personal information from the original sources.
- Organizations that compile or use these datasets face concrete exposure under data-protection regulations.
- Current cleaning pipelines do not reliably prevent personal data from reaching downstream AI applications.
- Legal exposure can extend beyond the original curators to any party that trains or deploys models on the data.
- Redefining the boundary of publicly available information would constrain how future datasets are assembled.
Where Pith is reading between the lines
- Similar privacy leakage patterns may appear in other large web corpora even when their curators claim different cleaning approaches.
- Shifting to narrower, purpose-collected data sources could become a practical way to reduce legal surface area for AI developers.
- Courts or regulators might treat the documented presence of personal data as evidence in future enforcement actions against scraped-data models.
- Systematic cross-dataset comparisons would test whether the observed issues are isolated or structural.
Load-bearing premise
The single audited dataset and its particular sanitization steps stand in for the full class of large-scale web-scraped machine learning corpora.
What would settle it
A follow-up audit of several other major web-scraped datasets that applies comparable cleaning methods and finds no measurable personal data.
Figures

























read the original abstract
We investigate the contents of web-scraped data for training AI systems, at sizes where human dataset curators and compilers no longer manually annotate every sample. Building off of prior privacy concerns in machine learning models, we ask: What are the legal privacy implications of web-scraped machine learning datasets? In an empirical study of a popular training dataset, we find significant presence of personally identifiable information despite sanitization efforts. Our audit provides concrete evidence to support the concern that any large-scale web-scraped dataset may contain legally defined personal data. We use these findings of a real-world dataset to inform our legal analysis with respect to existing privacy and data protection laws. We surface various legal risks of current data curation practices that may propagate personal information to train downstream models. Based on our empirical and legal analyses, we argue for reorientation of current frameworks of "publicly available" information to meaningfully limit the development of AI built upon indiscriminate scraping of the internet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical audit of a popular large-scale web-scraped ML training dataset and reports the presence of personally identifiable information (PII) despite prior sanitization. It leverages these findings to analyze risks under privacy and data protection laws, arguing that indiscriminate web scraping propagates personal data into downstream models and calling for a reorientation of legal frameworks treating such data as 'publicly available.'
Significance. If the audit methodology and generalization hold, the work offers a valuable bridge between technical dataset analysis and legal privacy scholarship in AI, providing concrete examples that could inform policy on data curation practices. The explicit combination of an empirical study with downstream legal implications is a constructive contribution, though its impact depends on addressing the scope of the single-dataset evidence.
major comments (2)
- [Abstract and §4] Abstract and §4 (Empirical Study): The claim of 'significant presence of personally identifiable information despite sanitization efforts' is asserted without reported quantitative details on audit methodology, sample size, false-positive rates, or evaluation criteria for the sanitization process. This directly weakens the evidential basis for the central generalization.
- [§5 and Conclusion] §5 (Legal Analysis) and Conclusion: The inference that findings from one audited dataset support the claim that 'any large-scale web-scraped dataset may contain legally defined personal data' requires demonstration that the dataset's scraping sources, scale, and cleaning pipeline are representative or not atypically lax relative to other corpora (e.g., those with additional deduplication steps). Without this, the legal-risk conclusions for the broader class do not follow.
minor comments (2)
- [Results tables] Table 1 or equivalent results summary: Clarify the exact PII categories detected and their prevalence to improve readability for non-technical legal readers.
- [Related Work] Related work section: Add explicit comparison to prior audits of Common Crawl-derived datasets to better situate the novelty of the sanitization evaluation.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and indicate the revisions we will make to improve the clarity and evidential support of the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Empirical Study): The claim of 'significant presence of personally identifiable information despite sanitization efforts' is asserted without reported quantitative details on audit methodology, sample size, false-positive rates, or evaluation criteria for the sanitization process. This directly weakens the evidential basis for the central generalization.
Authors: We agree that the empirical audit section requires greater transparency to support our claims. In the revised manuscript we will expand §4 with quantitative details, including the total number of samples audited, the precise PII detection methodology and tools employed, results from any manual verification used to estimate false-positive rates, and explicit criteria for assessing the prior sanitization process. These additions will strengthen the evidential foundation without altering the core findings. revision: yes
-
Referee: [§5 and Conclusion] §5 (Legal Analysis) and Conclusion: The inference that findings from one audited dataset support the claim that 'any large-scale web-scraped dataset may contain legally defined personal data' requires demonstration that the dataset's scraping sources, scale, and cleaning pipeline are representative or not atypically lax relative to other corpora (e.g., those with additional deduplication steps). Without this, the legal-risk conclusions for the broader class do not follow.
