Generating Project-Specific Test Cases with Requirement Validation Intention
Pith reviewed 2026-05-19 03:11 UTC · model grok-4.3
The pith
Retrieving a similar project test and editing it with an LLM produces tests that better match developers' validation intentions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
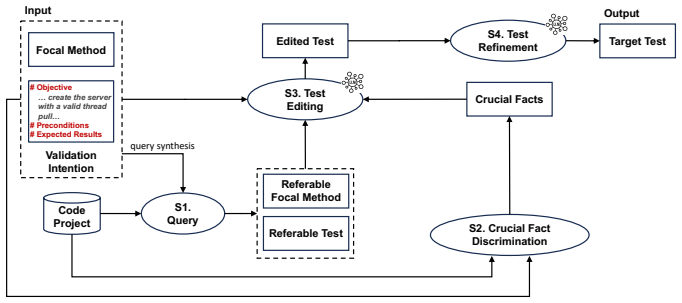
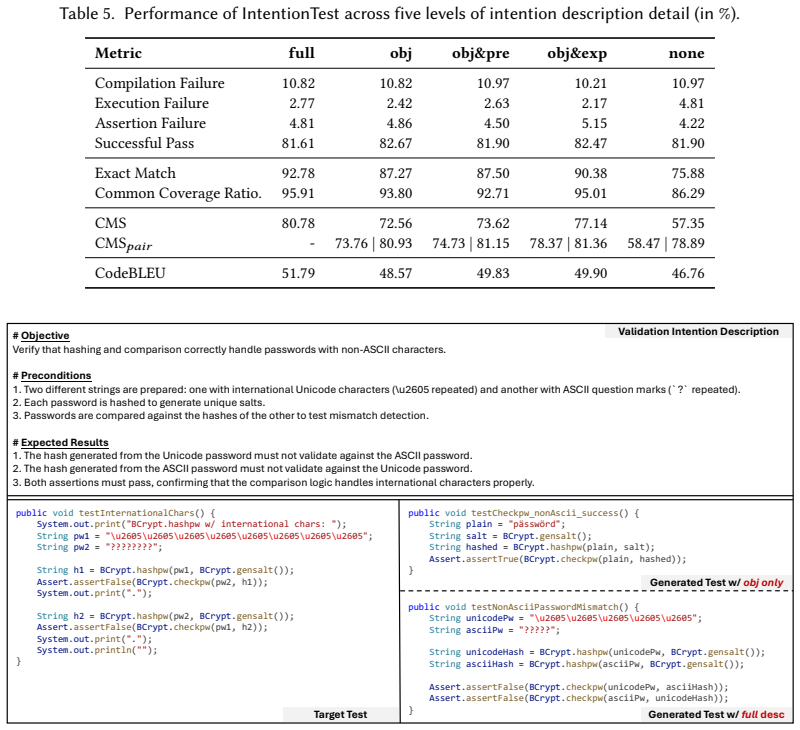
IntentionTest generates project-specific tests given a focal code and a validation intention description consisting of a test objective with precondition and expected results. It retrieves a reusable test in the project as reference and edits it with an LLM toward the target test. On 3,680 test cases, this produces tests far more semantically relevant to ground-truth tests by killing 28.1% to 37.6% more common mutants and sharing 16.9% to 23.9% more common coverage, while also generating 23.7% to 49.0% more successful passing tests than state-of-the-art baselines.
What carries the argument
IntentionTest's retrieval-and-edit pipeline, which locates a reusable test reference from the project and adapts it via LLM to a stated validation intention of objective, precondition, and expected results.
If this is right
- Generated tests become more semantically relevant to actual developer-written tests.
- Higher mutant-killing rates indicate stronger alignment with real fault-detection needs.
- Greater coverage overlap with ground-truth tests reflects structural similarity to human-written tests.
- A larger share of successful passing tests means the outputs are more immediately usable.
- Tests reflecting explicit validation intentions are more likely to be adopted in practice.
