AutoVDC: Automated Vision Data Cleaning Using Vision-Language Models
Pith reviewed 2026-05-19 04:18 UTC · model grok-4.3
The pith
Vision-language models can automatically detect erroneous annotations in autonomous driving datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
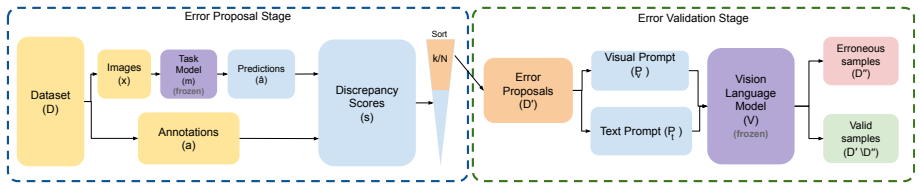
AutoVDC is a framework that leverages vision-language models to automatically identify erroneous annotations in object detection datasets for autonomous driving. Validated on KITTI and nuImages after intentionally injecting erroneous annotations, the method achieves high error detection rates. The pipeline compares performance across multiple VLMs and demonstrates that fine-tuning further improves error identification and subsequent data cleaning.
What carries the argument
AutoVDC pipeline that queries VLMs on images paired with their object annotations to flag inconsistencies or mistakes.
If this is right
- Error detection rates stay high when the same injected-error tests are run on both KITTI and nuImages.
- Fine-tuning the vision-language models used in the pipeline raises detection performance.
- The method reduces the need for repeated manual review cycles when building large autonomous driving datasets.
- Performance varies across different VLMs, with some models showing stronger results than others.
Where Pith is reading between the lines
- If false-positive rates remain low on untouched data, companies could insert AutoVDC as an early filter before any human review begins.
- The same VLM prompting strategy might extend to cleaning annotations for tasks such as semantic segmentation or lane marking.
- Wider adoption could lower the overall cost of creating high-quality training sets by cutting the number of human annotation passes required.
Load-bearing premise
That errors added on purpose to KITTI and nuImages match the actual annotation mistakes that appear in real production datasets for autonomous driving.
What would settle it
Apply AutoVDC to a production-scale driving dataset whose annotation errors have been independently verified by multiple human reviewers and check whether the flagged items align closely with the known errors while producing few false positives on clean images.
Figures



read the original abstract
Training of autonomous driving systems requires extensive datasets with precise annotations to attain robust performance. Human annotations suffer from imperfections, and multiple iterations are often needed to produce high-quality datasets. However, manually reviewing large datasets is laborious and expensive. In this paper, we introduce AutoVDC (Automated Vision Data Cleaning) framework and investigate the utilization of Vision-Language Models (VLMs) to automatically identify erroneous annotations in vision datasets, thereby enabling users to eliminate these errors and enhance data quality. We validate our approach using the KITTI and nuImages datasets, which contain object detection benchmarks for autonomous driving. To test the effectiveness of AutoVDC, we create dataset variants with intentionally injected erroneous annotations and observe the error detection rate of our approach. Additionally, we compare the detection rates using different VLMs and explore the impact of VLM fine-tuning on our pipeline. The results demonstrate our method's high performance in error detection and data cleaning experiments, indicating its potential to significantly improve the reliability and accuracy of large-scale production datasets in autonomous driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the AutoVDC framework, which uses Vision-Language Models (VLMs) to automatically detect erroneous annotations in vision datasets for autonomous driving. Validation is performed on KITTI and nuImages by creating variants with intentionally injected erroneous annotations, measuring error detection rates, comparing different VLMs, and examining the impact of VLM fine-tuning. The abstract concludes that the method demonstrates high performance with potential to improve large-scale production datasets.
Significance. If the approach can be shown to generalize beyond synthetic errors and to maintain low false-positive rates on clean data, it could meaningfully reduce the manual effort required for curating high-quality training data in autonomous driving. The application of VLMs to annotation cleaning is a timely idea that builds on recent multimodal capabilities, but the current evidence base is too limited to establish practical impact.
major comments (2)
- [Abstract] Abstract: the claim that results demonstrate 'high performance in error detection and data cleaning experiments' is unsupported because no quantitative metrics (detection rate, precision, recall, or false-positive rate) or details of the error-injection procedure are supplied. This omission is load-bearing for the central claim about improving production datasets.
