Recognition: no theorem link
Security Considerations for Multi-agent Systems
Pith reviewed 2026-05-15 14:06 UTC · model grok-4.3
The pith
No reviewed security framework covers a majority of threats in any category for multi-agent AI systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
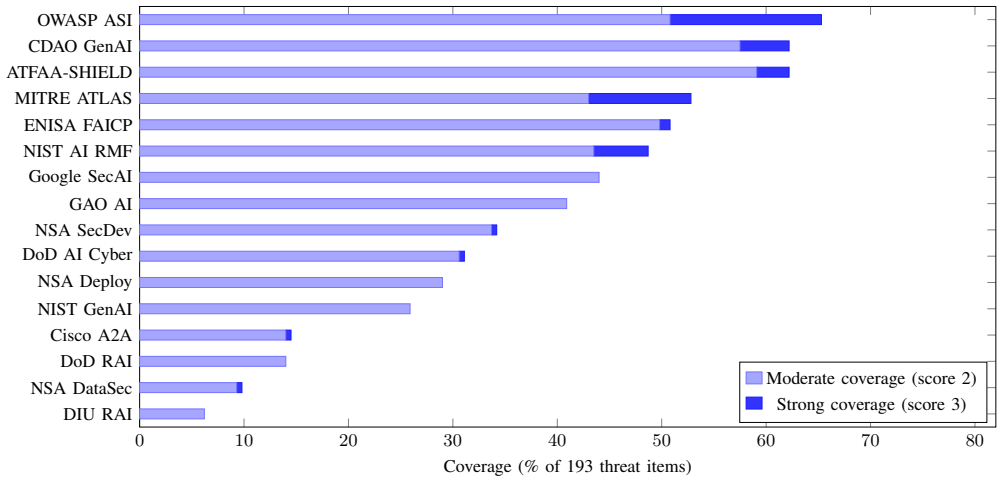
Multi-agent AI systems introduce qualitatively distinct security vulnerabilities from those of singular models; a quantitative scoring of sixteen frameworks against 193 validated threats shows that none achieve majority coverage in any of the nine risk categories, while non-determinism and data leakage remain the most under-addressed.
What carries the argument
A set of 193 distinct threat items across nine risk categories, derived from generative AI-assisted modeling and domain-expert validation, then used to score each framework on a three-point scale.
If this is right
- Framework selection for MAS deployments should favor the OWASP initiative for design-phase coverage while supplementing gaps elsewhere.
- Non-determinism and data leakage in shared-memory and inter-agent settings require targeted mitigations absent from current frameworks.
- Development and operational phases show lower average scores than design, indicating where new controls are most needed.
- The absence of majority coverage across all frameworks implies that custom controls will be required for production MAS.
Where Pith is reading between the lines
- Organizations may need to combine elements from multiple frameworks rather than relying on any single one.
- Real-world deployment data could test whether the 193 items capture the most common attack patterns observed in practice.
- Inter-agent communication protocols may require new standards that existing frameworks do not yet address.
Load-bearing premise
The 193 threat items fully and accurately represent the complete MAS cybersecurity risk landscape.
What would settle it
Discovery of a framework that scores above 50 percent coverage on every one of the nine categories using the same 193-item list, or identification of major MAS threats missing from that list.
Figures

read the original abstract
Multi-agent artificial intelligence systems or MAS are systems of autonomous agents that exercise delegated tool authority, share persistent memory, and coordinate via inter-agent communication. MAS introduces qualitatively distinct security vulnerabilities from those documented for singular AI models. Existing security and governance frameworks were not designed for these emerging attack surfaces. This study systematically characterizes the threat landscape of MAS and quantitatively evaluates 16 security frameworks for AI against it. A four-phase methodology is proposed: constructing a deep technical knowledge base of production multi-agent architectures; conducting generative AI-assisted threat modeling scoped to MAS cybersecurity risks and validated by domain experts; structuring survey plans at individual-threat granularity; and scoring each framework on a three-point scale against the cybersecurity risks. The risks were organized into 193 distinct main threat items across nine risk categories. The expected minimal average score is 2. No reviewed framework achieves majority coverage of any single category. Non-Determinism (mean score 1.231 across all 16 frameworks) and Data Leakage (1.340) are the most under-addressed domains. The OWASP Agentic Security Initiative leads overall at 65.3\% coverage and in the design phase; the CDAO Generative AI Responsible AI Toolkit leads in development and operational coverage. These results provide the first empirical cross-framework comparison for MAS security and offer evidence-based guidance for framework selection. Please check back for information on the published journal version.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a four-phase methodology to characterize the cybersecurity threat landscape of multi-agent AI systems (MAS), which feature autonomous agents with delegated tool authority, persistent shared memory, and inter-agent coordination. It constructs a set of 193 distinct threat items across nine risk categories via generative AI-assisted modeling followed by domain-expert validation, then scores 16 existing AI security frameworks on a three-point scale against these threats. The central findings are that no framework achieves majority coverage of any category, Non-Determinism (mean score 1.231) and Data Leakage (1.340) are the most under-addressed domains, and the OWASP Agentic Security Initiative leads with 65.3% overall coverage.