Authors: We acknowledge the referee's concern about generalizability. The audited dataset is a widely adopted example that reflects common web-scraping and sanitization practices found across many large-scale ML corpora. In revision we will add a dedicated paragraph in §5 comparing its sources, scale, and cleaning steps to other prominent datasets and citing related reports of PII leakage in the literature. We maintain, however, that the legal analysis centers on risks inherent to the widespread practice of indiscriminate web scraping rather than on proving every possible corpus is identical; the single concrete case study is offered as illustrative evidence of those risks. We will revise the conclusion to clarify this scope while preserving the policy recommendations. revision: partial
Circularity Check
No significant circularity; empirical audit provides independent evidence
full rationale
The paper conducts a direct empirical audit of one large-scale web-scraped dataset to identify personally identifiable information that persists after sanitization. This observation is external to the paper's own claims and is not derived from any self-referential definitions, fitted parameters, or prior results by the same authors. The legal analysis then applies existing privacy frameworks to the observed risks without reducing the central claim to an input by construction. No equations, uniqueness theorems, ansatzes, or self-citation chains are load-bearing in the derivation. The generalization from the audited example to 'any large-scale web-scraped dataset' is an inductive inference whose strength can be debated on representativeness grounds, but that does not create circularity under the specified criteria. The work is self-contained against external benchmarks via the dataset inspection itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The examined dataset and its sanitization steps are representative of typical industry web-scraped corpora.
Forward citations
Cited by 4 Pith papers
-
Channel-Level Semantic Perturbations: Unlearnable Examples for Diverse Training Paradigms
Unlearnable examples fail under pretraining-finetuning due to semantic filtering by frozen layers, but Shallow Semantic Camouflage restores effectiveness by confining perturbations to semantically valid subspaces.
-
How Can AI Augment Access to Justice? Public Defenders' Perspectives on AI Adoption
Public defenders view AI as most useful for evidence investigation but limited in courtroom work and strategy, with adoption blocked by costs, confidentiality risks, and norms, requiring human oversight and open development.
-
Security Considerations for Multi-agent Systems
No existing AI security framework covers a majority of the 193 identified multi-agent system threats in any category, with OWASP Agentic Security Initiative achieving the highest overall coverage at 65.3%.
-
Cyclic Adaptive Private Synthesis for Sharing Real-World Data in Education
CAPS provides an iterative differentially private synthesis method that outperforms one-shot baselines on authentic educational real-world data.
Reference graph
Works this paper leans on
-
[1]
CA Civ Code § 1798.192. 2018. California Consumer Privacy Act of 2018. https://leginfo.legislature.ca.gov/faces/codes_displayText.xhtml? division=3.&part=4.&lawCode=CIV&title=1.81.5
work page 2018
-
[2]
OR SB 619. 2018. Oregon Consumer Privacy Act of 2018. https: //olis.oregonlegislature.gov/liz/2023R1/Downloads/MeasureDocument/ SB619/Enrolled
work page 2018
-
[3]
15 U.S.C. § 6501. 1998. Children’s Online Privacy Protection Act of
work page 1998
-
[4]
https://uscode.house.gov/view.xhtml?req=granuleid%3AUSC-prelim- title15-section6501&edition=prelim
-
[5]
Lura Abbott and Christine Grady. 2011. A systematic review of the empirical literature evaluating IRBs: What we know and what we still need to learn. Journal of Empirical Research on Human Research Ethics 6, 1 (2011), 3–19
work page 2011