Where Pith is reading between the lines
- The same retrieval-and-edit pattern could be applied to other artifacts such as bug reports or requirements documents to keep them consistent with code changes.
- Projects with very few or highly unique tests may need fallback strategies when retrieval finds no close reference.
- Linking the validation intention description directly to formal requirements could create traceable tests from specification to execution.
- Extending the intention to cover non-functional aspects such as performance constraints would broaden the method beyond functional validation.
Load-bearing premise
The method assumes a suitable test reference can be retrieved from the project that is close enough in structure and intent for the LLM edit to succeed without semantic drift or incorrect assertions.
What would settle it
Running IntentionTest on a project containing no tests structurally similar to the target validation scenarios and observing that mutant-killing rates and passing-test counts fall to baseline levels or below would falsify the central claim.
Figures





read the original abstract
Test cases are valuable assets for maintaining software quality. State-of-the-art automated test generation techniques typically focus on maximizing program branch coverage or translating focal methods into test code. However, in contrast to branch coverage or code-to-test translation, practical tests are written out of the need to validate whether a requirement has been fulfilled. Specifically, each test usually reflects a developer's validation intention for a program function, regarding (1) what is the test scenario of a program function? and (2) what is expected behavior under such a scenario? Without taking such intention into account, generated tests are less likely to be adopted in practice. In this work, we propose IntentionTest, which generates project-specific tests given the description of validation intention. IntentionTest adopts a retrieval-and-edit manner. First, given a focal code and a description of validation intention consisting of a test objective with test precondition and expected results, IntentionTest retrieves a reusable test in the project as the test reference. Then, IntentionTest edits the test reference with an LLM regarding the validation intention toward the target test. We extensively evaluate IntentionTest against four baselines on 3,680 test cases. Compared to state-of-the-art baselines, IntentionTest can (1) generate tests far more semantically relevant to ground-truth tests by (i) killing 28.1% to 37.6% more common mutants and (ii) sharing 16.9% to 23.9% more common coverage; and (2) generate 23.7% to 49.0% more successful passing tests.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IntentionTest, a retrieval-and-edit technique that generates project-specific test cases given a validation intention (test objective, precondition, and expected results). It retrieves a reusable test from the project as reference and uses an LLM to edit it toward the target scenario. Evaluation on 3,680 test cases across projects shows IntentionTest outperforms four baselines by killing 28.1–37.6% more common mutants, sharing 16.9–23.9% more common coverage, and producing 23.7–49.0% more successful passing tests.
Significance. If the central empirical claims hold under fair conditions, the work meaningfully advances automated test generation by shifting focus from coverage maximization or focal-method translation to explicit requirement-validation intentions, potentially increasing the practical adoptability of generated tests. The scale of the evaluation (3,680 cases) and use of mutant analysis plus coverage overlap as semantic-relevance proxies are concrete strengths that support falsifiable claims.
major comments (2)
- [§5.2] §5.2 and Table 2: the experimental comparison does not indicate that the four baselines receive the same structured validation intention (objective + precondition + expected results) that IntentionTest uses for retrieval and editing. Standard coverage-driven or focal-method baselines normally operate without this oracle-like input; if the intention is supplied only to IntentionTest, the reported deltas (e.g., 28.1–37.6% more mutants killed) cannot isolate the contribution of the retrieval-and-edit pipeline from the effect of extra input. This assumption is load-bearing for the headline superiority claim.
- [§4.3] §4.3 and §5.3: no ablation or error analysis is presented on retrieval quality or on cases where LLM editing introduces semantic drift or incorrect assertions. The weakest assumption—that a retrieved reference is sufficiently close in structure and intent for reliable transformation—is therefore untested, undermining confidence that the observed gains stem from the proposed method rather than fortunate retrievals.
minor comments (2)
- [§5.1] The description of the four baselines in §5.1 would benefit from explicit pseudocode or parameter settings to allow exact reproduction.