Significance. If the 193-item threat list is shown to be both exhaustive and accurately classified, the work supplies the first quantitative, cross-framework empirical comparison for MAS security. This would offer concrete, evidence-based guidance on framework selection and identify priority gaps (especially non-determinism and data leakage) that future frameworks must address. The explicit scoring protocol and category-level breakdowns would also enable reproducible follow-on studies.
major comments (2)
- [Methodology] Methodology section: the description of generative AI-assisted threat modeling and subsequent domain-expert validation supplies no information on the number of experts, the validation protocol, inter-rater agreement statistics, or any cross-check against existing MAS or AI security taxonomies (e.g., NIST or academic surveys). Because the headline coverage percentages and the claim that 'no reviewed framework achieves majority coverage' rest entirely on the completeness and correctness of the 193-item list, these omissions are load-bearing.
- [Results] Results and Evaluation sections: the three-point scoring procedure is presented without examples of how individual threats were scored, how consistency across raters or frameworks was maintained, or sensitivity analysis showing how the reported means (Non-Determinism 1.231, Data Leakage 1.340) would change under plausible reclassifications of even a modest subset of the 193 items.
minor comments (2)
- [Abstract] The abstract ends with the sentence 'Please check back for information on the published journal version,' which is atypical for an arXiv preprint and should be removed or clarified.
- [Results] Table or figure presenting the per-framework, per-category scores would benefit from an explicit legend for the three-point scale and from reporting the raw counts rather than only means.
Simulated Author's Rebuttal
We are grateful to the referee for their constructive feedback, which has helped us improve the clarity and rigor of our work. Below we respond to each major comment and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Methodology] Methodology section: the description of generative AI-assisted threat modeling and subsequent domain-expert validation supplies no information on the number of experts, the validation protocol, inter-rater agreement statistics, or any cross-check against existing MAS or AI security taxonomies (e.g., NIST or academic surveys). Because the headline coverage percentages and the claim that 'no reviewed framework achieves majority coverage' rest entirely on the completeness and correctness of the 193-item list, these omissions are load-bearing.
Authors: We agree that the original manuscript omitted key details on the expert validation process. In the revised manuscript, we have expanded the Methodology section to describe the number of domain experts involved, the validation protocol (including iterative review and consensus resolution), inter-rater agreement statistics, and explicit cross-checks against the NIST AI Risk Management Framework as well as relevant academic surveys on AI threats. These additions directly support the completeness of the 193-item list and the validity of the coverage claims. revision: yes
-
Referee: [Results] Results and Evaluation sections: the three-point scoring procedure is presented without examples of how individual threats were scored, how consistency across raters or frameworks was maintained, or sensitivity analysis showing how the reported means (Non-Determinism 1.231, Data Leakage 1.340) would change under plausible reclassifications of even a modest subset of the 193 items.
Authors: We concur that greater transparency in the scoring procedure is warranted. The revised manuscript now includes concrete examples of how representative threats were scored, details the standardized rubric and reviewer process used to maintain consistency, and presents a sensitivity analysis evaluating the effect of plausible reclassifications on the mean scores. This analysis confirms that the identification of Non-Determinism and Data Leakage as the most under-addressed domains remains robust. revision: yes
Circularity Check
No significant circularity in the evaluation methodology
full rationale
The paper constructs an independent set of 193 threat items via generative AI-assisted modeling and domain-expert validation, then applies a three-point scoring process to 16 external frameworks. This produces the reported means (e.g., Non-Determinism at 1.231) and coverage percentages (e.g., OWASP at 65.3%) directly from the application step. No equation or definition equates the output scores to the construction process itself, no parameter is fitted and then relabeled as a prediction, and no load-bearing premise rests on a self-citation chain. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-agent systems introduce qualitatively distinct security vulnerabilities from those documented for singular AI models.