-
[6]
Adobe. 2025. Content Credentials overview. https://helpx.adobe.com/creative- cloud/help/content-credentials.html
work page 2025
-
[7]
Stability AI. 2025. https://stability.ai/news/stable-diffusion-public-release
work page 2025
-
[8]
Spawning AI. 2025. Spawning API. https://api.spawning.ai/spawning-api
work page 2025
-
[9]
Jerone Andrews, Dora Zhao, William Thong, Apostolos Modas, Orestis Pa- pakyriakopoulos, and Alice Xiang. 2023. Ethical considerations for responsible data curation. Advances in Neural Information Processing Systems 36 (2023), 55320–55360
work page 2023
-
[10]
Internet Archive. 2013. Wayback Machine APIs. https://archive.org/help/ wayback_api.php
work page 2013
- [11]
-
[12]
Romain Beaumont. 2022. Clip Retrieval: Easily compute clip embeddings and build a clip retrieval system with them. https://github.com/rom1504/clip- retrieval
work page 2022
-
[13]
Yoav Benjamini and Daniel Yekutieli. 2001. The control of the false discovery rate in multiple testing under dependency.Annals of statistics (2001), 1165–1188
work page 2001
-
[14]
Abeba Birhane, Sanghyun Han, Vishnu Boddeti, Sasha Luccioni, et al . 2024. Into the LAION’s den: Investigating hate in multimodal datasets. Advances in Neural Information Processing Systems 36 (2024)
work page 2024
-
[15]
Abeba Birhane, Pratyusha Kalluri, Dallas Card, William Agnew, Ravit Dotan, and Michelle Bao. 2022. The values encoded in machine learning research. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency. 173–184
work page 2022
- [16]
-
[17]
Abeba Birhane, Ryan Steed, Victor Ojewale, Briana Vecchione, and In- ioluwa Deborah Raji. 2024. SoK: AI Auditing: The Broken Bus on the Road to AI Accountability. In 2nd IEEE Conference on Secure and Trustworthy Machine Learning
work page 2024
-
[18]
Rishi Bommasani, Kathleen A Creel, Ananya Kumar, Dan Jurafsky, and Percy S Liang. 2022. Picking on the same person: Does algorithmic monoculture lead to outcome homogenization? Advances in Neural Information Processing Systems 35 (2022), 3663–3678
work page 2022
-
[19]
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. 2021. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [20]
-
[21]
Gavin Brown, Mark Bun, Vitaly Feldman, Adam Smith, and Kunal Talwar. 2021. When is memorization of irrelevant training data necessary for high-accuracy learning?. In Proceedings of the 53rd annual ACM SIGACT symposium on theory of computing. 123–132
work page 2021
-
[22]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in Neural Information Processing Systems 33 (2020), 1877–1901
work page 2020
-
[23]
Amy Bruckman. 2002. Studying the amateur artist: A perspective on disguising data collected in human subjects research on the Internet.Ethics and Information Technology 4 (2002), 217–231
work page 2002
-
[24]
Ben Caldwell, Michael Cooper, Loretta Guarino Reid, Gregg Vanderheiden, Wendy Chisholm, John Slatin, and Jason White. 2008. Web content accessibility guidelines (WCAG) 2.0. WWW Consortium (W3C) 290, 1-34 (2008), 5–12
work page 2008
- [25]
-
[26]
Nicolas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramer, Borja Balle, Daphne Ippolito, and Eric Wallace. 2023. Extract- ing training data from diffusion models. In 32nd USENIX Security Symposium (USENIX Security 23). 5253–5270
work page 2023
-
[27]
Yunzhuo Chen, Nur Al Hasan Haldar, Naveed Akhtar, and Ajmal Mian. 2023. Text-image guided Diffusion Model for generating Deepfake celebrity interac- tions. In 2023 International Conference on Digital Image Computing: Techniques and Applications (DICTA). IEEE, 348–355
work page 2023
-
[28]
Cloudflare. 2024. Cloudflare API v4 documentation: Get multiple domain de- tails. https://developers.cloudflare.com/api/operations/domain-intelligenceget- multiple-domain-details
work page 2024
-
[29]
Samantha Cole. 2023. Largest dataset powering AI images removed after dis- covery of child sexual abuse material. 404 Media 20 (2023)
work page 2023
-
[30]