- [Figure 2] Figure 2 (pipeline overview) uses small font sizes for the intention components; enlarging or adding a legend would improve readability.
Simulated Author's Rebuttal
Thank you for the referee's constructive comments and positive assessment of the work's significance, evaluation scale, and use of mutant analysis and coverage overlap. We address each major comment point by point below.
read point-by-point responses
-
Referee: [§5.2] §5.2 and Table 2: the experimental comparison does not indicate that the four baselines receive the same structured validation intention (objective + precondition + expected results) that IntentionTest uses for retrieval and editing. Standard coverage-driven or focal-method baselines normally operate without this oracle-like input; if the intention is supplied only to IntentionTest, the reported deltas (e.g., 28.1–37.6% more mutants killed) cannot isolate the contribution of the retrieval-and-edit pipeline from the effect of extra input. This assumption is load-bearing for the headline superiority claim.
Authors: The structured validation intention is the defining input to IntentionTest and the central element of our contribution, as the abstract and §1 emphasize that practical tests are written to validate specific requirements rather than maximize coverage or translate focal methods. The four baselines are established techniques that do not accept or exploit such explicit intention descriptions; they are intentionally chosen to represent current state-of-the-art approaches that lack this capability. The reported improvements therefore demonstrate the benefit of incorporating intention via retrieval-and-edit, which is precisely the point of the work. We will revise §5.2 and the caption of Table 2 to clarify that the intention is not an extraneous oracle but the core input that enables the proposed pipeline, and we will add a short discussion of why comparing against intention-agnostic baselines is the appropriate way to quantify the practical advantage. revision: partial
-
Referee: [§4.3] §4.3 and §5.3: no ablation or error analysis is presented on retrieval quality or on cases where LLM editing introduces semantic drift or incorrect assertions. The weakest assumption—that a retrieved reference is sufficiently close in structure and intent for reliable transformation—is therefore untested, undermining confidence that the observed gains stem from the proposed method rather than fortunate retrievals.
Authors: We agree that a dedicated analysis of retrieval quality and LLM editing behavior would increase confidence in the results. The current manuscript reports only aggregate end-to-end metrics across 3,680 cases. In the revised version we will add an error analysis subsection (or appendix) that (i) reports retrieval similarity statistics (e.g., token overlap or embedding distance between the retrieved reference and the target test) and (ii) presents a manual inspection of a random sample of cases, categorizing instances of semantic drift or incorrect assertions introduced during editing. This will directly test the assumption that retrieved references are sufficiently close for reliable transformation. revision: yes
Circularity Check
No circularity: empirical results rest on external benchmarks
full rationale
The paper proposes IntentionTest as a retrieval-and-edit technique and evaluates it empirically on 3,680 test cases against four external baselines, measuring mutant killing rates, coverage overlap, and passing-test counts relative to ground-truth developer tests. No equations, fitted parameters, or first-principles derivations are presented whose outputs reduce by construction to the inputs. The reported deltas are computed from independent test suites and standard mutation/coverage tools, satisfying the self-contained-against-external-benchmarks criterion.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 4 Pith papers
-
Generalizing Test Cases for Comprehensive Test Scenario Coverage
TestGeneralizer generalizes an initial test into a set of executable tests covering more diverse scenarios, delivering +31.66% mutation-based and +23.08% LLM-assessed scenario coverage gains over ChatTester on 12 open...
-
ARuleCon: Agentic Security Rule Conversion
ARuleCon uses AI agents plus execution-based checks to convert SIEM rules across vendors with 15% higher fidelity than standard LLM translation.
-
EditFlow: Benchmarking and Optimizing Code Edit Recommendation Systems via Reconstruction of Developer Flows
EditFlow reconstructs temporal developer editing flows from code changes to benchmark and optimize AI code edit recommenders so they align with natural incremental reasoning rather than static snapshots.