Forward citations
Cited by 1 Pith paper
-
A Formal Security Framework for MCP-Based AI Agents: Threat Taxonomy, Verification Models, and Defense Mechanisms
MCPSHIELD offers a threat taxonomy of 23 attack vectors, a labeled transition system verification model, and a defense-in-depth architecture claiming 91% coverage for MCP-based AI agents.
Reference graph
Works this paper leans on
-
[1]
The road to agentic ai navigating architecture, threats, and solutions,
V . Ciancaglini, M. Balduzzi, S. Gariuolo, R. V osseler, and F. Tucci, “The road to agentic ai navigating architecture, threats, and solutions,” Trend Micro Research, 2025. [Online]. Available: https: //www.trendmicro.com/vinfo/us/security/news/security-technology/ the-road-to-agentic-ai-navigating-architecture-threats-and-solutions
work page 2025
-
[2]
M. Corporation, “Microsoft 365 copilot,” Software application, 2026, aI-powered productivity tool integrating Word, Excel, PowerPoint, Outlook, and more. Available at: https://apps.microsoft.com/detail/ 9WZDNCRD29V9
work page 2026
-
[3]
Artificial intelligence risk management framework (AI RMF 1.0),
National Institute of Standards and Technology, “Artificial intelligence risk management framework (AI RMF 1.0),” National Institute of Standards and Technology, Tech. Rep. NIST AI 100-1, 2023. [Online]. Available: https://doi.org/10.6028/NIST.AI.100-1
-
[4]
Adversarial machine learning: A taxonomy and terminology of attacks and mitigations,
A. Vassilev, A. Oprea, A. Fordyce, H. Anderson, X. Davies, and M. Hamin, “Adversarial machine learning: A taxonomy and terminology of attacks and mitigations,” National Institute of Standards and Technology, Tech. Rep. NIST AI 100-2e2025, 2025. [Online]. Available: https://doi.org/10.6028/NIST.AI.100-2e2025
-
[5]
MITRE ATLAS: Adversarial threat landscape for artificial-intelligence systems,
MITRE Corporation, “MITRE ATLAS: Adversarial threat landscape for artificial-intelligence systems,” The MITRE Corporation, Tech. Rep., 2025, living knowledge base of adversarial ML tactics and techniques, Spring 2025 release. [Online]. Available: https: //atlas.mitre.org/
work page 2025
-
[6]
OW ASP Top 10 for Agen- tic Applications 2026,
OW ASP GenAI Security Project, “OW ASP Top 10 for Agen- tic Applications 2026,” OW ASP Foundation, Tech. Rep., 2026, agentic Security Initiative (ASI), https://genai.owasp.org/resource/ owasp-top-10-for-agentic-applications/
work page 2026
-
[7]
Securing agentic AI: A comprehensive threat model and mitigation framework for generative AI agents,
V . S. Narajala and O. Narayan, “Securing agentic AI: A comprehensive threat model and mitigation framework for generative AI agents,” Amazon Web Services, Proactive Security, Technical Report, 2025, presents the ATFAA threat taxonomy (9 threats, 5 domains) and the SHIELD mitigation framework (6 control strategies). [Online]. Available: https://arxiv.org/...