Federal Trade Commission. 2025. COPPA Safe Harbor Program. https://www. ftc.gov/enforcement/coppa-safe-harbor-program
work page 2025
-
[31]
Creative Commons. 2025. CC BY 4.0. https://creativecommons.org/licenses/ by/4.0/deed.en
work page 2025
-
[32]
Danish Contractor, Daniel McDuff, Julia Katherine Haines, Jenny Lee, Christo- pher Hines, Brent Hecht, Nicholas Vincent, and Hanlin Li. 2022. Behavioral use licensing for responsible AI. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency. 778–788
work page 2022
-
[33]
Common Crawl. 2025. Common Crawl. https://commoncrawl.org
work page 2025
-
[34]
Common Crawl. 2025. Frequently asked questions. https://commoncrawl.org/ faq
work page 2025
-
[35]
DataComp. 2023. DataComp. https://github.com/mlfoundations/datacomp
work page 2023
-
[36]
DataComp. 2023. Is there overlap between common-pool and laion-5B? https: //github.com/mlfoundations/datacomp/issues/19
work page 2023
-
[37]
Emily Denton, Alex Hanna, Razvan Amironesei, Andrew Smart, and Hilary Nicole. 2021. On the genealogy of machine learning datasets: A critical history of ImageNet. Big Data & Society 8, 2 (2021), 20539517211035955
work page 2021
-
[38]
Meera A Desai, Irene V Pasquetto, Abigail Z Jacobs, and Dallas Card. 2024. An archival perspective on pretraining data. Patterns 5, 4 (2024)
work page 2024
-
[39]
Mark Díaz, Sunipa Dev, Emily Reif, Emily Denton, and Vinodkumar Prab- hakaran. 2024. SoUnD Framework: Analyzing (So) cial Representation in (Un) structured (D) ata. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 7. 371–383
work page 2024
- [40]
- [41]
-
[42]
Brianna Dym and Casey Fiesler. 2020. Ethical and Privacy Considerations for Research Using Online Fandom Data. Transformative works and cultures 33 (2020)
work page 2020
-
[43]
EasyOCR. 2025. EasyOCR. https://www.jaided.ai/easyocr/
work page 2025
-
[44]
Benj Edwards. 2022. Artist finds private medical record photos in popular AI training data set. https://arstechnica.com/information-technology/2022/09/ artist-finds-private-medical-record-photos-in-popular-ai-training-data-set/
work page 2022
-
[45]
European Parliament and Council of the European Union. 2016. Regulation (EU) 2016/679 of the European Parliament and of the Council . https://data.europa.eu/ eli/reg/2016/679/oj
work page 2016
-
[46]
Hugging Face. 2025. https://huggingface.co/api/datasets/mlfoundations/ datacomp_pools?expand%5B%5D=downloads&expand%5B%5D= downloadsAllTime
work page 2025
-
[47]
Casey Fiesler and Nicholas Proferes. 2018. “Participant” perceptions of Twitter research ethics. Social Media+ Society 4, 1 (2018), 2056305118763366
work page 2018
-
[48]
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, et al. 2024. Datacomp: In search of the next generation of multimodal datasets. Advances in Neural Information Processing Systems 36 (2024)
work page 2024
-
[49]
Dilrukshi Gamage, Dilki Sewwandi, Min Zhang, and Arosha K Bandara. 2025. Labeling Synthetic Content: User Perceptions of Label Designs for AI-Generated Content on Social Media. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems . 1–29
work page 2025
- [50]
-
[51]
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii, and Kate Crawford. 2021. Datasheets for datasets. Commun. ACM 64, 12 (2021), 86–92
work page 2021
-
[52]
Github. 2023. img2dataset ignores X-Robots-Tag. https://github.com/rom1504/ img2dataset/issues/298
work page 2023
-
[53]
Github. 2023. Implement Robots.txt support. https://github.com/rom1504/ img2dataset/issues/48
work page 2023
-
[54]
Github. 2023. Metadata download error - OSError: Consistency check failed. https://github.com/mlfoundations/datacomp/issues/33
work page 2023
-
[55]
Abigail Goldsteen, Gilad Ezov, Ron Shmelkin, Micha Moffie, and Ariel Farkash
-
[56]
AI and Ethics 2, 3 (2022), 477–491
Data minimization for GDPR compliance in machine learning models. AI and Ethics 2, 3 (2022), 477–491
work page 2022
- [57]
- [58]
-
[59]