-
Learning Project-wise Subsequent Code Edits via Interleaving Neural-based Induction and Tool-based Deduction
TRACE improves project-wise subsequent code editing by interleaving neural-based induction for semantic edits and tool-based deduction for syntactic edits.
Reference graph
Works this paper leans on
-
[1]
2021. IEEE/ISO/IEC International Standard for Software and systems engineering–Software testing–Part 3:Test documentation.ISO/IEC/IEEE 29119-3:2021(E)(2021), 1–98
work page 2021
-
[2]
Nadia Alshahwan, Jubin Chheda, Anastasia Finogenova, Beliz Gokkaya, Mark Harman, Inna Harper, Alexandru Marginean, Shubho Sengupta, and Eddy Wang. 2024. Automated unit test improvement using large language models at meta. InCompanion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering. 185–196
work page 2024
-
[3]
Anonymous. 2025. Anonymous video for IntentionTest tool. https://youtu.be/i1qMPqb993A
work page 2025
-
[4]
Anonymous. 2025. Anonymous website for IntentionTest. https://sites.google.com/view/domain-specific-tester/home
work page 2025
-
[5]
Andrea Arcuri and Xin Yao. 2008. Search based software testing of object-oriented containers.Information Sciences 178, 15 (2008), 3075–3095
work page 2008
-
[6]
Spark authors. 2023. Spark - a tiny web framework for Java 8. https://github.com/perwendel/spark
work page 2023
-
[7]
awesome-algorithm authors. 2022. Awesome Algorithm. https://github.com/codeartx/awesome-algorithm
work page 2022
-
[8]
bartowski. 2025. DeepSeek-R1-Distill-Qwen-32B-GGUF. https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen- 32B-GGUF
work page 2025
-
[9]
Tobias Baum and Kurt Schneider. 2016. On the need for a new generation of code review tools. InProduct-Focused Software Process Improvement: 17th International Conference, PROFES 2016, Trondheim, Norway, November 22-24, 2016, Proceedings 17. Springer, 301–308
work page 2016
-
[10]
blade authors. 2025. Lightning fast and elegant mvc framework for Java8. https://github.com/lets-blade/blade
work page 2025
-
[11]
Pietro Braione, Giovanni Denaro, Andrea Mattavelli, and Mauro Pezzè. 2017. Combining symbolic execution and search-based testing for programs with complex heap inputs. InProceedings of the 26th ACM SIGSOFT International Symposium on Software Testing and Analysis. 90–101
work page 2017
-
[12]
Pietro Braione, Giovanni Denaro, Andrea Mattavelli, and Mauro Pezzè. 2018. SUSHI: a test generator for programs with complex structured inputs. In 2018 IEEE/ACM 40th International Conference on Software Engineering: Companion (ICSE-Companion)
work page 2018
-
[13]
Cristian Cadar, Daniel Dunbar, Dawson R Engler, et al. 2008. Klee: unassisted and automatic generation of high-coverage tests for complex systems programs.. InOSDI, Vol. 8. 209–224
work page 2008
-
[14]
José Campos, Andrea Arcuri, Gordon Fraser, and Rui Abreu. 2014. Continuous test generation: Enhancing continuous integration with automated test generation. InProceedings of the 29th ACM/IEEE international conference on Automated software engineering. 55–66
work page 2014
-
[15]
cron-utils authors. 2025. Cron utils for parsing, validations and human readable descriptions as well as date/time interoperability. https://github.com/jmrozanec/cron-utils
work page 2025
-
[16]
Ermira Daka, José Campos, Gordon Fraser, Jonathan Dorn, and Westley Weimer. 2015. Modeling readability to improve unit tests. InProceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. 107–118
work page 2015
-
[17]
Elizabeth Dinella, Gabriel Ryan, Todd Mytkowicz, and Shuvendu K Lahiri. 2022. Toga: A neural method for test oracle generation. InProceedings of the 44th International Conference on Software Engineering. 2130–2141