-
[8]
Generative AI responsible AI toolkit, version 1.0,
Chief Digital and Artificial Intelligence Office, “Generative AI responsible AI toolkit, version 1.0,” U.S. Department of Defense, Chief Digital and Artificial Intelligence Office, Tech. Rep., Dec
-
[9]
[Online]. Available: https://www.ai.mil/Portals/137/Documents/ Resources%20Page/2024-12GenAI-Responsible-AI-Toolkit.pdf
work page 2024
-
[10]
Taxonomy of failure mode in agentic ai systems,
P. Bryan, G. Severi, J. D. Gruyter, D. Jones, B. Bullwinkel, A. Min- nich, S. Chawla, G. Lopez, M. Pouliot, A. Fourney, W. Maxwell, K. Pratt, S. Qi, N. Chikanov, R. Lutz, R. Sekhar, R. Dheekonda, B.- E. Jagdagdorj, E. Kim, J. Song, K. Hines, R. Lundeen, S. Vaughan, V . Westerhoff, Y . Zunger, C. Kawaguchi, M. Russinovich, R. Shankar, and S. Kumar, “Taxono...
work page 2025
-
[11]
On the regulatory potential of user interfaces for ai agent governance,
K. J. K. Feng, T. S. Kim, R. Y . Pang, F. Huq, T. August, and A. X. Zhang, “On the regulatory potential of user interfaces for ai agent governance,” 2025. [Online]. Available: https://arxiv.org/abs/ 2512.00742
-
[12]
Formal Policy Enforcement for Real-World Agentic Systems
N. Palumbo, S. Choudhary, J. Choi, P. Chalasani, and S. Jha, “Policy compiler for secure agentic systems,” 2026. [Online]. Available: https://arxiv.org/abs/2602.16708
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Agentrim: Tool risk mitigation for agentic ai,
R. Betser, S. Bose, A. Giloni, C. Picardi, S. Padakandla, and R. Vainshtein, “Agentrim: Tool risk mitigation for agentic ai,” 2026. [Online]. Available: https://arxiv.org/abs/2601.12449
-
[14]
Overseeing agents without constant oversight: Challenges and opportunities,
M. Grunde-McLaughlin, H. Mozannar, M. Murad, J. Chen, S. Amershi, and A. Fourney, “Overseeing agents without constant oversight: Challenges and opportunities,” 2026. [Online]. Available: https://arxiv.org/abs/2602.16844
-
[15]
Multi-agent systems execute arbitrary malicious code,
H. Triedman, R. Jha, and V . Shmatikov, “Multi-agent systems execute arbitrary malicious code,” 2025. [Online]. Available: https://arxiv.org/abs/2503.12188
-
[16]
On the suitability of llm-driven agents for dark pattern audits,
C. Sun, Y . Vekaria, and R. Nithyanand, “On the suitability of llm-driven agents for dark pattern audits,” 2026. [Online]. Available: https://arxiv.org/abs/2603.03881
-
[17]
Emergent dark patterns in ai-generated user interfaces,
D. Pandey, “Emergent dark patterns in ai-generated user interfaces,”
-
[18]
Available: https://arxiv.org/abs/2602.18445
[Online]. Available: https://arxiv.org/abs/2602.18445
-
[19]
Human-in-the-loop interactive report generation for chronic disease adherence,
X. Zhang, J. Yu, P. Yan, L. Jiang, X. Shen, M. Cheng, and X. Liu, “Human-in-the-loop interactive report generation for chronic disease adherence,” 2026. [Online]. Available: https: //arxiv.org/abs/2601.06364
-
[20]
Agenticcyops: Securing multi-agentic ai integration in enterprise cyber operations,
S. Mitra, R. Patel, S. Mittal, M. R. Rahman, and S. Rahimi, “Agenticcyops: Securing multi-agentic ai integration in enterprise cyber operations,” 2026. [Online]. Available: https://arxiv.org/abs/ 2603.09134
-
[21]
Y . Liu, J. Cai, Y . Li, Q. Meng, Z. Liu, X. Li, C. Qian, C. Shi, and C. Yang, “Masfactory: A graph-centric framework for orchestrating llm-based multi-agent systems with vibe graphing,” 2026. [Online]. Available: https://arxiv.org/abs/2603.06007
-
[22]
AgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