Jack Hardinges, Elena Simperl, and Nigel Shadbolt. 2024. We must fix the lack of transparency around the data used to train foundation models. Harvard Data Science Review (Special Issue 5). https://doi. org/10.1162/99608f92. a50ec6e6 (2024)
-
[60]
Woodrow Hartzog. 2018. The case against idealising control. Eur. Data Prot. L. Rev. 4 (2018), 423
work page 2018
-
[61]
Woodrow Hartzog. 2019. The Public Information Fallacy. BUL Rev. 99 (2019), 459
work page 2019
-
[62]
Woodrow Hartzog and Evan Selinger. 2015. Surveillance as loss of obscurity. Wash. & Lee L. Rev. 72 (2015), 1343
work page 2015
-
[63]
Carol A Heimer and JuLeigh Petty. 2010. Bureaucratic ethics: IRBs and the legal regulation of human subjects research. Annual Review of Law and Social Science 6, 1 (2010), 601–626
work page 2010
-
[64]
Benjamin Henne, Maximilian Koch, and Matthew Smith. 2014. On the aware- ness, control and privacy of shared photo metadata. In International Conference on Financial Cryptography and Data Security . Springer, 77–88
work page 2014
-
[65]
Dennis D Hirsch. 2020. From Individual Control to Social Protection: New Paradigms for Privacy Law in the Age of Predictive Analytics’(2020). Md L Rev 79 (2020), 439
work page 2020
-
[66]
Rachel Hong, William Agnew, Tadayoshi Kohno, and Jamie Morgenstern. 2024. Who’s in and who’s out? A case study of multimodal CLIP-filtering in DataComp. 30 A Common Pool of Privacy Problems: Legal and Technical Lessons from a Large-Scale Web-Scraped Machine Learning Dataset In Proceedings of the 4th ACM Conference on Equity and Access in Algorithms, Mecha...
work page 2024
-
[67]
Jevan Hutson and Ben Winters. 2024. America’s next" Stop Model!" Model Deletion. Geo. L. Tech. Rev. 8 (2024), 124
work page 2024
-
[68]
ICO. 2025. Overview – Data Protection and the EU. https://ico.org.uk/for- organisations/data-protection-and-the-eu/overview-data-protection-and- the-eu/
work page 2025
-
[69]
iKeepSafe. 2025. Certified Products. https://ikeepsafe.org/products/#coppa
work page 2025
-
[70]
Mehtab Khan and Alex Hanna. 2022. The subjects and stages of ai dataset development: A framework for dataset accountability. Ohio St. Tech. LJ 19 (2022), 171
work page 2022
-
[71]
kidSAFE. [n. d.]. kidSAFE Seal Program Member List. https://www.kidsafeseal. com/certifiedproducts.html
-
[72]
Tadayoshi Kohno, Yasemin Acar, and Wulf Loh. 2023. Ethical frameworks and computer security trolley problems: Foundations for conversations. In 32nd USENIX Security Symposium (USENIX Security 23) . 5145–5162
work page 2023
-
[73]
LAION. 2025. Privacy Policy. https://laion.ai/privacy-policy/
work page 2025
-
[74]
LAION. 2025. Releasing RE-LAION 5B: Transparent iteration on LAION-5B with additional safety fixes. https://laion.ai/blog/relaion-5b/
work page 2025
-
[75]
Pierre-Carl Langlais, Carlos Rosas Hinostroza, Mattia Nee, Catherine Arnett, Pavel Chizhov, Eliot Krzystof Jones, Irène Girard, David Mach, Anastasia Stasenko, and Ivan P Yamshchikov. 2025. Common Corpus: The Largest Col- lection of Ethical Data for LLM Pre-Training. arXiv preprint arXiv:2506.01732 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Clément Le Ludec, Maxime Cornet, and Antonio A Casilli. 2023. The problem with annotation. Human labour and outsourcing between France and Madagas- car. Big Data & Society 10, 2 (2023), 20539517231188723
work page 2023
-
[77]
Christina Lee. 2025. Beyond Algorithmic Disgorgement: Remedying Algorith- mic Harms. (2025)
work page 2025
-
[78]
Vladimir I Levenshtein et al. 1966. Binary codes capable of correcting deletions, insertions, and reversals. In Soviet physics doklady, Vol. 10. Soviet Union, 707– 710
work page 1966
- [79]
-
[80]
Minghao Li, Tengchao Lv, Jingye Chen, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, and Furu Wei. 2023. Trocr: Transformer-based optical character recognition with pre-trained models. In Proceedings of the AAAI conference on artificial intelligence, Vol. 37. 13094–13102
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.