work page 2022
-
[18]
Chunhao Dong, Yanjie Jiang, Yuxia Zhang, Yang Zhang, and Liu Hui. 2025. ChatGPT-Based Test Generation for Refactoring Engines Enhanced by Feature Analysis on Examples . In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, 746–746. doi:10.1109/ICSE55347.2025.00210
-
[19]
Emad Fallahzadeh, Amir Hossein Bavand, and Peter C Rigby. 2023. Accelerating Continuous Integration with Parallel Batch Testing. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 55–67
work page 2023
-
[20]
Gordon Fraser and Andrea Arcuri. 2011. Evosuite: automatic test suite generation for object-oriented software. InProceedings of the 19th ACM SIGSOFT symposium and the 13th European conference on Foundations of software engineering. 416–419
work page 2011
- [21]
-
[22]
Patrice Godefroid, Nils Klarlund, and Koushik Sen. 2005. DART: Directed automated random testing. InProceedings of the 2005 ACM SIGPLAN conference on Programming language design and implementation. 213–223
work page 2005
-
[23]
Javier Godoy, Juan Pablo Galeotti, Diego Garbervetsky, and Sebastián Uchitel. 2021. Enabledness-based testing of object protocols.ACM Transactions on Software Engineering and Methodology (TOSEM)30, 2 (2021), 1–36
work page 2021
-
[24]
Larisa Gota, Dan Gota, and Liviu Miclea. 2020. Continuous Integration in Automation Testing. In2020 IEEE International Conference on Automation, Quality and Testing, Robotics (AQTR). IEEE, 1–6. 19
work page 2020
-
[25]
Giovanni Grano, Simone Scalabrino, Harald C. Gall, and Rocco Oliveto. 2018. An empirical investigation on the readability of manual and generated test cases. InProceedings of the 26th Conference on Program Comprehension. 348–351
work page 2018
-
[26]
imglib authors. 2023. Imglib: lightweight Image processing library. https://github.com/nackily/imglib
work page 2023
-
[27]
Sungmin Kang, Juyeon Yoon, and Shin Yoo. 2023. Large language models are few-shot testers: Exploring llm-based general bug reproduction. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2312–2323
work page 2023
-
[28]
Caroline Lemieux, Jeevana Priya Inala, Shuvendu K Lahiri, and Siddhartha Sen. 2023. Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 919–931
work page 2023
-
[29]
Tsz-On Li, Wenxi Zong, Yibo Wang, Haoye Tian, Ying Wang, Shing-Chi Cheung, and Jeff Kramer. 2023. Nuances are the key: Unlocking chatgpt to find failure-inducing tests with differential prompting. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 14–26
work page 2023
-
[30]
Yun Lin, You Sheng Ong, Jun Sun, Gordon Fraser, and Jin Song Dong. 2021. Graph-based seed object synthesis for search-based unit testing. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 1068–1080
work page 2021
-
[31]
Yun Lin, Jun Sun, Gordon Fraser, Ziheng Xiu, Ting Liu, and Jin Song Dong. 2020. Recovering fitness gradients for interprocedural Boolean flags in search-based testing. InProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis. 440–451
work page 2020
-
[32]
Simone Mezzaro, Alessio Gambi, and Gordon Fraser. 2024. An empirical study on how large language models impact software testing learning. InProceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering. 555–564
work page 2024
- [33]
-
[34]
Fangwen Mu, Lin Shi, Song Wang, Zhuohao Yu, Binquan Zhang, ChenXue Wang, Shichao Liu, and Qing Wang. 2024. ClarifyGPT: A Framework for Enhancing LLM-Based Code Generation via Requirements Clarification.Proceedings of the ACM on Software Engineering1, FSE (2024), 2332–2354
work page 2024
-
[35]
Zifan Nan, Zhaoqiang Guo, Kui Liu, and Xin Xia. 2025. Test Intention Guided LLM-Based Unit Test Generation. In 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). 1026–1038