D. Liu, Q. Ren, C. Qian, S. Shao, Y . Xie, Y . Li, Z. Yang, H. Luo, P. Wang, Q. Liu, B. Hu, L. Tang, J. Mei, D. Guo, L. Yuan, J. Yang, G. Chen, Q. Lin, Y . Yu, B. Zhang, J. Guo, J. Zhang, W. Shao, H. Deng, Z. Xi, W. Wang, W. Wang, W. Shen, Z. Chen, H. Xie, J. Tao, J. Dai, J. Ji, Z. Ba, L. Zhang, Y . Liu, Q. Zhang, L. Zhu, Z. Wei, H. Xue, C. Lu, J. Shao, a...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Think-augmented function calling: Improving llm parameter accuracy through embedded reasoning,
L. Wei, X. Peng, J. Ou, and B. Wang, “Think-augmented function calling: Improving llm parameter accuracy through embedded reasoning,” 2026. [Online]. Available: https://arxiv.org/abs/2601. 18282
work page 2026
-
[24]
A resource-rational principle for modeling visual attention control,
Y . Bai, “A resource-rational principle for modeling visual attention control,” 2026. [Online]. Available: https://arxiv.org/abs/2603.02056
-
[25]
Security Considerations for Artificial Intelligence Agents
N. Li, K. Zhang, K. Polley, and J. Ma, “Security considerations for artificial intelligence agents,” 2026. [Online]. Available: https: //arxiv.org/abs/2603.12230
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
H. Shen, S. Yan, H. Xue, S. Lu, X. Tang, G. Zhang, T. Zhao, and J. Yin, “Mm-condchain: A programmatically verified benchmark for visually grounded deep compositional reasoning,” 2026. [Online]. Available: https://arxiv.org/abs/2603.12266
-
[27]
Language model teams as distributed systems,
E. Mieczkowski, K. M. Collins, I. Sucholutsky, N. V ´elez, and T. L. Griffiths, “Language model teams as distributed systems,” 2026. [Online]. Available: https://arxiv.org/abs/2603.12229
-
[28]
Sceneassistant: A visual feedback agent for open-vocabulary 3d scene generation,
J. Luo, J. Tang, R. Lu, and G. Zeng, “Sceneassistant: A visual feedback agent for open-vocabulary 3d scene generation,” 2026. [Online]. Available: https://arxiv.org/abs/2603.12238
-
[29]
Sentinel agents for secure and trustworthy agentic ai in multi-agent systems,
D. Gosmar and D. A. Dahl, “Sentinel agents for secure and trustworthy agentic ai in multi-agent systems,” 2025. [Online]. Available: https://arxiv.org/abs/2509.14956
-
[30]
A blockchain-monitored agentic ai architecture for trusted perception- reasoning-action pipelines,
S. Jan, H. A. Razzaqi, A. Akarma, and M. R. Belgaum, “A blockchain-monitored agentic ai architecture for trusted perception- reasoning-action pipelines,” 2025. [Online]. Available: https://arxiv. org/abs/2512.20985
-
[31]
Y . Mou, Z. Xue, L. Li, P. Liu, S. Zhang, W. Ye, and J. Shao, “Toolsafe: Enhancing tool invocation safety of llm-based agents via proactive step-level guardrail and feedback,” 2026. [Online]. Available: https://arxiv.org/abs/2601.10156
-
[32]
Mindguard: Intrinsic decision inspection for securing llm agents against metadata poisoning,
Z. Wang, H. Du, G. Shi, J. Zhang, H. Cheng, Y . Yao, K. Guo, and X.-Y . Li, “Mindguard: Intrinsic decision inspection for securing llm agents against metadata poisoning,” 2025. [Online]. Available: https://arxiv.org/abs/2508.20412
-
[33]
Miniscope: A least privilege framework for authorizing tool calling agents,
J. Zhu, K. Tseng, G. Vernik, X. Huang, S. G. Patil, V . Fang, and R. A. Popa, “Miniscope: A least privilege framework for authorizing tool calling agents,” 2025. [Online]. Available: https://arxiv.org/abs/2512.11147
-
[34]
Trustworthy agentic ai requires deterministic architectural boundaries,
M. Bhattarai and M. Vu, “Trustworthy agentic ai requires deterministic architectural boundaries,” 2026. [Online]. Available: https://arxiv.org/abs/2602.09947
-
[35]
Towards verifiably safe tool use for llm agents,
A. Doshi, Y . Hong, C. Xu, E. Kang, A. Kapravelos, and C. K ¨astner, “Towards verifiably safe tool use for llm agents,” 2026. [Online]. Available: https://arxiv.org/abs/2601.08012
-
[36]
Silent egress: When implicit prompt injection makes llm agents leak without a trace,