- [Evaluation on KITTI and nuImages] Evaluation description: the paper reports results only on synthetically injected errors in KITTI and nuImages but provides no experiments measuring false-positive rates on the original clean datasets or any comparison between injected errors and naturally occurring annotation mistakes. Without these, the headline conclusion that the method will 'significantly improve the reliability ... of large-scale production datasets' cannot be assessed.
minor comments (2)
- Add a limitations section that explicitly discusses generalization risks from synthetic to real annotation errors and the computational cost of VLM inference at scale.
- Provide the exact prompt templates and VLM versions used so that the pipeline can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify areas where the abstract and evaluation sections can be strengthened with more explicit quantitative details and additional experiments. We address each point below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that results demonstrate 'high performance in error detection and data cleaning experiments' is unsupported because no quantitative metrics (detection rate, precision, recall, or false-positive rate) or details of the error-injection procedure are supplied. This omission is load-bearing for the central claim about improving production datasets.
Authors: We agree that the abstract would benefit from including specific quantitative metrics and a brief outline of the error-injection procedure to substantiate the performance claims. The body of the paper already reports error detection rates across different VLMs and fine-tuning settings on the injected-error variants. In the revision we will update the abstract to incorporate key metrics (detection rates) and a short description of how erroneous annotations were injected, thereby making the central claims more directly supported by evidence. revision: yes
-
Referee: [Evaluation on KITTI and nuImages] Evaluation description: the paper reports results only on synthetically injected errors in KITTI and nuImages but provides no experiments measuring false-positive rates on the original clean datasets or any comparison between injected errors and naturally occurring annotation mistakes. Without these, the headline conclusion that the method will 'significantly improve the reliability ... of large-scale production datasets' cannot be assessed.
Authors: We acknowledge the need to demonstrate low false-positive rates on clean data. We will add new experiments that apply AutoVDC to the unmodified KITTI and nuImages datasets and report the resulting false-positive rates. Regarding naturally occurring mistakes, the injected errors were chosen to reflect common annotation issues in object detection; we will expand the discussion to make this correspondence explicit. A direct head-to-head comparison with verified natural errors is not feasible with the current datasets and would require substantial new annotation effort, which we note as future work while still providing controlled evidence of the framework's utility. revision: partial
- Direct empirical comparison against naturally occurring annotation mistakes, because the evaluated datasets lack comprehensive ground-truth labels for such real-world errors.
Circularity Check
No circularity: empirical validation on injected errors
full rationale
The paper introduces an empirical framework that applies off-the-shelf VLMs to flag annotation errors in object-detection datasets. Validation consists of creating synthetic-error variants of KITTI and nuImages, running the VLM pipeline, and reporting detection rates. No equations, fitted parameters, or derivation steps appear in the abstract or described method; the performance numbers are direct experimental outputs rather than quantities that reduce to the inputs by construction. Self-citations, if present, are not invoked to justify uniqueness or to close a definitional loop. The work is therefore self-contained as a standard empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs can reliably distinguish correct from incorrect object annotations in driving scenes when given appropriate prompts.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage Error Proposal (discrepancy scoring) + Error Validation (VLM VQA) pipeline
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
noise-injection experiments on object-detection annotations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Evian: Towards Explainable Visual Instruction-tuning Data Auditing
EVian decomposes vision-language model responses into three cognitive components and audits them along consistency, coherence, and accuracy axes, showing that a small curated subset outperforms much larger training sets.