work page 2025
-
[36]
Pengyu Nie, Rahul Banerjee, Junyi Jessy Li, Raymond J Mooney, and Milos Gligoric. 2023. Learning deep semantics for test completion. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2111–2123
work page 2023
-
[37]
Shuyin Ouyang, Jie M. Zhang, Mark Harman, and Meng Wang. 2024. An Empirical Study of the Non-determinism of ChatGPT in Code Generation.ACM Trans. Softw. Eng. Methodol.(2024). doi:10.1145/3697010
-
[38]
Carlos Pacheco and Michael D Ernst. 2007. Randoop: feedback-directed random testing for Java. InCompanion to the 22nd ACM SIGPLAN conference on Object-oriented programming systems and applications companion. 815–816
work page 2007
-
[39]
Fabio Palomba, Dario Di Nucci, Annibale Panichella, Rocco Oliveto, and Andrea De Lucia. 2016. On the diffusion of test smells in automatically generated test code: an empirical study. InProceedings of the 9th International Workshop on Search-Based Software Testing. 5–14
work page 2016
-
[40]
Fabio Palomba, Annibale Panichella, Andy Zaidman, Rocco Oliveto, and Andrea De Lucia. 2016. Automatic test case generation: what if test code quality matters?. InProceedings of the 25th International Symposium on Software Testing and Analysis. 130–141
work page 2016
- [41]
-
[42]
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. Codebleu: a method for automatic evaluation of code synthesis.arXiv preprint arXiv:2009.10297 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[43]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al . 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Max Schäfer, Sarah Nadi, Aryaz Eghbali, and Frank Tip. 2023. An empirical evaluation of using large language models for automated unit test generation.IEEE Transactions on Software Engineering(2023)
work page 2023
-
[45]
Koushik Sen, Darko Marinov, and Gul Agha. 2005. CUTE: A concolic unit testing engine for C.ACM SIGSOFT Software Engineering Notes30, 5 (2005), 263–272
work page 2005
-
[46]
Jiho Shin, Sepehr Hashtroudi, Hadi Hemmati, and Song Wang. 2024. Domain Adaptation for Code Model-Based Unit Test Case Generation. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1211–1222. 20
work page 2024
- [47]
-
[48]
truth authors. 2025. Fluent assertions for Java and Android. https://github.com/google/truth
work page 2025
- [49]
-
[50]
Yue Wang, Hung Le, Akhilesh Gotmare, Nghi Bui, Junnan Li, and Steven Hoi. 2023. CodeT5+: Open Code Large Language Models for Code Understanding and Generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 1069–1088
work page 2023
-
[51]
Jin Wen, Qiang Hu, Yuejun Guo, Maxime Cordy, and Yves Le Traon. 2025. Variable Renaming-Based Adversarial Test Generation for Code Model: Benchmark and Enhancement.ACM Transactions on Software Engineering and Methodology (2025)
work page 2025
-
[52]
Chunqiu Steven Xia, Matteo Paltenghi, Jia Le Tian, Michael Pradel, and Lingming Zhang. 2024. Fuzz4all: Univer- sal fuzzing with large language models. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
work page 2024
-
[53]
yavi authors. 2025. a lambda based type safe validation for Java. https://github.com/making/yavi
work page 2025
-
[54]
Zhiqiang Yuan, Mingwei Liu, Shiji Ding, Kaixin Wang, Yixuan Chen, Xin Peng, and Yiling Lou. 2024. Evaluating and Improving ChatGPT for Unit Test Generation.Proc. ACM Softw. Eng.1, FSE, Article 76 (jul 2024), 24 pages. doi:10.1145/3660783
-
[55]
Xin Zhou, Kisub Kim, Bowen Xu, DongGyun Han, Junda He, and David Lo. 2023. Generation-based code review automation: how far are weƒ. In2023 IEEE/ACM 31st International Conference on Program Comprehension (ICPC). IEEE, 215–226. 21
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.