Q. Lan, A. Kaul, S. Jones, and S. Westrum, “Silent egress: When implicit prompt injection makes llm agents leak without a trace,”
-
[37]
Available: https://arxiv.org/abs/2602.22450
[Online]. Available: https://arxiv.org/abs/2602.22450
-
[38]
AgentCrypt: Advancing Privacy and (Secure) Computation in AI Agent Collaboration
H. Karthikeyan, Y . Guo, L. de Castro, A. Polychroniadou, U. M. Sehwag, L. Ardon, S. Ganesh, and M. Veloso, “Agentcrypt: Advancing privacy and (secure) computation in ai agent collaboration,” 2025. [Online]. Available: https://arxiv.org/abs/2512.08104
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Prompt injection attack to tool selection in llm agents,
J. Shi, Z. Yuan, G. Tie, P. Zhou, N. Z. Gong, and L. Sun, “Prompt injection attack to tool selection in llm agents,” 2025. [Online]. Available: https://arxiv.org/abs/2504.19793
-
[40]
A. Rath, “Agent drift: Quantifying behavioral degradation in multi-agent llm systems over extended interactions,” 2026. [Online]. Available: https://arxiv.org/abs/2601.04170
-
[41]
Z. Anbiaee, M. Rabbani, M. Mirani, G. Piya, I. Opushnyev, A. Ghorbani, and S. Dadkhah, “Security threat modeling for emerging ai-agent protocols: A comparative analysis of mcp, a2a, agora, and anp,” 2026. [Online]. Available: https://arxiv.org/abs/2602.11327
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Agent tools orchestration leaks more: Dataset, benchmark, and mitigation,
Y . Qiao, D. Liu, H. Yang, W. Zhou, and S. Hu, “Agent tools orchestration leaks more: Dataset, benchmark, and mitigation,” 2025. [Online]. Available: https://arxiv.org/abs/2512.16310
-
[43]
Xagen: An explainability tool for identifying and correcting failures in multi- agent workflows,
X. Wang, M. Yin, E. Koh, and M. D. Dogan, “Xagen: An explainability tool for identifying and correcting failures in multi- agent workflows,” 2025. [Online]. Available: https://arxiv.org/abs/ 2512.17896
-
[44]
Adaptiflow: An extensible framework for event-driven autonomy in cloud microservices,
B. A. Z. Ndadji, S. Bliudze, and C. Quinton, “Adaptiflow: An extensible framework for event-driven autonomy in cloud microservices,” 2025. [Online]. Available: https://arxiv.org/abs/2512. 23499
work page 2025
-
[45]
A2p-vis: an analyzer- to-presenter agentic pipeline for visual insights generation and reporting,
S. Gan, R. Wang, J. Mooney, and D. Kang, “A2p-vis: an analyzer- to-presenter agentic pipeline for visual insights generation and reporting,” 2025. [Online]. Available: https://arxiv.org/abs/2512.22101
-
[46]
The 2025 AI Agent Index: Documenting Technical and Safety Features of Deployed Agentic AI Systems
L. Staufer, K. Feng, K. Wei, L. Bailey, Y . Duan, M. Yang, A. P. Ozisik, S. Casper, and N. Kolt, “The 2025 ai agent index: Documenting technical and safety features of deployed agentic ai systems,” 2026. [Online]. Available: https://arxiv.org/abs/2602.17753
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
A survey of agentic ai and cybersecurity: Challenges, opportunities and use-case prototypes,
S. J. Lazer, K. Aryal, M. Gupta, and E. Bertino, “A survey of agentic ai and cybersecurity: Challenges, opportunities and use-case prototypes,”
-
[48]
Available: https://arxiv.org/abs/2601.05293
[Online]. Available: https://arxiv.org/abs/2601.05293
-
[49]
Agentic AI Security: Threats, Defenses, Evaluation, and Open Challenges
A. Chhabra, S. Datta, S. K. Nahin, and P. Mohapatra, “Agentic ai security: Threats, defenses, evaluation, and open challenges,” 2025. [Online]. Available: https://arxiv.org/abs/2510.23883
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Open Challenges in Multi-Agent Security: Towards Secure Systems of Interacting AI Agents