Reference graph
Works this paper leans on
-
[1]
Automatic labeling to generate training data for online lidar-based moving object segmentation,
X. Chen et al., “Automatic labeling to generate training data for online lidar-based moving object segmentation,” RA-L, vol. 7, no. 3, 2022. 1
work page 2022
-
[2]
Scalability in perception for autonomous driving: Waymo open dataset,
P. Sun et al., “Scalability in perception for autonomous driving: Waymo open dataset,” in CVPR, June 2020. 1
work page 2020
-
[3]
Argoverse 2: Next generation datasets for self- driving perception and forecasting,
B. Wilson et al., “Argoverse 2: Next generation datasets for self- driving perception and forecasting,” in NeurIPS Datasets and Benchmarks, 2021. 1
work page 2021
-
[4]
VQA: Visual Question Answering,
S. Antol et al. , “VQA: Visual Question Answering,” in ICCV,
-
[5]
Are we ready for au- tonomous driving? the KITTI vision benchmark suite,
A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for au- tonomous driving? the KITTI vision benchmark suite,” in CVPR,
-
[6]
nuScenes: A multimodal dataset for au- tonomous driving,
H. Caesar et al. , “nuScenes: A multimodal dataset for au- tonomous driving,” in CVPR, 2020. 1, 2, 4
work page 2020
-
[7]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,”
-
[8]
C. M. Bishop, Pattern Recognition and Machine Learning . Springer, 2006. 2
work page 2006
-
[9]
Efficient algorithms for mining outliers from large data sets,
S. Ramaswamy, R. Rastogi, and K. Shim, “Efficient algorithms for mining outliers from large data sets,” in SIGMOD/PODS,
-
[10]
Active label cleaning for improved dataset quality under resource constraints,
M. Bernhardt et al., “Active label cleaning for improved dataset quality under resource constraints,” Nature Communications , vol. 13, no. 1, 2022. 2
work page 2022
-
[11]
Simple and scalable predictive uncertainty estimation using deep ensembles,
B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and scalable predictive uncertainty estimation using deep ensembles,” in NeurIPS, 2017. 2
work page 2017
-
[12]
A sequential algorithm for training text classifiers,
D. D. Lewis and W. A. Gale, “A sequential algorithm for training text classifiers,” in SIGIR. Springer London, 1994. 2
work page 1994
-
[13]
Active learning literature survey,
B. Settles, “Active learning literature survey,” University of Wisconsin-Madison Department of Computer Sciences, Tech. Rep. TR 1648, 2009. 2
work page 2009
-
[14]
H.-M. Heyn et al. , “Automotive perception software devel- opment: An empirical investigation into data, annotation, and ecosystem challenges,” 2023. 2
work page 2023
-
[15]
A survey on autonomous driving datasets: Statistics, annotation quality, and a future outlook,
M. Liu et al. , “A survey on autonomous driving datasets: Statistics, annotation quality, and a future outlook,” 2024. 2
work page 2024
-
[16]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng et al. , “Judging llm-as-a-judge with mt-bench and chatbot arena,” 2023. 2
work page 2023
-
[17]
Llms-as-judges: A comprehensive survey on llm- based evaluation methods,
H. Li et al. , “Llms-as-judges: A comprehensive survey on llm- based evaluation methods,” 2024. 2
work page 2024
-
[18]
Generative AI for synthetic data genera- tion: Methods, challenges and the future,
X. Guo and Y . Chen, “Generative AI for synthetic data genera- tion: Methods, challenges and the future,” 2024. 2
work page 2024
-
[19]
Learning transferable visual models from natural language supervision,
A. Radford et al. , “Learning transferable visual models from natural language supervision,” 2021. 2
work page 2021
-
[20]
Florence-2: Advancing a unified representation for a variety of vision tasks,
B. Xiao et al. , “Florence-2: Advancing a unified representation for a variety of vision tasks,” 2023. 2
work page 2023
-
[21]
SAM 2: Segment anything in images and videos,
N. Ravi et al., “SAM 2: Segment anything in images and videos,”
- [22]
-
[23]
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,”
-
[24]
Phi-3 technical report: A highly capable language model locally on your phone,
M. Abdin et al. , “Phi-3 technical report: A highly capable language model locally on your phone,” 2024. 2
work page 2024
-
[25]
Laion-5b: An open large-scale dataset for training next generation image-text models,
C. Schuhmann et al., “Laion-5b: An open large-scale dataset for training next generation image-text models,” 2022. 2
work page 2022
-
[26]
ViP-LLaV A: Making large multimodal models understand arbitrary visual prompts,
M. Cai et al. , “ViP-LLaV A: Making large multimodal models understand arbitrary visual prompts,” 2024. 2, 5, 6
work page 2024
-
[27]
J. Kim, Y . Ku, J. Kim, J. Cha, and S. Baek, “Vlm-pl: Advanced pseudo labeling approach for class incremental object detection via vision-language model,” in CVPR Workshops, 2024. 2
work page 2024
-
[28]
M. Diab, G. Barchi, and D. Moser, “Vision-language models as pseudo-label validators in semi-supervised learning: Geo- locating medium voltage cabins from google street view im- agery,” 01 2025. 2
work page 2025
-
[29]
H. Lu, Y . Bian, and R. C. Shah, “ClipGrader: Leveraging vision- language models for robust label quality assessment in object detection,” 2025. 2
work page 2025
-
[30]
Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding,
Z. Wu et al., “Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding,” 2024. 5, 6
work page 2024
- [31]
- [32]
- [33]
-
[34]
LoRA: Low-rank adaptation of large language models,
E. J. Hu et al., “LoRA: Low-rank adaptation of large language models,” in ICLR, 2022. 5 8
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.