C. S. de Witt, “Open challenges in multi-agent security: Towards secure systems of interacting ai agents,” 2025. [Online]. Available: https://arxiv.org/abs/2505.02077
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Every keystroke you make: A tech-law measurement and analysis of event listeners for wiretapping,
S. Munir, N. Demir, Q. Li, K. Kollnig, and Z. Shafiq, “Every keystroke you make: A tech-law measurement and analysis of event listeners for wiretapping,” 2025. [Online]. Available: https://arxiv.org/abs/2508.19825
-
[52]
Secure development of a hooking-based deception framework against keylogging techniques,
M. S. I. Sajid, S. Ahmed, and R. Sosnoski, “Secure development of a hooking-based deception framework against keylogging techniques,”
-
[53]
Available: https://arxiv.org/abs/2508.04178
[Online]. Available: https://arxiv.org/abs/2508.04178
-
[54]
Authenticated delegation and authorized ai agents,
T. South, S. Marro, T. Hardjono, R. Mahari, C. D. Whitney, D. Greenwood, A. Chan, and A. Pentland, “Authenticated delegation and authorized ai agents,” 2025. [Online]. Available: https: //arxiv.org/abs/2501.09674
-
[55]
Towards automating data access permissions in ai agents,
Y . Wu, K. Yang, F. Roesner, T. Kohno, N. Zhang, and U. Iqbal, “Towards automating data access permissions in ai agents,” 2025. [Online]. Available: https://arxiv.org/abs/2511.17959
-
[56]
Policy-aware generative ai for safe, auditable data access governance,
S. A. Mandalawi, M. A. Mohammed, H. Maclean, M. C. Cakmak, and J. R. Talburt, “Policy-aware generative ai for safe, auditable data access governance,” 2025. [Online]. Available: https://arxiv.org/abs/2510.23474
-
[57]
H. Dang, T. Liu, Z. Wu, J. Yang, H. Jiang, T. Yang, P. Chen, Z. Wang, H. Wang, H. Li, B. Yin, and M. Jiang, “Improving large language models function calling and interpretability via guided-structured templates,” 2025. [Online]. Available: https: //arxiv.org/abs/2509.18076
-
[58]
Autotool: Dynamic tool selection and integration for agentic reasoning,
J. Zou, L. Yang, Y . Qi, S. Chen, M. Ai, K. Shen, J. He, and M. Wang, “Autotool: Dynamic tool selection and integration for agentic reasoning,” 2025. [Online]. Available: https://arxiv.org/abs/ 2512.13278
-
[59]
Toolrm: Outcome reward models for tool-calling large language models,
M. Agarwal, I. Abdelaziz, K. Basu, M. Unuvar, L. A. Lastras, Y . Rizk, and P. Kapanipathi, “Toolrm: Outcome reward models for tool-calling large language models,” 2025. [Online]. Available: https://arxiv.org/abs/2509.11963
-
[60]
Where llm agents fail and how they can learn from failures,
K. Zhu, Z. Liu, B. Li, M. Tian, Y . Yang, J. Zhang, P. Han, Q. Xie, F. Cui, W. Zhang, X. Ma, X. Yu, G. Ramesh, J. Wu, Z. Liu, P. Lu, J. Zou, and J. You, “Where llm agents fail and how they can learn from failures,” 2025. [Online]. Available: https://arxiv.org/abs/2509.25370
-
[61]
Tool preferences in agentic llms are unreliable,
K. Faghih, W. Wang, Y . Cheng, S. Bharti, G. Sriramanan, S. Balasubramanian, P. Hosseini, and S. Feizi, “Tool preferences in agentic llms are unreliable,” 2025. [Online]. Available: https: //arxiv.org/abs/2505.18135
-
[62]
From allies to adversaries: Manipulating llm tool-calling through adversarial injection,
H. Wang, R. Zhang, J. Wang, M. Li, Y . Huang, D. Wang, and Q. Wang, “From allies to adversaries: Manipulating llm tool-calling through adversarial injection,” 2024. [Online]. Available: https://arxiv.org/abs/2412.10198
-
[63]
From prompt injections to protocol exploits: Threats in llm-powered ai agents workflows,
M. A. Ferrag, N. Tihanyi, D. Hamouda, L. Maglaras, A. Lakas, and M. Debbah, “From prompt injections to protocol exploits: Threats in llm-powered ai agents workflows,” 2025. [Online]. Available: https://arxiv.org/abs/2506.23260
-
[64]
Attractive metadata attack: Inducing llm agents to invoke malicious tools,
K. Mo, L. Hu, Y . Long, and Z. Li, “Attractive metadata attack: Inducing llm agents to invoke malicious tools,” 2025. [Online]. Available: https://arxiv.org/abs/2508.02110
-
[65]
T. Gasmi, R. Guesmi, I. Belhadj, and J. Bennaceur, “Bridging ai and software security: A comparative vulnerability assessment of llm agent deployment paradigms,” 2025. [Online]. Available: https://arxiv.org/abs/2507.06323
-
[66]
Ai ides or autonomous agents? measuring the impact of coding agents on software development,
S. Agarwal, H. He, and B. Vasilescu, “Ai ides or autonomous agents? measuring the impact of coding agents on software development,”
-
[67]
Available: https://arxiv.org/abs/2601.13597
[Online]. Available: https://arxiv.org/abs/2601.13597
-
[68]
The attack and defense landscape of agentic ai: A comprehensive survey,
J. Kim, X. Liu, Z. Wang, S. Qiu, B. Li, W. Guo, and D. Song, “The attack and defense landscape of agentic ai: A comprehensive survey,” 2026. [Online]. Available: https://arxiv.org/abs/2603.11088
-
[69]
V . Koc, J. Verre, D. Blank, and A. Morgan, “Mind the metrics: Patterns for telemetry-aware in-ide ai application development using the model context protocol (mcp),” 2025. [Online]. Available: https://arxiv.org/abs/2506.11019
-
[70]
Exploring the challenges and opportunities of ai-assisted codebase generation,
P. Eibl, S. Sabouri, and S. Chattopadhyay, “Exploring the challenges and opportunities of ai-assisted codebase generation,” 2025. [Online]. Available: https://arxiv.org/abs/2508.07966
-
[71]
Ai agent systems: Architectures, applications, and evaluation,
B. Xu, “Ai agent systems: Architectures, applications, and evaluation,”
-
[72]
Available: https://arxiv.org/abs/2601.01743
[Online]. Available: https://arxiv.org/abs/2601.01743
-
[73]
A safety and security framework for real-world agentic systems,
S. Ghosh, B. Simkin, K. Shiarlis, S. Nandi, D. Zhao, M. Fiedler, J. Bazinska, N. Pope, R. Prabhu, D. Rohrer, M. Demoret, and B. Richardson, “A safety and security framework for real-world agentic systems,” 2025. [Online]. Available: https: //arxiv.org/abs/2511.21990
-
[74]
Task-aware delegation cues for llm agents,
X. Gu, “Task-aware delegation cues for llm agents,” 2026. [Online]. Available: https://arxiv.org/abs/2603.11011
-
[75]
X. Zhang, Y . Cui, G. Wang, W. Qiu, Z. Li, F. Han, Y . Huang, H. Qiu, B. Zhu, and P. He, “Verified multi-agent orchestration: A plan-execute-verify-replan framework for complex query resolution,”
-
[76]
Available: https://arxiv.org/abs/2603.11445
[Online]. Available: https://arxiv.org/abs/2603.11445
-
[77]
Agenttrace: A structured logging framework for agent system observability,
A. AlSayyad, K. Y . Huang, and R. Pal, “Agenttrace: A structured logging framework for agent system observability,” 2026. [Online]. Available: https://arxiv.org/abs/2602.10133
-
[78]
Agentsight: System-level observability for ai agents using ebpf,
Y . Zheng, Y . Hu, T. Yu, and A. Quinn, “Agentsight: System-level observability for ai agents using ebpf,” 2025. [Online]. Available: https://arxiv.org/abs/2508.02736
-
[79]
Q. Lan, A. Kaul, S. Jones, and S. Westrum, “Zero-trust runtime verification for agentic payment protocols: Mitigating replay and context-binding failures in ap2,” 2026. [Online]. Available: https://arxiv.org/abs/2602.06345
-
[80]
Trajectory-informed memory generation for self-improving agent systems,
G. Fang, V . Isahagian, K. R. Jayaram, R. Kumar, V . Muthusamy, P. Oum, and G. Thomas, “Trajectory-informed memory generation for self-improving agent systems,” 2026. [Online]. Available: https://arxiv.org/abs/2603.10600
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.